-
mysql源码分析——InnoDB的磁盘结构之日志文件格式分析
一、日志种类
在前面分析过了MySql数据库的日志,主要是两大类,即MySql的日志和数据库引擎的日志。在前面分析过的TC_LOG就是MySql中的2PC日志,同时Binlog也继承了此日志。在InnoDB引擎中,有Redo Log和Undo Log,在前面分析上层
控制的基础上,本次重点分析redo log日志的文件结构和相关控制流程。二、文件格式类型
在Redo Log日志中,它是记载的逻辑意义的物理日志,其日志格式跟应用逻辑有着相当强的关系。它的基本格式主要包括:
1、type
日志类型,主要有mlog_1byte、mlog_2bytes、mlog_4bytes、mlog_8bytes、mlog_write_string、mlog_undo_insert、mlog_init_file_page等64种类型。
2、sapce ID
表空间ID,这个不做多说明 。
3、page_no
所在表空间的ID
4、offset
数据相对于页的偏移量。
5、data
具体要修改的数据。
根据不同的日志,可能一些细节的字段有些不同,但是上面这几条,基本都包括。从整体上来看,Redo日志主要分为三种,即作用于页的;作用于Sapce的和涉及额外信息的Logic的。
三、redo log文件格式
日志落盘后,文件的组成有两个文件即ib_logfile0和ib_logfile1,其组成结构相同。主要有以下几个部分:
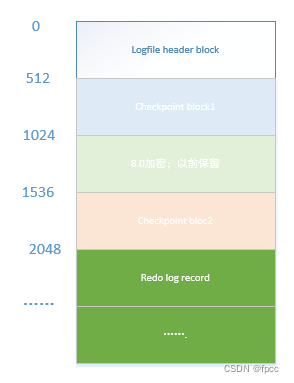
日志的最小单位是块,大小为512字节。块的后四个字节是checksum校验值。日志文件的前四个块为文件头,它存储着日志文件的元数据信息和checkpoint信息。
logfile header block的文件组成如下:

log_head_format:版本号,占用四个字节,最新版本号为4:
LOG_HEADER_FORMAT_5_7_9 = 1,
LOG_HEADER_FORMAT_8_0_1 = 2,
LOG_HEADER_FORMAT_8_0_3 = 3,
LOG_HEADER_FORMAT_8_0_19 = 4,
LOG_HEADER_FORMAT_CURRENT = LOG_HEADER_FORMAT_8_0_19start_lsn:默认16*512,此值在初始化和切换类型时写入
log_head_creator:32个字节,默认值为MySQL 8.0.20
checksum:本块的加和校验值checksum block的组成如下:
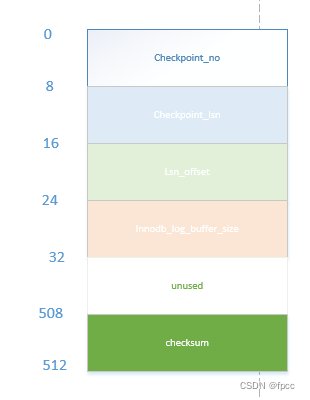
checkpoint_no :checkpoint完成后加1
checkpoint_lsn:崩溃恢复的lsn值
lsn_offset:lsn的偏移值
innodb_log_buffer_size:参数innodb_log_buffer_size的大小
checksum值:本块的checksum值log data block的组成如下:
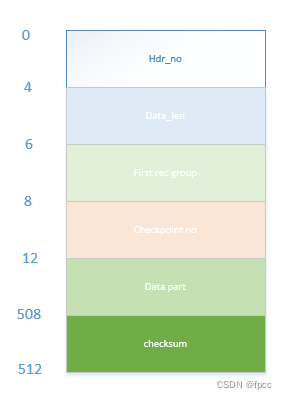
hdr_no:4字节块号,值必须大于0,最高位即flush标志位,为1,表示这个块已经刷到磁盘。最大允许的块号为:LOG_BLOCK_MAX_NO = 0x3FFFFFFFUL + 1
data_len:2字节,当前块写入的字节数,含块头的12个字节。其最高两位用来表示当前块是否加密
first_rec_group:2字节,用来存储mtr log 第一个记录开始的偏移值。如此值不为0,recover即从此偏移点开始解析日志
checkpoint_no:4字节,刷入的最新log block被写入时的log_sys->next_checkpoint_no的低4字节其实这些东西没啥太多技术含量,更多的是一些细节的说明。
四、相关代码
在MySql中,只要明白了相关的流程和设计,代码就好分析了。针对Redo Log的情况,下面分析一下相关的代码:
文件头预定义数据:
os0file.h #define OS_FILE_LOG_BLOCK_SIZE 512 // log0log.h /** First checkpoint field in the log header. We write alternately to the checkpoint fields when we make new checkpoints. This field is only defined in the first log file. */ constexpr uint32_t LOG_CHECKPOINT_1 = OS_FILE_LOG_BLOCK_SIZE; /** Log Encryption information in redo log header. */ constexpr uint32_t LOG_ENCRYPTION = 2 * OS_FILE_LOG_BLOCK_SIZE; /** Second checkpoint field in the header of the first log file. */ constexpr uint32_t LOG_CHECKPOINT_2 = 3 * OS_FILE_LOG_BLOCK_SIZE; /** Size of log file's header. */ constexpr uint32_t LOG_FILE_HDR_SIZE = 4 * OS_FILE_LOG_BLOCK_SIZE;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
文件头的格式代码:
enum log_header_format_t { /** The MySQL 5.7.9 redo log format identifier. We can support recovery from this format if the redo log is clean (logically empty). */ LOG_HEADER_FORMAT_5_7_9 = 1, /** Remove MLOG_FILE_NAME and MLOG_CHECKPOINT, introduce MLOG_FILE_OPEN redo log record. */ LOG_HEADER_FORMAT_8_0_1 = 2, /** Allow checkpoint_lsn to point any data byte within redo log (before it had to point the beginning of a group of log records). */ LOG_HEADER_FORMAT_8_0_3 = 3, /** Expand ulint compressed form. */ LOG_HEADER_FORMAT_8_0_19 = 4, /** The redo log format identifier corresponding to the current format version. * / LOG_HEADER_FORMAT_CURRENT = LOG_HEADER_FORMAT_8_0_19 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在前面内存处理中,已经把log_t(struct alignas(ut::INNODB_CACHE_LINE_SIZE) log_t log0types.h)的源码简单分析过了,这里不再拷贝代码。上面的注释很清楚,就是有点麻烦,得认真看看。看一下日志文件头的处理函数(innobase/log/log0chkp.cc):
void log_files_header_fill(byte *buf, lsn_t start_lsn, const char *creator, bool no_logging, bool crash_unsafe) { memset(buf, 0, OS_FILE_LOG_BLOCK_SIZE); mach_write_to_4(buf + LOG_HEADER_FORMAT, LOG_HEADER_FORMAT_CURRENT); mach_write_to_8(buf + LOG_HEADER_START_LSN, start_lsn); strncpy(reinterpret_cast(buf) + LOG_HEADER_CREATOR, creator, LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR); ut_ad(LOG_HEADER_CREATOR_END - LOG_HEADER_CREATOR >= strlen(creator)); uint32_t header_flags = 0; if (no_logging) { LOG_HEADER_SET_FLAG(header_flags, LOG_HEADER_FLAG_NO_LOGGING); } if (crash_unsafe) { LOG_HEADER_SET_FLAG(header_flags, LOG_HEADER_FLAG_CRASH_UNSAFE); } mach_write_to_4(buf + LOG_HEADER_FLAGS, header_flags); log_block_set_checksum(buf, log_block_calc_checksum_crc32(buf)); } void log_files_header_flush(log_t &log, uint32_t nth_file, lsn_t start_lsn) { ut_ad(log_writer_mutex_own(log)); MONITOR_INC(MONITOR_LOG_NEXT_FILE); ut_a(nth_file < log.n_files); byte * buf = log.file_header_bufs[nth_file]; log_files_header_fill(buf, start_lsn, LOG_HEADER_CREATOR_CURRENT, log.m_disable, log.m_crash_unsafe); /* Save start LSN for first file. * / if (nth_file == 0) { log.m_first_file_lsn = start_lsn; } DBUG_PRINT("ib_log", ("write " LSN_PF " file " ULINTPF " header", start_lsn, ulint(nth_file))); const auto dest_offset = nth_file * uint64_t{log.file_size}; const auto page_no = static_cast (dest_offset / univ_page_size.physical()); auto err = fil_redo_io( IORequestLogWrite, page_id_t{log.files_space_id, page_no}, univ_page_size, static_cast (dest_offset % univ_page_size.physical()), OS_FILE_LOG_BLOCK_SIZE, buf); ut_a(err == DB_SUCCESS); } void log_files_header_read(log_t &log, uint32_t header) { ut_a(srv_is_being_started); ut_a(!log_checkpointer_is_active()); const auto page_no = static_cast (header / univ_page_size.physical()); auto err = fil_redo_io(IORequestLogRead, page_id_t{log.files_space_id, page_no}, univ_page_size, static_cast (header % univ_page_size.physical()), OS_FILE_LOG_BLOCK_SIZE, log.checkpoint_buf); ut_a(err == DB_SUCCESS); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
