-
【C++】string的接口从生涩到灵活使用——这篇文章就够了
目录
1.反转字母(初级)
本篇文章其实是以笔者在LeetCode的刷题经历为基础而诞生的。string的接口有100多个,实在有些繁杂,哪些应该熟练掌握,哪些应该简单了解,自己摸索其实成本其实还是挺高的,所以我想这一篇文章能够带给你帮助。内容有些长,只要你耐心看完一定会有很大的收货。各位刚接触string的同道中人也可以先刷刷这些题试试水。


第一类题目:反转字符串类型
反转字母(初级)
正向迭代器
在此之前,我们先来介绍关于正向迭代器的两个接口:
 先来看如何使用:
先来看如何使用: - void test_string1()
- {
- string s = "abcdefg";
- /*迭代器的使用:iterator 是一种在string类域中被重新命名的类型,所以string::iterator
- 表示类型*/
- string::iterator it_begin = s.begin();
- string::iterator it_end = s.end();
- /*string迭代器行为类似于指针,begin()接口获得字符串的起始位置
- end()接口获得字符串最终的位置(也就是'\0'的位置)*/
- cout << *it_begin << ' ' << *(it_end - 1) << endl;
- //我们可以像指针一样操作string迭代器:
- while (it_begin <= it_end - 1)
- {
- (*it_begin) -= 32; //全部转成大写字母
- cout << *it_begin << ' ';
- ++it_begin;
- }
- cout << endl;
- } //运行结果如下图:

题目讲解

这道题思路很简单,使用前后指针,往中间移动的过程中,将字母交换即可,这道题就来使用一下迭代器,直接附上代码实现:
- class Solution {
- public:
- string reverseOnlyLetters(string& s) {
- //定义前后指针
- string::iterator it_begin = s.begin(), it_end = s.end() - 1;
- while(it_begin < it_end)
- {
- /*这里如果忘记怎么用isalpha函数判断是否是字母,也可以用*it_begin > 'A'
- && *it_begin < 'Z'...... 的逻辑*/
- while(it_begin < it_end && !isalpha(*it_begin))
- {
- ++it_begin;
- }
- while(it_begin < it_end && !isalpha(*it_end))
- {
- --it_end;
- }
- if(it_begin < it_end)
- {
- swap(*it_begin, *it_end);
- ++it_begin;
- --it_end;
- }
- }
- return s;
- }
- };
2.反转字母(中级)
在此之前我们来介绍两个接口:
reverse和size


先来看如何使用:
- void test_string2()
- {
- //reverse和size的使用
- string s = "hello";
- //size获得字符串的长度,且不包含'\0'
- size_t sz = s.size();
- cout << sz << endl;
- string::iterator it_begin = s.begin(), it_end = s.end();
- /*reverse在std的命名空间中,也就是说使用std命名空间后可以直接调用该接口
- 该函数的两个参数的类型必须是迭代器,且区间是左闭右开
- 该函数效果是:实现字符串的翻转,与上一题类似*/
- reverse(it_begin, it_end);
- cout << s << endl;
- }//效果如下图所示:

题目讲解

思路上也不算难,只不过比第一题多加了一些限制条件而已,我们以每2k个为一组进行遍历,将前k个进行翻转;对于最后不满2k个进行特殊判断即可,附上代码实现:
- class Solution {
- public:
- string reverseStr(string& s, int k) {
- for(size_t i = 0; i < s.size(); i += 2 * k)
- {
- //i + k <= s.size()确保迭代器不会越界
- if(i + k <= s.size())
- {
- //对前k个进行翻转
- reverse(s.begin() + i, s.begin() + i + k);
- }
- else
- {
- //剩余的不满k个全部翻转
- reverse(s.begin() + i, s.end());
- }
- }
- return s;
- }
- };
3.反转字母(高级)
在此之前我们先来介绍两个接口:
find和resize

