-
微服务(SpringCloud、Dubbo、Seata、Sentinel、SpringGateway)
什么是微服务
微服务的概念是由Martin Fowler(马丁·福勒)在2014年提出的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HCjSZT5R-1667640638009)(note/day01/imagesay01/images/day01/image-20220428153622848.png)]](https://1000bd.com/contentImg/2024/04/28/a1db4e6c04b3c956.png)
微服务是由以单一应用程序构成的小服务,自己拥有自己的行程与轻量化处理,服务依业务功能设计,以全自动的方式部署,与其他服务使用 HTTP API 通信。同时服务会使用最小的规模的集中管理能力,服务可以用不同的编程语言与数据库等组件实现。
简单来说,微服务就是将一个大型项目的各个业务模块拆分成多个互不相关的小项目,而这些小项目专心完成自己的功能,而且可以调用其他小项目的方法,从而完成整体功能
京东\淘宝这样的大型互联网应用程序,基本每个操作都是一个单独的微服务在支持:
- 登录服务器
- 搜索服务器
- 商品信息服务器
- 购物车服务器
- 订单服务器
- 支付服务器
- 物流服务器
- …
为什么需要微服务

左侧小餐馆就像单体项目;一旦服务器忙,所有业务都无法快速响应,即使添加了服务器,也不能很好的解决这个问题,不能很好的实现"高并发,高可用,高性能",但是因为服务器数量少,所以成本低,适合并发访问少的项目。
右侧大餐厅就是微服务项目;每个业务专门一批人来负责,业务之间互不影响,在某个模块性能不足时,针对这个模块添加服务器改善性能,万一一个服务器发生异常,并不会影响整体功能,但是完成部署的服务器数量多,成本高,需要较多投资,能够满足"高并发,高可用,高性能"的项目。
怎么搭建微服务项目
在微服务概念提出之前(2014年),每个厂商都有自己的解决方案,但是Martin Fowler(马丁·福勒)提出了微服务的标准之后,为了技术统一和兼容性,很多企业开始支持这个标准,现在我们开发的微服务项目,大多数都是在马丁·福勒标准下的。
如果我们自己编写支持这个标准的代码是不现实的,必须通过现成的框架或组件完成满足这个微服务标准的项目结构和格式,当今程序员要想快速开发满足上面微服务标准的项目结构,首选SpringCloud。Spring Cloud
什么是SpringCloud
SpringCloud是由Spring提供的一套能够快速搭建微服务架构程序的框架集,框架集表示SpringCloud不是一个框架,而是很多框架的统称。SpringCloud就是为了搭建微服务架构项目出现的,有人将SpringCloud称之为"Spring全家桶",广义上指代Spring的所有产品。
Spring Cloud的内容
内容的提供者
- Spring自己提供的开发出来的框架或软件
- Netflix(奈非):早期的很长一段时间,提供了大量的微服务解决方案
- alibaba(阿里巴巴):新版本的SpringCloudAlibaba正在迅速占领市场(推荐使用)
功能上分类
- 微服务的注册中心
- 微服务间的调用
- 微服务的分布式事务
- 微服务的限流
- 微服务的网关
- …
注册中心Nacos