再看检查点:
void log_create_first_checkpoint(log_t &log, lsn_t lsn) { byte block[OS_FILE_LOG_BLOCK_SIZE]; lsn_t block_lsn; page_no_t block_page_no; uint64_t block_offset; ut_a(srv_is_being_started); ut_a(!srv_read_only_mode); ut_a(!recv_recovery_is_on()); ut_a(buf_are_flush_lists_empty_validate()); log_background_threads_inactive_validate(log); /* Write header of first file. * / log_files_header_flush(*log_sys, 0, LOG_START_LSN); /* Write header in log file which is responsible for provided lsn. * / block_lsn = ut_uint64_align_down(lsn, OS_FILE_LOG_BLOCK_SIZE); block_offset = log_files_real_offset_for_lsn(log, block_lsn); uint32_t nth_file = static_cast(block_offset / log.file_size); log_files_header_flush(log, nth_file, block_lsn); /* Write the first, empty log block. * / std::memset(block, 0x00, OS_FILE_LOG_BLOCK_SIZE); log_block_set_hdr_no(block, log_block_convert_lsn_to_no(block_lsn)); log_block_set_flush_bit(block, true); log_block_set_data_len(block, LOG_BLOCK_HDR_SIZE); log_block_set_checkpoint_no(block, 0); log_block_set_first_rec_group(block, lsn % OS_FILE_LOG_BLOCK_SIZE); log_block_store_checksum(block); std::memcpy(log.buf + block_lsn % log.buf_size, block, OS_FILE_LOG_BLOCK_SIZE); ut_d(log.first_block_is_correct_for_lsn = lsn); block_page_no = static_cast (block_offset / univ_page_size.physical()); auto err = fil_redo_io( IORequestLogWrite, page_id_t{log.files_space_id, block_page_no}, univ_page_size, static_cast (block_offset % UNIV_PAGE_SIZE), OS_FILE_LOG_BLOCK_SIZE, block); ut_a(err == DB_SUCCESS); /* Start writing the checkpoint. * / log.last_checkpoint_lsn.store(0); log.next_checkpoint_no.store(0); log_files_write_checkpoint(log, lsn); /* Note, that checkpoint was responsible for fsync of all log files. * / } void log_files_write_checkpoint(log_t &log, lsn_t next_checkpoint_lsn) { ut_ad(log_checkpointer_mutex_own(log)); ut_a(!srv_read_only_mode); log_writer_mutex_enter(log); const checkpoint_no_t checkpoint_no = log.next_checkpoint_no.load(); DBUG_PRINT("ib_log", ("checkpoint " UINT64PF " at " LSN_PF " written", checkpoint_no, next_checkpoint_lsn)); byte *buf = log.checkpoint_buf; memset(buf, 0x00, OS_FILE_LOG_BLOCK_SIZE); mach_write_to_8(buf + LOG_CHECKPOINT_NO, checkpoint_no); mach_write_to_8(buf + LOG_CHECKPOINT_LSN, next_checkpoint_lsn); const uint64_t lsn_offset = log_files_real_offset_for_lsn(log, next_checkpoint_lsn); mach_write_to_8(buf + LOG_CHECKPOINT_OFFSET, lsn_offset); mach_write_to_8(buf + LOG_CHECKPOINT_LOG_BUF_SIZE, log.buf_size); log_block_set_checksum(buf, log_block_calc_checksum_crc32(buf)); ut_a(LOG_CHECKPOINT_1 < univ_page_size.physical()); ut_a(LOG_CHECKPOINT_2 < univ_page_size.physical()); /* Note: We alternate the physical place of the checkpoint info. See the (next_checkpoint_no & 1) below. * / LOG_SYNC_POINT("log_before_checkpoint_write"); auto err = fil_redo_io( IORequestLogWrite, page_id_t{log.files_space_id, 0}, univ_page_size, (checkpoint_no & 1) ? LOG_CHECKPOINT_2 : LOG_CHECKPOINT_1, OS_FILE_LOG_BLOCK_SIZE, buf); ut_a(err == DB_SUCCESS); LOG_SYNC_POINT("log_before_checkpoint_flush"); log_fsync(); DBUG_PRINT("ib_log", ("checkpoint info written")); log.next_checkpoint_no.fetch_add(1); LOG_SYNC_POINT("log_before_checkpoint_lsn_update"); log.last_checkpoint_lsn.store(next_checkpoint_lsn); LOG_SYNC_POINT("log_before_checkpoint_limits_update"); log_limits_mutex_enter(log); log_update_limits_low(log); log.dict_max_allowed_checkpoint_lsn = 0; log_limits_mutex_exit(log); log_writer_mutex_exit(log); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
看一下块的定义:
#endif /* UNIV_PFS_IO */ /** Encapsulates a log block of size QUEUE_BLOCK_SIZE, enqueued by the producer, dequeued by the consumer and written into the redo log archive file. */ class Block { public: /** Constructor initializes the byte array to all 0's and sets that the log block is not the last log block enqueued (is_final_block = false). */ Block() { reset(); } /** Destructor initializes the byte array to all 0's and sets that the log block is not the last log block enqueued (is_final_block = false). */ ~Block() { reset(); } Block &operator=(const Block &) = default; /** Resets the data in the log block, initializing the byte array to all 0's and sets that the block is not the last log block enqueued (is_final_block = false) */ void reset() { memset(m_block, 0, QUEUE_BLOCK_SIZE); m_is_final_block = false; m_is_flush_block = false; m_offset = 0; } /** Get the byte array of size QUEUE_BLOCK_SIZE associated with this object. @retval byte[] The byte array of size QUEUE_BLOCK_SIZE in this object. */ const byte *get_queue_block() const MY_ATTRIBUTE((warn_unused_result)) { return m_block; } /** Copy a log block from the given position inside the input byte array. Note that a complete log block is of size OS_FILE_LOG_BLOCK_SIZE. A log block could also be of size less than OS_FILE_LOG_BLOCK_SIZE, in which case it is overwritten in the next iteration of log writing by InnoDB. @param[in] block The byte array containing the log block to be stored in this log block object. @param[in] pos The position inside the byte array from which a log block should be copied. @retval true if a complete redo log block (multiple of OS_FILE_LOG_BLOCK_SIZE) was