-
简单的小复习(一)
这里写目录标题
1.掌握手写二分查找的代码
步骤
1)数组排序
2 取中间值和目标值比较
3)再取中间值比较。。。。。。规范描述
1.前提:有已排序数组A
2.定义左边界L,右边界R 确定搜索范围,循环执行二分查找
3.获取中间索引M=Floor((L+R)/2)
4.中间索引A[M]与带搜索到值T进行比较
1)A[M]==T 找到 返回中间索引
2)A[M]>T 中间值右侧的其他元素都大于T无需比较。中间索引左边去找,M-1为右边界.重新查找 。
3)A[M]5.L>R表示没有找到,结束循环。 int l=0; //左边界 int r=arr.length-1; //右边界 where(l<=r) { n=(l+r)/2; if(arr[n]==t) { return n; }else if( a[n]>t) { r=n-1; }else { l=n+1; } } return -1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
问题:如何避免获取中间索引时整数溢出?(当元素特别多左右边界相加时整数溢出)
解决方法:
1.(l+r)/2 => l/2 +r/2=>l+(-l/2+r/2)=>l+(r-l)/2
2.(l+r)>>>1小练习


1.共有13个元素 中间是第7个 为31 48>31 在31右侧找
2 右侧6个元素 取中间靠左元素 45 45<48 在右侧找
3.右侧三个元素 取中间 49 在49左侧找
4.找到48
一直/2 一直到1 看除了几次 或 2的几次方是128冒泡排序
相邻两个元素比较,如果前一个元素大于后一个元素交换位置
描述:、
1.依次比较数组中相邻两个元素大小,若a[j]> a[j+1],则交换两个元素,两两都比较一遍称为一轮冒泡,结果是让最大的元素排至最后
2.重复以.上步骤,直到整个数组有序
for(int j=0;j<arr.length-1;j++) { for(int i =0;i<arr.length-1;i++) { if(arr[i]>arr[i+1]){ int t =arr[i] a[i] =a[i+1] a[i+1]=t } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
优化冒泡 每次冒泡完一轮后 最后面一次可以不用比较 逐级递减
for(int j=0;j<arr.length-1;j++) { for(int i =0;i<arr.length-1-j;i++) { if(arr[i]>arr[i+1]){ int t =arr[i] a[i] =a[i+1] a[i+1]=t } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
优化冒泡: 减少冒泡次数 可能在冒泡过程还没结束时 数组已经有序了 那么可以不用再往下进行循环
在每次冒泡之前 判断元素是否发生交换 不发生交换则说明已经有序for(int j=0;j<arr.length-1;j++) { boolean swapped =false; for(int i =0;i<arr.length-1-j;i++) { if(arr[i]>arr[i+1]){ int t =arr[i]; arr[i] =arr[i+1]; arr[i+1]=t; swapped =true; } } if(!swapped){ break; } System.out.println(Arrays.toString(arr)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
选择排序
刚开始所有元素均处于未排序状态中
我们要从未排序元素中的第一个元素开始和后面比较 取到最小的元素 然后和数组前面未排序的交换位置描述:
1.将数组分为两个子集,排序的和未排序的,每一轮从未排序的子集中选出最小的元素,放入排序子集2.重复以 上步骤,直到整个数组有序
for(int i =0 ; i<arr.length-1;i++) { //i 可以作为选择完最小元素需要交换到的目标下标 int s= i ;代表最小元素的小标 for(int j = s+1 ;j<arr.length; j++) { if(arr[s]>arr[j]) { s=j; } } if(s!=i) { int swap=0; swap = arr[i]; arr[i]=arr[s]; arr[s]=swap; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