什么是Nacos
Nacos是Spring Cloud Alibaba提供的一个软件,这个软件主要具有注册中心和配置中心的功能,我们先学习它注册中心的功能;
微服务中所有项目都必须注册到注册中心才能成为微服务的一部分,注册中心和企业中的人力资源管理部门有相似;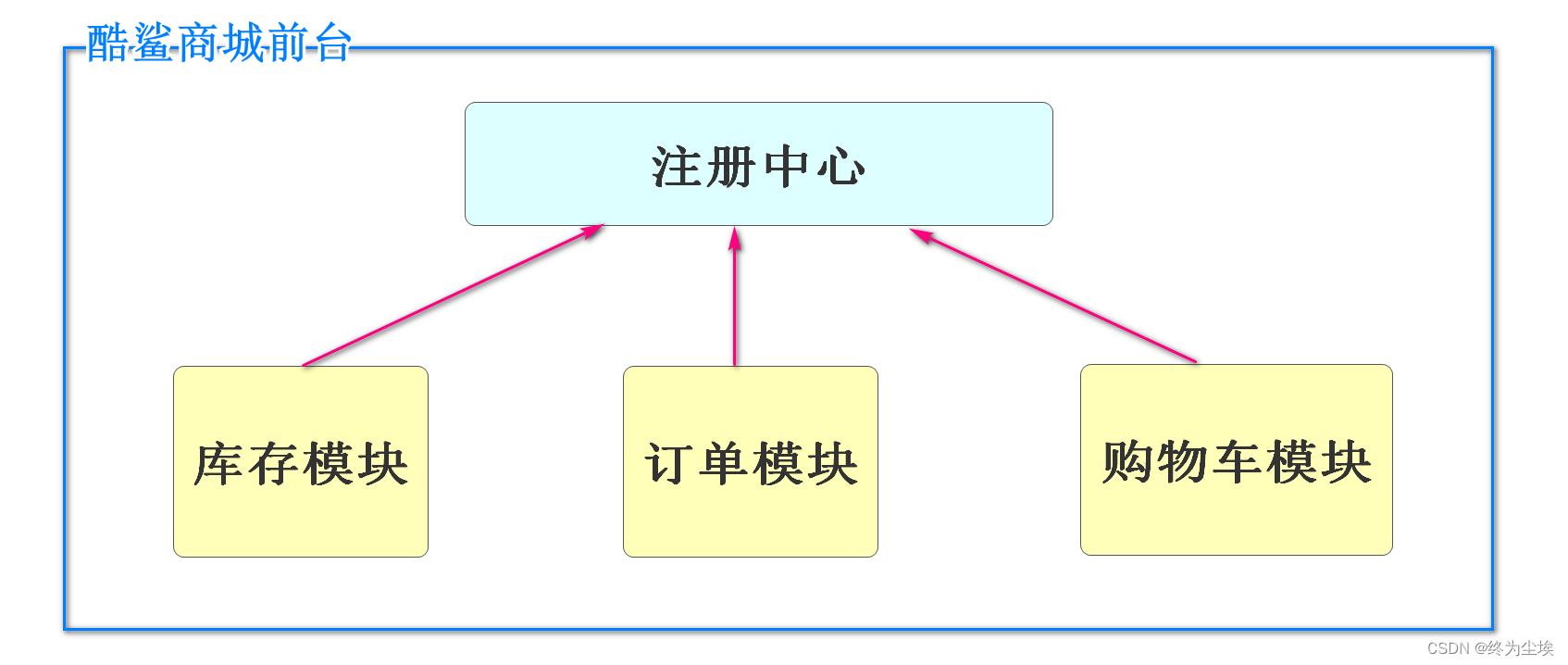
当前微服务项目中所有的模块,在启动前,必须添加注册到Nacos的配置;
所谓注册,就是将自己的信息,提交到Nacos来保存。
Nacos的下载
https://github.com/alibaba/nacos/releases/download/1.4.3/nacos-server-1.4.3.zip
国外网站,下载困难可以多试几次。
Nacos的启动
因为Nacos是java开发的,我们要启动Nacos必须保证当前系统配置了java环境变量,简单来说就是要环境变量中,有JAVA_HOME的配置,指向安装jdk的路径,确定了支持java后,就可以启动Nacos了;
mac系统安装Nacos推荐:https://blog.csdn.net/gongzi_9/article/details/123359171
windows的java环境变量正常后,将nacos-server-1.4.2.zip压缩包解压,双击打开解压得到的文件夹后,再双击打开其中的bin目录;
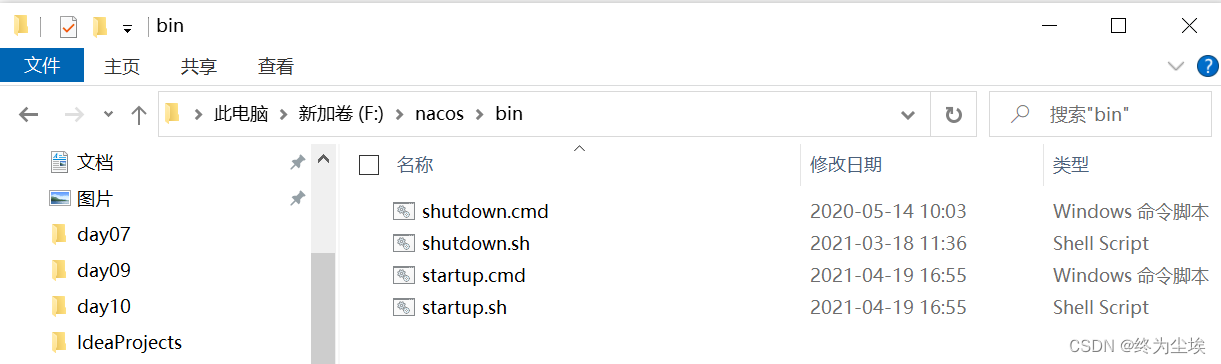
cmd结尾的文件是windows版本的sh结尾的文件是linux和mac版本的
startup是启动文件,shutdown是停止文件
Windows下启动Nacos不能直接双击cmd文件
需要在dos窗口运行,在当前资源管理器地址栏输入cmd
E:\tools\nacos\bin>startup.cmd -m standalone- 1
startup.cmd:windows启动nacos的命令文件
-m 表示要设置启动参数
standalone:翻译为标准的孤独的,意思是正常的使用单机模式启动
运行成功默认占用8848端口,并且在代码中提示
如果不输入standalone运行会失败
如果报了please set JAVA_HOME…,表示当前项目没有配置java环境变量(主要是没有设置JAVA_HOME),如果运行没有报错,打开浏览器输入地址:http://localhost:8848/nacos
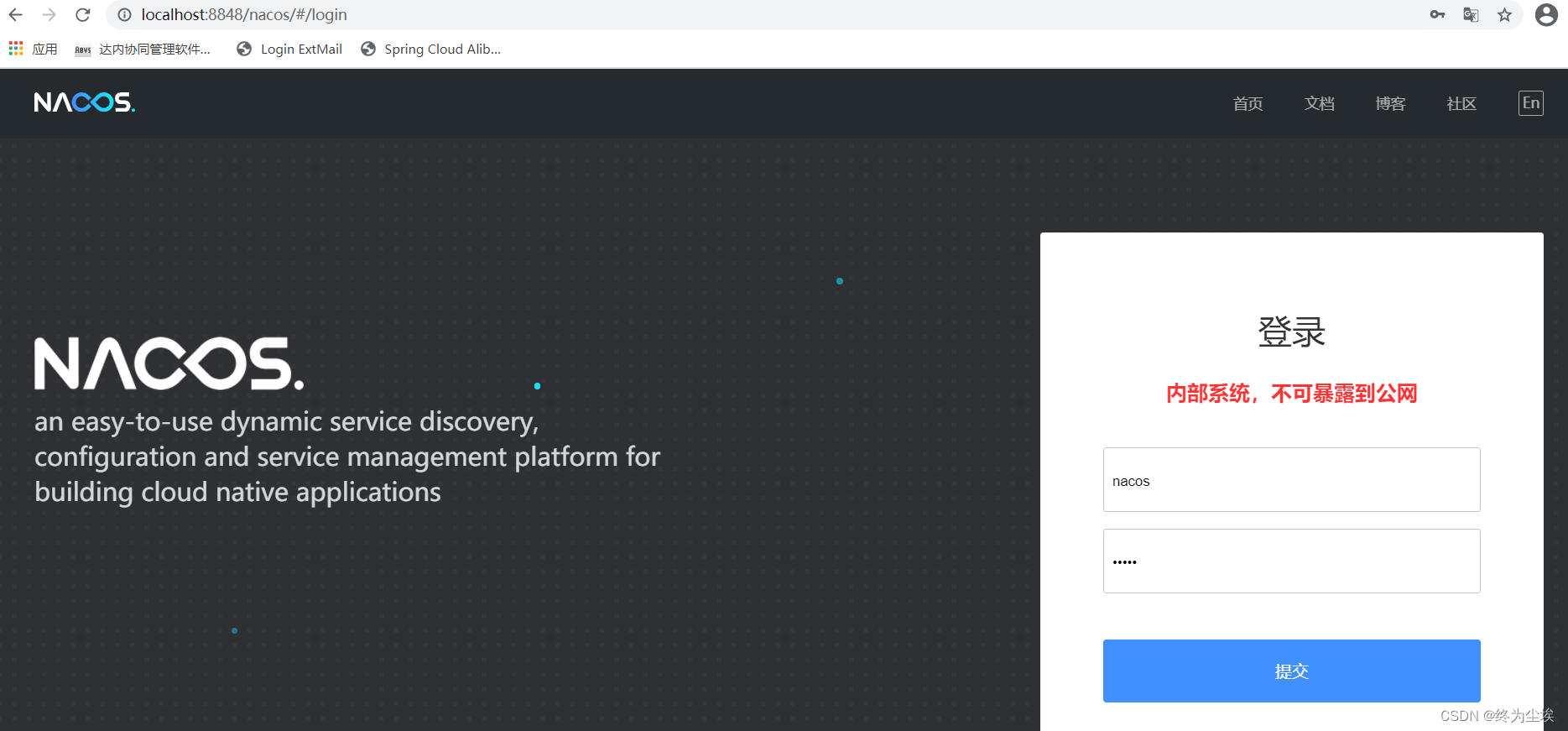
如果是首次访问,会出现这个界面.
登录系统:
用户名:nacos
密码:nacos
登录之后可以进入后台列表,不能关闭启动nacos的dos窗口,我们要让我们编写的项目注册到Nacos,才能真正是微服务项目。
使用Idea启动Nacos
之前我们启动Nacos都是使用dos命令行
启动过程比较复杂,命令比较长
Idea实际上支持我们更加方便的启动Nacos
步骤1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D4bB98Mi-1667648331230)(image-20220822092823703.png)]](https://1000bd.com/contentImg/2024/04/28/4bb8b7f1447359ea.png)