copied. @retval false otherwise. */ bool put_log_block(const byte block[], const size_t pos) MY_ATTRIBUTE((warn_unused_result)) { ut_ad(!full()); size_t size = log_block_get_data_len(block + pos); /* if the incoming log block is empty */ if (size == 0) { return false; /* purecov: inspected */ } memcpy(m_block + m_offset, block + pos, OS_FILE_LOG_BLOCK_SIZE); /* If the incoming log block is complete. */ if (size == OS_FILE_LOG_BLOCK_SIZE) { m_offset += size; return true; } return false; } /** Return the is_final_block flag. @retval true if the is_final_block flag is true. false if the is_final_block flag is false. */ bool get_is_final_block() const MY_ATTRIBUTE((warn_unused_result)) { return m_is_final_block; } /** Set the is_final_block flag. @param[in] is_final_block the state of the is_final_block flag. */ void set_is_final_block(const bool is_final_block) { m_is_final_block = is_final_block; } /** Return if the log block is full. Condition is (m_offset == QUEUE_BLOCK_SIZE). Since we increment m_offset by OS_FILE_LOG_BLOCK_SIZE only, the equivalent condition is (m_offset > QUEUE_BLOCK_SIZE - OS_FILE_LOG_BLOCK_SIZE). The latter one convinces the fortify tool, that we will never overrun the buffer, while the first one is insufficient for the tool. @retval true if the log block has QUEUE_BLOCK_SIZE bytes. @retval false otherwise. */ bool full() const MY_ATTRIBUTE((warn_unused_result)) { return (m_offset > QUEUE_BLOCK_SIZE - OS_FILE_LOG_BLOCK_SIZE); } /// Whether this block is a flush block. A flush block is made from /// the current temporary block redo_log_archive_tmp_block on a flush /// request. A flush block may be full or not, depending on the /// current work of the "producer". To avoid races set this variable /// only under the log writer mutex. The "consumer" shall not update /// its file write offset when it writes a flush block. The next /// regular block shall overwrite it. bool m_is_flush_block{false}; private: /** The bytes in the log block object. */ byte m_block[QUEUE_BLOCK_SIZE]; /** Offset inside the byte array of the log block object at which the next redo log block should be written. */ size_t m_offset{0}; /** Flag indicating if this is the last block enqueued by the producer. * / bool m_is_final_block{false}; }; /** This template class implements a queue that, 1. Implements a Ring Buffer. 1.1 The ring buffer can store QUEUE_SIZE_MAX elements. 1.2 Each element of the ring buffer stores log blocks of size QUEUE_BLOCK_SIZE. 2. Blocks for more data to be enqueued if the queue is empty. 3. Blocks for data to be dequeued if the queue is full. 4. Is thread safe. */ templateclass Queue { public: /** Create the queue with essential objects. */ void create() { ut_ad(m_enqueue_event == nullptr); ut_ad(m_dequeue_event == nullptr); ut_ad(m_ring_buffer == nullptr); m_front = -1; m_rear = -1; m_size = 0; m_enqueue_event = os_event_create(); m_dequeue_event = os_event_create(); mutex_create(LATCH_ID_REDO_LOG_ARCHIVE_QUEUE_MUTEX, &m_mutex); } /** Initialize the ring buffer by allocating memory and initialize the indexes of the queue. The initialization is done in a separate method so that the ring buffer is allocated memory only when redo log archiving is started. @param[in] size The size of the ring buffer. */ void init(const int size) { mutex_enter(&m_mutex); ut_ad(m_enqueue_event != nullptr); ut_ad(m_dequeue_event != nullptr); ut_ad(m_ring_buffer == nullptr); m_front = -1; m_rear = -1; m_size = size; m_ring_buffer.reset(new T[m_size]); mutex_exit(&m_mutex); } /** Deinitialize the ring buffer by deallocating memory and reset the indexes of the queue. */ void deinit() { mutex_enter(&m_mutex); m_ring_buffer.reset(); m_front = -1; m_rear = -1; m_size = 0; while (m_waiting_for_dequeue || m_waiting_for_enqueue) { /* purecov: begin inspected */ if (m_waiting_for_dequeue) os_event_set(m_dequeue_event); if (m_waiting_for_enqueue) os_event_set(m_enqueue_event); mutex_exit(&m_mutex); std::this_thread::yield(); mutex_enter(&m_mutex); /* purecov: end */ } mutex_exit(&m_mutex); } /** Delete the queue and its essential objects. */ void drop() { deinit(); mutex_enter(&m_mutex); os_event_destroy(m_enqueue_event); os_event_destroy(m_dequeue_event); m_enqueue_event = nullptr; m_dequeue_event = nullptr; mutex_exit(&m_mutex); mutex_free(&m_mutex); } /* Enqueue the log block into the queue and update the indexes in the ring buffer. @param[in] lb The log block that needs to be enqueued. */ void enqueue(const T &lb) { /* Enter the critical section before enqueuing log blocks to ensure thread safe writes. */ mutex_enter(&m_mutex); /* If the queue is full, wait for a dequeue. */ while ((m_ring_buffer != nullptr) && (m_front == ((m_rear + 1) % m_size))) { /* purecov: begin inspected */ m_waiting_for_dequeue = true; mutex_exit(&m_mutex); os_event_wait(m_dequeue_event); os_event_reset(m_dequeue_event); mutex_enter(&m_mutex); /* purecov: end */ } m_waiting_for_dequeue = false; if (m_ring_buffer != nullptr) { /* Perform the insert into the ring buffer and update the indexes. */ if (m_front == -1) { m_front = 0; } m_rear = (m_rear + 1) % m_size; m_ring_buffer[m_rear] = lb; os_event_set(m_enqueue_event); } mutex_exit(&m_mutex); } /** Dequeue the log block from the queue and update the indexes in the ring buffer. @param[out] lb The log that was dequeued from the queue. */ void