冒泡排序 与选择排序比较
1.二者平均时间复杂度都是0(n2)
2.选择排序一般要快于冒泡,因为其交换次数少
3.但如果集合有序度高,冒泡优于选择
4.冒泡属于稳定排序算法,而选择属于不稳定排序插入排序
从未排序的元素中一个个取出来 插入到已排序的之中
描述
1.将数组分为两个区域,排序区域和未排序区域,每一轮从未排序区域中取出第一个元素,插入到排序区域(需保证顺序)
2.重复以上步骤,直到整个数组有序与选择排序比较
. 二者平均时间复杂度都是0(n2)
2.大部分情况下,插入都略优于选泽
3.有序集合插入的时间复杂度为0(n)
4.插入属于稳定排序算法,而选择属于不稳定排序for(int i =1;i<arr.length;i++) { int t =arr[i];//代表待插入元素值 int j =i-1;//代表已排序区域索引 while(j>=0){ if(t<arr[j]){ arr[j+1]=arr[j]; }else { break; } j--; } arr[j+1]=t; System.out.println(Arrays.toString(arr)); } } [5, 7, 6, 1, 5, 7, 4, 8] [5, 6, 7, 1, 5, 7, 4, 8] [1, 5, 6, 7, 5, 7, 4, 8] [1, 5, 5, 6, 7, 7, 4, 8] [1, 5, 5, 6, 7, 7, 4, 8] [1, 4, 5, 5, 6, 7, 7, 8] [1, 4, 5, 5, 6, 7, 7, 8]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
快速排序
每一轮排序选择一 个基准点(pivot) 进行分区
1.让小于基准点的元素的进入-一个分区,大于基准点的元素的进入另一一个分区
2.当分区完成时,基准点元素的位置就是其最终位置在子 分区内重复以上过程,直至子分区元素个数少于等于1,这体现的分而治之的思想(divide-and-conquer)

1.平均时间复杂度是 0(n log2n),最坏时间复杂度0(n2)
2.数据量较大时, 优势非常明显
3.属于不稳定排序单边循环
public static void main(String[] args) { int arr[] = {5,3,7,2,9,8,1,4}; // int a[] = {1, 2,, 3, 4, 5, 6, 7, 8, 9}; quick(arr,0,arr.length-1); } public static void quick(int arr[],int l,int h){ if(l>=h) { return; } int p = partition(arr, l, h); //第一次交换后基准点的索引值 quick(arr,l,p-1); //左边分区的范围确定 quick(arr,p+1,h); //右边分区的范围确定 } public static int partition(int arr[],int l,int h){ int pv =arr[h]; //取得基准点元素 int i =l; for(int j = i;j<h;j++){ if(arr[j]<pv){ int swap = arr[j]; arr[j]=arr[i]; arr[i]=swap; i++; } } //把基准点换到正确位置 int swap =arr[h]; arr[h]=arr[i]; arr[i]=swap; System.out.println(Arrays.toString(arr)); return i; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
双边循环
public static void main(String[] args) { int arr[] = {5,3,7,2,9,8,1,4}; // int a[] = {1, 2,, 3, 4, 5, 6, 7, 8, 9}; quick(arr,0,arr.length-1); } public static void quick(int arr[],int l,int h){ if(l>=h) { return; } int p = partition(arr, l, h); //第一次交换后基准点的索引值 quick(arr,l,p-1); //左边分区的范围确定 quick(arr,p+1,h); //右边分区的范围确定 } public static int partition(int arr[],int l,int h){ int pv =arr[l]; //取得基准点元素 int i=l; int j=h; while(i<j){ while (i<j&&arr[j]>pv){ //从右边向左找的 j--; //不做操作 急需向下走 如果找到的化则向下进行从左边找大的 } while(i<j&&arr[i]<=pv){ i++; } //右边找到小的 左边找到大的 进行交换 int swap =arr[j]; arr[j]=arr[i]; arr[i]=swap; } //交换基准点 int swap = arr[i]; arr[i]=arr[l]; arr[l]=swap; System.out.println(Arrays.toString(arr)); return j; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
什么是面向对象
对象,就是对问题中的事物的抽象
面向对象:
就是把现实中的事物都抽象为“对象”。每个对象是唯一的,且都可以拥有它的属性与行为。我们就可以通过调用这些对象的方法、属性去解决问题。它的三个基本特征:封装、继承、多态
封装:封装(encapsulation)即信息隐蔽。它是指在确定系统的某一部分内容时,应考虑到其它部分的信息及联系都在这一部分的内部进行,外部各部分之间的信息联系应尽可能的少。
四种访问控制级别
public:对外公开,访问级别最高
protected:只对同一个包中的类或者子类公开
默认:只对同一个包中的类公开
private:不对外公开,只能在对象内部访问,访问级别最低继承:让某个类型的对象获得另一个类型的对象的属性和方法。继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
多态:对于同一个行为,不同的子类对象具有不同的表现形式。
重载和重写的区别

接口和抽象类的区别

String StringBuffer StringBuilder的区别


JAVA 中的异常体系

Final 修饰符、


为什么局部内部类和匿名内部类只能访问局部final变量?

