-
Flink系列文档-(YY03)-Flink编程基础API
1 Flink编程入口
首先获取flink编程的核心入口对象
- /**
- * 获取批处理入口对象
- */
- // 1) 普通的批处理对象
- ExecutionEnvironment environment1 = ExecutionEnvironment.getExecutionEnvironment();
- Configuration configuration = new Configuration();
- configuration.setInteger("rest.port" , 80820);
- // 2) 带本地界面的批处理入口对象
- ExecutionEnvironment environment2 = ExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
- /**
- * 获取流处理入口对象
- */
- StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
- StreamExecutionEnvironment see2 = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
- /**
- * 获取流处理入口对象
- * 可以处理批次数据
- * 也可以处理流式数据
- */
- see.setRuntimeMode(RuntimeExecutionMode.BATCH) ; // 批处理模式
- see.setRuntimeMode(RuntimeExecutionMode.STREAMING) ; // 流处理模式
- see.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC) ; // 自动处理模式
注意:上面代码中开启WEBUI本地运行模式时 需要添加如下依赖
- <dependency>
- <groupId>org.apache.flinkgroupId>
- <artifactId>flink-runtime-web_2.12artifactId>
- <version>${flink.version}version>
- dependency>
2 基本Source算子
source是用来获取外部数据的算子,按照获取数据的方式,可以分为:
- 基于集合的Source
- 基于Socket网络端口的Source
- 基于文件的Source
- 第三方Connector Source
- 自定义Source
从并行度的角度,source又可以分为非并行的source和并行的source。
- 非并行source:并行度只能为1,即只有一个运行时实例,在读取大量数据时效率比较低,通常是用来做一些实验或测试,例如Socket Source;
- 并行Source:并行度可以是1到多个,在计算资源足够的前提下,并行度越大,效率越高。例如Kafka Source;
2.1 基于集合的Source(常用于测试)
可将一个普通的Java集合、迭代器或者可变参数转换成一个分布式数据流DataStream;
- /**
- * @Date: 22.11.7
- * @Author: Hang.Nian.YY
- * @qq: 598196583
- * @Tips: 学大数据 ,到多易教育
- * @Description: SOURCE: 基于集合的source算子
- */
- public class Base_API_Source_Demo01 {
- public static void main(String[] args) throws Exception {
- Configuration configuration = new Configuration();
- configuration.setInteger("rest.port" , 80820);
- StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
- // 设置处理数据的并行度
- see.setParallelism(2) ;
- /**
- * 基于集合的source算子
- */
- //1)
- DataStreamSource
ds1 = see.fromSequence(1, 10); - //2)
- DataStreamSource
ds2 = see.fromElements("big", "data", "hang", "yy", "dy"); - //3)
- List
list = Arrays.asList("big", "data", "hang", "yy", "dy"); - DataStreamSource
ds3 = see.fromCollection(list); - //4)
- // 可以并行化处理的数据流 , 指定数据并行化分发的规则
- // 参数一 使用flink自己现成的具有数据分发规则的迭代器的实现类 参数二 返回数据类型
- DataStreamSource
ds4 = see.fromParallelCollection(new NumberSequenceIterator(1L, 10L), Long.class); - // 将数据流出到控制台 ,print可以指定参数 : 输出标记
- ds1.print("输出数据: ") ;
- // 触发程序提交
- see.execute() ;
- }
- }
2.2 基于Socket的Source(常用于测试)
非并行的Source,通过socket通信来获取数据得到数据流;
该方法还有多个重载的方法,如:socketTextStream(String hostname, int port, String delimiter, long maxRetry)可以指定行分隔符和最大重新连接次数。
- //调用env的socketTextStream方法,从指定的Socket地址和端口创建DataStream
- DataStreamSource
lines = env.socketTextStream("localhost", 8888);
提示:socketSource是一个非并行source,如果使用socketTextStream读取数据,在启动Flink程序之前,必须先启动一个Socket服务,为了方便,Mac或Linux用户可以在命令行终端输入nc -lk 8888启动一个Socket服务并在命令行中向该Socket服务发送数据。
2.3 基于文件的Source
基于文件的Source,本质上就是使用指定的FileInputFormat组件读取数据,可以指定TextInputFormat、CsvInputFormat、BinaryInputFormat等格式;
底层都是ContinuousFileMonitoringFunction(连续的文件监控),这个类继承了RichSourceFunction,RichSourceFunction产生的Source都是非并行的Source;
readFile
readFile(FileInputFormat inputFormat, String filePath) 方法可以指定读取文件的FileInputFormat 格式,参数FileProcessingMode,可取值:
- PROCESS_ONCE,只读取文件中的数据一次,读取完成后,程序退出
- PROCESS_CONTINUOUSLY,会一直监听指定的文件,文件的内容发生变化后,会将以前的内容和新的内容全部都读取出来,进而造成数据重复读取。
- String path = "file:///Users/xing/Desktop/a.txt";
- //PROCESS_CONTINUOUSLY模式是一直监听指定的文件或目录,2秒钟检测一次文件是否发生变化
- DataStreamSource
lines = env.readFile(new TextInputFormat(null), path, - FileProcessingMode.PROCESS_CONTINUOUSLY, 2000);
readTextFile
readTextFile(String filePath) 可以从指定的目录或文件读取数据,默认使用的是TextInputFormat格式读取数据,还有一个重载的方法readTextFile(String filePath, String charsetName)可以传入读取文件指定的字符集,默认是UTF-8编码。该方法是一个有限的数据源,数据读完后,程序就会退出,不能一直运行。该方法底层调用的是readFile方法,FileProcessingMode为PROCESS_ONCE
DataStreamSourcelines = env.readTextFile(path); 2.4 Kafka Source (生产中常用)
在实际生产环境中,为了保证flink可以高效地读取数据源中的数据,通常是跟一些分布式消息中件结合使用,例如Apache Kafka。Kafka的特点是分布式、多副本、高可用、高吞吐、可以记录偏移量等。Flink和Kafka整合可以高效的读取数据,并且可以保证Exactly Once(精确一次性语义)。
首先在maven项目的pom.xml文件中导入Flink跟Kafka整合的依赖
- <dependency>
- <groupId>org.apache.flinkgroupId>
- <artifactId>flink-connector-kafka_2.12artifactId>
- <version>1.14.4version>
- dependency>
代码示例
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- KafkaSource
kafkaSource = KafkaSource. builder() - .setBootstrapServers("doitedu01:9092")
- .setValueOnlyDeserializer(new SimpleStringSchema())
- .setStartingOffsets(OffsetsInitializer.latest())
- .setTopics("flink-01")
- .setGroupId("fk03")
- .build();
-
- WatermarkStrategy
strategy = WatermarkStrategy - .