先来看看如何使用:
- void test_string3()
- {
- //find的介绍:
- string s = "hello world hello programmer";
- //1.常见用法:直接传入你想找的某个字符,返回第一个出现该字符的下标(类型:size_t)
- //比如这里我想找第一个空格出现的位置:
- size_t pos1 = s.find(' ');
- cout << pos1 << endl;
- //2.当然如果没有找到,语法规定返回string::npos,这里来验证一下:
- //我们找一个字符'z',但是字符串中并不存在
- size_t pos2 = s.find('z');
- if (pos2 == string::npos)
- cout << "yes" << endl;
- else
- cout << "no" << endl;
- /*3.小应用:查找文件后缀名
- 现在有一个文件名为:test.cpp,我想获得后缀如何操作?*/
- string file = "test.cpp";
- size_t pos3 = file.find('.');
- //这里介绍一个接口:substr,给定范围后可以返回子子字符串
- string suffixName = file.substr(pos3, file.size()-pos3);
- cout << suffixName << endl;
- //4.另一个常见用法:查找模式串是否存在,比如:
- string haystack = "hello world hello everyone";
- string needle = "everyone";
- if (haystack.find(needle) != string::npos)
- cout << "find!" << '\n';
- else
- cout << "none!" << '\n';
- /*当然你也可以这样用:haystack.find("everyone");
- 这里的原理就是:这个传入的字符串会隐式类型转化为string类型,然后再进行查找
- 当find只传入需要查找的对象作为参数时,默认从0位置开始查找,如果想从特定某个位置
- 开始查找,需要传入具体的开始位置,例如:*/
- haystack.find(needle, 5);
- }//运行结果如下图所示:


- void test_string4()
- {
- //resize的使用:
- string s1 = " hello world ";
- //使用快慢指针法:
- size_t fast = 0, slow = 0;
- while (fast < s1.size())
- {
- if(s1[fast] != ' ')
- {
- if (slow != 0)
- {
- s1[slow] = ' ';
- ++slow;
- }
- while (fast < s1.size() && s1[fast] != ' ')
- {
- s1[slow++] = s1[fast++];
- }
- }
- ++fast;
- }
- //resize:重新改变s1的空间大小,传入的参数(类型size_t)是你想让空间最终变成你指定的大小
- s1.resize(slow);
- cout << s1 << endl;
- }//运行结果如下图所示:

题目讲解


对整个字符串进行翻转的操作不难:
- //只需使用一次reverse即可:
- string s = "the sky is blue";
- reverse(s.begin(), s.end());
接下来如何对每个单词进行翻转?
笔者一开始是想使用find来找到每个空格的位置,以此来控制每两个空格之间的单词进行翻转,这种操作有点冗杂,还需要特别处理一些头尾单词,得到如下代码:
- string reverseSeriesWords(string& s)
- {
- size_t pos = s.find(' '); //找到第一个空格位置
- size_t index = 0;
- reverse(s.begin() + index, s.begin() + pos); //单独控制第一个单词
- while (s.find(' ', pos + 1) != string::npos)//进入循环进行遍历,每两个空格使用一次 reverse
- {
- index = pos;
- pos = s.find(' ', index + 1);
- reverse(s.begin() + index + 1, s.begin() + pos);
- }
- reverse(s.begin() + pos + 1, s.end()); //最后单独控制最后一个单词
- return s;
- }
后来,经过反思与借鉴得到更好的代码如下:
- void reverse(string& s, int start, int end)
- { //翻转,区间写法:左闭又闭 []
- for (int i = start, j = end; i < j; i++, j--)
- {
- swap(s[i], s[j]); //调用库函数swap
- }
- }
- void reverseSeriesWords(string& s)
- {
- int start = 0;
- for (int i = 0; i <= s.size(); ++i)
- {
- if (i == s.size() || s[i] == ' ')
- { //到达空格或者串尾,说明一个单词结束,进行翻转。
- reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
- start = i + 1; //更新下一个单词的开始下标start
- }
- }
- }
最终得到完整的代码如下:
- class Solution {
- public:
- void reverse(string& s, int start, int end)
- { //翻转,区间写法:左闭又闭 []
- for (int i = start, j = end; i < j; i++, j--)
- {
- swap(s[i], s[j]);
- }
- }
- void removeSpaces(string& s) //移除空格我们在将rsize接口的时候已经实现过了
- {
- size_t fast = 0, slow = 0;
- while (fast < s1.size())
- {
- if(s1[fast] != ' ')
- {
- if (slow != 0)
- {
- s1[slow] = ' ';
- ++slow;
- }
- while (fast < s1.size() && s1[fast] != ' ')
- {
- s1[slow++] = s1[fast++];
- }
- }
- ++fast;
- }
- //resize:根据你的指定,重新改变s1的空间大小
- s1.resize(slow);
- }
- string reverseSeriesWords(string& s)
- {
- removeSpaces(s); //去除多余空格
- reverse(s, 0, s.size() - 1);
- int start = 0;
- for (int i = 0; i <= s.size(); ++i)
- {
- if (i == s.size() || s[i] == ' ')
- { //到达空格或者串尾,说明一个单词结束,进行翻转。
- reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
- start = i + 1; //更新下一个单词的开始下标start
- }
- }
- return s;
- }
- };
第二类题目:一个字符串的子字符串
1.模拟实现strStr()

