-
(十一)MyBatis的高级映射及延迟加载
上一篇:(十)Mybatis之动态SQL
下一篇:(十二)Mybatis的缓存机制环境
数据库:
- 学生表t_students,班级表t_clazz
班级表t_clazz:

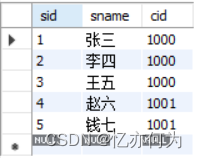
学生表t_students:
- 订单表t_order,商品表t_products,关系表t_orderitem
商品表t_products:

订单表t_order:

关系表t_orderitem:

引⼊依赖:mysql驱动依赖、mybatis依赖、logback依赖、junit依赖。
引入配置文件:jdbc.properties、mybatis-config.xml、logback.xml
pojo类:- Student、Clazz
- Order、Products
多对一
多个学生对应一个班级
pojo类Student中添加⼀个属性:Clazz clazz; 表示学生关联的班级对象。
多种方式,常见的包括三种:- 第⼀种方式:⼀条SQL语句,级联属性映射。
- 第⼆种方式:⼀条SQL语句,association。
- 第三种方式:两条SQL语句,分步查询。(这种方式常用:优点⼀是可复用。优点⼆是支持懒加载。)
Student:
/** * 学生信息 */ public class Student {//Student是多的一方 private Integer sid; private String sname; private Clazz clazz;//clazz是一的一方 public Clazz getClazz() { return clazz; } public void setClazz(Clazz clazz) { this.clazz = clazz; } public Student() { } public Student(Integer sid, String sname) { this.sid = sid; this.sname = sname; } @Override public String toString() { return "Student{" + "sid=" + sid + ", sname='" + sname + '\'' + ", clazz=" + clazz + '}'; } public Integer getSid() { return sid; } public void setSid(Integer sid) { this.sid = sid; } public String getSname() { return sname; } public void setSname(String sname) { this.sname = sname; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
Clazz:
/** * 班级信息 */ public class Clazz { private Integer cid; private String cname; public Clazz() { } public Clazz(Integer cid, String cname) { this.cid = cid; this.cname = cname; } @Override public String toString() { return "Clazz{" + "cid=" + cid + ", cname='" + cname + '\'' + '}'; } public Integer getCid() { return cid; } public void setCid(Integer cid) { this.cid = cid; } public String getCname() { return cname; } public void setCname(String cname) { this.cname = cname; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
第⼀种方式:级联属性映射
⼀条SQL语句,使用resultMap标签进行级联属性映射
创建StudentMapper接口,添加方法
/** * 通过id查询,同时获取学生关联的班级信息,使用resultMap标签进行级联属性映射 * @param id 学生的id * @return 学生对象,含有班级对象 */ Student selectById(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
创建StudentMapper.xml映射文件,配置级联属性映射
<resultMap id="studentResultMap" type="Student"> <id property="sid" column="sid"></id> <result property="sname" column="sname"></result> <!--通过'.',进行引用属性映射--> <result property="clazz.cid" column="cid"></result> <result property="clazz.cname" column="cname"></result> </resultMap> <select id="selectById" resultMap="studentResultMap"> select s.sid,s.sname,c.cid,c.cname from t_students s left join t_clazz c on s.cid = c.cid where s.sid = #{sid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
测试程序:
@Test public void testSelectById() { SqlSession session = SqlSessionUtil.getSession(); StudentMapper mapper = session.getMapper(StudentMapper.class); Student student = mapper.selectById(2); System.out.println(student); SqlSessionUtil.close(session); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

第⼆种方式:association
多对一映射的第二种方式,一条SQL语句,在resultMap使用association标签进行关联
- association标签:翻译为关联,把一个对象关联到另一个对象上。
- property属性:提供要映射类的属性名
- javaType属性:要映射的类名
- id标签和result标签,用法与resultMap一样
StudentMapper接口添加方法:
/** * 通过id查询,同时获取学生关联的班级信息,使用association标签进行关联 * @return */ Student selectByIdAssociation(Integer id);- 1
- 2
- 3
- 4
- 5
StudentMapper.xml映射文件配置:
<resultMap id="studentResultMapAssociation" type="Student"> <id property="sid" column="sid"></id> <result property="sname" column="sname"></result> <association property="clazz" javaType="Clazz"> <id property="cid" column="cid" /> <result property="cname" column="cname" /> </association> </resultMap> <select id="selectByIdAssociation" resultMap="studentResultMapAssociation"> select s.sid,s.sname,c.cid,c.cname from t_students s left join t_clazz c on s.cid = c.cid where s.sid = #{sid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试程序:
@Test public void testSelectByIdAssociation() { SqlSession session = SqlSessionUtil.getSession(); StudentMapper mapper = session.getMapper(StudentMapper.class); Student student = mapper.selectByIdAssociation(4); System.out.println(student); SqlSessionUtil.close(session); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