forBoundedOutOfOrderness(Duration.ZERO) - .withTimestampAssigner(new SerializableTimestampAssigner
() { - @Override
- public long extractTimestamp(String element, long recordTimestamp) {
- String[] arr = element.split(",");
- return Long.parseLong(arr[3]);
- }
- });
-
- // 1,a,100,1646784001000
- DataStreamSource
stream1 = env.fromSource(kafkaSource,strategy,"").setParallelism(2);
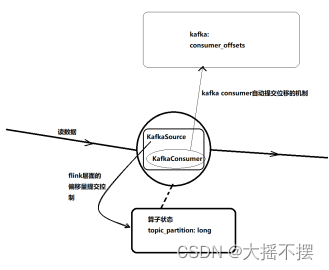
新版本API中,flink会把kafka消费者的消费位移记录在算子状态中,这样就实现了消费位移状态的容错,从而可以支持端到端的exactly-once;
2.5 自定义Source
Flink的DataStream API可以让开发者根据实际需要,灵活的自定义Source,本质上就是定义一个类,实现SourceFunction或继承RichParallelSourceFunction,实现run方法和cancel方法。
自定义source
可以实现 SourceFunction 或者 RichSourceFunction , 这两者都是非并行的source算子
也可实现 ParallelSourceFunction 或者 RichParallelSourceFunction , 这两者都是可并行的source算子
-- 带 Rich的,都拥有 open() ,close()生命周期方法 ,getRuntimeContext() 方法
-- 带 Parallel的,都可多实例并行执行
创建非并行 Source 数据源
- class MySource0 implements SourceFunction
{ - @Override
- public void run(SourceContext
ctx) throws Exception { - }
- @Override
- public void cancel() {
- }
- }
- /**
- * RichXXX 方法中具有
- * 1) getRuntimeContext 运行时上下文
- * 2) open()
- * 3) close() 等生命周期方法
- */
- class MySource02 extends RichSourceFunction
{ - ArrayList
list = new ArrayList<>() ; - @Override
- public void open(Configuration parameters) throws Exception {
- BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("data/yy.txt")));
- String line = null ;
- while ((line = br.readLine())!=null){
- String[] arr = line.split(",");
- DaYao daYao = new DaYao(arr[0], arr[1], arr[2], Double.parseDouble(arr[3]));
- list.add(daYao) ;
- }
- }
- @Override
- public void run(SourceContext
ctx) throws Exception { - while (true){
- int index = RandomUtils.nextInt(list.size());
- DaYao daYao = list.get(index);
- ctx.collect(daYao);
- Thread.sleep(2000);
- }
- }
- @Override
- public void cancel() {
- }
- @Override
- public void close() throws Exception {
- super.close();
- }
- }
创建并行的source 数据源
- class MySource03 implements ParallelSourceFunction
{ - @Override
- public void run(SourceContext
ctx) throws Exception { - }
- @Override
- public void cancel() {
- }
- }
- /**
- * @Date: 22.11.07
- * @Author: Hang.Nian.YY
- * @qq: 598196583
- * @Tips: 学大数据 ,到多易教育
- * @Description:
- */
- public class MySource extends RichParallelSourceFunction
{ - ArrayList
list = new ArrayList<>() ; - @Override
- public void open(Configuration parameters) throws Exception {
- BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("data/dayao.txt")));
- String line = null ;
- while ((line = br.readLine())!=null){
- String[] arr = line.split(",");
- DaYao daYao = new DaYao(arr[0], arr[1], arr[2], Double.parseDouble(arr[3]));
- list.add(daYao) ;
- }
- }
- @Override
- public void run(SourceContext
ctx) throws Exception { - while (true){
- int index = RandomUtils.nextInt(list.size());
- DaYao daYao = list.get(index);
- ctx.collect(daYao);
- Thread.sleep(2000);
- }
- }
- @Override
- public void cancel() {
- }
- }
-
相关阅读:
游戏开发玩法设计的重要性
这些不知道,别说你熟悉 Nacos,深度源码解析!
分享记账的目的,选择的记账方法
基于两种算法的无线信道“指纹”特征识别(Matlab代码实现)
机器学习——手写数字识别
java.lang.NoClassDefFoundError:com/fasterxml/jackson/core/JsonFactory
护航数据安全|安全狗入选厦门市工业领域数据安全管理支撑单位
浏览器打不开DevTools?
java的匿名内部类的使用
使用phpmailer发送邮件(以QQ邮箱为例)
- 原文地址:https://blog.csdn.net/qq_37933018/article/details/127739852
