-
Ceph — 架构
Ceph 架构
Ceph是统一存储系统,支持三种接口。
- Object:有原生的API,而且也兼容Swift和S3的API
- Block:支持精简配置、快照、克隆
- File:Posix接口,支持快照
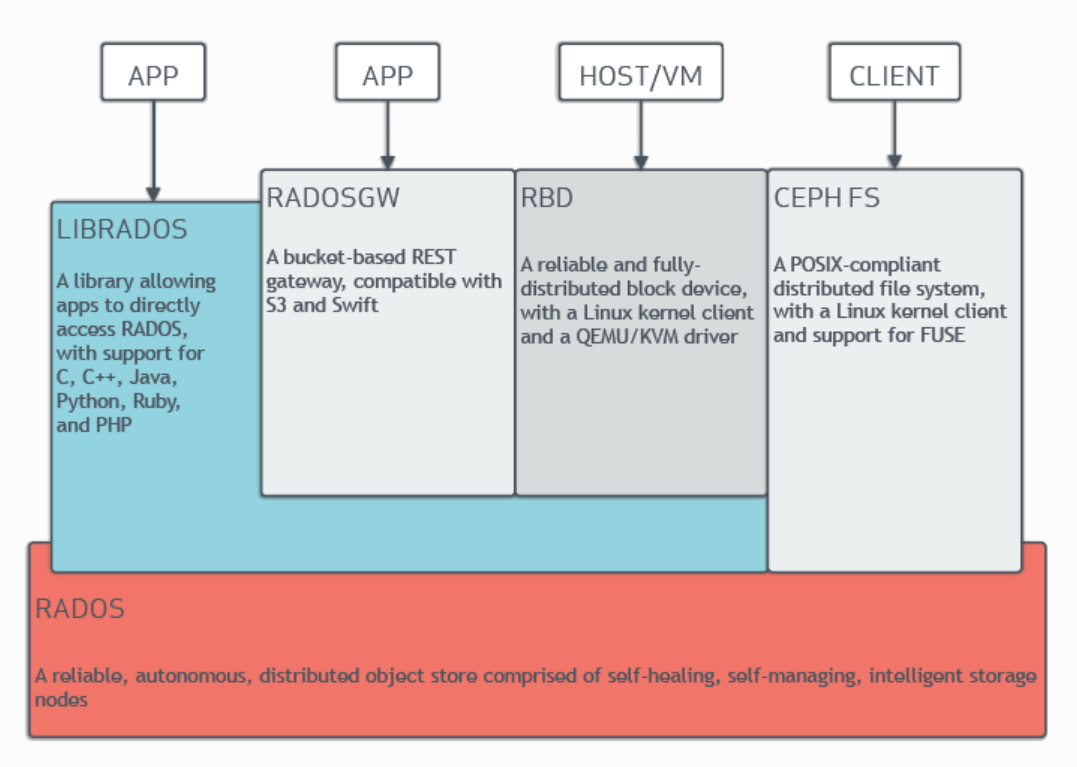
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”。 RADOS由两个组件组成:- OSD: Object Storage Device,提供存储资源。
- Monitor:维护整个Ceph集群的全局状态。
RADOS具有很强的扩展性和可编程性,Ceph基于RADOS开发了 Object Storage、Block Storage、FileSystem。Ceph另外两个组件是:
- MDS:用于保存CephFS的元数据。
- RADOS Gateway:对外提供REST接口,兼容S3和Swift的API。
数据存储
Ceph存储集群从Ceph客户端接收数据——无论是通过Ceph块设备、Ceph对象存储、Ceph文件系统还是使用librados创建的自定义实现——这些数据被存储为RADOS对象。每个对象存储在对象存储设备上。Ceph OSD daemon处理存储驱动器上的读、写和复制操作。对于较旧的Filestore后端,每个RADOS对象都作为一个单独的文件存储在传统的文件系统(通常是XFS)上。使用新的和默认的BlueStore后端,对象以一种类似于单片数据库的方式存储。
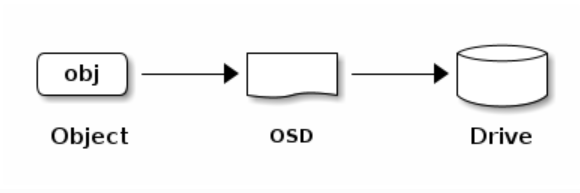
Ceph OSD Daemons将数据作为对象存储在一个平面命名空间中(例如,没有目录层次结构)。对象具有标识符、二进制数据和由一组名称/值对组成的元数据。语义完全取决于Ceph客户端。例如,cepfs使用元数据来存储文件属性—文件所有者、创建日期、最后修改日期等等。

优势
Ceph也是分布式存储系统,它的特点是:
高扩展性:
- 高度并行。没有单个中心控制组件。所有负载都能动态的划分到各个服务器上。把更多的功能放到OSD上,让OSD更智能。
- 自管理。容易扩展、升级、替换。当组件发生故障时,自动进行数据的重新复制。当组件发生变化时(添加/删除),自动进行数据的重分布。
高可靠性:
-
数据多副本。可配置的per-pool副本策略和故障域布局,支持强一致性。
-
没有单点故障。可以忍受许多种故障场景;防止脑裂;单个组件可以滚动升级并在线替换。
-
所有故障的检测和自动恢复。恢复不需要人工介入,在恢复期间,可以保持正常的数据访问。
-
并行恢复。并行的恢复机制极大的降低了数据恢复时间,提高数据的可靠性。
高性能:
-