dequeue(T &lb) { /* Enter the critical section before dequeuing log blocks to ensure thread safe reads. */ mutex_enter(&m_mutex); /* If the queue is empty wait for an enqueue. */ while ((m_ring_buffer != nullptr) && (m_front == -1)) { m_waiting_for_enqueue = true; mutex_exit(&m_mutex); os_event_wait(m_enqueue_event); os_event_reset(m_enqueue_event); mutex_enter(&m_mutex); } m_waiting_for_enqueue = false; if (m_ring_buffer != nullptr) { /* Perform the reads from the ring buffer and update the indexes. */ lb = m_ring_buffer[m_front]; if (m_front == m_rear) { m_front = -1; m_rear = -1; } else { m_front = (m_front + 1) % m_size; } os_event_set(m_dequeue_event); } mutex_exit(&m_mutex); } bool empty() { return m_front == -1; } private: /** Whether the producer waits for a dequeue event. */ bool m_waiting_for_dequeue{false}; /** Whether the consumer waits for an enqueue event. */ bool m_waiting_for_enqueue{false}; /** Index representing the front of the ring buffer. */ int m_front{-1}; /** Index representing the rear of the ring buffer. */ int m_rear{-1}; /** The total number of elements in the ring buffer. */ int m_size{0}; /** The buffer containing the contents of the queue. */ std::unique_ptr - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
日志的环形缓冲区和基本块的定义在上面的代码中可以看到,不过需要说明的是Queue是一个模板类,需要有点模板的知识。
下面看一下写入:/** @} */ /**************************************************/ /** @name Log write_notifier thread *******************************************************/ /** @{ */ void log_write_notifier(log_t *log_ptr) { ut_a(log_ptr != nullptr); log_t &log = *log_ptr; lsn_t lsn = log.write_lsn.load() + 1; log_write_notifier_mutex_enter(log); Log_thread_waiting waiting{log, log.write_notifier_event, srv_log_write_notifier_spin_delay, srv_log_write_notifier_timeout}; for (uint64_t step = 0;; ++step) { if (log.should_stop_threads.load()) { if (!log_writer_is_active()) { if (lsn > log.write_lsn.load()) { ut_a(lsn == log.write_lsn.load() + 1); break; } } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { log_write_notifier_mutex_exit(log); os_event_wait(log.writer_threads_resume_event); ut_ad(log.write_notifier_resume_lsn.load(std::memory_order_acquire) + 1 >= lsn); lsn = log.write_notifier_resume_lsn.load(std::memory_order_acquire) + 1; /* clears to acknowledge * / log.write_notifier_resume_lsn.store(0, std::memory_order_release); log_write_notifier_mutex_enter(log); } LOG_SYNC_POINT("log_write_notifier_before_check"); bool released = false; auto stop_condition = [&log, lsn, &released](bool wait) { LOG_SYNC_POINT("log_write_notifier_after_event_reset"); if (released) { log_write_notifier_mutex_enter(log); released = false; } LOG_SYNC_POINT("log_write_notifier_before_check"); if (log.write_lsn.load() >= lsn) { return (true); } if (log.should_stop_threads.load()) { if (!log_writer_is_active()) { return (true); } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { return (true); } if (wait) { log_write_notifier_mutex_exit(log); released = true; } LOG_SYNC_POINT("log_write_notifier_before_wait"); return (false); }; const auto wait_stats = waiting.wait(stop_condition); MONITOR_INC_WAIT_STATS(MONITOR_LOG_WRITE_NOTIFIER_, wait_stats); LOG_SYNC_POINT("log_write_notifier_before_write_lsn"); const lsn_t write_lsn = log.write_lsn.load(); const lsn_t notified_up_to_lsn = ut_uint64_align_up(write_lsn, OS_FILE_LOG_BLOCK_SIZE); while (lsn <= notified_up_to_lsn) { const auto slot = log_compute_write_event_slot(log, lsn); lsn += OS_FILE_LOG_BLOCK_SIZE; LOG_SYNC_POINT("log_write_notifier_before_notify"); os_event_set(log.write_events[slot]); } lsn = write_lsn + 1; if (step % 1024 == 0) { log_write_notifier_mutex_exit(log); std::this_thread::sleep_for(std::chrono::seconds(0)); log_write_notifier_mutex_enter(log); } } log_write_notifier_mutex_exit(log); } /** @} */ /**************************************************/ /** @name Log flush_notifier thread *******************************************************/ /** @{ */ void log_flush_notifier(log_t *log_ptr) { ut_a(log_ptr != nullptr); log_t &log = *log_ptr; lsn_t lsn = log.flushed_to_disk_lsn.load() + 1; log_flush_notifier_mutex_enter(log); Log_thread_waiting waiting{log, log.flush_notifier_event, srv_log_flush_notifier_spin_delay, srv_log_flush_notifier_timeout}; for (uint64_t step = 0;; ++step) { if (log.should_stop_threads.load()) { if (!log_flusher_is_active()) { if (lsn > log.flushed_to_disk_lsn.load()) { ut_a(lsn == log.flushed_to_disk_lsn.load() + 1); break; } } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { log_flush_notifier_mutex_exit(log); os_event_wait(log.writer_threads_resume_event); ut_ad(log.flush_notifier_resume_lsn.load(std::memory_order_acquire) + 1 >= lsn); lsn = log.flush_notifier_resume_lsn.load(std::memory_order_acquire) + 1; /* clears to acknowledge * / log.flush_notifier_resume_lsn.store(0, std::memory_order_release); log_flush_notifier_mutex_enter(log); } LOG_SYNC_POINT("log_flush_notifier_before_check"); bool released = false; auto stop_condition = [&log, lsn, &released](bool wait) { LOG_SYNC_POINT("log_flush_notifier_after_event_reset"); if (released) { log_flush_notifier_mutex_enter(log); released = false; } LOG_SYNC_POINT("log_flush_notifier_before_check"); if (log.flushed_to_disk_lsn.load() >= lsn) { return (true); } if (log.should_stop_threads.load()) { if (!log_flusher_is_active()) { return (true); } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { return (true); } if (wait) { log_flush_notifier_mutex_exit(log); released = true; } LOG_SYNC_POINT("log_flush_notifier_before_wait"); return (false); }; const auto wait_stats = waiting.wait(stop_condition); MONITOR_INC_WAIT_STATS(MONITOR_LOG_FLUSH_NOTIFIER_, wait_stats); LOG_SYNC_POINT("log_flush_notifier_before_flushed_to_disk_lsn"); const lsn_t flush_lsn = log.flushed_to_disk_lsn.load(); const lsn_t notified_up_to_lsn = ut_uint64_align_up(flush_lsn, OS_FILE_LOG_BLOCK_SIZE); while (lsn <= notified_up_to_lsn) { const auto slot = log_compute_flush_event_slot(log, lsn); lsn += OS_FILE_LOG_BLOCK_SIZE; LOG_SYNC_POINT("log_flush_notifier_before_notify"); os_event_set(log.flush_events[slot]); } lsn = flush_lsn + 1; if (step % 1024 == 0) { log_flush_notifier_mutex_exit(log); std::this_thread::sleep_for(std::chrono::seconds(0)); log_flush_notifier_mutex_enter(log); } } log_flush_notifier_mutex_exit(log); } static void log_files_write_buffer(log_t &log, byte *buffer, size_t buffer_size, lsn_t start_lsn) { ut_ad(log_writer_mutex_own(log)); using namespace Log_files_write_impl; validate_buffer(log, buffer, buffer_size); validate_start_lsn(log, start_lsn, buffer_size); checkpoint_no_t checkpoint_no = log.next_checkpoint_no.load(); const auto real_offset = compute_real_offset(log, start_lsn); bool write_from_log_buffer; auto write_size = compute_how_much_to_write(log, real_offset, buffer_size, write_from_log_buffer); if (write_size == 0) { start_next_file(log, start_lsn); return; } prepare_full_blocks(log, buffer, write_size, start_lsn, checkpoint_no); byte *write_buf; uint64_t written_ahead = 0; lsn_t lsn_advance = write_size; if (write_from_log_buffer) { /* We have at least one completed log block to write. We write completed blocks from the log buffer. Note, that possibly we do not write all completed blocks, because of write-ahead strategy (described earlier). */ DBUG_PRINT("ib_log", ("write from log buffer start_lsn=" LSN_PF " write_lsn=" LSN_PF " -> " LSN_PF, start_lsn, log.write_lsn.load(), start_lsn + lsn_advance)); write_buf = buffer; LOG_SYNC_POINT("log_writer_before_write_from_log_buffer"); } else { DBUG_PRINT("ib_log", ("incomplete write start_lsn=" LSN_PF " write_lsn=" LSN_PF " -> " LSN_PF, start_lsn, log.write_lsn.load(), start_lsn + lsn_advance)); #ifdef UNIV_DEBUG if (start_lsn == log.write_lsn.load()) { LOG_SYNC_POINT("log_writer_before_write_new_incomplete_block"); } /* Else: we are doing yet another incomplete block write within the same block as the one in which we did the previous write. */ #endif /* UNIV_DEBUG */ write_buf = log.write_ahead_buf; /* We write all the data directly from the write-ahead buffer, where we first need to copy the data. */ copy_to_write_ahead_buffer(log, buffer, write_size, start_lsn, checkpoint_no); if (!current_write_ahead_enough(log, real_offset, 1)) { written_ahead = prepare_for_write_ahead(log, real_offset, write_size); } } srv_stats.os_log_pending_writes.inc(); /* Now, we know, that we are going to write completed blocks only (originally or copied and completed). */ write_blocks(log, write_buf, write_size, real_offset); LOG_SYNC_POINT("log_writer_before_lsn_update"); const lsn_t old_write_lsn = log.write_lsn.load(); const lsn_t new_write_lsn = start_lsn + lsn_advance; ut_a(new_write_lsn > log.write_lsn.load()); log.write_lsn.store(new_write_lsn); notify_about_advanced_write_lsn(log, old_write_lsn, new_write_lsn); LOG_SYNC_POINT("log_writer_before_buf_limit_update"); log_update_buf_limit(log, new_write_lsn); srv_stats.os_log_pending_writes.dec(); srv_stats.log_writes.inc(); /* Write ahead is included in write_size. */ ut_a(write_size >= written_ahead); srv_stats.os_log_written.add(write_size - written_ahead); MONITOR_INC_VALUE(MONITOR_LOG_PADDED, written_ahead); int64_t free_space = log.lsn_capacity_for_writer - log.extra_margin; /* The free space may be negative (up to -log.extra_margin), in which case we are in the emergency mode, eating the extra margin and asking to increase concurrency_margin. * / free_space -= new_write_lsn - log.last_checkpoint_lsn.load(); MONITOR_SET(MONITOR_LOG_FREE_SPACE, free_space); log.n_log_ios++; update_current_write_ahead(log, real_offset, write_size); } static void log_writer_write_buffer(log_t &log, lsn_t next_write_lsn) { ut_ad(log_writer_mutex_own(log)); LOG_SYNC_POINT("log_writer_write_begin"); const lsn_t last_write_lsn = log.write_lsn.load(); ut_a(log_lsn_validate(last_write_lsn) || last_write_lsn % OS_FILE_LOG_BLOCK_SIZE == 0); ut_a(log_lsn_validate(next_write_lsn) || next_write_lsn % OS_FILE_LOG_BLOCK_SIZE == 0); ut_a(next_write_lsn - last_write_lsn <= log.buf_size); ut_a(next_write_lsn > last_write_lsn); size_t start_offset = last_write_lsn % log.buf_size; size_t end_offset = next_write_lsn % log.buf_size; if (start_offset >= end_offset) { ut_a(next_write_lsn - last_write_lsn >= log.buf_size - start_offset); end_offset = log.buf_size; next_write_lsn = last_write_lsn + (end_offset - start_offset); } ut_a(start_offset < end_offset); ut_a(end_offset % OS_FILE_LOG_BLOCK_SIZE == 0 || end_offset % OS_FILE_LOG_BLOCK_SIZE >= LOG_BLOCK_HDR_SIZE); /* Wait until there is free space in log files.