第三种方式:分步查询
多对一映射的第三种方式,分布查询,两条SQL语句
还是使用association标签:- select属性:指定下一步SQL语句的id,全限定的接口方法名
- column属性:指定要传给第二步的属性
分布查询第一步
第一步,根据id查询所有信息,这些信息含有cid(班级id),我们需要把这个cid传给下一步需要配置结果映射,当然属性名跟数据库表字段名一样,可以不用配(最好配上,因为能提高效率)
StudentMapper接口添加方法:/** * 通过id查询,同时获取学生关联的班级信息,分布查询第一步 * @return */ Student selectByIdStep1(Integer id);- 1
- 2
- 3
- 4
- 5
StudentMapper.xml配置文件配置:
<resultMap id="studentResultMapByStep1" type="Student"> <id property="sid" column="sid" /> <result property="sname" column="sname" /> <association property="clazz" select="com.advanced.mapping.mapper.ClazzMapper.selectByIdStep2" column="cid"/> </resultMap> <select id="selectByIdStep1" resultMap="studentResultMapByStep1"> select * from t_students where sid = #{sid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
分布查询第二步
第二步,需要sql语句获取第一步传过来的cid,根据第一步传过来的cid查询班级信息
创建ClazzMapper接口,添加方法:/** * 分布查询第二步,根据cid获取班级信息 * @param id * @return */ Clazz selectByIdStep2(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
创建ClazzMapper.xml配置文件:
<!--分布查询第二步,根据cid获取班级信息--> <select id="selectByIdStep2" resultType="Clazz"> select * from t_clazz where cid = #{cid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
测试程序
调用方法的时候,只要调用StudentMapper里面的第一步方法就可以了,Mybatis会自动调用第二步方法。
@Test public void testSelectByIdStep() { SqlSession session = SqlSessionUtil.getSession(); StudentMapper mapper = session.getMapper(StudentMapper.class); Student student = mapper.selectByIdStep1(3); System.out.println(student); SqlSessionUtil.close(session); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
发现Mybatis自动执行了两条sql语句

延迟加载
分步查询的优点:
-
第一:复用性增强。可以重复利用。(拆成N多个步骤。每一个步骤都可以重复利用。)
-
第二:采用这种分步查询,可以充分利用他们的延迟加载/懒加载机制。
延迟加载(懒加载): 延迟加载的核心原理是:用的时候再执行查询语句。不用的时候不查询。 作用:提高性能。尽可能的不查,或者说尽可能的少查。来提高效率。- 1
- 2
- 3
在mybatis当中怎么开启延迟加载呢?
-
association标签中添加fetchType=“lazy”,默认情况下是没有开启延迟加载的。
这种在association标签中配置fetchType=“lazy”,是局部的设置,只对当前的association关联的sql语句起作用。 -
在实际的开发中,大部分都是需要使用延迟加载的,所以建议开启全部的延迟加载机制:
在mybatis核心配置文件中添加全局配置:lazyLoadingEnabled=true实际开发中的模式: 把全局的延迟加载打开。 如果某一步不需要使用延迟加载,在对应association标签设置:fetchType="eager"- 1
- 2
- 3
测试程序:
还是使用分布查询的查询,开启懒加载,我们不把结果集全部输出,我们只输出学生的相关信息@Test public void testSelectByIdStep() { SqlSession session = SqlSessionUtil.getSession(); StudentMapper mapper = session.getMapper(StudentMapper.class); Student student = mapper.selectByIdStep1(3); //System.out.println(student); System.out.println(student.getSname()); //System.out.println(student.getClazz().getCname()); SqlSessionUtil.close(session); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

我们发现,只访问学生信息,Mybatis不会执行第二条sql语句,只会执行你所访问信息的相关sql语句,松开访问班级信息的语句,发现执行了两条sql语句,这就是懒加载的好处。

