-
基于Part Affinity Fields的姿态估计后处理笔记
openpose论文
paper and code: https://paperswithcode.com/paper/openpose-realtime-multi-person-2d-pose
Confidence Maps for Part Detection
在等式中评估fS(6)在训练过程中,我们从注释的二维关键点生成地面真实置信图S∗。每个置信图都是一个特定身体部位可以位于任何特定给定像素的二维表示。理想情况下,如果图像中出现一个人,如果对应的部分可见,则每个置信图中应该存在一个峰值;如果图像中有多个人,则每个人k应该有一个对应于每个可见部分j的峰值。
我们首先为每个人生成个体置信图。在位置P处的个体置信度为:
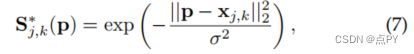
其中,σ控制着峰值的扩散。网络预测的基真置信图是通过最大算子对个体置信图的集合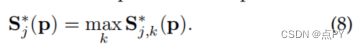
我们取置信图的最大值而不是平均值,以便附近峰值的精度保持不同,如右图所示。在测试时,我们预测置信图,并通过执行非最大抑制获得身体部分候选者。Part Affinity Fields for Part Association

给定一组被检测到的身体部位(如图5a中的红色和蓝色点所示),我们如何将它们组合起来,形成一个未知数量的人的全身姿势?我们需要对每一对身体部位检测的关联进行一个信心度量,也就是说,它们属于同一个人。测量这种关联的一种可能的方法是检测肢体上每对部分之间的一个额外中点,并检查候选部分检测之间的发生率,如图5b所示。然而,当人们聚集在一起时——正如他们很容易做的那样——这些中点很可能支持错误的关联(图5b中的绿线所示)。这种错误关联的产生是由于表征中的两个限制造成的: (1)它只编码每条肢体的位置,而不是方向;(2)它将一个肢体的支撑区域减少到一个单个点。
零件亲和字段(PAF)解决了这些限制。它们在肢体支撑区域的位置和方向信息(如图5c所示)。每个PAF都是每个肢体的二维向量场,也如图1d所示。对于属于一个特定肢体的区域中的每个像素,一个二维向量对从该肢体的一部分指向另一部分的方向进行编码。每一种类型的肢体都有一个相应的PAF,连接着它的两个相关的身体部位。
考虑下图中所示的一个肢体。设xj1,k和xj2,k是物体。如果一个点p位于肢体上,在L∗c,k §的值是一个点从j1到j2的单位向量;对于所有其他的点,这个向量都是零值的。
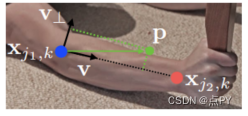
在训练期间,为了评估f_l等式6,我们定义了真值PAF,Lc_k,图上的点定义如下:
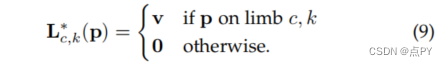
其中,v定义如下v = (X_j2_k - X_j1_k)/ || X_j2_k - X_j1_k||2
V是在肢体方向上的单位向量。肢体上的点集被定义为那些在线段的距离阈值内的点,即那些点p
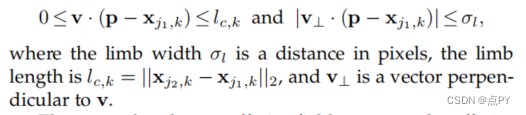
地面真值局部亲和场平均了图像中所有人的亲和场
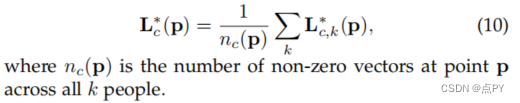
在测试过程中,我们通过计算沿着连接候选部分位置的线段上对应的PAF上的线积分来衡量候选部分检测结果之间的关联。换句话说,我们测量了预测的PAF与通过连接被检测到的身体部位而形成的候选肢体的对齐情况。特别地,对于两个候选部分位置d_j1和d_j2,我们采样预测的部分亲和场,L_c沿着线段来衡量对他们的关联的置信度,
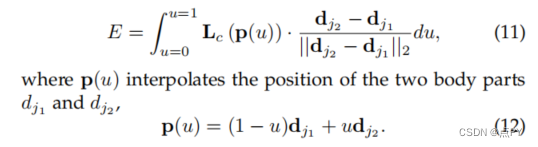
在实际应用中,我们通过对u的均匀间隔值进行采样和求和来近似积分。
代码解析
参考代码:https://github.com/Daniil-Osokin/lightweight-human-pose-estimation.pytorch
关键点提取
def extract_keypoints(heatmap, all_keypoints, total_keypoint_num): heatmap[heatmap < 0.1] = 0 heatmap_with_borders = np.pad(heatmap, [(2, 2), (2, 2)], mode='constant') heatmap_center = heatmap_with_borders[1:heatmap_with_borders.shape[0]-1, 1:heatmap_with_borders.shape[1]-1] heatmap_left = heatmap_with_borders[1:heatmap_with_borders.shape[0]-1, 2:heatmap_with_borders.shape[1]] heatmap_right = heatmap_with_borders[1:heatmap_with_borders.shape[0]-1, 0:heatmap_with_borders.shape[1]-2] heatmap_up = heatmap_with_borders[2:heatmap_with_borders.shape[0], 1:heatmap_with_borders.shape[1]-1] heatmap_down = heatmap_with_borders[0:heatmap_with_borders.shape[0]-2, 1:heatmap_with_borders.shape[1]-1] heatmap_peaks = (heatmap_center > heatmap_left) &\ (heatmap_center > heatmap_right) &\ (heatmap_center > heatmap_up) &\ (heatmap_center > heatmap_down) heatmap_peaks = heatmap_peaks[1:heatmap_center.shape[0]-1, 1:heatmap_center.shape[1]-1] keypoints = list(zip(np.nonzero(heatmap_peaks)[1], np.nonzero(heatmap_peaks)[0])) # (w, h) keypoints = sorted(keypoints, key=itemgetter(0)) suppressed = np.zeros(len(keypoints), np.uint8) keypoints_with_score_and_id = [] keypoint_num = 0 for i in range(len(keypoints)): if suppressed[i]: continue for j in range(i+1, len(keypoints)): if math.sqrt((keypoints[i][0] - keypoints[j][0]) ** 2 + (keypoints[i][1] - keypoints[j][1]) ** 2) < 6: suppressed[j] = 1 keypoint_with_score_and_id = (keypoints[i][0], keypoints[i][1], heatmap[keypoints[i][1], keypoints[i][0]], total_keypoint_num + keypoint_num) keypoints_with_score_and_id.append(keypoint_with_score_and_id) keypoint_num += 1 all_keypoints.append(keypoints_with_score_and_id) return keypoint_num- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
