-
大数据-hadoop环境安装(集群)
本伪分布式是在vmware上建立的
1、安装概述
安装流程:
节点结构:

2、准备环境
操作系统:centos7
master:192.168.73.31
slave1:192.168.73.32
slave2:192.168.73.33
JDK版本:java-1.8.0-openjdk-devel.x86_64
hadoop版本:hadoop-3.3.1.tar.gz
3、配置机器名称和IP
修改主机名称和IP地址信息,分别将3台虚拟机主机名称修改为master、slave1、slave2

IP地址信息如下:
分别将master机器对应的IP修改为:192.168.73.31
将slave1机器对应的IP修改为:192.168.73.32
将slave2机器对应的IP修改为:192.168.73.33

所有配置修改好,需要将虚拟机重启,才有效果,执行reboot命令
操作命令如下:
- hostname #查看机器名称
- vim /etc/hostname #修改机器名称的配置文件
- vim /etc/sysconfig/network-scripts/ifcfg-ens33 #修改机器IP地址信息
- #IP地址信息如下:
- TYPE=Ethernet
- PROXY_METHOD=none
- BROWSER_ONLY=no
- BOOTPROTO=static
- DEFROUTE=yes
- IPV4_FAILURE_FATAL=no
- IPV6INIT=yes
- IPV6_AUTOCONF=yes
- IPV6_DEFROUTE=yes
- IPV6_FAILURE_FATAL=no
- IPV6_ADDR_GEN_MODE=stable-privacy
- NAME=ens33
- UUID=2beef6cf-0c31-4730-86fe-674429167de8
- DEVICE=ens33
- ONBOOT=yes
- IPADDR=192.168.73.31
- GATEWAY=192.168.73.2
- NETMASK=255.255.255.0
- DNS1=192.168.73.2
修改3台机器上的/etc/hosts配置文件,添加如下信息
- 192.168.73.31 master
- 192.168.73.32 slave1
- 192.168.73.33 slave2

配置好之后,3台机器相互ping,如果互通,则配置正常 ping + 机器名称
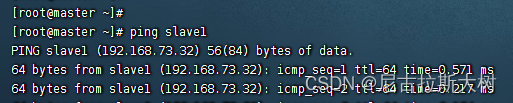
4、设置免密登录
1.在master上生成公钥
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次)
- cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
- rm ./id_rsa* # 删除之前生成的公匙(如果有)
- ssh-keygen -t rsa # 一直按回车就可以、
- cat ./id_rsa.pub >> ./authorized_keys #让 Master 节点需能无密码 SSH 本机

完成后可执行
ssh Master验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到s1子节点:
模板:scp ~/.ssh/id_rsa.pub 用户名@子节点名字:/home/hadoop/
在子节点上,去创建hadoop目录,然后再主节点上执行传输公钥的命令
- #子节点上执行
- cd /home
- mkdir hadoop
- #在主节点上执行
- scp ~/.ssh/id_rsa.pub root@slave1:/home/hadoop/
- scp ~/.ssh/id_rsa.pub root@slave2:/home/hadoop/

2 在子节点上操作
分别在子节点执行下面的命令,将 ssh 公匙加入授权:
- mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
- cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
- rm ~/id_rsa.pub # 用完就可以删掉了
5、检验主节点是否可以免密登录子节点
在主节点上执行:ssh 子节点名字
exit //登出ssh s1
不输入密码登录就代表成功。
6、安装和配置JDK环境变量
安装jdk,配置jdk环境变量
- which java
- ls -lrt /usr/bin/java
- ls -lrt /etc/alternatives/java

