-
Python——弹幕词频统计及其文本分析(绘制词云)(含源代码)
利用python数据结构(list, dict, set等)完成简单的文本分析任务。
弹幕是现下视频网站,尤其是短视频网站提供的关键功能之一。以B站为例,其有着特殊的弹幕文化,且在视频的不同部分往往会有不同话题的弹幕:比如在视频开头会出 现“来啦”“x小时前”“第一!”;在up主暗示一键三连之后常常会出现“下次一定”或者“你币有 了”;和up主建立默契之后,观众可以判断视频是否有恰饭,往往在广告之前会出现“要素察 觉”“恰饭”“快跑”等等。因此,弹幕经常被作为测度用户(viewer)与视频作者(up主)之间交互行为的关键数据。本次作业提供的数据来自B站某知名up主,已上传至课程资料的data目录下,数据格式说明如下。 a. 弹幕文件:danmuku.csv,为2799000 rows × 3 columns,本次作业仅使用第一列,即弹幕的文本内容。 b . 停用词表示例,stopwords_list.txt 请大家尝试完成以下数据分析任务:
1. 使用danmuku.csv,其中一个弹幕可以视为一个文档(document),读入文档并分词(可以使用jieba或pyltp)。
2. 过滤停用词(可用stopwords_list.txt,或自己进一步扩充)并统计词频,输出特定数目的高频词和低频词进行观察。建议将停用词提前加入到jieba等分词工具的自定义词典中,避免停用词未被正确分词。
3. 根据词频进行特征词筛选,如只保留高频词,删除低频词(出现次数少于5之类),并得到特征词组成的特征集。
4. 利用特征集为每一条弹幕生成向量表示,可以是0,1表示(one-hot,即该特征词在弹幕中是否出现)也可以是出现次数的表示(该特征词在弹幕中出现了多少次)。注意,可能出现一些过短的弹幕,建议直接过滤掉。
5. 利用该向量表示,随机找几条弹幕,计算不同弹幕间的语义相似度,可尝试多种方式,如欧几里得距离或者余弦相似度等,并观察距离小的样本对和距离大的样本对是否在语义上确实存在明显的差别。请思考,这种方法有无可能帮助我们找到最有代表性的弹幕?
6. (附加)能不能对高频词(如top 50之类)进行可视化呈现(WordCloud包)?
7. (附加)能不能考虑别的特征词构建思路,如常用的TF-IDF,即一方面词的频率要高,另一方面,词出现的文档数越少越好,观察其与仅利用词频所得的结果有何差异,哪个更好?
8. (附加)了解一下word2vec等深度学习中常用的词向量表征(如gensim和pyltp中均有相关的库),并思考如果用这种形式的话,那么一条弹幕会被表示成什么形式?弹幕之间计算相似性的时候,会带来哪些新的问题?
注意:不要使用jieba等库中提供的函数实现特征词抽取和文档表示,要求自己使用相关数据结构来实现;要通过函数对代码进行封装,并在main函数中调用。
目录
2.Restopwords(): 读⼊停⽤词,返回⼀个停⽤词列表
3.Comments_lines(): 将评论的数据集读⼊并返回已每条弹幕为元素
4.Word_frequ(rows,stopwords): 统计词频函数
6.Matrix(counts1,rows): 为每⼀条弹幕⽣成向量函数
7.Distance(n,matrics): 计算随机两个弹幕之间余弦距离和欧式距离
8.plot_Wc(counts1): 传⼊词频字典绘制词云图
一、完整代码
- import jieba
- import csv
- import random
- import math
- import wordcloud
- import matplotlib.pyplot as plt
- def Restopwords():
- ''' 读取停用词函数'''
- with open("D:\学习文件\大三上\现代程序设计\第一次作业\dataset\stopwords_list.txt",'r',encoding='utf-8') as f:
- stopwords = f.read().splitlines() #用splitlines()函数 将读取的每一行作为一个元素存入列表stopwords中
- return stopwords #返回停用词列表
- def Comments_lines():
- '''读取数据集的函数'''
- with open("D:\学习文件\大三上\现代程序设计\第一次作业\dataset\danmuku.csv","r",encoding='utf-8') as f:
- reader = csv.reader(f) #使用reader()函数,将整个数据集每行作为一个元素,存入reader列表
- rows= [row[0] for row in reader] #对reader进行遍历,只取第一列弹幕作为元素
- rows = rows[0:5000]
- return rows #返回已每条弹幕作为元素的列表
- def Word_frequ(rows,stopwords):
- '''这是一个统计词频的函数'''
- coms = [] #这是一个承接所有词组的列表
- for row in rows: #对每条弹幕进行遍历
- com = jieba.lcut(row) #使用jieba库进行分词
- coms.extend(com) #将所有分出的词组加入coms列表
- counts = {} #这是一个统计词频的字典
- for word in coms: #对每个词进行遍历
- if len(word) == 1: #不使用单字作为一个词
- continue
- elif word in stopwords: #在停用词列表中的剔出
