昨天下午星球有同学问了一个问题:目前业内高可用部署主要采用方案?
看到这个问题,我的第一反应是问题太宽泛,不够明确。我反问了她一个问题:“你需要什么高可用?业务高可用?服务高可用?数据库高可用?还是其他?”
针对问题我也给出了我的理解和方案,大致内容如下:
|
高可用类型 |
简单理解 |
高可用方案 |
|
业务高可用 |
用户的操作都可以正常被处理 |
冗余设计+故障预案+监控告警+良好的服务发布体系 |
|
服务高可用 |
service可持续处理请求,但不对业务的正确性负责 |
分布式集群+限流熔断方案+ |
上述的内容只是一个引子,因为高可用和线上服务的稳定性有密切的关系。而软件测试或者说质量保障的工作范畴,不仅仅在测试环境,线上环境的服务质量保障,也是我们需要关注的重点。
这其实也是我在之前的文章《如何建立高效的质量保障体系》中提到的一点:交付(线上)质量持续运营。见下图:
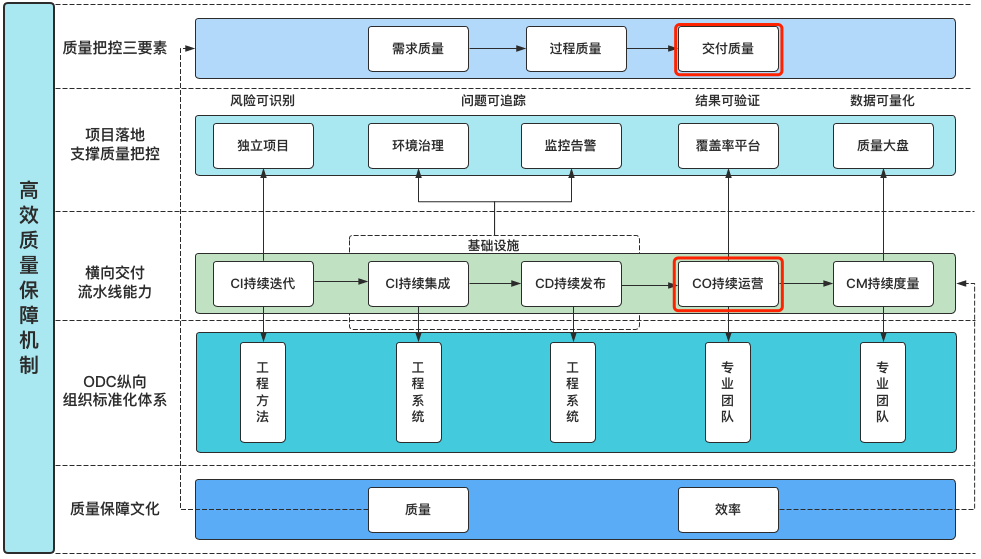
那么如何做好线上的服务质量保障工作,达到持续运营的理想状态呢?这是我本篇文章要聊的话题。
发现线上故障
业内程序员面试时候据说有个三高的说法,即:高并发、高性能、高可用。
分布式架构中有CAP理论,即:Consistency(数据一致性)、Availability(服务可用性)、Partition tolerance(分区容错性)。
这些点对软件系统提出了很高的要求,既要能扛得住高并发流量冲击,又要具备很好的性能来处理请求,还要达到服务和业务的高可用,并且要保证业务数据的一致性,最后还要对异常场景有一定的冗余处理能力,简直是难上加难。
而线上服务(或者说生产环境),我们最担心也最常见的就是出现线上故障。故障的种类很多,什么服务挂了、支付失败、无法加载商品图片等等不一而足。
要保障线上服务质量,避免出现线上故障的前提,除了在测试阶段做好测试,上线发布前仔细验证之外,还需要具备在故障发生时及时发现故障的能力。
目前最常见的发现故障的手段有两种,分别是:日志分析和监控告警。
当然,很多的监控告警系统也是通过埋点数据和日志采集,对采集的数据进行过滤,解析成一定的结构数据,然后进行存储以及可视化展示来做的。
比如很经典的ELK(Elasticsearch+Logstash+Kibana),如下图:
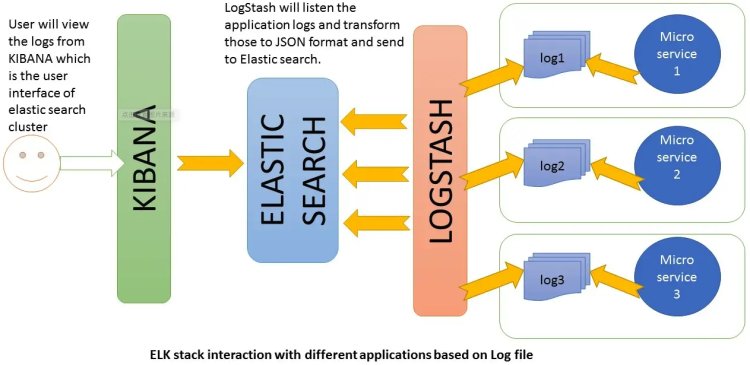
通过日志分析和监控告警,我们可以快速的发现线上故障,及时的进行处理。
处理线上故障
发现线上出现故障后,第一优先级永远是快速恢复线上业务的可用性,然后再考虑其他。