- #安装jdk
- yum install java-1.8.0-openjdk-devel.x86_64
- #配置Java环境变量
- vim /etc/profile
- #在profile文件里添加如下内容
- export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64/jre
- export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib
- export PATH=$PATH:$JAVA_HOME/bin
- #使其生效
- source /etc/profile
7、安装Hadoop
- 在master上切换到/usr/local目录,下载并解压hadoop 3.3.1.tar.gz(是已经编译好的)
- wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- tar -xzvf hadoop-3.3.1.tar.gz
主节点与节点都要安装和修改配置,操作和配置文件的内容都是一致的
1.配置hadoop-env.sh
去到刚才解压的文件夹里,进入到/etc/hadoop下,编辑hadoop-env.sh文件最下面,写入并保存:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64/jre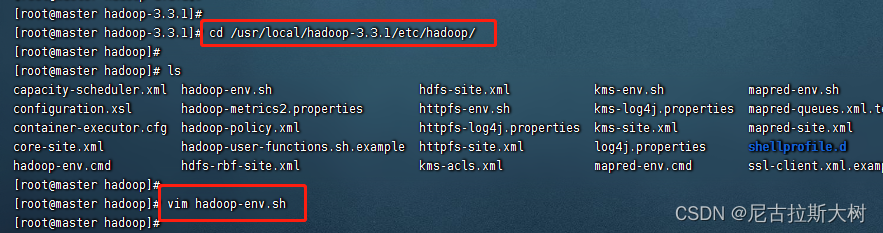
2.编辑core-site.xml文件
注意:三台机器上的core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml的配置内容要完全一致,地址全部都是master,不因分机而改变host名
在节点内加入配置 - <configuration>
- <property>
- <name>hadoop.tmp.dirname>
- <value>/root/hadoop/tmpvalue>
- <description>Abase for other temporary directories.description>
- property>
- <property>
- <name>fs.default.namename>
- <value>hdfs://master:9000value>
- property>
- configuration>
3.配置hdfs-site.xml
在- <property>
- <name>dfs.name.dirname>
- <value>/root/hadoop/dfs/namevalue>
- <description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.description>
- property>
- <property>
- <name>dfs.data.dirname>
- <value>/root/hadoop/dfs/datavalue>
- <description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.description>
- property>
- <property>
- <name>dfs.replicationname>
- <value>2value>
- property>
- <property>
- <name>dfs.permissionsname>
- <value>truevalue>
- <description>need not permissionsdescription>
- property>
- <property>
- <name>dfs.namenode.http-addressname>
- <value>master:9870value>
- property>
4.配置mapred-site.xml
在- <property>
- <name>mapred.job.trackername>
- <value>master:49001value>
- property>
- <property>
- <name>mapred.local.dirname>
- <value>/root/hadoop/varvalue>
- property>
- <property>
- <name>mapreduce.framework.namename>
- <value>yarnvalue>
- property>
5.配置yarn-site.xml
在- <property>
- <name>yarn.resourcemanager.hostnamename>
- <value>mastervalue>
- property>
- <property>
- <description>The address of the applications manager interface in the RM.description>
- <name>yarn.resourcemanager.addressname>
- <value>${yarn.resourcemanager.hostname}:8032value>
- property>
- <property>
- <description>The address of the scheduler interface.description>
- <name>yarn.resourcemanager.scheduler.addressname>
- <value>${yarn.resourcemanager.hostname}:8030value>
- property>
- <property>
- <description>The http address of the RM web application.description>
- <name>yarn.resourcemanager.webapp.addressname>
- <value>${yarn.resourcemanager.hostname}:8088value>
- property>
- <property>
- <description>The https adddress of the RM web application.description>
- <name>yarn.resourcemanager.webapp.https.addressname>
- <value>${yarn.resourcemanager.hostname}:8090value>
- property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.addressname>
- <value>${yarn.resourcemanager.hostname}:8031value>
- property>
- <property>
- <description>The address of the RM admin interface.description>
- <name>yarn.resourcemanager.admin.addressname>
- <value>${yarn.resourcemanager.hostname}:8033value>
- property>
- <property>
- <name>yarn.nodemanager.aux-servicesname>
- <value>mapreduce_shufflevalue>
- property>
- <property>
- <name>yarn.scheduler.maximum-allocation-mbname>
- <value>2048value>
- <discription>每个节点可用内存,单位MB,默认8182MBdiscription>
- property>
- <property>
- <name>yarn.nodemanager.vmem-pmem-rationame>
- <value>2.1value>
- property>
- <property>
- <name>yarn.nodemanager.resource.memory-mbname>
- <value>2048value>
- property>
- <property>
- <name>yarn.nodemanager.vmem-check-enabledname>
- <value>falsevalue>
- property>
6.修改workers
在master节点的workers文件内把localhost删除(与这些配置文件在同一个目录下),加入- slave1
- slave2
保存
在slave1节点的workers文件内把localhost删除,加入- master
- slave2
保存
在slave2节点的workers文件内把localhost删除,加入- master
- slave1
7.在/root下新增如下目录
- mkdir /root/hadoop
- mkdir /root/hadoop/tmp
- mkdir /root/hadoop/var
- mkdir /root/hadoop/dfs
- mkdir /root/hadoop/dfs/name
- mkdir /root/hadoop/dfs/data
八、初始化
也即格式化,在master节点进入到/usr/local/hadoop-3.3.1/bin目录然后执行
./hadoop namenode -format九、启动hadoop
切换到目录/usr/local/hadoop-3.2.1/sbin
在start-dfs.sh 、stop-dfs.sh两个文件开头位置添加如下配置- HDFS_DATANODE_USER=root
- HADOOP_SECURE_DN_USER=root
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh 、stop-yarn.sh两个文件开头位置添加如下配置
- YARN_RESOURCEMANAGER_USER=root
- HADOOP_SECURE_DN_USER=root
- YARN_NODEMANAGER_USER=root
或者在/etc/profile文件下添加
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
- export YARN_RESOURCEMANAGER_USER=root
- export YARN_NODEMANAGER_USER=root
在/usr/local/hadoop-3.2.1/sbin下,执行
./start-all.sh使用浏览器访问192.168.73.31:9870(主节点服务器),可以进入到overview界面

