-
Flink系列文档-(YY08)-Flink核心概念
1 核心概念
1.1 基础概念
- 用户通过算子api所开发的代码,会被flink任务提交客户端解析成jobGraph
- 然后,jobGraph提交到集群JobManager,转化成ExecutionGraph(并行化后的执行图)
- 然后,ExecutionGraph中的各个task会以多并行实例(subTask)部署到taskmanager上执行;
- subTask运行的位置是taskmanager所提供的槽位(task slot),槽位简单理解就是线程;
重要提示
- 一个算子的逻辑,可以封装在一个独立的task中(可以有多个运行时实例:subTask);
- 也可把多个算子的逻辑chain在一起后封装在一个独立的task中(可以有多个运行时实例:subTask);
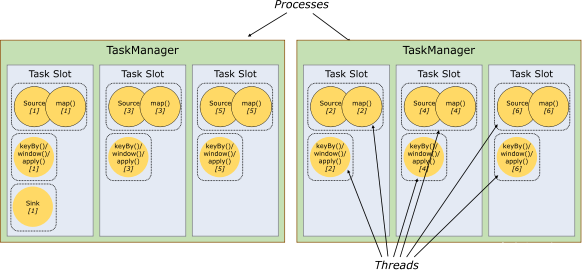
同一个task的不同运行实例,必须放在不同的task slot上运行;
同一个task slot,可以运行多个不同task的各一个并行实例;
1.2 task与算子链(operator chain)
上下游算子,能否chain在一起,放在一个Task中,取决于如下3个条件:
- 上下游算子实例间是oneToOne数据传输(forward);
- 上下游算子并行度相同;
- 上下游算子属于相同的slotSharingGroup(槽位共享组);
3个条件都满足,才能合并为一个task;否则不能合并成一个task;
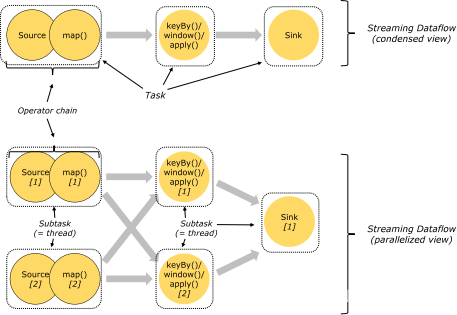
当然,即使满足上述3个条件,也不一定就非要把上下游算子绑定成算子链;
flink提供了相关的api,来让用户可以根据自己的需求,进行灵活的算子链合并或拆分;
- setParallelism 设置算子的并行度
- slotSharingGroup 设置算子的槽位共享组
- disableChaining 对算子禁用前后链合并
- startNewChain 对算子开启新链(即禁用算子前链合并)
单个并行演示
- package com.blok2;
- import org.apache.flink.configuration.Configuration;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- /**
- * @Date: 22.11.11
- * @Author: Hang.Nian.YY
- * @qq: 598196583
- * @Tips: 学大数据 ,到多易教育
- * @Description:
- */