JDK JRE JVM三者的区别和联系


hashCode与equals

深拷贝和浅拷贝的区别

List和Set的区别

ArrayList
1.ArrayList的扩容机制
无参构造默认生成一个长度为零的数组 ,若使用add进行数组元素添加 第一次长度会扩容为10 之后每一次会在这个基础上扩容1.5倍
调用adaAll进行元素添加时,若数组中没有元素则会扩容为10或者元素的实际个数的长度的较大值,若数组中已经存在元素,则会扩容为原容量的1.5倍或者元素实际个数的较大值
每次扩容是生成一个新的数组 把原有元素放进扩容后的数组 然后原有的会被删除
2.掌握Iterator 的 fail-fast fail-safe 机制fail-fast:一旦发现遍历的同时其他人来修改,则立刻抛异常
整个过程中,iterator的指针只进行过一次定义,所以它的指针会保持为第一时的状态,然而在循环执行过程中,list集合发生了长度上的变动,所以对应的iterator指针也应该做相应的调整,因为物理位置发生了改变,但可惜的是,iterator还是保持第一次声明时的状态,所以这个时候iterator.next()指针所保持的物理地址已经不符合当前要求了,故会抛出java.util.ConcurrentModificationException该异常。02
fail-safe :发现遍历的同时其他人来修改,应当有应对策略,例如牺牲一致性来让整个遍历运行完成
CopyOnWriteArrayList替换ArrayList,就不会抛出异常。
fail-safe 集合中的所有对集合的修改都是先复制一个副本。然后在副本上进行。并不会在原来的集合中进行修改。并且这些修改方法都是加锁进行控制的

LinkedList
ArrayList 与 LinkedList 的比较

CopyonWriteArrayList

HashMap
HashMap底层数据结构是什么 1.7 与1.8有什么不同?
HashMap何时会扩容?
当元素个数达到数组长度的四分之三时会进行扩容
数组的容量都是2的n次幂
1.7 底层是数组+链表 1.8底层是数组 +(链表或红黑树) 元素比较多的时候使用红黑树 当元素少的时候使用链表




