0、项目说明
- 项目目的:通过泰坦尼克号乘船者的信息数据训练一个可以做生存预测的分类模型
- 乘船者信息数据
链接:https://pan.baidu.com/s/1QbrlGltiMYRmRR4Ro_SAgw
提取码:1234
- 项目概览:
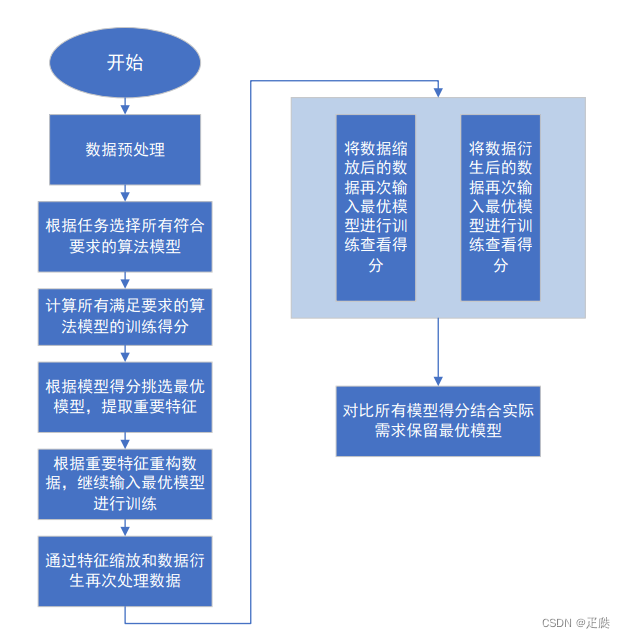
1、项目整体流程
1.1、项目数据预处理
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('./泰坦尼克船员获救/titanic_train.csv')
'''
PassengerId:乘客id
Survived:是否存活
Pclass:船舱等级
Name:姓名
Sex:性别
Age:年龄
SibSp:兄弟姐妹的个数
Parch:家人数量
Ticket:船票号
Fare:船票价格
Cabin:门牌号
Embarked:上船地点
'''
data.head(3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

data.shape
data.loc[:,'Fare'].unique().max()
data.info()
'''
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64 有缺失数据,考虑填充(平均值、中位数、众数)
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object 有缺失数据,考虑删除
11 Embarked 889 non-null object 有缺失数据,考虑填充
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
data.loc[:,'Age'].fillna(data.loc[:,'Age'].median(),inplace=True)
data.drop(columns='Cabin',inplace=True)
data.loc[:,'Embarked'].value_counts()
'''
Embarked
S 644
C 168
Q 77
Name: count, dtype: int64
'''
data.loc[:,'Embarked'].fillna(value="S",inplace=True)
data.info()
'''
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Embarked 891 non-null object
dtypes: float64(2), int64(5), object(4)
memory usage: 76.7+ KB
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
'''
方法1
data.loc[:,'Sex'] = data.loc[:,'Sex'].map({'male':0,'female':1})
data.loc[:,'Embarked'] = data.loc[:,'Embarked'].map({'S':0,'C':1,'Q':2})
'''
data.loc[:,'Sex'] = data.loc[:,'Sex'].factorize()[0]
data.loc[:,'Embarked'] = data.loc[:,
