-
《CRFL:Certifiably Robust Federated Learning against Backdoor Attacks》
CRFL:Certifiably Robust Federated Learning against Backdoor Attacks
CRFL:针对后门攻击的可验证的鲁棒性联邦学习
后门攻击:
后门攻击是深度学习中的一种新兴安全威胁。当深度神经模型被注入后门时,它会在标准输入上正常运行,但一旦输入包含特定的后门触发器,就会给出对手指定的预测。当前的文本后门攻击在一些棘手的情况下攻击性能较差。
相关术语:
- user:等价于defender,是DNN模型的所有者;
- attacker:是想要在模型中植入后门的人;
- clean input:指没有触发器的输入,它可以是原始训练样本、验证样本或测试样本,等价于clean sample,clean instance,benign input;
- trigger input:指带有攻击者指定的为了触发后门而设置的触发器的输入,等价于trigger sample,trigger instance,adversarial input,poisoned input;
- target class:指攻击者指定触发器对应要触发的目标标签,等价于target label;
- source class:指攻击者要通过trigger input触发修改的原标签,等价于source label;
- latent representation:等价于latent feature,指高维数据(一般特指input)的低维表示,latent representation是来自神经网络中间层的特征;
- Digital Attack:指对抗性扰动被标记在数字输入上,例如通过修改数字图像中的像素;
- Physical Attack:指对物理世界中的攻击对象做出对抗性扰动,不过对于系统捕获的digital input是不可控的,可以理解为在现实世界中发动攻击。
背景:
联邦学习作为一种分布式的学习方式,通过聚合来自不同客户端的信息来训练一个全局模型,已经取得了很大成功。
联邦学习存在的安全问题:
恶意用户会通过后门对全局模型进行投毒攻击和模型替换,进而干预全局模型的预测结果。
现存方法的缺陷:
现存的大量方法都是通过设计一些鲁棒性的聚合方法,或者针对后门设计一些经验鲁棒联邦训练协议,但是这些方法都缺乏鲁棒性验证。
文章的贡献:
- 提出第一个针对后门的验证鲁棒性联邦学习框架CRFL。CRFL利用对模型参数的裁剪与平滑来控制全局模型的平滑性,因此对规模有限的后门能具有鲁棒验证性。
- 指出了所提方法的验证鲁棒性与联邦学习中参数的关系,参数包括有毒实例级别、攻击者数量、训练的次数。
- 做了大量的实验进行验证,提出了第一个在联邦学习中针对后门攻击的可验证鲁棒性基准。
1. 介绍(Introduction)
在联邦学习的场景中,很容易在本地客户端添加像后门这种的对抗扰动,从而影响全局模型的训练。针对这些对抗攻击,现有方法包括:设计一种鲁棒性聚合函数、开发经验丰富的联邦学习协议、利用噪声扰动、在训练期间增加额外的评估。但是这些方法都缺乏在一定条件下针对后门攻击的鲁棒性验证。
**CRFL的具体过程:**在训练阶段,每个客户端可以上传参数到服务端做聚合与更新,其中服务端主要负责:(1)聚合从客户端收集的模型信息;(2)裁剪聚合模型的范式;(3)对被裁剪模型增加随机噪声;(4)给每一个客户端返回新的模型参数。在测试阶段:服务器基于随机参数平滑法来使最终全局模型平滑,同时基于这个平滑后的模型来做最终预测。
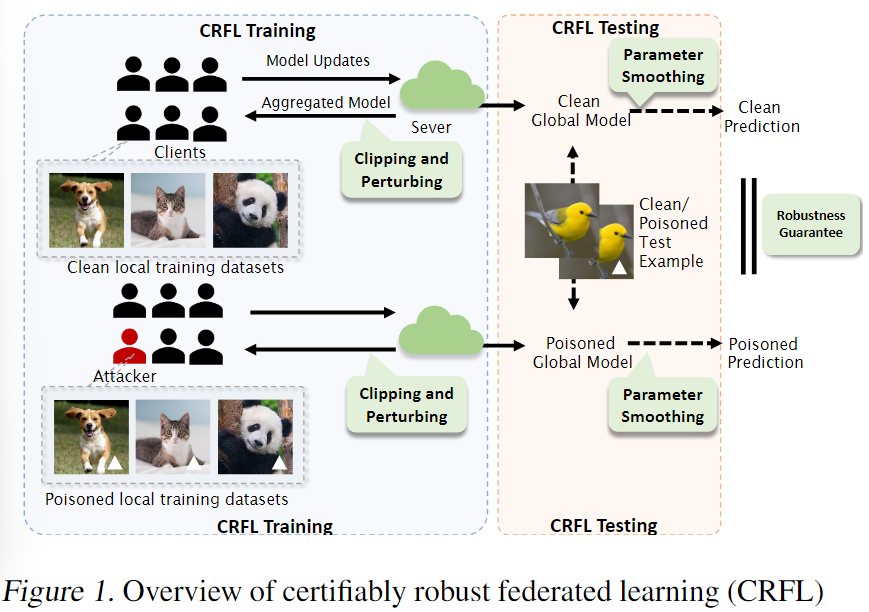
通过理论证明,只要后门是在认证的范围内,所训练出的全局模型针对后门攻击将是可验证鲁棒的。为了获得上述鲁棒性验证,在每一步聚合过程中,通过将聚合过程视作一个马尔科夫内核,从而量化被聚合模型的紧密度。利用这个模型紧密度与参数平滑程序来验证最终的预测结果。
2.相关工作(Related work)
**联邦学习中的后门攻击:**针对联邦学习的后门攻击目标是训练一个强壮的有毒本地模型并且提交有毒模型更新到中心服务器,从而误导全局模型。后门攻击的目标是在训练阶段注入一个后门模式,这样任何具有这种模式的测试输入都会被错误地分类到目标标签。在联邦学习中后门攻击者操纵本地模型训练,同时拟合主任务与后门任务。最终全局模型在正常样本上表现正常,在后门样本中具有很高的攻击成功率。攻击者可以通过在本地多次迭代训练,从而扩展恶意更新。
鲁棒联邦学习:(1)识别并降低有害的权重;【在IID问题的假设下】(2)引入鲁棒性的联邦协议;(3)增加识别后门攻击的额外验证阶段。【验证鲁棒性】
3.准备工作(Preliminaries)
3.1联邦学习
优化目标:
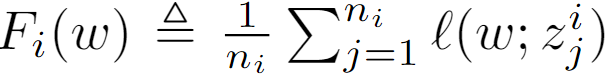
一轮学习过程(Avarage SGD):
客户端:
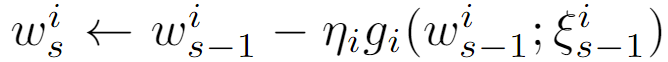