另一个答案



单例模式
单例模式 :一个类控制只有一个实例
1.饿汉式(类一加载就创建了单例对象)
1)构造方法私有
2) 提供一个静态的成员变量 成员变量的类型就是单例类的类型 值是用私有构造器创建都唯一实例
3)提供一个方法返回实例 供外部调用public class Singleton1 implements Serializable { //提供一个私有构造器 private Singleton1(){ } //在类内部创建一个实例 private static final Singleton1 INSTANCE = new Singleton1(); //提供一个方法供外部使用 public static Singleton1 getInstance(){ return INSTANCE; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
防止反射破坏单例可以在构造器加一个判断
public class Singleton1 implements Serializable { //提供一个私有构造器 private Singleton1(){ if(INSTANCE !=null){ throw new RuntimeException("单例对象不能重复创建"); } } //在类内部创建一个实例 private static final Singleton1 INSTANCE = new Singleton1(); //提供一个方法供外部使用 public static Singleton1 getInstance(){ return INSTANCE; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
防止序列化破坏单例可以 在类中写一个特殊的方法 readResolve
pulic Object readResolve (){ return INSTANCE; }- 1
- 2
- 3
2.懒汉式(调用生成实例方法才会生成实例 )
//提供一个私有构造器 private Singleton1(){ } //在类内部创建一个空实例 private static Singleton1 INSTANCE = null; //提供一个方法供外部使用时创建单例 public static Singleton1 getInstance(){ if(INSTANCE==null){ INSTANCE = new Singleton1(); } return INSTANCE; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这样多线程环境下不安全 需要加锁
public static synchronized Singleton1 getInstance(){ if(INSTANCE==null){ INSTANCE = new Singleton1(); } return INSTANCE; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
DCL( 双检索) 懒汉式(可以认为是对懒汉式的优化)
因为 上面的懒汉式加了锁 是每次调用时都会判断当前锁有没有被占用,但其实只有初始化实例时需要调用,所以这样会影响性能
需要加上volatile 修饰 //解决共享变量的 可见性,有序性 在这里是解决 有序性
private static volatile Singleton1 INSTANCE = null; public static Singleton1 getInstance() { if (INSTANCE == null) { synchronized (Singleton1.class) { if (INSTANCE == null) { INSTANCE = new Singleton1(); } } } return INSTANCE; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
内部类懒汉式 (不需要考虑线程安全问题)
public class Singleton1 implements Serializable { //提供一个私有构造器 private Singleton1() { } private static class Holder{ static Singleton1 INSTANCE = new Singleton1(); } public static Singleton1 getInstance(){ return Holder.INSTANCE; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
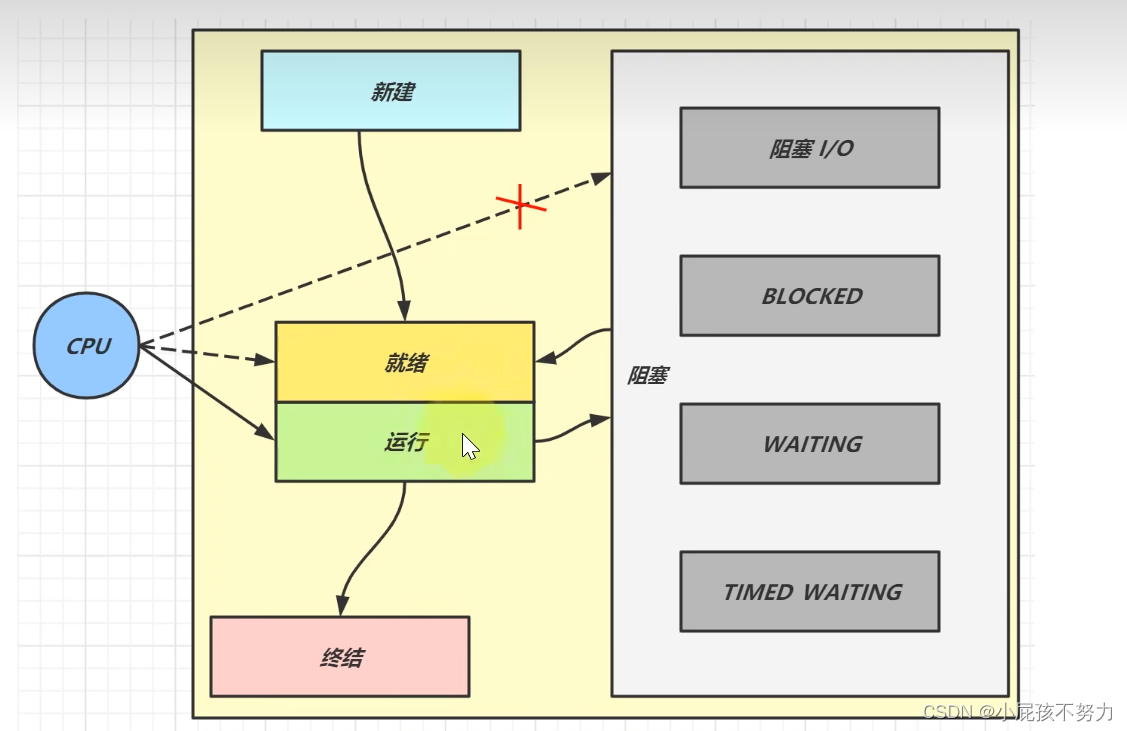
线程有哪些状态
JAVA线程分为六种状态
1)NEW 新建
2)RUNNABLE 可运行
3)TERMINATED 终结
4)BLOCKED 阻塞
5)WAITING 等待
6)TIMED_WAITING 等待(有时限)

操作系统层面共有五种状态
1.新建
2.就绪
3.运行
4.阻塞
5.终结
线程池的核心参数


sleep 和 wait的 异同点

lock 和 synchronized的对比

-
相关阅读:
零基础学Java(12)静态字段与静态方法
本质矩阵,基础矩阵,单应矩阵
VALSE2022天津线下参会个人总结8月22日-1
【服务器数据恢复】农科院某研究所DELL服务器raid5两块硬盘掉线的数据恢复
数据结构与算法之美学习笔记:17 | 跳表:为什么Redis一定要用跳表来实现有序集合?
Ae 动态图形模板
python+django医院设备综合管理系统vue363
北漂七年拿过阿里、腾讯、华为offer的资深架构师,分享经验总结
Linux上x86_64架构的动态链接器 ld-linux-x86-64.so.2
前端页面实现【矩阵表格与列表】
- 原文地址:https://blog.csdn.net/weixin_46427348/article/details/127699737
