-
【python】批量高速获取 Instagram,一个简单的外国分享网站
前言
嗨喽~大家好呀,这里是魔王呐 !

Instagram(照片墙)是一款运行在移动端上的社交应用,以一种快速、美妙和有趣的方式将你随时抓拍下的图片彼此分享,Facebook公司旗下社交应用
本篇文章主要是如何“批量高速获取”Instagram里的视频
环境使用
-
Python 3.8
-
Pycharm
主要模块使用
- requests
代码编写
请求网站
url = 'https://www.instagram.com/graphql/query/?query_hash=69cba40317214236af40e7efa697781d&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22QVFDNFFmNWtjVWptaHNHN2Fhd21hdlFOQ1BMbDZQeHMzSVczMnl6T2dUN2U3YU5kYm9jZW1rYXgtUHlyQ0xMS2tjRm9iLXp2WG5Zb2NWSE9LR3laRU9zTw%3D%3D%22%7D' headers = { 'cookie': 'mid=Yr_f0AALAAGON2Eshq1-xqSrwgYv; ig_did=171E68A6-7132-4DE4-BE07-0B21352CE315; ig_nrcb=1; csrftoken=nZWluAdEtRyverD04rZECJdTTpqFUM2v; ds_user_id=53914138896; sessionid=53914138896%3AdSQkczPUqeBlKA%3A0%3AAYdUZgBloqRamafNmehfod2vBZQXVdLGvL66lV55qw; datr=CeW_YlRjzoVC-Kv6Yvqrnda3; fbm_124024574287414=base_domain=.instagram.com; fbsr_124024574287414=44mb43B3CsveUJD_NWVjypxL1Mg5HzmaboYwdPBSOhE.eyJ1c2VyX2lkIjoiMTAwMDgzMDk4MzUzNDY2IiwiY29kZSI6IkFRRFRBSlBZdjJsR294SFpqQ1lTYmhwMUFUYVFCb3JXODhVbVBYX3VHTmR3MEYzNV9wMWtYWGdjenlVQXhxbnJuNTBEMWhIeWVJVVJFc2xhZ0NkY0NBNkwzd3FuWHAxYnphMUlPNTVZbFhVWnRGdndsRGtKRGlaejBNV1kyMS11Y1l6YUY5RmhNeGtTdjUxdU9DZDNKczA5bVZKSUQ3am13ZVB6R1FOVEY5am52bU1KZFBWbGpBTlE0QkNURWduSzBLM3ZnWUpBa0IxRFhTN21hN1VLSTVLU24yYzN4LVZpWk1hNWx0c25hNlhmNEJRMXhqVTdvNTIzQjVIcDhjRnRDNzlGZi1BSjYyeUVQM29XOVhuSk1ybndxa3R0SmVCbWl1aUpkSl9PZ1NpVGxiVmxBcFMwNS1nMlFoRHlDbjJObUlPTDdRYnI4M1dxWWNSajNIbmw3WlQwIiwib2F1dGhfdG9rZW4iOiJFQUFCd3pMaXhuallCQUZRMzFSWkJwVFZxTThKTVhOaEowUldGZDg3M3V3QUhPOFNLWkNuNHg5S3NHbWNydzRrZDJaQlpBb2pxUVgwdk5rMXFrWkN3WkJwNm9udmhSR1RwMjhXVlpDZ01yYzNGTlpBNFpBcHkxTG1wWTE5TkNKQnNHNHRLRGZpOUFScVlHdm9BWkF0UjVTZzZseG01Z1Y5cjRQdEo4blBmMEZaQ3R3eGpZTUJDQXZuZExTR2Jhem91d0l1cUVzWkQiLCJhbGdvcml0aG0iOiJITUFDLVNIQTI1NiIsImlzc3VlZF9hdCI6MTY1Njc0NDExN30; fbsr_124024574287414=8U6nJaZd9v_-yN9_pOuM_f85VO9MnOh9wKtVnck79GI.eyJ1c2VyX2lkIjoiMTAwMDgzMDk4MzUzNDY2IiwiY29kZSI6IkFRRGVyQ1dDNzlzWHFoN2VPYkVGNDkyZlBrMHg0b0dVaWRHeFJmWHU0clpsNGVncDRlTVhvVVJUM1hpbk9uSnJPRkZmRXBIR1hNd2I0M2hnRDF5VzZvYUg0Zjg3MVFqc1BSVURtT2RNcURaNDRZcENPWnlPRzllbzNkSjNzYS1IbnBCUlRmSy1tN3o3QWQxZ0d0UlItcnJ5V1d2djM3emxKYmJfQmxvNXVfT3EtV2pZWjdXZnVKOG1PLWMwTWlhdzB6RE1ZZmo0VFhoRXJuQTBfblJ4QWszMFlqR3JUSTVXd0J0VkExT25SMEZPSHZZa0RqTC1KYS1CLVpydG9IaHE4dFVSLXNNQVNlNW1lb0lyQ2NGZndBSm1uZmxkRnl1b2UxMGs0ejROdlA4cVd0RGd4ZzRnLWJCbGtid2FBcUhaRGZZOEI1UXo0T3dxdmhoV3dSS1psZVJHIiwib2F1dGhfdG9rZW4iOiJFQUFCd3pMaXhuallCQUhiQzR2TU9aQnF1T25FcVA2RU13N3lEYkZaQXpnQkRCQlNqbU1aQXdZU2FaQjVGZEJXWkFXMDBiVG13U0Z1SFd4b2VIalIyOWhDRHA4TExaQW9EODN3UDZmbGdKSjlzelpCQVJqQVJOV1ZtVlR4WkI3TUVNNXpNN3NaQXFzcEVmVVFYb3V5NXF1NDU3ak52UGl2N3hhQmtjWkJLWkE1dXhEYUlJZUtYOGk5cFJoa2dxNUNqM2gyWkJLWVpEIiwiYWxnb3JpdGhtIjoiSE1BQy1TSEEyNTYiLCJpc3N1ZWRfYXQiOjE2NTY3NDQxMTd9; rur="EAG\05453914138896\0541688280184:01f7fbbf803c04403c41e92677764cf18d5c012e079a4cfd0d7b94107375e93be9e6b7fe"', 'referer': 'https://www.instagram.com/instagram/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36', 'viewport-width': '2560', 'x-asbd-id': '198387', 'x-csrftoken': 'nZWluAdEtRyverD04rZECJdTTpqFUM2v', 'x-ig-app-id': '936619743392459', 'x-ig-www-claim': 'hmac.AR1Do_jGsh-QtK6YpzVBvUI6Fb_1qQ7SzZYlfrdsTz3TLjUH', 'x-requested-with': 'XMLHttpRequest', } response = requests.get(url=url, headers=headers, verify=False)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
返回数据
print(response.json())- 1
解析数据
for index in response.json()['data']['user']['edge_owner_to_timeline_media']['edges']: try: video_id = index['node']['id'] print(video_id) link = f'https://i.instagram.com/api/v1/media/{video_id}/info/' json_data = requests.get(url=link, headers=headers).json() # pprint.pprint(json_data) video_url = json_data['items'][0]['video_versions'][0]['url'] # 获取二进制数据内容 video_content = requests.get(url=video_url, headers=headers).content except: pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
保存数据
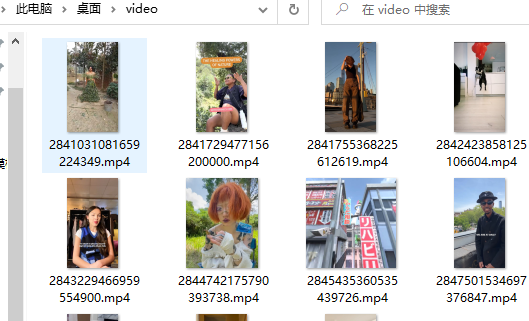
with open('video\\' + video_id + '.mp4', mode='wb') as f: f.write(video_content)- 1
- 2
效果展示

推荐往期文章
🎯 博主所有文章素材、解答、源码领取处:点击
对python感兴趣的小伙伴也可以看一下博主其他相关文章哦~
python小介绍:
python是什么?工作前景如何?怎么算有基础?爬数据违法嘛?。。
python数据分析前景:
用python分析“数据分析”到底值不值得学习,以及学完之后大概能拿到多少工资
python基础自测题:
最后推荐一套Python视频给大家,希望对大家有所帮助:
尾语
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝
-
-
相关阅读:
Linux 了解DHCP服务及如何操作
uni-app中vue3+setup实现下拉刷新、上拉加载更多效果
防火墙实验一
Kubernetes 使用 containerd 做为 CRI
编码踩坑——多线程可能带来意想不到的OOM
入门Python编程:了解计算机语言、Python介绍和开发环境搭建
WordPress主题DUX v8.2源码下载
恋爱脑学Rust之dyn关键字的作用
计算机网络基础 IP头部报文;IP的分片;
Chrome 浏览器关闭后再打开,需要重新登录账号,解决办法
- 原文地址:https://blog.csdn.net/python56123/article/details/127787092