-
2021 神经网络压缩 (李宏毅
首先,为什么需要对神经网络模型进行压缩呢?我们在之前的课程中介绍过很多大型的深度学习模型,但当我们想要将这些大模型放在算力比较小的边缘设备或者其他IoT设备里面,就需要对大模型进行压缩。

Lower latency:低时延 Privacy:私密性
介绍5个网络压缩的方法,我们只考虑算法(软件)层面,不考虑硬件层面的解决方法。

1. Network Pruning(网络剪枝)
对于一个大的网络来说,我们能想到的是,众多网络参数中一定会有不重要/冗余的一些参数,因此我们将这些参数减掉达到网络压缩的目的。

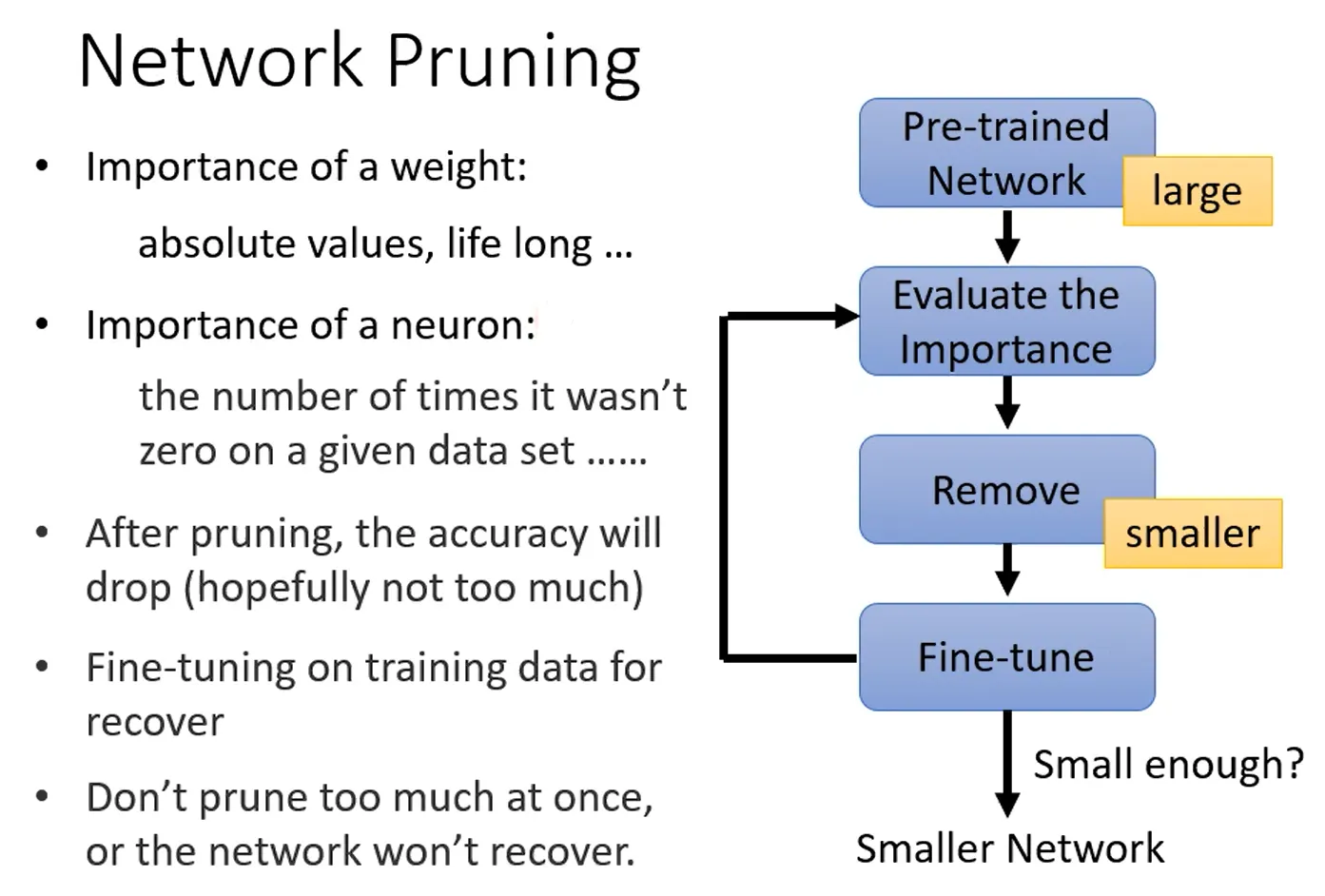
网络剪枝的步骤如下:首先,我们预训练一个大规模的网络,然后评估里面参数的重要性,包括权重(weight)的重要性和神经元(neuron)的重要性。
- 评价weight重要性,我们可以用绝对值衡量,即绝对值越大,weight越重要,或者采用之前介绍的life long learning的想法(也許我們也可以就把每個參數的 bi 算出來、就可以知道那個參數重不重要)。
- 评价neuron重要性,我们可以用其输出的结果为0的次数衡量,即输出0越多越不重要。
接着我们对多余的参数的重要性评估并修剪,得到一个小的网络,再对里面的参数微调,再评估、修剪。。。重复上述过程,直到满足要求,完成Network pruning过程。(一次剪掉大量参数可能对network伤害太大,所以一次只剪掉一点参数比如10%)
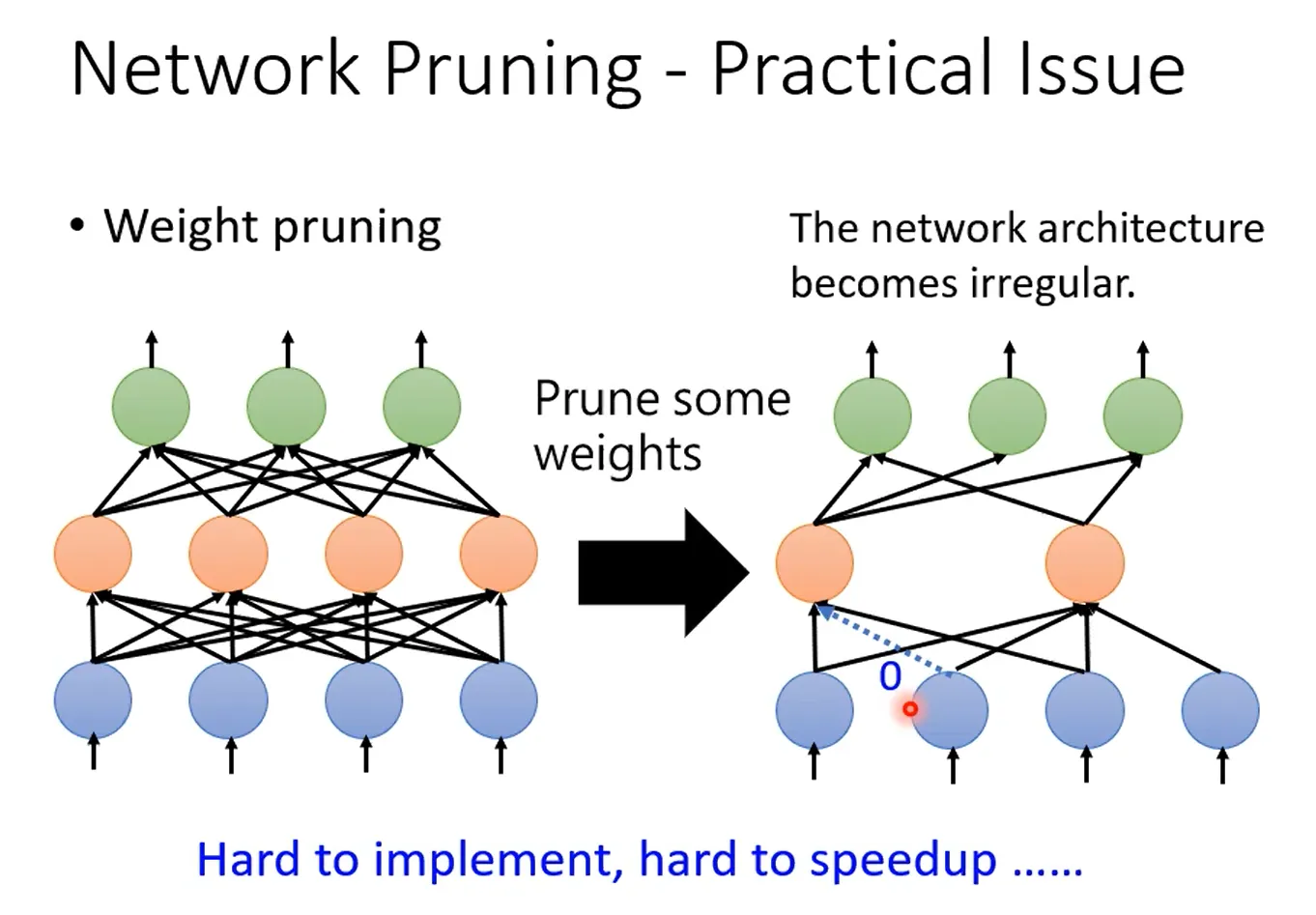