基于PAF的关键点配对
这个过程比较复杂,大致可以分为以下几个步骤:
-
获取所有关键点之间的向量,即潜在的肢体向量;
-
沿着肢体向量进行等间距采样;
-
计算潜在肢体向量和部分亲和场之间的亲和分数,这里需要用到下面这个公式;
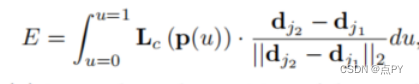
-
根据亲和分数来获得肢体列表;
-
抑制不匹配的肢体。
def group_keypoints_apple(all_keypoints_by_type, pafs, pose_entry_size=20, min_paf_score=0.05): pose_point = [] all_keypoints = np.array([item for sublist in all_keypoints_by_type for item in sublist]) points_per_limb = 10 grid = np.arange(points_per_limb, dtype=np.float32).reshape(1, -1, 1) all_keypoints_by_type = [np.array(keypoints, np.float32) for keypoints in all_keypoints_by_type] part_id = 0 part_pafs = pafs kpts_a = all_keypoints_by_type[BODY_PARTS_KPT_IDS_APPLE[part_id][0]] kpts_b = all_keypoints_by_type[BODY_PARTS_KPT_IDS_APPLE[part_id][1]] n = len(kpts_a) m = len(kpts_b) if n == 0 or m == 0: return pose_point # Get vectors between all pairs of keypoints, i.e. candidate limb vectors. a = kpts_a[:, :2] a = np.broadcast_to(a[None], (m, n, 2)) b = kpts_b[:, :2] vec_raw = (b[:, None, :] - a).reshape(-1, 1, 2) # Sample points along every candidate limb vector. steps = (1 / (points_per_limb - 1) * vec_raw) points = steps * grid + a.reshape(-1, 1, 2) points = points.round().astype(dtype=np.int32) x = points[..., 0].ravel() y = points[..., 1].ravel() # Compute affinity score between candidate limb vectors and part affinity field. field = part_pafs[y, x].reshape(-1, points_per_limb, 2) vec_norm = np.linalg.norm(vec_raw, ord=2, axis=-1, keepdims=True) vec = vec_raw / (vec_norm + 1e-6) affinity_scores = (field * vec).sum(-1).reshape(-1, points_per_limb) valid_affinity_scores = affinity_scores > min_paf_score valid_num = valid_affinity_scores.sum(1) affinity_scores = (affinity_scores * valid_affinity_scores).sum(1) / (valid_num + 1e-6) success_ratio = valid_num / points_per_limb # Get a list of limbs according to the obtained affinity score. valid_limbs = np.where(np.logical_and(affinity_scores > 0, success_ratio > 0.7))[0] if len(valid_limbs) == 0: return pose_point if len(valid_limbs) == 1: valid_limbs = valid_limbs else: success_ratio_ = success_ratio[valid_limbs] arr_success_ratio = np.array(success_ratio_) valid_limbs = np.array([valid_limbs[np.argmax(arr_success_ratio)]]) b_idx, a_idx = np.divmod(valid_limbs, n) affinity_scores = affinity_scores[valid_limbs] # Suppress incompatible connections. a_idx, b_idx, affinity_scores = connections_nms(a_idx, b_idx, affinity_scores) connections = [kpts_a[a_idx, 3].astype(np.int32), kpts_b[b_idx, 3].astype(np.int32)] pose_point = [all_keypoints[connections[0]].squeeze()[:2], all_keypoints[connections[1]].squeeze()[:2]] return pose_point- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
-
相关阅读:
名词解释 MongoDB
K8S原来如此简单(八)ServiceAccount+RBAC
项目如何实现富文本框文件上传
一文看懂单总线协议(1-wire)
Zookeeper的ZAB协议原理详解
看看GPT-4V是怎么开车的,必须围观,大模型真的大有作为 | 万字长文
HTTP协议(超级详细)
流量攻击:如何有效利用网络漏洞
【使用VS开发的第一个QT项目——实现相机功能(包括QT下载、配置、摄像头程序)】
968. 监控二叉树
- 原文地址:https://blog.csdn.net/weixin_42990464/article/details/127803355