- public class _01_Task_Chain {
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- conf.setInteger("rest.port", 8888);
- StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
- see.setParallelism(1);
- //1 加载数据流
- DataStreamSource
ds = see.socketTextStream("linux01", 50820); - System.out.println(ds.getParallelism()); //打印数据流的并行度
- //2 处理每条数据流
- SingleOutputStreamOperator
ds2 = ds.map(line -> line.toUpperCase()); - System.out.println(ds2.getParallelism()); //打印数据流的并行度
- //3 处理每条数据流
- SingleOutputStreamOperator
ds3 = ds2.map(line -> "YY-" + line + "-YY"); - ds3.print("结果数据流: ") ;
- see.execute("路虽远行则将至");
- }
- }
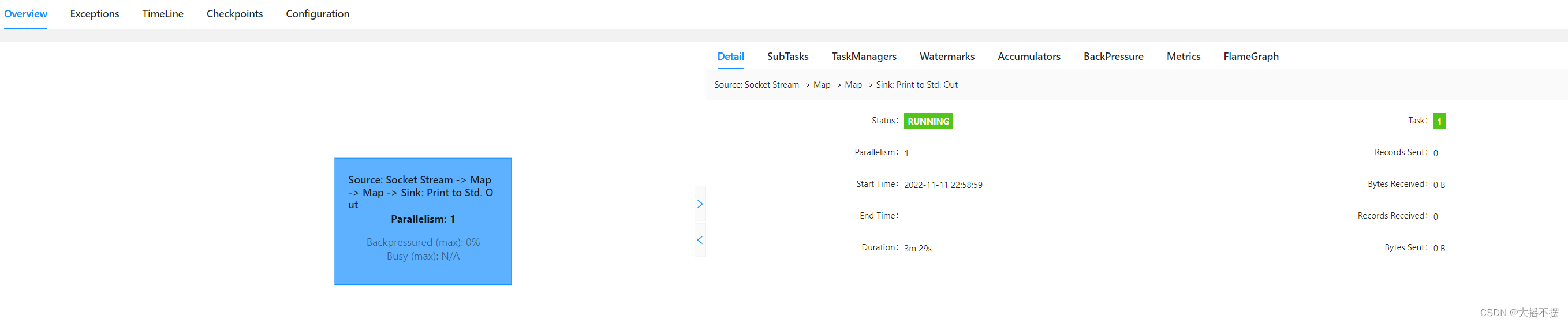
禁用自动算子链
//1 加载数据流 DataStreamSource
ds = see.socketTextStream("linux01", 50820); ds.disableChaining() ; //2 处理每条数据流 SingleOutputStreamOperator ds2 = ds.map(line -> line.toUpperCase()); ds2.disableChaining() ; //3 处理每条数据流 SingleOutputStreamOperator ds3 = ds2.map(line -> "YY-" + line + "-YY"); ds3.print("结果数据流: ") ; 
前后subTask并行度不同
see.setParallelism(1); //1 加载数据流 DataStreamSource