做这道题之前,先想一个问题:
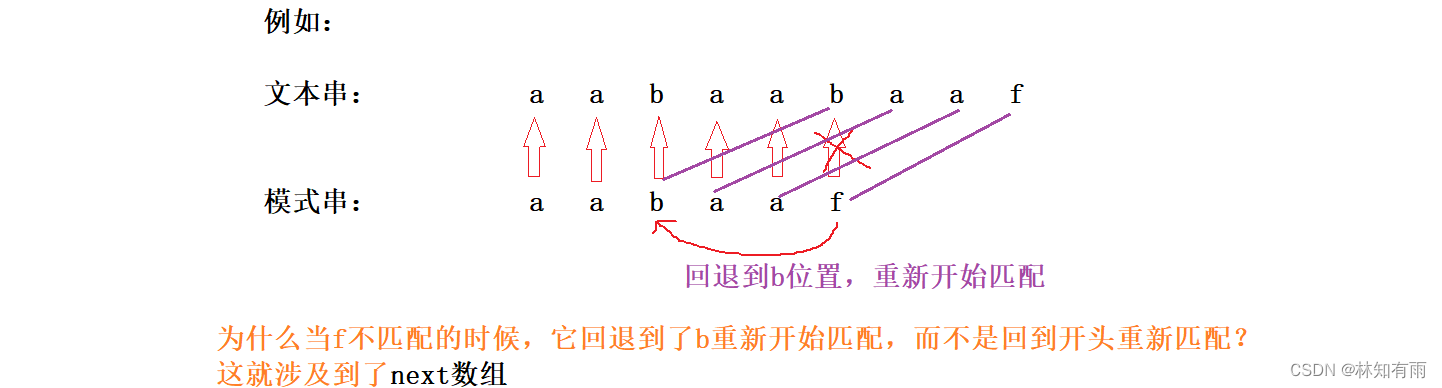
给定文本串:a a b a a b a a f (长度假设为N)
给定模式串:a a b a a f (长度假设为M)
如何在前文本符串中查找模式串是否存在?
我第一个想到的是暴力求解,直接走两层循环来匹配,但是时间复杂度很高:O(M * N),那么有没有更优化得分方法?这里介绍KMP算法
KMP算法
理论讲解
KMP主要应用在字符串匹配上,KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。