步骤2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T0FNWKza-1667648331232)(image-20220505142258656.png)]](https://1000bd.com/contentImg/2024/04/28/546c2bf534c20b9b.png)
步骤3:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EZcdDACu-1667648331235)(image-20220505142111568.png)]](https://1000bd.com/contentImg/2024/04/28/a94913cd76aa90eb.png)
配置成功之后Nacos就会出现在idea的启动选项中了,这种方法实际上只是为了简便大家启动nacos的操作,还是需要掌握命令行的启动方式的!
Dubbo概述
什么是RPC
RPC是Remote Procedure Call的缩写 翻译为:远程过程调用。目标是为了实现两台(多台)计算机\服务器,相互调用方法\通信的解决方案。RPC只是实现远程调用的一套标准。
该标准主要规定了两部分内容:
1.通信协议
2.序列化协议为了方便大家理解RPC,下面的图片帮助理解
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5XY4SLgn-1667648507826)(image-20220505143449423.png)]](https://1000bd.com/contentImg/2024/04/28/87d5dd82abd8f417.png)
上面图是老婆和老公在家的时,老婆让老公洗碗的调用流程。这个流程可以理解为项目内的功能的调用,类似面向对象编程实例化对象,调用方法的过程,但是这个调用关系如果是远程的,意思是老婆和老公现在是两个不同的项目。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zs5nqca7-1667648507827)(image-20220505143611367.png)]](https://1000bd.com/contentImg/2024/04/28/0cb5b4efba2373af.png)
我们看到上图中,远程调用必须借助一个通信设备,图片中是手机通信协议
通信协议指的就是远程调用的通信方式。实际上这个通知的方式可以有多种,例如:写信,飞鸽传书,发电报。在程序中,通信方法实际上也是有多种的,每种通信方式会有不同的优缺点。
序列化协议
序列化协议指通信内容的格式,双方都要理解这个格式。上面的图片中,老婆给老公发信息,一定是双方都能理解的信息。发送信息是序列化过程,接收信息需要反序列化,程序中,序列化的方式也是多种的,每种序列化方式也会有不同的优缺点。
什么是Dubbo
上面对RPC有基本认识之后,再学习Dubbo就简单了。Dubbo是一套RPC框架。既然是框架,我们可以在框架结构高度,定义Dubbo中使用的通信协议,使用的序列化框架技术,而数据格式由Dubbo定义,我们负责配置之后直接通过客户端调用服务端代码。可以说Dubbo就是RPC概念的实现。
Dubbo是SpringCloudAlibaba提供的框架,能够实现微服务相互调用的功能!