ds = see.socketTextStream("linux01", 50820); //2 处理每条数据流 SingleOutputStreamOperator ds2 = ds.map(line -> line.toUpperCase()); ds2.setParallelism(2) ; //3 处理每条数据流 SingleOutputStreamOperator ds3 = ds2.map(line -> "YY-" + line + "-YY"); ds3.print("结果数据流: ") ; see.execute("路虽远行则将至"); 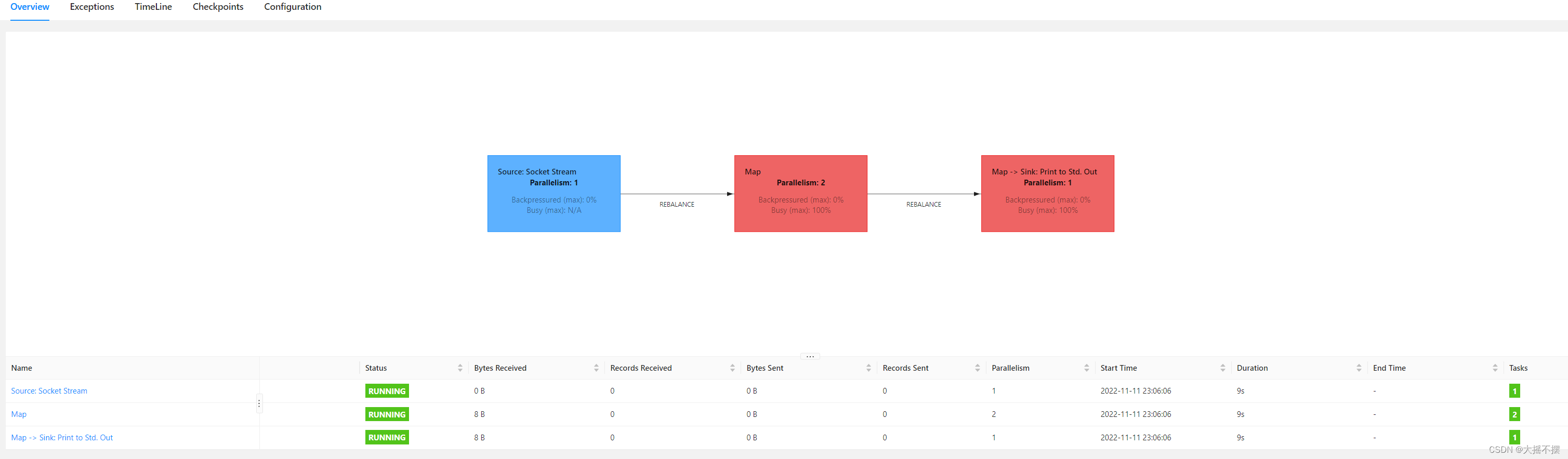
自动taskchain合并, 可以手动指定阶段taskchain
see.setParallelism(1); //1 加载数据流 DataStreamSource
ds = see.socketTextStream("linux01", 50820); //2 处理每条数据流 SingleOutputStreamOperator ds2 = ds.map(line -> line.toUpperCase()); ds2.startNewChain() ; //3 处理每条数据流 SingleOutputStreamOperator ds3 = ds2.map(line -> "YY-" + line + "-YY"); ds3.print("结果数据流: ") ; see.execute("路虽远行则将至"); 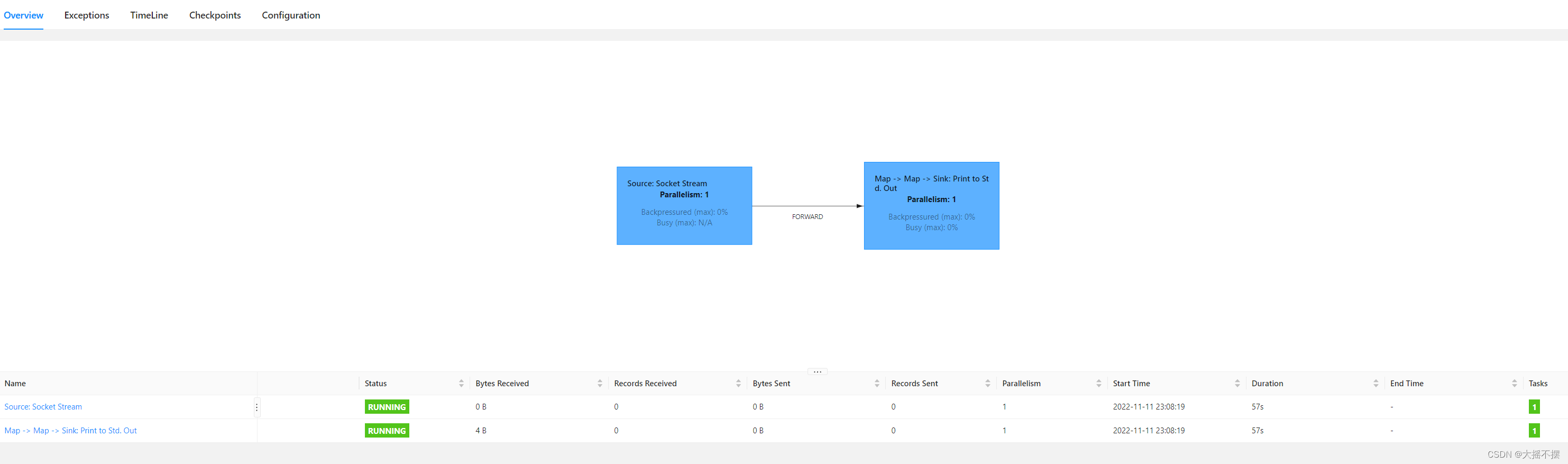
设置算子槽位共享组
see.setParallelism(1); /** * ds ds2 ds3 默认在同一个算子槽位共享组 自动合并taskchain * 三个source设置同一个算子槽位共享组 自动合并taskchain * ds2.slotSharingGroup("a") ; * * 三个source设置不同算子槽位共享组 自动合并taskchain */ //1 加载数据流 DataStreamSourceds = see.socketTextStream("linux01", 50820); ds.slotSharingGroup("a") ; //2 处理每条数据流 SingleOutputStreamOperator ds2 = ds.map(line -> line.toUpperCase()); ds2.slotSharingGroup("b") ; //3 处理每条数据流 SingleOutputStreamOperator ds3 = ds2.map(line -> "YY-" + line + "-YY"); ds3.slotSharingGroup("a") ; ds3.print("结果数据流: ") ; see.execute("路虽远行则将至"); 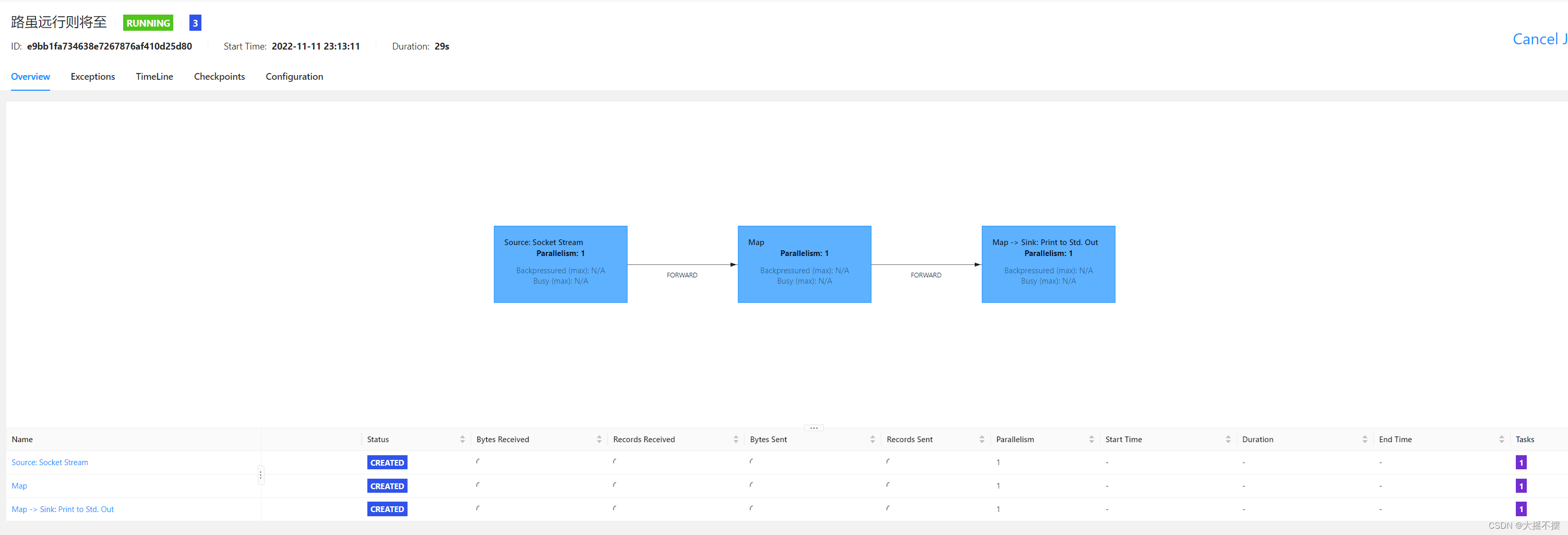