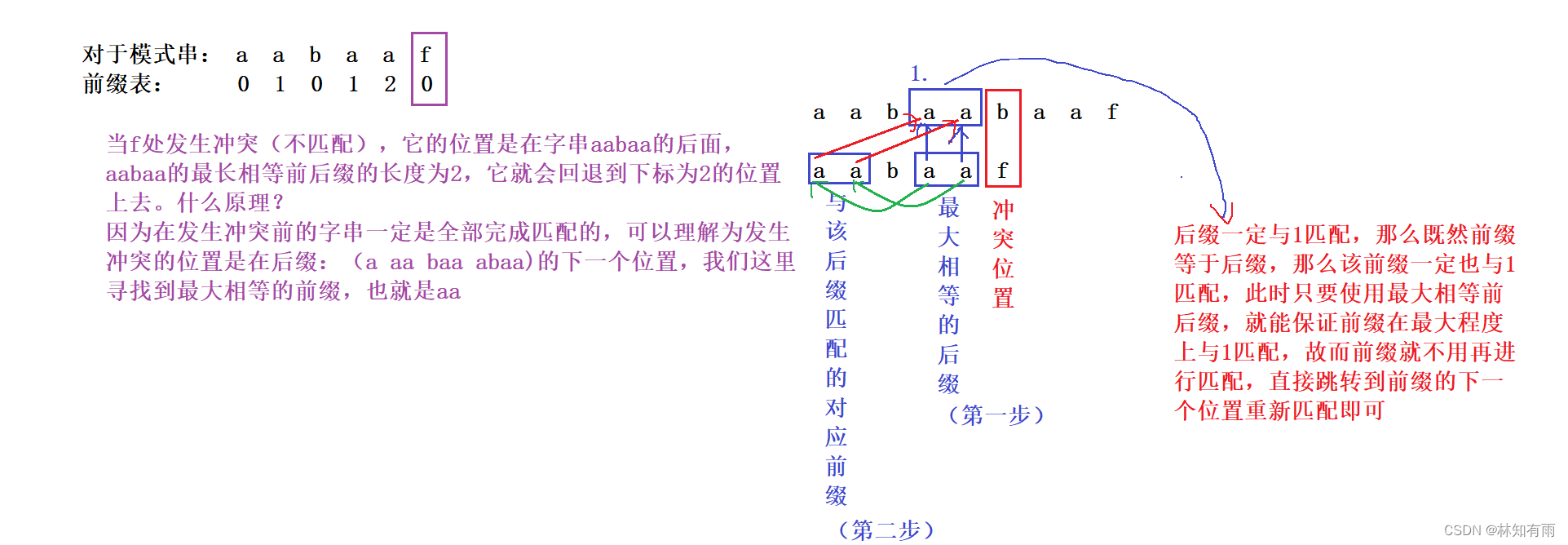
代码实现
而前缀表就是存放在next数组里面,下面我们介绍如何通过代码实现——传入一个模式串能够得到其next数组的函数
1.首先我们对next数组进行初始化
- size_t i, j = 0; //定义两个指针,之后用来遍历
- next[0] = j //将next数组第一个位置初始化为0
2.处理前后缀相同和不同的情况
首先得知道一个点:


- //给出代码:
- void getNext(int* next, const string& s) {
- int j = -1;
- next[0] = j;
- for(int i = 1; i < s.size(); i++) //注意i从1开始
- {
- //当前后缀不同:
- while (j >= 0 && s[i] != s[j + 1])
- {
- j = next[j]; // 向前回退
- }
- //当前后缀相同:
- if (s[i] == s[j + 1])
- {
- j++;
- }
- next[i] = j; // 将j(前缀的长度)赋给next[i]
- }
- }//运行结果如下:

至此我们next数组构建的函数已经完成
使用next数组模拟实现strStr()

