-
Elasticsearch、Kibana
1.Elasticsearch
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。
而商品的数量非常多,而且分类繁杂。如何能正确的显示出用户想要的商品,并进行合理的过滤,
尽快促成交易,是搜索系统要研究的核心。
面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都会使用全文检索技术Elasticsearch。安装:
先创建一个用户
useradd wwr
passwd 123456
su wwr
然后上传压缩文件到linux

解压缩:tar -zxvf elasticsearch-6.2.4.tar.gz mv elasticsearch-6.3.0/ elasticsearch 重命名一下 cd elasticsearch/config vim jvm.options 修改成如下内容 -Xms512m -Xmx512m- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
vim elasticsearch.yml
修改如下内容path.data: /home/wwr/elasticsearch/data # 数据目录位置 path.logs: /home/wwr/elasticsearch/logs # 日志目录位置 network.host: 0.0.0.0 # 此行前面带一个空格 绑定到0.0.0.0,允许任何ip来访问- 1
- 2
- 3
进入elasticsearch目录创建
mkdir datacd /home/wwr/elasticsearch/bin/./elasticsearch直接运行的话会报权限不够的错误。

用root用户修改配置文件,
su
vim /etc/security/limits.conf添加* soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 //这里直接复制,粘贴是有*号的,别删掉- 1
- 2
- 3
- 4
- 5

vim /etc/sysctl.conf添加如下内容vm.max_map_count=655360- 1
关闭ssh
service sshd stop
查看ssh状态
service sshd status重新回到wwr用户下,
cd /home/wwr/elasticsearch/bin/
./elasticsearch启动就好了
记得关闭防火墙
在浏览器端进行测试

2.安装Kibana
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
需要先安装node.js,并配置环境变量
我的版本是16.14.2。

将Kibana解压,修改配置文件


不可以直接启动,需要先开启Elasticsearch,不然会报No Living Connections错误,启动成功后:
然后到浏览器测试:
http://localhost:5601直接回车就很好了。

3.安装ik分词器

unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer解压缩

删除压缩文件(必做)
启动Elasticsearch

测试:POST _analyze { "analyzer": "ik_max_word", "text": "张万森,下雪啦" }- 1
- 2
- 3
- 4
- 5

ElasticSearch的语法学习
创建索引
PUT wwr { "settings": { "number_of_shards": 5 , "number_of_replicas": 1 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
因为我已经创建过了wwr索引所以会报错。

查看索引
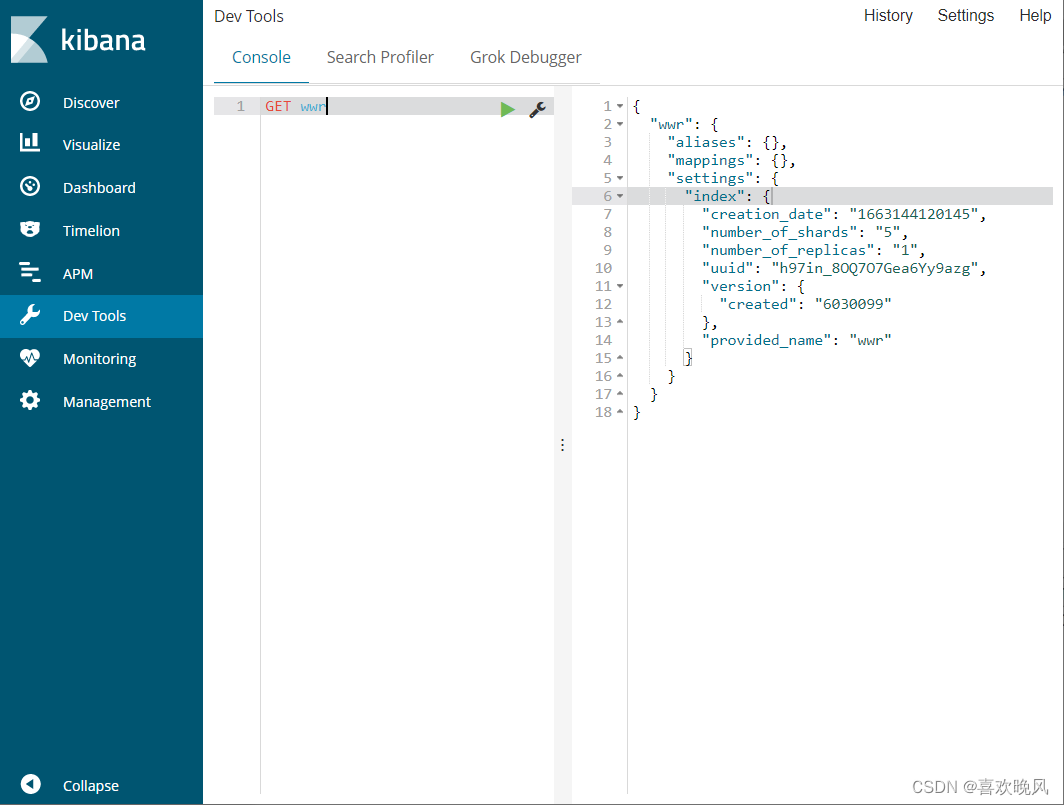
删除索引

映射配置
1.什么是映射
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
只有配置清楚,Elasticsearch才会帮我们进行索引库的创建2.映射语法格式
PUT /索引库名/_mapping/类型名称 { "properties": { "字段名": { "type": "类型", "index": true, "store": true, "analyzer": "分词器" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

查看映射关系

字段常用属性详解
1.type属性
String类型,又分两种:
text:可分词,不可参与聚合
keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存
储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省
空间。2.index
true:字段会被索引,则可以用来进行搜索。默认值就是true false:字段不会被索引,不能用来搜索
3.store
Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做 _source 的属性 中。而且我们可以通过过滤
_source 来选择哪些要显示,哪些不显示。 而如果设置store为true,就会在 _source 以外额外存储一份数据,多余,因此一般我们都会将 store设置为false,事实上,store的默认值就是false。新增数据
POST /wwr/books/ { "title":"百年孤独", "images":"http://image.lano.com/12479122.jpg", "price":30.00 }- 1
- 2
- 3
- 4
- 5
- 6
oh fuck!,明天再写
-
相关阅读:
php+mysql幼儿园早教网站
MQTT 基础--持久会话和排队消息:第 7 部分
APM32F0XX/STM32F0XX停机模式功耗测试
创建自己的cli
linux环境下查询主板、CPU、内存等硬件信息
json数组能不能放到hashmap中
前端八股文(3)53-84
Rust 力扣 - 1456. 定长子串中元音的最大数目
《C++ Primer》练习9.43-练习9.46:替换字符串简写和插入前后缀
【Oracle】分析函数partition by,解决了使用group by后select语句中只能是分组的字段或者是一个聚合函数的问题
- 原文地址:https://blog.csdn.net/wwr12138333/article/details/126847190