刚才提到,修剪的单位有两种,一种是以权重(weight)为单位,一种是以神经元(neuron)为单位,这两者有什么不同呢?实作上差别较大
首先Weight pruning,但这样就造成network 形状不规则(irregular),难以编程实现(pytorch定义network每一層有幾個 Neuron/ vector),同时难以用GPU加速(矩阵乘法)。通常的做法是将冗余的weight置为0,但这样做还是保留了参数(等于0),不是真正去除掉。
在这篇论文中有个关于参数pruning多少与训练速度提升关系的实验验证,其中紫色线sparsity表示参数去掉的量。可以发现,虽然参数去掉了将近95%,但是速度依然没有提升。
(這個 Network Pruning 的方法、其實是一個非常有效率的方法、往往你可以 Prune 到 95% 以上的參數、那但是你的 Accuracy 只掉 1~2% 而已)

接着Neuron pruning,通过去除冗余的神经元,简化网络结构。这样得到的网络结构是
-
相关阅读:
[glacierctf 2022] 只会3个
Unity实现设计模式——责任链模式
[附源码]计算机毕业设计在线票务系统Springboot程序
《未来简史》读书笔记
方阵行列式与转置矩阵
指针的用法
php实验室安全系统的设计与实现毕业设计-附源码191610
使用VSCode插件开发Hyperledger Fabric智能合约(链码)
使用Jenkins自动给多个仓库创建分支
调试接口小技巧-通过接口调试工具去下载上传文件
- 原文地址:https://blog.csdn.net/linyuxi_loretta/article/details/127693695