Dubbo的发展历程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gh98cJuj-1667648507829)(image-20220505151527323.png)]](https://1000bd.com/contentImg/2024/04/28/fdcb9d49440dda38.png)
Dubbo历程
在dubbo2012年底停止更新后,国内很多公司在Dubbo的基础上进行修改,继续更新,比较知名的修改版本就是当当网的DubboX;2012年底dubbo停止更新后到2017年dubbo继续更新之前,2015SpringCloud开始兴起,当时没有阿里的框架,国内公司要从SpringCloud和Dubbo中抉择使用哪个微服务方案。
我们学习的Dubbo指的都是2.7之后的版本
是能够和SpringCloudAlibaba配合使用的
Dubbo对协议的支持
RPC框架分通信协议和序列化协议,Dubbo框架支持多种通信协议和序列化协议,可以通过配置文件进行修改。
Dubbo支持的通信协议:
- dubbo协议(默认)
- rmi协议
- hessian协议
- http协议
- webservice
- …
支持的序列化协议
- hessian2(默认)
- java序列化
- compactedjava
- nativejava
- fastjson
- dubbo
- fst
- kryo
Dubbo默认情况下,支持的协议有如下特征:
- 采用NIO单一长链接
- 优秀的并发性能,但是处理大型文件的能力差
Dubbo方便支持高并发和高性能。
Dubbo服务的注册与发现
在Dubbo的调用过程中,必须包含注册中心的支持,即项目调用服务的模块必须在同一个注册中心中,注册中心推荐阿里自己的Nacos,兼容性好,能够发挥最大性能。但是Dubbo也支持其它软件作为注册中心(例如Redis,zookeeper等)。
服务发现,即消费端自动发现服务地址列表的能力,是微服务框架需要具备的关键能力,借助于自动化的服务发现,微服务之间可以在无需感知对端部署位置与 IP 地址的情况下实现通信。
如上面RPC的示例中,老婆就是服务的消费端,她能发现老公具备的服务,如果老婆调用了老公的服务,就是完成了Dubbo调用。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MU82XiL0-1667648507830)(image-20220505153224006.png)]](https://1000bd.com/contentImg/2024/04/28/108f390744e5b8ba.png)
consumer服务的消费者,指服务的调用者(使用者)也就是老婆的位置,provider服务的提供者,指服务的拥有者(生产者)也就是老公的位置。Dubbo中,远程调用依据是服务的提供者在Nacos中注册的服务名称,一个服务名称,可能有多个运行的实例,任何一个空闲的实例都可以提供服务。
常见面试题:Dubbo的注册发现流程
1.首先服务的提供者启动服务时,将自己的具备的服务注册到注册中心,其中包括当前提供者的ip地址和端口号等信息,Dubbo会同时注册该项目提供的远程调用的方法
2.消费者(使用者)启动项目,也注册到注册中心,同时从注册中心中获得当前项目具备的所有服务列表
3.当注册中心中有新的服务出现时,(在心跳时)会通知已经订阅发现的消费者,消费者会更新所有服务列表
4.RPC调用,消费者需要调用远程方法时,根据注册中心服务列表的信息,只需服务名称,不需要ip地址和端口号等信息,就可以利用Dubbo调用远程方法了。
负载均衡
什么是负载均衡
在实际项目中,一个服务基本都是集群模式的,也就是多个功能相同的项目在运行,这样才能承受更高的并发。这时一个请求到这个服务,就需要确定访问哪一个服务器。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JC5yTlXT-1667648507832)(1655891169062.png)]](https://1000bd.com/contentImg/2024/04/28/47bdaeaaf08608a1.png)
Dubbo框架内部支持负载均衡算法,能够尽可能的让请求在相对空闲的服务器上运行,在不同的项目中,可能选用不同的负载均衡策略,以达到最好效果。
Loadbalance:就是负载均衡的意思
Dubbo内置负载均衡策略算法
- random loadbalance:随机分配策略(默认)
- round Robin Loadbalance:权重平均分配
- leastactive Loadbalance:活跃度自动感知分配
- consistanthash Loadbalance:一致性hash算法分配
实际运行过程中,每个服务器性能不同,在负载均衡时,都会有性能权重,这些策略算法都考虑权重问题。
随机分配策略
假设我们当前3台服务器,经过测试它们的性能权重比值为5:3:1,下面可以生成一个权重模型。
5:3:1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u8k0iqaa-1667648507833)(image-20220923162323931.png)]](https://1000bd.com/contentImg/2024/04/28/a576082b7c5eec2e.png)
随机生成一个随机数,在哪个范围内让哪个服务器运行。
优点:
算法简单,效率高,长时间运行下,任务分配比例准确;
缺点:
偶然性高,如果连续的几个随机请求发送到性能弱的服务器,会导致异常甚至宕机。
权重平滑分配
如果几个服务器权重一致,那么就是依次运行,但是服务器的性能权重一致的可能性很小,所以我们需要权重平滑分配。
一个优秀的权重分配算法,应该是让每个服务器都有机会运行的,如果一个集群服务器性能比为5:3:1服务为A,B,C,
1>A 2>A 3>A 4>A 5>A
6>B 7>B 8>B
9>C
上面的安排中,连续请求一个服务器肯定是不好的,我们希望所有的服务器都能够穿插在一起运行
Dubbo2.7之后更新了这个算法使用"平滑加权算法"优化权重平均分配策略
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-in1DTlyt-1667649424381)(day04/1655955337434.png)]](https://1000bd.com/contentImg/2024/04/28/712a123642a9b384.png)
优点:
能够尽可能的在权重要求的情况下,实现请求的穿插运行(交替运行),不会发生随机策略中的偶发情况;
缺点
服务器较多时,可能需要减权和复权的计算,需要消耗系统资源。
活跃度自动感知
记录每个服务器处理一次请求的时间,按照时间比例来分配任务数,运行一次需要时间多的分配的请求数较少。
一致性Hash算法
根据请求的参数进行hash运算,以后每次相同参数的请求都会访问固定服务器,因为根据参数选择服务器,不能平均分配到每台服务器上,使用的也不多。
Dubbo实现微服务调用
确定调用结构
- order模块调用stock模块的减少库存的功能
- order模块调用cart模块的删除购物车的功能
- business模块调用order新增订单的功能
要想实现Dubbo调用,必须按照Dubbo规定的配置和行业标准的结构来实现;Dubbo调用的好处是直接将要消费的目标(例如order模块中消费stock的方法)编写在当前消费者的业务逻辑层(Service)中,无需编写新的代码结构,开发流程不会因为Dubbo而变化。
Dubbo生产者消费者配置
Dubbo生产者消费者相同的配置;
pom文件添加dubbo依赖,yml文件配置dubbo信息.生产者
-
要有service接口项目
-
提供服务的业务逻辑层实现类(ServiceImpl)要添加@DubboService注解
-
SpringBoot启动类要添加@EnableDubbo注解
消费者
- pom文件添加消费模块的service依赖
- 业务逻辑层远程调用前,模块使用@DubboReference注解获取业务逻辑层实现类对象
Seata概述
下载Seata
https://github.com/seata/seata/releases
https://github.com/seata/seata/releases/download/v1.4.2/seata-server-1.4.2.zip
两个网址二选一.