一对多
一个班级对应多个学生,通常是在一的一方中有List集合属性。
⼀对多的实现通常包括两种实现方式:- 第⼀种方式:collection
- 第⼆种方式:分步查询
Student不变
Clazz:/** * 班级信息 */ public class Clazz { private Integer cid; private String cname; private List<Student> students; public List<Student> getStudents() { return students; } public void setStudents(List<Student> students) { this.students = students; } public Clazz() { } public Clazz(Integer cid, String cname) { this.cid = cid; this.cname = cname; } @Override public String toString() { return "Clazz{" + "cid=" + cid + ", cname='" + cname + '\'' + ", students=" + students + '}'; } public Integer getCid() { return cid; } public void setCid(Integer cid) { this.cid = cid; } public String getCname() { return cname; } public void setCname(String cname) { this.cname = cname; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
第⼀种方式:collection
一对多映射的第一种方式,一条SQL语句,在resultMap使用collection标签
collection标签:翻译为集合,与多对一的association标签标签用法差不多- property属性:提供要给集合类的属性名
- javaType属性:要给集合的类名
- id标签和result标签,用法与resultMap一样
在ClazzMapper接口添加方法:
/** * 根据id查询,使用collection * @param id * @return */ Clazz selectByCollection(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
ClazzMapper.xml配置:
<resultMap id="clazzResultMap" type="Clazz"> <id property="cid" column="cid"></id> <result property="cname" column="cname"></result> <collection property="students" ofType="Student"> <id property="sid" column="sid"></id> <result property="sname" column="sname"></result> </collection> </resultMap> <select id="selectByCollection" resultMap="clazzResultMap"> select c.cid,c.cname,s.sid,s.sname from t_clazz c left join t_students s on c.cid = s.cid where c.cid = #{cid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试程序:

第⼆种方式:分步查询
一对多映射的第二种方式,分布查询,两条SQL语句,与多对一差不多
分步查询第一步
第一步,根据id查询所有信息,这些信息含有班级id(字段名为cid),我们需要把这个cid传给下一步需要配置结果映射,当然属性名跟数据库表字段名一样,可以不用配(最好配上,因为能提高效率)
ClazzMapper接口添加方法:/** * 根据id查询,分布查询,第一步 * @param id * @return */ Clazz selectByIdStep1(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
ClazzMapper.xml配置:
<resultMap id="selectByIdStep" type="Clazz"> <id property="cid" column="cid"></id> <result property="cname" column="cname"></result> <collection property="students" select="com.advanced.mapping.mapper.StudentMapper.selectByIdStep2" column="cid"> </collection> </resultMap> <select id="selectByIdStep1" resultMap="selectByIdStep"> select * from t_clazz where cid = #{cid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
分步查询第二步
第二步,需要sql语句获取第一步传过来的cid,根据第一步传过来的cid查询学生信息
StudentMapper接口添加方法:/** * 分布查询第二步,根据cid获取学生信息 * @param id * @return */ List<Student> selectByIdStep2(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
StudentMapper.xml配置:
<!--分布查询第二步,根据cid获取学生信息--> <select id="selectByIdStep2" resultType="Student"> select * from t_students where cid = #{cid} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
测试程序
@Test public void testSelectByIdStep() { SqlSession session = SqlSessionUtil.getSession(); ClazzMapper mapper = session.getMapper(ClazzMapper.class); Clazz clazz = mapper.selectByIdStep1(1000); System.out.println(clazz); //System.out.println(clazz.getCname()); //clazz.getStudents().stream().forEach(student -> System.out.println(student)); SqlSessionUtil.close(session); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