- continue
- else:
- counts[word] = counts.get(word, 0) + 1 #如果该词在字典中存在,则值再加1,要是不存在就创建一个
- return counts
- def Screen(counts):
- '''这是一个筛选词频的函数'''
- items = list(counts.items()) #将之前的词频字典转化为元组为元素的列表
- items1 = items[:]
- for i in items1:
- #如果词频小于5就将其删除
- if i[1] <= 5:
- items.remove(i)
- counts1 = dict(items)
- return counts1
- def Matrix(counts1,rows):
- '''这是一个根据弹幕生成向量矩阵的函数'''
- matrics = []
- n = len(counts1)
- items = list(counts1.keys())
- for row in rows: #对每条弹幕进行遍历
- words = jieba.lcut(row) #对一条弹幕进行分词
- if len(words) <=7: #如果一条弹幕总词组数量小于7,则不计入矩阵
- pass
- else:
- #找到对于单词对应的位置,在该位置设置标记
- lis = [0]*n
- for word in words:
- if word in items:
- lis[items.index(word)] = 1
- matrics.append(lis)
- return matrics,n
- def Distance(n,matrics):
- '''这是一个计算不同弹幕距离的函数'''
- sums = 0
- mole = 0
- #随机找出矩阵中的两个向量
- for i in range(n):
- x = random.randint(0,10)
- y = random.randint(0,10)
- sums = (matrics[x][i] - matrics[y][i])**2 + sums
- mole = mole + matrics[x][i]*matrics[y][i]
- # 计算欧式距离
- distance_euc = math.sqrt(sums)
- sum1 = sum(matrics[x]);sum2 = sum(matrics[y])
- deno = math.sqrt(sum1*sum2)
- #计算余弦距离
- if deno == 0:
- distance_cos = 0
- else:
- distance_cos = mole/deno
- return distance_euc,distance_cos
- def plot_Wc(counts1):
- '''这是将词频字典生成词云的函数'''
- #主结构很像前端里面CSS的写法
- wc = wordcloud.WordCloud( #根据词频字典生成词云图
- max_words=100, # 最多显示词数
- max_font_size=300, # 字体最大值
- background_color="white", # 设置背景为白色,默认为黑色
- width = 1500, # 设置图片的宽度
- height= 960, # 设置图片的高度
- margin= 10, # 设置图片的边缘
- font_path='C:/Windows/Fonts/simsun.ttc'
- )
- wc.generate_from_frequencies(counts1) # 从字典生成词云
- plt.imshow(wc) # 显示词云
- plt.axis('off') # 关闭坐标轴
- plt.show() # 显示图像
- def TF_IDF(counts1,rows):
- '''对TF_IDF进行构建'''
- n = len(counts1)
- m = len(rows)
- counts_IF = counts1
- for i in counts1:
- #计算tf
- tf = counts1.get(i)/n
- count = 0
- for row in rows:
- words = jieba.lcut(row)
- if i in words:
- count = count + 1
- #计算idf
- idf = math.log(m/count)
- #两者求积得tf_idf
- tf_idf = tf*idf
- counts_IF[i] = tf_idf
- return counts_IF
- def main():
- '''这是主函数对之前定义的函数进行调用'''
- stopwords = Restopwords() #停用词列表
- rows = Comments_lines() #弹幕列表
- counts = Word_frequ(rows,stopwords) #词频列表
- counts1 = Screen(counts)
- #matrics,n = Matrix(counts1,rows)
- #distance_euc,distance_cos = Distance(n,matrics)
- counts_IF = TF_IDF(counts1,rows)
- print(counts_IF)
- plot_Wc(counts1)
- if __name__ == '__main__':
- main()
⼆、各功能实现
1.只导⼊⽂件前200⾏时词频的结果