什么是Seata
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务,也是Spring Cloud Alibaba提供的组件。
Seata官方文档:https://seata.io/zh-cn/
更多信息可以通过官方文档获取
为什么需要Seata
之前单体项目中的事务使用的技术叫Spring声明式事务,能够保证一个业务中所有对数据库的操作要么都成功,要么都失败,来保证数据库的数据完整性。但是在微服务的项目中,业务逻辑层涉及远程调用,当前模块发生异常,无法操作远程服务器回滚。这时要想让远程调用也支持事务功能,就需要使用分布式事务组件Seata。
Seata保证微服务远程调用业务的原子性
Seata将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata的运行原理
观察下面事务模型
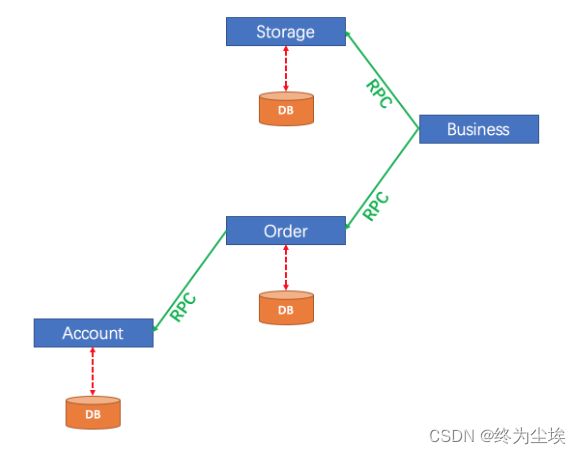
上面结构是比较典型的远程调用结构。
如果account操作数据库失败需要让order模块和storage模块撤销(回滚)操作,声明式事务不能完成这个操作,需要使用Seata来解决。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RFz98R81-1667650451039)(image-20220506115157648.png)]](https://1000bd.com/contentImg/2024/04/28/94633b6925f2e103.png)
Seata构成部分包含
- 事务协调器TC
- 事务管理器TM
- 资源管理器RM
我一般使用AT(自动)模式完成分布式事务的解决
AT模式运行过程
1.事务的发起方™会向事务协调器(TC)申请一个全局事务id,并保存;
2.Seata会管理事务中所有相关的参与方的数据源,将数据操作之前和之后的镜像都保存在undo_log表中,这个表是seata组件规定的表,没有它就不能实现效果,依靠它来实现提交(commit)或回滚(roll back)的操作;
3.事务的发起方™会连同全局id一起通过远程调用,运行资源管理器(RM)中的方法;
4.RM接收到全局id,去运行指定方法,并将运行结果的状态发送给TC;
5.如果所有分支运行都正常,TC会通知所有分支进行提交,真正的影响数据库内容;
反之如果所有分支中有任何一个分支发生异常,TC会通知所有分支进行回滚,数据库数据恢复为运行之前的内容。
Seata的启动
seata也是java开发的,启动方式和nacos很像,只是启动命令不同。
它要求配置环境变量中Path属性值有java的bin目录路径
解压后路径不要用中文,不要用空格,也是解压之后的bin目录下。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jU17k5FS-1667650451040)(1655972562021.png)]](https://1000bd.com/contentImg/2024/04/28/aa54d667b646e3a1.png)
在路径上输入cmd进入dos窗口
mac系统同学直接参考启动nacos的命令
D:\tools\seata\seata-server-1.4.2\bin>seata-server.bat -h 127.0.0.1 -m file- 1
输入后,最后出现8091端口的提示即可!
如果想使用idea启动seata,和之前nacos启动相似
使用Seata
配置Seata
cart\stock\order三个模块时需要Seata支持进行事务管理的模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0VNauC8c-1667700872100)(image-20220506115157648.png)]](https://1000bd.com/contentImg/2024/04/28/a009ef524086b029.png)
这三个模块都需要添加下面pom依赖和配置
<dependency> <groupId>io.seatagroupId> <artifactId>seata-spring-boot-starterartifactId> dependency> <dependency> <groupId>com.github.pagehelpergroupId> <artifactId>pagehelper-spring-boot-starterartifactId> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>fastjsonartifactId> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面修改cart\stock\order模块的application-dev.yml
代码如下
seata: tx-service-group: csmall_group # 定义事务的分组,一般是以项目为单位的,方便与其它项目区分 service: vgroup-mapping: csmall_group: default # csmall_group分组的配置,default会默认配置Seata grouplist: default: localhost:8091 # 配置Seata服务器的地址和端口号- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意同一个事务必须在同一个tx-service-group中,同时指定相同的seata地址和端口。
business模块的配置
business模块作为当前分布式事务模型的触发者
它应该是事务的起点,但是它不连接数据库,所以配置稍有不同
pom文件seata依赖仍然需要,但是只需要seata依赖
<dependency> <groupId>io.seatagroupId> <artifactId>seata-spring-boot-starterartifactId> dependency>- 1
- 2
- 3
- 4
application-dev.yml是一样的
seata: tx-service-group: csmall_group # 定义事务的分组,一般是以项目为单位的,方便与其它项目区分 service: vgroup-mapping: csmall_group: default # csmall_group分组的配置,default会默认配置Seata grouplist: default: localhost:8091 # 配置Seata服务器的地址和端口号- 1
- 2
- 3
- 4
- 5
- 6
- 7
添加完必要的配置之后,要想激活Seata功能非常简单,只要在起点业务的业务逻辑方法上添加专用的注解即可,添加这个注解的模块就是模型中的TM,他调用的所有远程模块都是RM。
business模块添加订单的业务逻辑层开始的方法
@Service @Slf4j public class BusinessServiceImpl implements IBusinessService { // Dubbo调用order模块的新增订单功能 // 当前business是单纯的消费者,不需要在类上编写@DubboService @DubboReference private IOrderService dubboOrderService; // Global:全局 , Transactional事务 // 一旦这个方法标记为@GlobalTransactional // 就相当于设置了分布式事务的起点,当前模块在事务模型中就是TM事务管理器 // 最终效果就是当前方法开始之后,所有的远程调用操作数据库的功能都在同一个事务中 // 体现出事务原子性的特征,要么都运行,要么都不运行 @GlobalTransactional @Override public void buy() { // 代码略... } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
先启动nacos,再启动seata,然后按顺序启动四个服务cart\stock\order\business,利用knife4j进行访问,business模块 localhost:20000/doc.html。