思路讲解:首先我们先得到needle的next数组
- int next[needle.size()];
- getNext(next, needle);
接着我们开始遍历haystack与needle
- size_t j = 0;
- for(size_t i = 0; i < haystack.size(); ++i)
- {
- //出现冲突时回到next数组对应下标处
- while(j > 0 && haystack[i] != needle[j])
- {
- j = next[j - 1];
- }
- //没出现冲突时一直往后匹配即可
- if(haystack[i] == needle[j])
- {
- ++j;
- }
- //当j遍历到最后等于模式串的长度时仍没有出现冲突即证明存在子串
- //这时我们返回下标即可
- if(j == needle.size())
- {
- return (i - needle.size() + 1);
- }
- }
如下附上完整代码:
- class Solution {
- public:
- void getNext(int* next, string& s)
- {
- //初始化
- size_t j = 0;
- next[0] = j;
- //得到next数组
- for(size_t i = 1; i < s.size(); ++i)
- {
- while(j > 0)
- {
- if(s[i] != s[j])
- {
- j = next[j - 1];
- }
- else
- break;
- }
- if(s[i] == s[j])
- ++j;
- next[i] = j;
- }
- }
- int strStr(string haystack, string needle) {
- if(needle.size() == 0)
- {
- return 0;
- }
- int next[needle.size()];
- getNext(next, needle);
- size_t j = 0;
- for(size_t i = 0; i < haystack.size(); ++i)
- {
- while(j > 0 && haystack[i] != needle[j])
- {
- j = next[j - 1];
- }
- if(haystack[i] == needle[j])
- {
- ++j;
- }
- if(j == needle.size())
- {
- return (i - needle.size() + 1);
- }
- }
- return -1;
- }
- };
2.重复的子字符串

再次之间我们先来介绍两个接口:
erase 和 operator+

- void test_string7()
- {
- //operator+ 用法:
- string s = "hello ";
- string tmp = "world";
- //创建一个新变量来接收
- //可以+ 一个string对象:
- string newstr = s + tmp;
- cout << newstr << endl;
- //也可以单独加一个字符:
- string newstr2 = newstr + '!';
- cout << newstr2 << '\n';
- //operator+= 用法:
- s += tmp;
- s += '!';
- cout << s << endl;
- //不过不建议多用erase接口,尾部删除还好,如果中间删除还要挪动数组,时间复杂度就为O(N)了
- }//运行结果如下图:

- void test_string8()
- {
- //erase的用法:
- string s = "hello world";
- //1.删除指定位置字符,参数为迭代器:
- s.erase(s.begin());
- cout << s << endl;
- //2.删除指定范围字符串,参数为迭代器,区间为左闭右开:
- string s2 = "hello world";
- s2.erase(s2.begin(), s2.begin() + 5);
- cout << s2 << endl;
- //3.删除指定范围字符,参数为size_t,区间为左闭右开:
- string s3 = "hello world";
- s3.erase(0, 6);
- cout << s3 << endl;
- }//代码演示如下图:

题目讲解
这里介绍两种解题方法:
1.移动匹配:
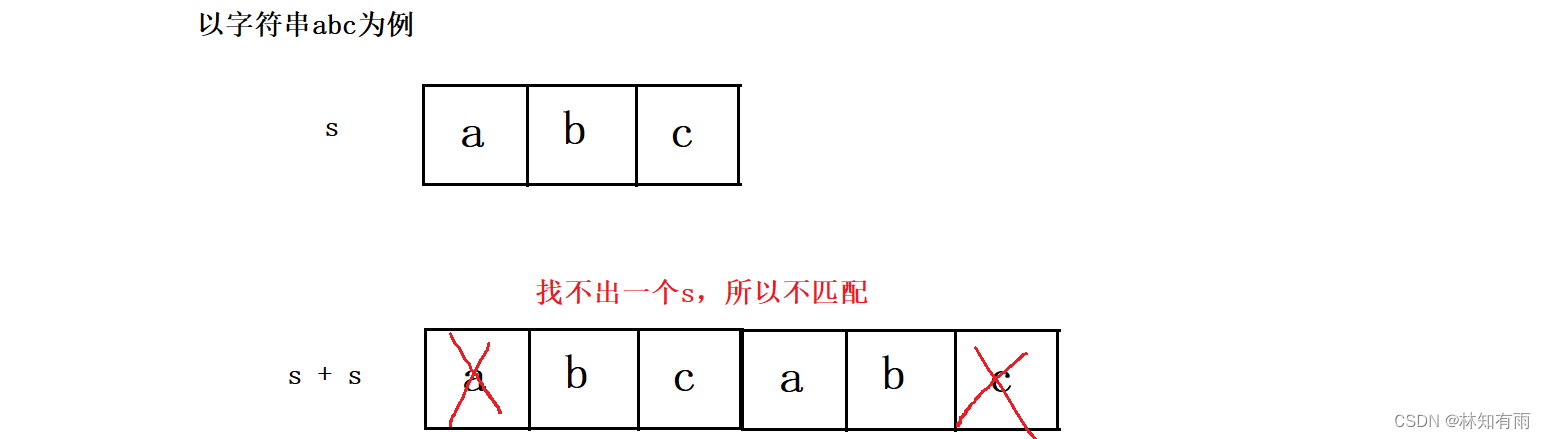
接下来附上代码:
- class Solution {
- public:
- bool repeatedSubstringPattern(string s) {
- string newstr = s + s;
- string::iterator it_begin = newstr.begin(), it_end = newstr.end();
- newstr.erase(it_end - 1); //删除尾
- newstr.erase(it_begin); //删除头
- if(newstr.find(s) != string::npos)
- {
- return true;
- }
- else
- return false;
- }
- };
2.KMP算法逻辑解决