服务端:
后门攻击:
攻击者:
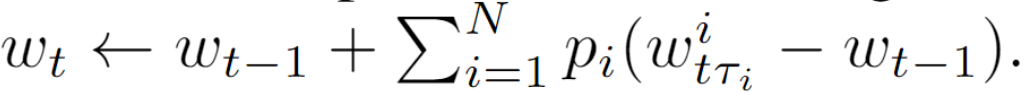
服务端:

4.方法(Methodology)
训练过程:

测试过程:

**与中心化设置(RAB)中可证明鲁棒性比较:**RAB使用M个噪声扰动的数据来训练M个模型,属于输入数据扰动。CRFL只训练了一个全局模型,并且最终生成M个噪声扰动的模型副本,输入模型参数扰动。
5. 验证鲁棒性
**目标:**在联邦学习中,验证鲁棒性的目标就是对于每一个测试点,返回测试点的预测值以及验证值,这个验证值代表如果某些客户端的本地(局部的)本地数据集中的一些特征被修改,该测试点的预测值依然不会改变。
三个假设:
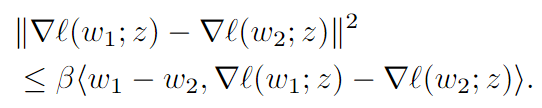
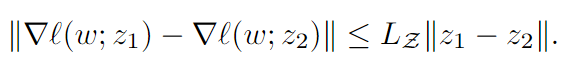
FL服从算法1训练,算法2测试。
定理1 一般鲁棒性条件:
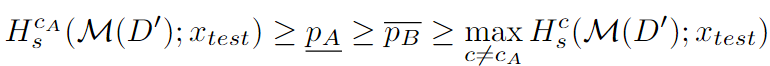
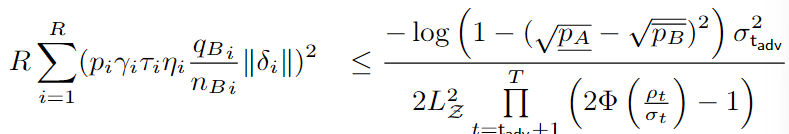
然后可证明鲁棒性成立:
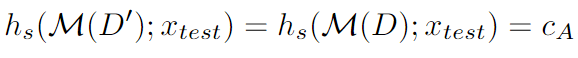
推理1 特征级鲁棒性条件:
对特征扰动的范围需要满足小于RAD,方能保证鲁棒性

引理1 Lipschitz 梯度常数:
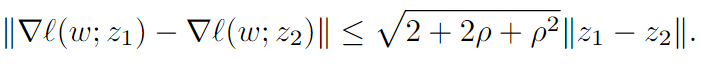
定理2 模型紧密度(KL散度):
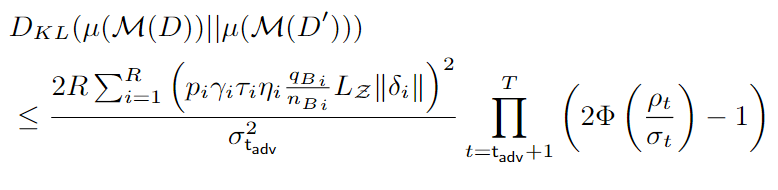
定理3 参数平滑上界
平滑后的参数w’与原来参数w之间的KL散度满足下列不等式,则模型是鲁棒的,即对于一个测试样本,最终预测的结果为类c是不变的。

6. 实验
给定半径r,在r点有两个评估指标。
**certified rate 可验证率:**表示可能存在后门攻击的分类器预测与干净的分类器预测有多一致。

**certified accuracy 可验证准确度:**对于部分测试集,后门攻击分类器与干净分类器做出一致预测与正确预测可能性。

-
相关阅读:
[数字信号处理]应用FFT计算线性卷积
Opencv高级图像处理
c语言练习:POJ 1003 宿醉(HangOver)
zemax---中英文名词对照表(持续更新中)
echarts优秀使用案例
HCIP之BGP的路由聚合
Redis为什么变慢了
银河麒麟V10 SP2 auditd服务内存泄露问题
5(6)-羧基四甲基罗丹明,CAS号:150347-56-1
2024抖音矩阵云混剪系统源码 短视频矩阵营销系统
- 原文地址:https://blog.csdn.net/qq_45724216/article/details/127842123