当前测试常见错误
如果seata启动时发送内存不足的错误,可以参考下面的文章解决:
https://blog.csdn.net/he_lei/article/details/116229467
保证当前seata的环境变量是java1.8,在windows系统中运行seata可能出现不稳定的情况,重启seata即可解决。
Seata效果
要想seata出现效果,我们要有一个发生异常的情况,当发生异常时,去观察是否会回滚,可以编写代码随机的抛出异常,来根据是否有异常,是否回滚,判断seata是否有效。
OrderServiceImpl在新增订单方法前添加随机发送异常的方法
@Override public void orderAdd(OrderAddDTO orderAddDTO) { // 1.减少订单中商品的库存数(要调用stock模块的功能) // 先实例化业务逻辑层需要的指定类型DTO才能调用 StockReduceCountDTO countDTO=new StockReduceCountDTO(); countDTO.setCommodityCode(orderAddDTO.getCommodityCode()); countDTO.setReduceCount(orderAddDTO.getCount()); // dubbo调用stock执行减少库存的方法 stockService.reduceCommodityCount(countDTO); // 2.从购物车中删除用户勾选的商品(要调用cart模块的功能) cartService.deleteUserCart(orderAddDTO.getUserId(), orderAddDTO.getCommodityCode()); // ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ if(Math.random()<0.5){ throw new CoolSharkServiceException( ResponseCode.INTERNAL_SERVER_ERROR,"发送随机异常!"); } // 3.将orderAddDTO中的信息转换为Order实体类,然后新增到数据库中 Order order=new Order(); BeanUtils.copyProperties(orderAddDTO,order); // 执行新增 orderMapper.insertOrder(order); log.info("新增订单信息为:{}",order); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
再次测试localhost:20000/doc.html,点击触发购买业务的功能,观察是否发生异常,以及发生异常时数据库是否没有变化,正常运行时,数据库数据是否正常变化。
Seata其他模式介绍
之前讲解了Seata软件AT模式的运行流程,AT模式的运行有一个非常明显的前提条件,这个条件不满足,就无法使用AT模式。条件就是事务分支都必须是操作关系型数据库(Mysql\MariaDB\Oracle),因为关系型数据库才支持提交和回滚,其它非关系型数据库都是直接影响数据(例如Redis),所以如果我们在业务过程中有一个节点操作的是Redis或其它非关系型数据库时,就无法使用AT模式。
除了AT模式之外还有TCC、SAGA 和 XA 事务模式
TCC模式
简单来说,TCC模式就是自己编写代码完成事务的提交和回滚,在TCC模式下,我们需要为参与事务的业务逻辑编写一组共3个方法。
prepare:准备
commit:提交
rollback:回滚
- prepare方法是每个模块都会运行的方法
- 当所有模块的prepare方法运行都正常时,运行commit
- 当任意模块运行的prepare方法有异常时,运行rollback
这样的话所有提交或回滚代码都由自己编写。
优点:虽然代码是自己写的,但是事务整体提交或回滚的机制仍然可用(仍然由TC来调度);
缺点:每个业务都要编写3个方法来对应,代码冗余,而且业务入侵量大。
SAGA模式
SAGA模式的思想是对应每个业务逻辑层编写一个新的类,可以设置指定的业务逻辑层方法发生异常时,运行当新编写的类中的代码,相当于将TCC模式中的rollback方法定义在了一个新的类中。
优点:这样编写代码不影响已经编写好的业务逻辑代码,一般用于修改已经编写完成的老代码;
缺点:是每个事务分支都要编写一个类来回滚业务,会造成类的数量较多,开发量比较大。
XA模式
支持XA协议的数据库分布式事务,使用比较少
Sentinel
官网地址:https://sentinelguard.io/zh-cn/
下载地址:https://github.com/alibaba/Sentinel/releases
什么是Sentinel
Sentinel英文翻译"哨兵\门卫",Sentinel也是Spring Cloud Alibaba的组件。随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
为什么需要Sentinel
为了保证服务器运行的稳定性,在请求数到达设计最高值时,将过剩的请求限流,保证在设计的请求数内的请求能够稳定完成处理。
-
丰富的应用场景
双11,秒杀,12306抢火车票
-
完备的实时状态监控
可以支持显示当前项目各个服务的运行和压力状态,分析出每台服务器处理的秒级别的数据
-
广泛的开源生态
很多技术可以和Sentinel进行整合,SpringCloud,Dubbo,而且依赖少配置简单
-
完善的SPI扩展
Sentinel支持程序设置各种自定义的规则
基本配置
我们的限流针对的是控制器方法,我们找一个简单的模块来测试和观察限流效果
在csmall-stock-webapi模块中
添加sentinel的依赖
<dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-sentinelartifactId> dependency>- 1
- 2
- 3
- 4
- 5
application-dev.yml文件添加配置
spring: application: # 为当前项目起名,这个名字会被Nacos记录并使用 name: nacos-stock cloud: sentinel: transport: dashboard: localhost:8080 # 配置Sentinel提供的运行状态仪表台的位置 # 执行限流的端口号,每个项目需要设置不同的端口号,例如cart模块可以设置为8722 port: 8721 nacos: discovery: # 配置Nacos所在的位置,用于注册时提交信息 server-addr: localhost:8848- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Sentinel启动
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zcl5P58u-1667700872101)(image-20220824114843759.png)]](https://1000bd.com/contentImg/2024/04/28/4f529a62561c4512.png)
windows直接双击start-sentinel.bat文件,没有就文件地址栏cmd,加上
java -jar sentinel-dashboard-1.8.2.jar- 1
mac使用下面命令执行jar包
java -jar sentinel-dashboard-1.8.2.jar- 1
启动之后,打开浏览器http://localhost:8080/,会看到下面的界面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QlJlmCSw-1667700872102)(image-20220727115123049.png)]](https://1000bd.com/contentImg/2024/04/28/6d114b0897c77562.png)
用户名和密码都是:sentinel
刚开始什么都没有,是空界面,后面我们有控制器的配置就会出现信息了。
限流方法
我们以stock模块为例,演示限流的效果,StockController在减少库存的方法上添加限流的注解