接下来我们以字符串"abababab"为例,得到next数组

接下来附上代码实现:
- class Solution {
- public:
- void getNext(int* next, string& s)
- {
- size_t j = 0;
- next[0] = j;
- for(size_t i = 1; i < s.size(); ++i)
- {
- while(j > 0 && s[i] != s[j])
- {
- j = next[j - 1];
- }
- if(s[i] == s[j])
- ++j;
- next[i] = j;
- }
- }
- bool repeatedSubstringPattern (string& s) {
- if (s.size() == 0) {
- return false;
- }
- int next[s.size()];
- getNext(next, s);
- int len = s.size();
- if (next[len - 1] != 0 && len % (len - (next[len - 1] )) == 0) {
- return true;
- }
- return false;
- }
- };
第三类题目:一些值得注意的细节
字符串最后一个单词的长度

在这之前先来介绍两个接口:
getline 和 cin
- void test_string9()
- {
- string s1, s2;
- //现在想对s1输入"hello"
- cin >> s1;
- cout << s1 << endl;
- //如果现在想对s2输入"hello world"呢?
- cin >> s2;
- cout << s2 << endl;
- } //代码运行结果如下图所示:

为什么输入了“hello world”最后打印却只有“hello”?
因为对于cin来说,空格就表示对当前对象输入完成了,而在空格后面继续输入,数据保存在缓存中,但是没有另外的对象接收,在程序运行完就自动丢弃了。所以cin无法对一个对象输入带着空格的英文词组,或者句子。
这个时候只能用getline了:

题目讲解
这题本身没有什么难度,只是想区别一些getline和cin的用法,避免混淆,这里直接附上代码:
- #include
- #include
- using namespace std;
- int main()
- {
- string line;
- while(getline(cin, line))
- {
- size_t pos = line.rfind(' '); //rfind和find使用方式一样,只不过是find是从前往后找, refind是从后往前找
- cout<}return 0;}
好了,文章到这里结束了,本篇文章介绍了常见的string接口的使用,但是并不完全,实际上还需要读者在平时的时候查查文档,加深印象。
最后附上一个大佬对于string类的认识:
STL_string类到底怎么啦?

- 相关阅读:
【滤波跟踪】基于不变扩展卡尔曼滤波器对装有惯性导航系统和全球定位系统IMU+GPS进行滤波跟踪附matlab代码
Unity接入北斗探针SDK(基于AndroidJavaProxy)丨安卓交互的最佳方式
SAP KO22内部订单预算BAPI与BDC
家庭网络中的组网方式
通过WSL2 Ubuntu18.04搭建CANN算子开发环境
Databend 开源周报第 111 期
Day08_DM层建设实战,本地视频+md,review第1遍,220625,
【个人总结】动态路由实现方案
Spring原理学习(六)Scope
向NXP官网Linux内核添加ALPHA开发板
- 原文地址:https://blog.csdn.net/Lin_zhiyouyu/article/details/127694744