访问resourcemanager http://192.168.73.31:8088/cluster
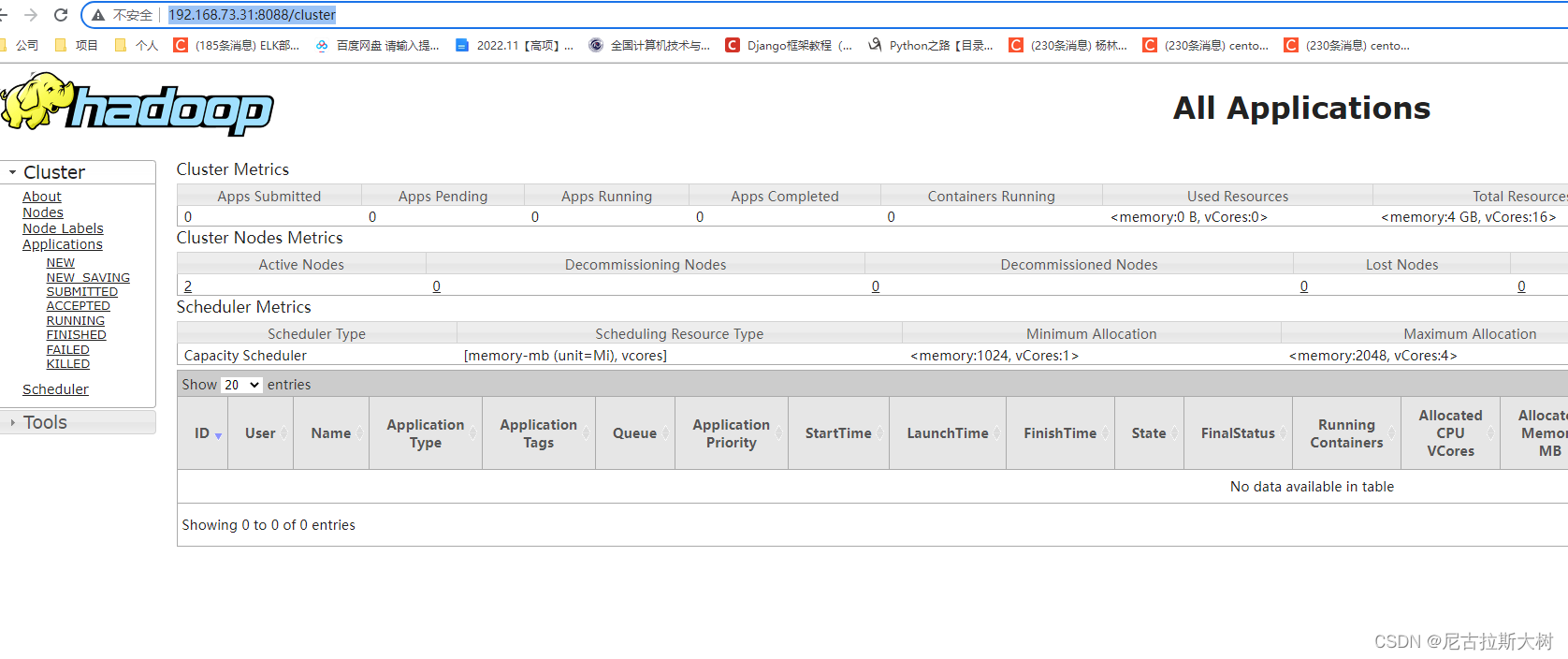
注意:如果不能访问,请检查防火墙是否关闭或者端口是否开发
-
相关阅读:
@SpringBootApplication 注解报红
沉睡者IT - 十月之后「牛市」还是「熊市」
Hexo+Github 快速搭建个人博客
【c++百日刷题计划】 ———— DAY10,奋战百天,带你熟练掌握基本算法
Java面试题及答案整理(2022最新版)
PCI Pharma Services宣布斥资数百万美元扩建英国制造设施,以满足市场对支持肿瘤治疗的全球高效药制造服务日益增长的需求
金融量化项目案例 -- 双均线策略制定
让你秒读懂阿里云数据库架构与选型
SpringBoot——SpringBoot访问外部接口
Vulnhub: Ragnar Lothbrok: 1靶机
- 原文地址:https://blog.csdn.net/weixin_42109071/article/details/127785333