 导⼊全⽂件的词频结果
导⼊全⽂件的词频结果

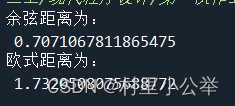
2.计算随机两个向量的距离
3.使⽤TF_IDF统计词频,并且绘制词云图

三、对于封装函数的解释
1.初始模块的导⼊

2.Restopwords(): 读⼊停⽤词,返回⼀个停⽤词列表

主要的难点在于splitlines()函数的实现
3.Comments_lines(): 将评论的数据集读⼊并返回已每条弹幕为元素
的列表
使⽤ [row[0] for row in reader] 来只获取第⼀列数据
4.Word_frequ(rows,stopwords): 统计词频函数
 注意 jieba.lcut() 函数的使⽤ 和 counts[word] = counts.get(word, 0) + 1 对于词频的统计使⽤的 if 函数对词组是否在停⽤词中进⾏了判断返回了⼀个词频字典
注意 jieba.lcut() 函数的使⽤ 和 counts[word] = counts.get(word, 0) + 1 对于词频的统计使⽤的 if 函数对词组是否在停⽤词中进⾏了判断返回了⼀个词频字典5.Screen(counts): 筛选词频函数
 使⽤了 list() 函数和 dict() 函数,来实现列表和字典之间的相互转化 邱骏坤 20377242 词频分析作业8返回了⼀个词频都⼤于 5 的词频字典
使⽤了 list() 函数和 dict() 函数,来实现列表和字典之间的相互转化 邱骏坤 20377242 词频分析作业8返回了⼀个词频都⼤于 5 的词频字典 这⾥使⽤ if len(words) <=7:pass来将过短的弹幕删除将会返回⼀个⼆维数组矩阵和向量的⻓度
这⾥使⽤ if len(words) <=7:pass来将过短的弹幕删除将会返回⼀个⼆维数组矩阵和向量的⻓度7.Distance(n,matrics): 计算随机两个弹幕之间余弦距离和欧式距离

余弦距离计算公式:
 欧式距离计算公式:
欧式距离计算公式: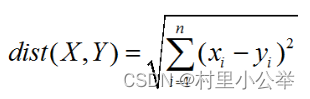
8.plot_Wc(counts1): 传⼊词频字典绘制词云图

9.TF_IDF(counts1,rows):



10.主函数

-
相关阅读:
价格监测千万别漏掉这些内容
敏捷发布列车初探2 ---- Agile Release Train
【Pytorch】数据集的加载和处理(二)
shell编程中的正则表达式和文本处理工具
【H3C设备组网配置】第二版
【SA8295P 源码分析 (一)】07 - XBL Loader 解析 sbl1_config_table 规则分析
MySQL 基础篇(第04话):mysqld 和 mysql 命令的区别
JavaEE——网络编程(TCP流编程)
数仓之全量表、增量表、快照表、切片表、拉链表
mysql基础知识(四) 聚合函数
- 原文地址:https://blog.csdn.net/m0_56134806/article/details/127231500