@PostMapping("/reduce/count") @ApiOperation("减少商品库存数") // @SentinelResource注解需要标记为控制层方法上,在该方法运行后,会被Sentinel监测 // 该方法运行前,Sentinel监测不到,必须至少运行一次后才可以开始监测信息 // "减少商品库存数"这个名称就是显示在Sentinel上该方法的名称 @SentinelResource("减少商品库存数") public JsonResult reduceCommodityCount( StockReduceCountDTO stockReduceCountDTO){ // 调用业务逻辑层 stockService.reduceCommodityCount(stockReduceCountDTO); return JsonResult.ok("库存减少完成!"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
nacos\seata\sentinel要启动
重启stock服务(其它服务都可以停掉)
如果不运行knife4j测试,sentinel的仪表盘不会有任何信息,在第一次运行了减少库存方法之后,sentinel的仪表盘才会出现nacos-stock的信息,选中这个信息点击"簇点链路",找到我们编写的"减少商品库存数"方法,点 “+流控”,设置流控规则。
我们先设置QPS为1也就是每秒请求数超过1时,进行限流,然后我们可以快速双击knife4j减少库存的方法,触发它的流控效果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7EJ3Y6ZW-1667700872107)(image-20220824144103301.png)]](https://1000bd.com/contentImg/2024/04/28/0e00ccf4f451e9cd.png)
这样的流控没有正确的消息提示,需要自定义方法进行正确的提示给用户看到。
自定义限流方法
对于被限流的请求,我们可以自定义限流的处理方法,默认情况下可能不能正确给用户提示,一般情况下,对被限流的请求也要有"服务器忙请重试"或类似的提示。
StockController类中@SentinelResource注解中,可以自定义处理限流情况的方法
@PostMapping("/reduce/count") @ApiOperation("减少商品库存数") // @SentinelResource注解需要标记为控制层方法上,在该方法运行后,会被Sentinel监测 // 该方法运行前,Sentinel监测不到,必须至少运行一次后才可以开始监测信息 // "减少商品库存数"这个名称就是显示在Sentinel上该方法的名称 // blockHandler就是指定被限流时,要运行自定义方法的属性,"blockError"就是方法名 @SentinelResource(value = "减少商品库存数",blockHandler = "blockError") public JsonResult reduceCommodityCount( StockReduceCountDTO stockReduceCountDTO){ // 调用业务逻辑层 stockService.reduceCommodityCount(stockReduceCountDTO); return JsonResult.ok("库存减少完成!"); } // Sentinel自定义限流方法定义规则如下 // 1.访问修饰符必须是public // 2.返回值类型必须和控制器方法一致 // 3.方法名必须是控制器方法注解中blockHandler定义的名称 // 4.方法参数必须包含控制器的所有参数,而且可以额外添加BlockException的异常类型参数 public JsonResult blockError(StockReduceCountDTO stockReduceCountDTO, BlockException e){ // 运行这个方法表示当前请求被Sentinel限流了,需要给出被限流的提示 return JsonResult.failed(ResponseCode.INTERNAL_SERVER_ERROR, "服务器忙,请稍后再试"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
重启stock-webapi模块,再次尝试被限流,观察被限流的提示。
QPS与并发线程数
-
QPS:是每秒请求数
单纯的限制在一秒内有多少个请求访问控制器方法
-
并发线程数:是当前正在使用服务器资源请求线程的数量
限制的是使用当前服务器的线程数
并发线程数测试可能需要阻塞当前控制器方法一段时间,方便测试
stockService.reduceCommodityCount(stockReduceCountDTO); try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } return JsonResult.ok("库存减少完成!");- 1
- 2
- 3
- 4
- 5
- 6
- 7
自定义降级方法
所谓降级就是正常运行控制器方法的过程中,控制器方法发生了异常,Sentinel支持我们运行别的方法来处理异常,或运行别的业务流程处理。
我们也学习过处理控制器异常的统一异常处理类,和我们的降级处理有类似的地方,但是Sentinel降级方法优先级高,而且针对单一控制器方法编写。
StockController类中@SentinelResource注解中,可以定义处理降级情况的方法
@PostMapping("/reduce/count") @ApiOperation("减少商品库存数") // @SentinelResource注解需要标记为控制层方法上,在该方法运行后,会被Sentinel监测 // 该方法运行前,Sentinel监测不到,必须至少运行一次后才可以开始监测信息 // "减少商品库存数"这个名称就是显示在Sentinel上该方法的名称 // blockHandler就是指定被限流时,要运行自定义方法的属性,"blockError"就是方法名 @SentinelResource( value = "减少商品库存数", blockHandler = "blockError", fallback = "fallbackError") public JsonResult reduceCommodityCount( StockReduceCountDTO stockReduceCountDTO){ // 调用业务逻辑层 stockService.reduceCommodityCount(stockReduceCountDTO); // 随机发生异常,测试服务降级效果 if(Math.random()<0.5){ // 如果发生这个异常,就会运行降级方法 throw new CoolSharkServiceException( ResponseCode.INTERNAL_SERVER_ERROR, "随机异常"); } return JsonResult.ok("库存减少完成!"); } // 限流方法略..... // 降级方法: 由@SentinelResource注解fallback属性指定的方法 // 方法定义规则和限流方法基本一致,方法的参数中,最后的参数可以额外添加Throwable类型 // 当控制器方法发生异常时,Sentinel会调用这个方法,优先级比统一异常处理类高 // 实际开发中,可能包含一些业务例如:运行老版本代码,或使用户获得一些补偿 public JsonResult fallbackError(StockReduceCountDTO stockReduceCountDTO, Throwable throwable){ // 我们的业务仅仅是输出异常提示 return JsonResult.failed(ResponseCode.INTERNAL_SERVER_ERROR, "运行发生异常,服务降级!"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
重启csmall-stock-webapi模块测试。当发生随机异常时,就运行降级方法,当没有发生随机异常时,就正常运行!
