-
大爷,快来玩呀!带禁手规则的五子棋实践强化学习理论
下载地址: https://github.com/wangjia184/renju
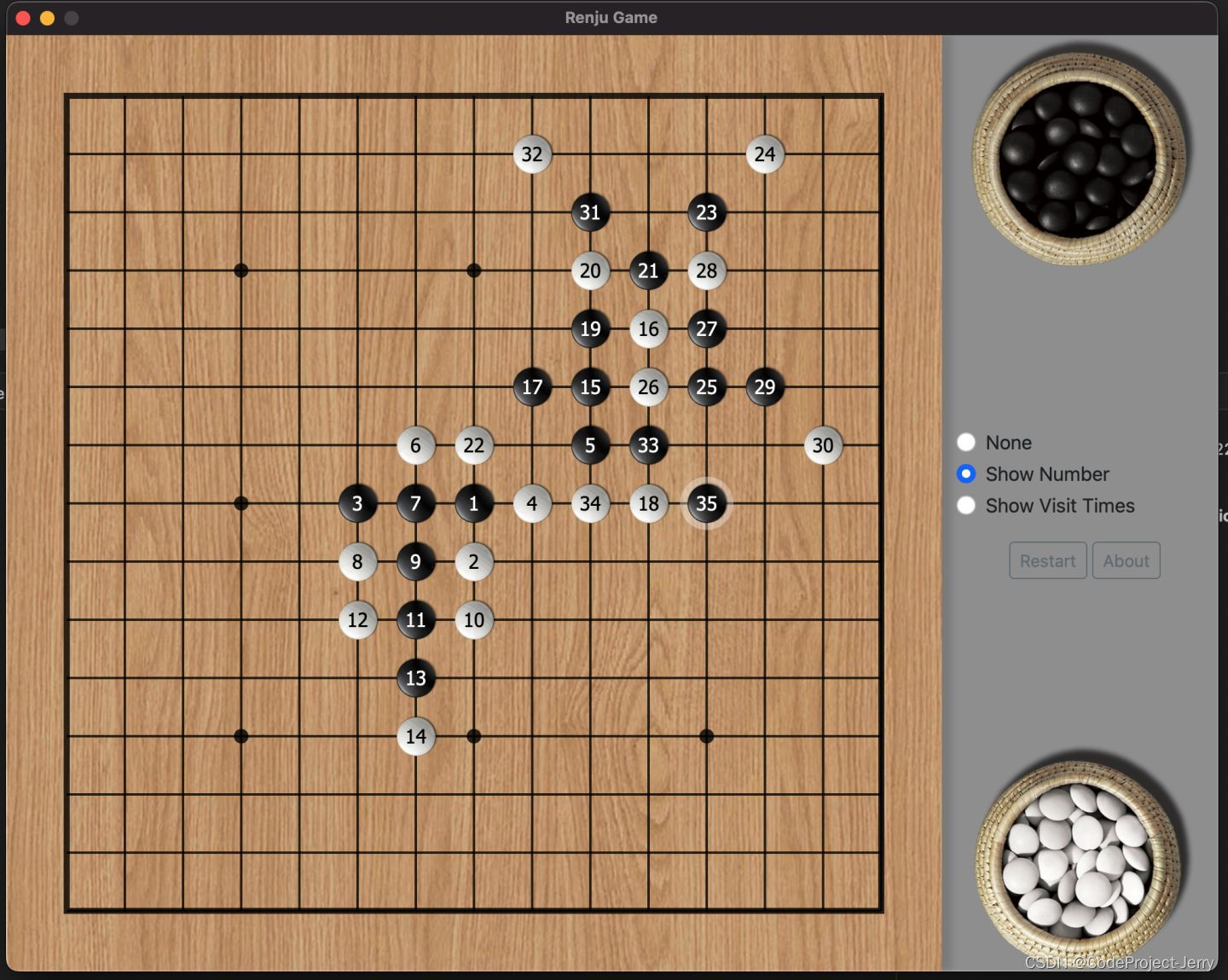
最近迷上了强化学习,自学理论时感觉非常抽象,所以做了个五子棋玩玩。程序可以到我的github(https://github.com/wangjia184/renju)仓库下载,棋力怎么样试试才知道。为了削弱黑棋的优势,实现了禁手规则。三三/四四/长连皆为输。
1.基本结构
这版本采用的是AlphaZero的思路。策略价值神经网络加蒙特卡洛树搜索。残差网络模块长度只有AlphaZero的一半;宽度也从256被缩水到了64。价值输出那的全连接层激活函数换成了ELU避免dying RELU问题。从我的测试来看,棋力还行。
2.性能
蒙特卡罗树搜索属于CPU密集型操作。由于Python的性能太差,而且GIL的存在导致实现并发非常麻烦,所以我采用Rust实现,这里不得不赞一句,用Rust既能获得媲美C++的性能,还具备非常好的内存安全性和线程安全性。越用越喜欢。
性能最大的挑战并不在training阶段,而是在selfplay阶段。因为此阶段每走一步都需要进行成百上千次的mcts迭代,而单次inference的阿姆达尔加速比并不大,我试过Mac M1的GPU甚至NPU,都比CPU慢。甚至还尝试过将多个并行的棋局inference合并到一个batch给GPU推理,发现效果并不理想。最后发现用量化+CPU方式反而是最快的方式。
Selfplay阶段采用ONNX Runtime的INT8量化,精度会有所下降,效果还行;人类对弈阶段用Tensorflow Lite+XNNPACK的FP16量化,精度下降基本可以忽略不记。
策略的优化速度很大程度上和价值迭代以及策略迭代的速度相关,所以优化selfplay可以大大加快速度。
在实现上,设计了一种创新型的lockless 树形结构,可以执行安全的多线程并发操作。Selfplay阶段并不需要用到并发,而human play阶段我发现tflite自带多线程加速单次inference。既然能够发挥硬件性能,所以最终的实现上并不需要用到并发搜索。