1.3 分区算子
分区算子:用于指定上游task的各并行subtask与下游task的subtask之间如何传输数据;
Flink中,对于上下游subTask之间的数据传输控制,由ChannelSelector策略来控制,而且Flink内针对各种场景,开发了众多ChannelSelector的具体实现

设置数据传输策略时,不需要显式指定partitioner,而是调用封装好的算子即可:

默认情况下,flink会优先使用REBALANCE分发策略
/** * @Date: 22.11.12 * @Author: Hang.Nian.YY * @qq: 598196583 * @Tips: 学大数据 ,到多易教育 * @Description: */ public class _02_Partition { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 8888); StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf); //1 加载数据流 DataStreamSourceds = see.socketTextStream("doitedu01", 50820); //2 处理每条数据流 SingleOutputStreamOperator ds2 = ds.map(line -> line.toUpperCase()) .setParallelism(2) //指定上游到下游分发数据的规则 .shuffle() .map(line -> "YY-" + line + "-YY") .setParallelism(3); ds2.print("结果数据流: "); see.execute("路虽远行则将至"); } }
-
相关阅读:
TCP协议与UDP协议
C++ 字面量
Oracle实现主键字段自增
DockerFile 文件详解、docker-maven-plugins的使用的使用
MySQL事务隔离与行锁的关系
AI绘画-Stable Diffusion三次元人物模型训练(炼丹)教程,你也可以定制你的三上youya老师!
企业虚拟化KVM的三种安装方式(1、完全文本2、模板镜像+配置文件3、gustos图形方式部署安装虚拟机)
暴雪退游,网易独行
《golang设计模式》第三部分·行为型模式-06-备忘录模式(Memento)
CS201 USB TYPEC音频控制芯片|TYPEC拓展坞音频芯片|CS201参数特性
- 原文地址:https://blog.csdn.net/qq_37933018/article/details/127814264