SpringGateway网关
奈非框架简介
早期(2020年前)奈非提供的微服务组件和框架受到了很多开发者的欢迎,这些框架和SpringCloud Alibaba的对应关系我们要了解,现在还有很多旧项目维护是使用奈非框架完成的微服务架构
Nacos对应Eureka都是注册中心,Dubbo对应Ribbon+feign都是实现微服务远程RPC调用的组件
Sentinel对应Hystrix都是做项目限流熔断降级的组件,Gateway对应Zuul都是网关组件,Gateway框架不是阿里写的,是Spring提供的。什么是网关
"网"指网络,“关"指关口或关卡,网关:就是指网络中的关口\关卡,网关就是当前微服务项目的"统一入口”。
程序中的网关就是当前微服务项目对外界开放的统一入口,所有外界的请求都需要先经过网关才能访问到我们的程序,提供了统一入口之后,方便对所有请求进行统一的检查和管理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M0dTZw1i-1667700872108)(image-20220216164903290.png)]](https://1000bd.com/contentImg/2024/04/28/dcbb33850645a6b4.png)
网关的主要功能有:
- 将所有请求统一经过网关
- 网关可以对这些请求进行检查
- 网关方便记录所有请求的日志
- 网关可以统一将所有请求路由到正确的模块\服务上
路由的近义词就是"分配"。
Spring Gateway简介
我们使用Spring Gateway作为当前项目的网关框架,Spring Gateway是Spring自己编写的,也是SpringCloud中的组件。
SpringGateway官网:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
简单网关演示
SpringGateway网关是一个依赖,不是一个软件,所以我们要使用它的话,必须先创建一个SpringBoot项目。
这个项目也要注册到Nacos注册中心,因为网关项目也是微服务项目的一个组成部分。
beijing和shanghai是编写好的两个项目,gateway项目就是网关项目,需要添加相关配置。
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-gatewayartifactId> dependency> <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-loadbalancerartifactId> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们从yml文件配置开始添加
server: port: 9000 spring: application: name: gateway cloud: nacos: discovery: # 网关也是微服务项目的一部分,所以也要注册到Nacos server-addr: localhost:8848 gateway: # routes就是路由的意思,这是属性是一个数组类型,其中的值都是数组元素 routes: # 数组元素配置中,-开头表示一个数组元素的开始,后面所有内容都是这个元素的内容 # id表示当前路由的名称,和任何之前出现过的名字没有任何关联,唯一的要求就是不要后之后的id重复 - id: gateway-beijing # 下面的配置是路由的目标,也就是目标的服务器名称 # lb是LoadBalance的缩写,beijing是服务器名称 uri: lb://beijing # predicates是断言的意思,就是满足某个条件时,去执行某些操作的设置 predicates: # predicates也是一个数组,配置断言的内容 # 这个断言的意思就是如果访问的路径是/bj/开头(**表示任何路径), # 就去访问上面定好的beijing服务器 # ↓ P一定要大写!!!!!!! - Path=/bj/** # spring.cloud.gateway.routes[0].uri # spring.cloud.gateway.routes[0].predicates[0]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
下面启动服务测试访问网关,使用路由功能到beijing服务器,保证beijing和gateway启动。
关于路由的配置目标
路由规则解释:路由规则一定是在开发之前就设计好的,一般可以使用约定好的路径开头来实现的。
例如:
gateway项目中如果路径以 /bj开头,就是要访问beijing项目,如果路径以 /sh开头.就是养访问shanghai项目。
具体实现来讲,所有的外界请求都要统一访问往网关
例如
localhost:9000/bj/show 9000后面的路径提取出来是/bj/show根据上面设计访问beijing模块
localhost:9000/sh/show 9000后面的路径提取出来是/sh/show根据上面设计访问shanghai模块
csmall项目
如果路径是 /base/business开头的, 就去找nacos-business服务器
如果路径是 /base/cart开头的, 就去找nacos-cart服务器
如果路径是 /base/order开头的, 就去找nacos-order服务器
如果路径是 /base/stock开头的, 就去找nacos-stock服务器
分布式
有多台服务器负责相同的业务
例如stock模块有3台服务器,这3台服务器就是分布式部署的
我们的微服务一个项目有多个模块,每个模块都可以单独运行
当他们都启动时,也是分布式部署的特征
-
相关阅读:
3D感知技术(2)3D数据获取技术概述
UNIAPP实战项目笔记34 购物车的单选和全选单选联动
Web学习笔记-Vue3(环境配置、概念、整体布局设计)
TiDB Lightning 目标数据库要求
【无标题】
如何将MindSpore模型转ONNX格式并使用OnnxRuntime推理---全流程开发指导
MySQL单表查询和多表查询
tep时隔8个月迎来重大全新升级
反序列化漏洞(2), 分析调用链, 编写POC
i711800h和r54600h哪个好
- 原文地址:https://blog.csdn.net/weixin_43121885/article/details/127706266