3.棋局多样性
SelfPlay阶段的棋局多样性至关重要。同一个batch中需要来自各种不同棋局的训练数据才能让noise相互抵消。所以每次selfplay都会同时使用26种开局,而对于每种开局又再创建20盘对弈。也就是说每轮selfplay同时有520盘对弈进行。
在这些棋局的开始阶段落子抽样算法中,dirichlet noise比重占到了50%,使开局阶段的棋局尽量充满变数。而随着棋局的进行,该比重逐步降低直到10%。
当这520盘对弈都完成后,将所有收集到的棋局都进行旋转/翻转/镜像等操作,数据倍增8x。再将这些训练数据彻底打乱,以5000为最大值组成一个个batch交给后面的training阶段。
而在和人类对弈杰顿,为了增加多变性和趣味性,程序最开始的几手棋会随机落子。
4.训练
训练阶段没有什么特别的,喂数据给tensorflow进行拟合。最初用过Mac M1的GPU,发现tensorflow的metal plugin有内存泄漏,还等着apple修复,所以后来换到了Intel 13700K + 128G RAM的机器上训练。是的,没有显卡(坚决不买30系矿卡),纯CPU训练。训练了大概4~5天吧,就是目前看到的样子。
接下来还打算试试其它的RL算法(比如DQN之类的)来实现五子棋。看着各种RL算法,我感觉刘姥姥进了大观园,挺有意思的。
-
相关阅读:
AWS Lambda从入门到精通
解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题
国债期货合约代码是什么字母
基于R语言的Copula变量相关性分析及应用
C++ Qt 开发:ListWidget列表框组件
多数据中心多活技术架构
JavaScript教程第一篇(作者原创)
Mobile App自动化测试技术及实现
Zookeeper安装及使用
与迭代次数有关的一种差值结构
- 原文地址:https://blog.csdn.net/wangjia184/article/details/127820503