Client和Server直接通信,不需要代理和转发
-
多个OSD带来的高并发度。objects是分布在所有OSD上。
-
负载均衡。每个OSD都有权重值(现在以容量为权重)。
-
client不需要负责副本的复制(由primary负责),这降低了client的网络消耗。
Cluster MAP
Ceph依赖于Ceph客户端和Ceph OSD守护进程对集群拓扑的了解,集群拓扑包括5个map,统称为“Cluster Map”:
- Monitor Map: 包含集群fsid、每个监视器的位置、名称、地址和端口。它还指示当前纪元、创建map的时间以及最后更改的时间。要查看 monitor map,执行ceph mon dump。
- OSD Map: 当map创建和最后修改时包含集群fsid,还包含一个池列表,副本大小,PG编号,OSD列表和它们的状态。查看OSD映射,执行ceph OSD dump命令。
- PG Map: 包含PG版本、时间戳、最后一个OSD Map纪元、完整的比率,以及每个放置组的详细信息,如PG ID、Up Set、Acting Set、PG的状态,以及每个池的数据使用统计信息
- CRUSH Map: 包含存储设备、故障域层次结构(例如,设备、主机、机架、行、房间等)的列表,以及存储数据时遍历层次结构的规则。要查看一个CRUSH Map,执行ceph osd getcrushmap -o {filename};然后,执行crushtool -d {compp -crushmap-filename} -o {decomp-crushmap-filename}反编译它。
- MDS Map: 包含当前MDS Map的纪元,映射创建的时间,以及最后一次更改的时间。它还包含用于存储元数据的池、元数据服务器列表以及哪些元数据服务器处于
up和in状态。查看MDS映射,执行ceph fs dump命令。
每个map维护其操作状态更改的迭代历史。Ceph Monitors维护集群映射的主副本,包括集群成员、状态、更改和Ceph存储集群的整体运行状况。
-
相关阅读:
基础语言-第17天-正则表达式
代码随想录-哈希表|ACM模式
国家加快培育数据要素市场的重要意义是什么
计算机网络-网络互连和互联网(四)
5.华为交换机局域网vlan网段隔离配置
【业务功能篇94】微服务-springcloud-springboot-认证服务-注册功能-第三方短信验证API
ArduinoUNO实战-第二十二章-红外遥控实验
java基于微信小程序的家校作业成绩管理系统 uni-app
计算几何算法模板
【测控电路】自举式高输入阻抗放大电路
- 原文地址:https://blog.csdn.net/weixin_45804031/article/details/127779961