分布查询同样能进行懒加载,这里就不演示了,参考多对一多对多
在实际项目开发中,多对多关系也是非常常见的关系,比如,一个购物系统中,一个订单中可以购买多种商品,一种商品也可以属于多个不同的订单,订单和商品就是多对多的关系。对于数据库中多对多关系建议使用一个中间表来维护关系,中间表中的订单id作为外键参照订单表的id,商品id作为外键参照商品表的id。下面我们就用一个简单示例来看看MyBatis怎么处理多对多关系。
多对多关系,可以拆成两个一对多关系,也可以拆成两个多对一关系,就可以使用上面的方式进行处理,这里只演示订单到商品的多对多关系的分布查询,也就是拆成两个一对多,进行分布查询,其他自己推就可以了
Products 商品实体类:public class Products { Integer id;//商品id String name;//商品名称 Double price;//商品价格 Integer pnum;//商品库存 public Products() { } @Override public String toString() { return "Products{" + "id=" + id + ", name='" + name + '\'' + ", price=" + price + ", pnum=" + pnum + '}'; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Double getPrice() { return price; } public void setPrice(Double price) { this.price = price; } public Integer getPnum() { return pnum; } public void setPnum(Integer pnum) { this.pnum = pnum; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
Order 订单实体类
/** * 订单实体类 */ public class Order { Integer id;//订单id String address;//订单地址 String name;//收件人 String phone;//手机号 Date time;//订单日期 List<Products> products;//多对多的关系映射 public Order() { } @Override public String toString() { return "Order{" + "id=" + id + ", address='" + address + '\'' + ", name='" + name + '\'' + ", phone='" + phone + '\'' + ", time=" + time + ", products=" + products + '}'; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public Date getTime() { return time; } public void setTime(Date time) { this.time = time; } public List<Products> getProducts() { return products; } public void setProducts(List<Products> products) { this.products = products; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
分布查询第一步
第一步,订单跟关系表是一对多关系,我们根据订单的id查询,这些信息含有订单id,需要把这个id传给第二步进行查询,当然属性名跟数据库表字段名一样,可以不用配(最好配上,因为能提高效率)
创建OrderMapper接口,添加方法:/** * 分布查询第一步,根据id查询,订单到商品的多对多关系 * @param id * @return */ Order selectByIdStep1(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
创建OrderMapper.xml进行配置:
<resultMap id="OrderResultMapByStep1" type="Order"> <id property="id" column="id" /> <result property="address" column="address" /> <result property="name" column="name" /> <result property="phone" column="phone" /> <result property="time" column="time" /> <association property="products" select="com.advanced.mapping.mapper.ProductsMapper.selectByIdStep2" column="id" fetchType="lazy"/> </resultMap> <select id="selectByIdStep1" resultMap="OrderResultMapByStep1"> select * from t_order where id = #{id} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
分布查询第二步
第二步,需要sql语句获取第一步传过来的订单id,根据第一步传过来的id,通过商品表和关系表多表查询查询出商品信息。
当然这里也可以拆成两步,通过第一步传过来的订单id查询出商品id,再传给第三步进行商品查询,把一条sql语句拆成两条,但是这种方式需要创建一个关系表的pojo类,以及对应的接口和映射文件,比较麻烦,最重要的是查询出来的关系表的数据在这个业务里面基本没用,不会去用,比较鸡肋。
这里之间就一条语句进行查询了
创建ProductsMapper接口,添加方法:/** * 分布查询第二步,订单到商品的多对多关系 * @param id * @return */ List<Products> selectByIdStep2(Integer id);- 1
- 2
- 3
- 4
- 5
- 6
创建ProductsMapper.xml进行配置:
<select id="selectByIdStep2" resultType="Products"> select p.* from t_products p left join t_orderitem o on p.id = o.product_id where o.order_id = #{id} </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试程序
@Test public void testSelectByIdStep(){ SqlSession session = SqlSessionUtil.getSession(); OrderMapper mapper = session.getMapper(OrderMapper.class); Order order = mapper.selectByIdStep1(2); System.out.println(order); }- 1
- 2
- 3
- 4
- 5
- 6
- 7

同样也能进行懒加载,参考多对一方式一对一
在实际项目开发中,一对一也是非常常见的,例如一个大学生只有一个学号,一个学号只属于一个学生。同样,人与身份证也是一对一的级联关系。
一对一,两种方案:一、主键共享。二、外键唯一
使用分布查询的话,把id传给第二步,参考上面进行推导即可 - 学生表t_students,班级表t_clazz
-
相关阅读:
L1W4作业1 逐步构建你的深度神经网络
【数智化人物展】同方有云联合创始人兼总经理江琦:云计算,引领数智化升级的动能...
Streamlit项目:乐高风格马赛克设计工坊~打造个性化马赛克图案的平台
Kotlin高仿微信-第14篇-单聊-视频通话
赵章光:只要用心去做,一切都不难
IDEA 集成Maven
充电以及电池
springboot websocket server无法接收二进制消息数据问题一例
神经网络入门
供应链管理的基本方法
- 原文地址:https://blog.csdn.net/weixin_45832694/article/details/127718067