写到这里突然想起之前就职的某家企业交易团队负责人的话:优先业务止血,再考虑问题定位分析和优化。
以我的工作经历来说,一般发现线上故障后的处理流程如下:
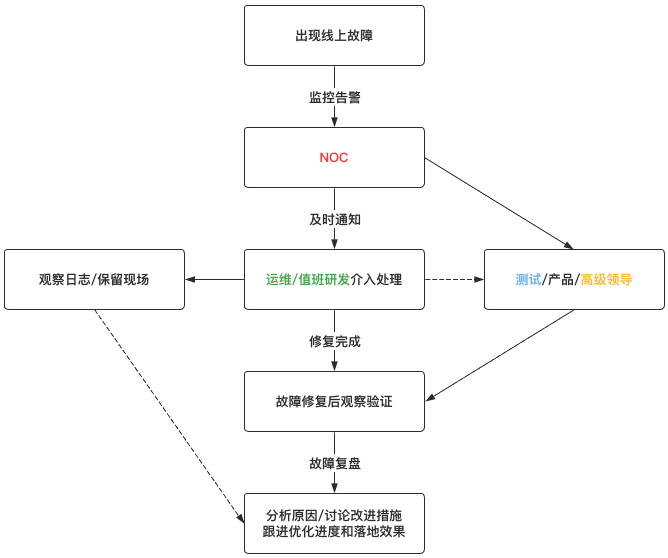
一般来说,线上故障处理,主要会涉及到如下四种角色:
NOC:一般指专门的线上服务巡检和监控值班人员,出现故障时作为信息收集和信息分发中心;
运维/研发:线上故障由对应业务域/服务的研发和运维进行处理(研发对代码最熟,运维有服务配置发布和变更权限);
测试/产品:故障恢复后测试进行观察验证,如果影响范围较大,还需要通知产品甚至市场运营进行对应的配合处理;
高层领导:如果故障比较严重,需要上升到更高级别的负责人,并且某些重要操作需要高层决策和授权;
修复线上故障
一般来说,对于线上出现故障,快速恢复服务可用业务可用,降低故障带来的损失是首要的,修复bug反而是其次。
所以在线上出现故障时,一般都会采用一些临时方案来达到快速止血的目的。常见的临时方案有:
- 服务重启;
- 部署回滚;
- 限流降级;
有临时方案就有后续的优化方案,一般在线上故障恢复后,会进行如下几个步骤:
- 利用日志和故障现场保留的dump文件等进行根因分析;
- 修复故障后在测试环境进行验证,确认没问题后再发布到生产环境;
- 记录故障从发生到彻底修复的全过程,进行线上故障复盘,提出后续改进方案并跟进落地;
当然,除了上述的一些手段,还可以通过如下几种方式来降低线上出现故障的影响和损失:
- 组织线上故障演练,培养技术同学的临时反应和处理问题能力;
- 通过灰度发布或者发布beta版本,让用户成为帮助我们发现问题;
- 做专项的混沌工程,在不断的攻防演练中提升线上服务的质量和稳定性;
运营线上质量
聊了这么多,那测试同学如何针对线上故障,做好质量持续运营呢?可以从上面的几张配图来切入。
线上服务巡检:NOC并不是一个岗位,而是一种职责,测试同学对于业务和自己负责的项目相对更熟悉,要做到最快速度发现和处理线上故障,就是要让最正确的人第一时间响应和介入处理。
而测试同学可以达到监控巡检和信息分发以及快速验证的作用。当然,这种机制需要一定的时间建立,还需要一定的基础技术服务设施支撑。
组织故障复盘:流程和规范可以将好的实践标准化流程化自动化,让技术团队共享经验,而组织故障复盘并且跟进后续的优化落地效果,就是一个测试同学可以很好胜任的事情。
故障处理手册:有了日常线上巡检,组织了故障复盘,可以沉淀很多的最佳实践,可以将这些实践抽取共性,沉淀输出为一份故障处理手册,并在团队内做宣讲和落地。
这样既可以让其他同学在面对故障时能更快的响应处理,也能让新同学入职后快速的熟悉团队的技术栈,加快融入速度。