*/ const lsn_t checkpoint_limited_lsn = log_writer_wait_on_checkpoint(log, last_write_lsn, next_write_lsn); ut_ad(log_writer_mutex_own(log)); ut_a(checkpoint_limited_lsn > last_write_lsn); LOG_SYNC_POINT("log_writer_after_checkpoint_check"); if (arch_log_sys != nullptr) { log_writer_wait_on_archiver(log, last_write_lsn, next_write_lsn); } ut_ad(log_writer_mutex_own(log)); LOG_SYNC_POINT("log_writer_after_archiver_check"); const lsn_t limit_for_next_write_lsn = checkpoint_limited_lsn; if (limit_for_next_write_lsn < next_write_lsn) { end_offset -= next_write_lsn - limit_for_next_write_lsn; next_write_lsn = limit_for_next_write_lsn; ut_a(end_offset > start_offset); ut_a(end_offset % OS_FILE_LOG_BLOCK_SIZE == 0 || end_offset % OS_FILE_LOG_BLOCK_SIZE >= LOG_BLOCK_HDR_SIZE); ut_a(log_lsn_validate(next_write_lsn) || next_write_lsn % OS_FILE_LOG_BLOCK_SIZE == 0); } DBUG_PRINT("ib_log", ("write " LSN_PF " to " LSN_PF, last_write_lsn, next_write_lsn)); byte *buf_begin = log.buf + ut_uint64_align_down(start_offset, OS_FILE_LOG_BLOCK_SIZE); byte *buf_end = log.buf + end_offset; /* Do the write to the log files * / log_files_write_buffer( log, buf_begin, buf_end - buf_begin, ut_uint64_align_down(last_write_lsn, OS_FILE_LOG_BLOCK_SIZE)); LOG_SYNC_POINT("log_writer_write_end"); } void log_writer(log_t *log_ptr) { ut_a(log_ptr != nullptr); log_t &log = *log_ptr; lsn_t ready_lsn = 0; log_writer_mutex_enter(log); Log_thread_waiting waiting{log, log.writer_event, srv_log_writer_spin_delay, srv_log_writer_timeout}; Log_write_to_file_requests_monitor write_to_file_requests_monitor{log}; for (uint64_t step = 0;; ++step) { bool released = false; auto stop_condition = [&ready_lsn, &log, &released, &write_to_file_requests_monitor](bool wait) { if (released) { log_writer_mutex_enter(log); released = false; } /* Advance lsn up to which data is ready in log buffer. */ log_advance_ready_for_write_lsn(log); ready_lsn = log_buffer_ready_for_write_lsn(log); /* Wait until any of following conditions holds: 1) There is some unwritten data in log buffer 2) We should close threads. */ if (log.write_lsn.load() < ready_lsn || log.should_stop_threads.load()) { return (true); } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { return (true); } if (wait) { write_to_file_requests_monitor.update(); log_writer_mutex_exit(log); released = true; } return (false); }; const auto wait_stats = waiting.wait(stop_condition); MONITOR_INC_WAIT_STATS(MONITOR_LOG_WRITER_, wait_stats); if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire) && !log.should_stop_threads.load())) { log_writer_mutex_exit(log); os_event_wait(log.writer_threads_resume_event); log_writer_mutex_enter(log); ready_lsn = log_buffer_ready_for_write_lsn(log); } /* Do the actual work. */ if (log.write_lsn.load() < ready_lsn) { log_writer_write_buffer(log, ready_lsn); if (step % 1024 == 0) { write_to_file_requests_monitor.update(); log_writer_mutex_exit(log); std::this_thread::sleep_for(std::chrono::seconds(0)); log_writer_mutex_enter(log); } } else { if (log.should_stop_threads.load()) { /* When log threads are stopped, we must first ensure that all writes to log buffer have been finished and only then we are allowed to set the should_stop_threads to true. * / log_advance_ready_for_write_lsn(log); ready_lsn = log_buffer_ready_for_write_lsn(log); if (log.write_lsn.load() == ready_lsn) { break; } } } } log_writer_mutex_exit(log); } void log_flusher(log_t *log_ptr) { ut_a(log_ptr != nullptr); log_t &log = *log_ptr; Log_thread_waiting waiting{log, log.flusher_event, srv_log_flusher_spin_delay, srv_log_flusher_timeout}; log_flusher_mutex_enter(log); for (uint64_t step = 0;; ++step) { if (log.should_stop_threads.load()) { if (!log_writer_is_active()) { /* If write_lsn > flushed_to_disk_lsn, we are going to execute one more fsync just after the for-loop and before this thread exits (inside log_flush_low at the very end of function def.). */ break; } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { log_flusher_mutex_exit(log); os_event_wait(log.writer_threads_resume_event); log_flusher_mutex_enter(log); } bool released = false; auto stop_condition = [&log, &released, step](bool wait) { if (released) { log_flusher_mutex_enter(log); released = false; } LOG_SYNC_POINT("log_flusher_before_should_flush"); const lsn_t last_flush_lsn = log.flushed_to_disk_lsn.load(); ut_a(last_flush_lsn <= log.write_lsn.load()); if (last_flush_lsn < log.write_lsn.load()) { /* Flush and stop waiting. */ log_flush_low(log); if (step % 1024 == 0) { log_flusher_mutex_exit(log); std::this_thread::sleep_for(std::chrono::seconds(0)); log_flusher_mutex_enter(log); } return (true); } /* Stop waiting if writer thread is dead. */ if (log.should_stop_threads.load()) { if (!log_writer_is_active()) { return (true); } } if (UNIV_UNLIKELY( log.writer_threads_paused.load(std::memory_order_acquire))) { return (true); } if (wait) { log_flusher_mutex_exit(log); released = true; } return (false); }; if (srv_flush_log_at_trx_commit != 1) { const auto current_time = Log_clock::now(); ut_ad(log.last_flush_end_time >= log.last_flush_start_time); if (current_time < log.last_flush_end_time) { /* Time was moved backward, possibly by a lot, so we need to adjust the last_flush times, because otherwise we could stop flushing every innodb_flush_log_at_timeout for a while. */ log.last_flush_start_time = current_time; log.last_flush_end_time = current_time; } const auto time_elapsed = current_time - log.last_flush_start_time; using us = std::chrono::microseconds; const auto time_elapsed_us = std::chrono::duration_cast(time_elapsed).count(); ut_a(time_elapsed_us >= 0); const auto flush_every = srv_flush_log_at_timeout; const auto flush_every_us = 1000000LL * flush_every; if (time_elapsed_us < flush_every_us) { log_flusher_mutex_exit(log); /* When we are asked to stop threads, do not respect the limit for flushes per second. * / if (!log.should_stop_threads.load()) { os_event_wait_time_low(log.flusher_event, flush_every_us - time_elapsed_us, 0); } log_flusher_mutex_enter(log); } } const auto wait_stats = waiting.wait(stop_condition); MONITOR_INC_WAIT_STATS(MONITOR_LOG_FLUSHER_, wait_stats); } if (log.write_lsn.load() > log.flushed_to_disk_lsn.load()) { log_flush_low(log); } ut_a(log.write_lsn.load() == log.flushed_to_disk_lsn.load()); log_flusher_mutex_exit(log); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
前面提到过,日志可以多线程操作,所以有这个事件通知写入函数。
其实上面这些说明还是有些复杂,要想更清楚的分析这个文件代码,还是看一下log0recv.cc中的分析函数:/** Try to parse a single log record body and also applies it if specified. @param[in] type Redo log entry type @param[in] ptr Redo log record body @param[in] end_ptr End of buffer @param[in] space_id Tablespace identifier @param[in] page_no Page number @param[in,out] block Buffer block, or nullptr if a page log record should not be applied or if it is a MLOG_FILE_ operation @param[in,out] mtr Mini-transaction, or nullptr if a page log record should not be applied @param[in] parsed_bytes Number of bytes parsed so far @param[in] start_lsn lsn for REDO record @return log record end, nullptr if not a complete record */ static byte *recv_parse_or_apply_log_rec_body( mlog_id_t type, byte *ptr, byte *end_ptr, space_id_t space_id, page_no_t page_no, buf_block_t *block, mtr_t *mtr, ulint parsed_bytes, lsn_t start_lsn) { bool applying_redo = (block != nullptr); switch (type) { #ifndef UNIV_HOTBACKUP case MLOG_FILE_DELETE: return (fil_tablespace_redo_delete( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, recv_sys->bytes_to_ignore_before_checkpoint != 0)); case MLOG_FILE_CREATE: return (fil_tablespace_redo_create( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, recv_sys->bytes_to_ignore_before_checkpoint != 0)); case MLOG_FILE_RENAME: return (fil_tablespace_redo_rename( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, recv_sys->bytes_to_ignore_before_checkpoint != 0)); case MLOG_FILE_EXTEND: return (fil_tablespace_redo_extend( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, recv_sys->bytes_to_ignore_before_checkpoint != 0)); #else /* !UNIV_HOTBACKUP */ // Mysqlbackup does not execute file operations. It cares for all // files to be at their final places when it applies the redo log. // The exception is the restore of an incremental_with_redo_log_only // backup. case MLOG_FILE_DELETE: return (fil_tablespace_redo_delete( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, !recv_sys->apply_file_operations)); case MLOG_FILE_CREATE: return (fil_tablespace_redo_create( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, !recv_sys->apply_file_operations)); case MLOG_FILE_RENAME: return (fil_tablespace_redo_rename( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, !recv_sys->apply_file_operations)); case MLOG_FILE_EXTEND: return (fil_tablespace_redo_extend( ptr, end_ptr, page_id_t(space_id, page_no), parsed_bytes, !recv_sys->apply_file_operations)); #endif /* !UNIV_HOTBACKUP */ case MLOG_INDEX_LOAD: #ifdef UNIV_HOTBACKUP // While scaning redo logs during a backup operation a // MLOG_INDEX_LOAD type redo log record indicates, that a DDL // (create index, alter table...) is performed with // 'algorithm=inplace'. The affected tablespace must be re-copied // in the backup lock phase. Record it in the index_load_list. if (!recv_recovery_on) { index_load_list.emplace_back( std::pair(ptr) << " end_ptr " << static_cast (end_ptr) << " block " << static_cast (block) << " mtr " << static_cast (mtr); #endif /* UNIV_HOTBACKUP && UNIV_DEBUG */ if (applying_redo) { /* Applying a page log record. */ ut_ad(mtr != nullptr); page = block->frame; page_zip = buf_block_get_page_zip(block); ut_d(page_type = fil_page_get_type(page)); #if defined(UNIV_HOTBACKUP) && defined(UNIV_DEBUG) if (page_type == 0) { meb_print_page_header(page); } #endif /* UNIV_HOTBACKUP && UNIV_DEBUG */ } else { /* Parsing a page log record. */ ut_ad(mtr == nullptr); page = nullptr; page_zip = nullptr; ut_d(page_type = FIL_PAGE_TYPE_ALLOCATED); } const byte *old_ptr = ptr; switch (type) { #ifdef UNIV_LOG_LSN_DEBUG case MLOG_LSN: /* The LSN is checked in recv_parse_log_rec(). */ break; #endif /* UNIV_LOG_LSN_DEBUG */ case MLOG_4BYTES: ut_ad(page == nullptr || end_ptr > ptr + 2); /* Most FSP flags can only be changed by CREATE or ALTER with ALGORITHM=COPY, so they do not change once the file is created. The SDI flag is the only one that can be changed by a recoverable transaction. So if there is change in FSP flags, update the in-memory space structure (fil_space_t) */ if (page != nullptr && page_no == 0 && mach_read_from_2(ptr) == FSP_HEADER_OFFSET + FSP_SPACE_FLAGS) { ptr = mlog_parse_nbytes(MLOG_4BYTES, ptr, end_ptr, page, page_zip); /* When applying log, we have complete records. They can be incomplete (ptr=nullptr) only during scanning (page==nullptr) */ ut_ad(ptr != nullptr); fil_space_t *space = fil_space_acquire(space_id); ut_ad(space != nullptr); fil_space_set_flags(space, mach_read_from_4(FSP_HEADER_OFFSET + FSP_SPACE_FLAGS + page)); fil_space_release(space); break; } // fall through case MLOG_1BYTE: /* If 'ALTER TABLESPACE ... ENCRYPTION' was in progress and page 0 has REDO entry for this, now while applying this entry, set encryption_op_in_progress flag now so that any other page of this tablespace in redo log is written accordingly. */ if (page_no == 0 && page != nullptr && end_ptr >= ptr + 2) { ulint offs = mach_read_from_2(ptr); fil_space_t *space = fil_space_acquire(space_id); ut_ad(space != nullptr); ulint offset = fsp_header_get_encryption_progress_offset( page_size_t(space->flags)); if (offs == offset) { ptr = mlog_parse_nbytes(MLOG_1BYTE, ptr, end_ptr, page, page_zip); byte op = mach_read_from_1(page + offset); switch (op) { case Encryption::ENCRYPT_IN_PROGRESS: space->encryption_op_in_progress = ENCRYPTION; break; case Encryption::DECRYPT_IN_PROGRESS: space->encryption_op_in_progress = DECRYPTION; break; default: space->encryption_op_in_progress = NONE; break; } } fil_space_release(space); } // fall through case MLOG_2BYTES: case MLOG_8BYTES: #ifdef UNIV_DEBUG if (page && page_type == FIL_PAGE_TYPE_ALLOCATED && end_ptr >= ptr + 2) { /* It is OK to set FIL_PAGE_TYPE and certain list node fields on an empty page. Any other write is not OK. */ /* NOTE: There may be bogus assertion failures for dict_hdr_create(), trx_rseg_header_create(), trx_sys_create_doublewrite_buf(), and trx_sysf_create(). These are only called during database creation. */ ulint offs = mach_read_from_2(ptr); switch (type) { default: ut_error; case MLOG_2BYTES: /* Note that this can fail when the redo log been written with something older than InnoDB Plugin 1.0.4. */ ut_ad( offs == FIL_PAGE_TYPE || offs == IBUF_TREE_SEG_HEADER + IBUF_HEADER + FSEG_HDR_OFFSET || offs == PAGE_BTR_IBUF_FREE_LIST + PAGE_HEADER + FIL_ADDR_BYTE || offs == PAGE_BTR_IBUF_FREE_LIST + PAGE_HEADER + FIL_ADDR_BYTE + FIL_ADDR_SIZE || offs == PAGE_BTR_SEG_LEAF + PAGE_HEADER + FSEG_HDR_OFFSET || offs == PAGE_BTR_SEG_TOP + PAGE_HEADER + FSEG_HDR_OFFSET || offs == PAGE_BTR_IBUF_FREE_LIST_NODE + PAGE_HEADER + FIL_ADDR_BYTE + 0 /*FLST_PREV*/ || offs == PAGE_BTR_IBUF_FREE_LIST_NODE + PAGE_HEADER + FIL_ADDR_BYTE + FIL_ADDR_SIZE /*FLST_NEXT*/); break; case MLOG_4BYTES: /* Note that this can fail when the redo log been written with something older than InnoDB Plugin 1.0.4. */ ut_ad( 0 || offs == IBUF_TREE_SEG_HEADER + IBUF_HEADER + FSEG_HDR_SPACE || offs == IBUF_TREE_SEG_HEADER + IBUF_HEADER + FSEG_HDR_PAGE_NO || offs == PAGE_BTR_IBUF_FREE_LIST + PAGE_HEADER /* flst_init */ || offs == PAGE_BTR_IBUF_FREE_LIST + PAGE_HEADER + FIL_ADDR_PAGE || offs == PAGE_BTR_IBUF_FREE_LIST + PAGE_HEADER + FIL_ADDR_PAGE + FIL_ADDR_SIZE || offs == PAGE_BTR_SEG_LEAF + PAGE_HEADER + FSEG_HDR_PAGE_NO || offs == PAGE_BTR_SEG_LEAF + PAGE_HEADER + FSEG_HDR_SPACE || offs == PAGE_BTR_SEG_TOP + PAGE_HEADER + FSEG_HDR_PAGE_NO || offs == PAGE_BTR_SEG_TOP + PAGE_HEADER + FSEG_HDR_SPACE || offs == PAGE_BTR_IBUF_FREE_LIST_NODE + PAGE_HEADER + FIL_ADDR_PAGE + 0 /*FLST_PREV*/ || offs == PAGE_BTR_IBUF_FREE_LIST_NODE + PAGE_HEADER + FIL_ADDR_PAGE + FIL_ADDR_SIZE /*FLST_NEXT*/); break; } } #endif /* UNIV_DEBUG */ ptr = mlog_parse_nbytes(type, ptr, end_ptr, page, page_zip); if (ptr != nullptr && page != nullptr && page_no == 0 && type == MLOG_4BYTES) { ulint offs = mach_read_from_2(old_ptr); switch (offs) { fil_space_t *space; uint32_t val; default: break; case FSP_HEADER_OFFSET + FSP_SPACE_FLAGS: case FSP_HEADER_OFFSET + FSP_SIZE: case FSP_HEADER_OFFSET + FSP_FREE_LIMIT: case FSP_HEADER_OFFSET + FSP_FREE + FLST_LEN: space = fil_space_get(space_id); ut_a(space != nullptr); val = mach_read_from_4(page + offs); switch (offs) { case FSP_HEADER_OFFSET + FSP_SPACE_FLAGS: space->flags = val; break; case FSP_HEADER_OFFSET + FSP_SIZE: space->size_in_header = val; if (space->size >= val) { break; } ib::info(ER_IB_MSG_718, ulong{space->id}, space->name, ulong{val}); if (fil_space_extend(space, val)) { break; } ib::error(ER_IB_MSG_719, ulong{space->id}, space->name, ulong{val}); break; case FSP_HEADER_OFFSET + FSP_FREE_LIMIT: space->free_limit = val; break; case FSP_HEADER_OFFSET + FSP_FREE + FLST_LEN: space->free_len = val; ut_ad(val == flst_get_len(page + offs)); break; } } } break; case MLOG_REC_INSERT: case MLOG_COMP_REC_INSERT: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index(ptr, end_ptr, type == MLOG_COMP_REC_INSERT, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = page_cur_parse_insert_rec(FALSE, ptr, end_ptr, block, index, mtr); } break; case MLOG_REC_CLUST_DELETE_MARK: case MLOG_COMP_REC_CLUST_DELETE_MARK: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index( ptr, end_ptr, type == MLOG_COMP_REC_CLUST_DELETE_MARK, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = btr_cur_parse_del_mark_set_clust_rec(ptr, end_ptr, page, page_zip, index); } break; case MLOG_COMP_REC_SEC_DELETE_MARK: ut_ad(!page || fil_page_type_is_index(page_type)); /* This log record type is obsolete, but we process it for backward compatibility with MySQL 5.0.3 and 5.0.4. */ ut_a(!page || page_is_comp(page)); ut_a(!page_zip); ptr = mlog_parse_index(ptr, end_ptr, true, &index); if (ptr == nullptr) { break; } /* Fall through */ case MLOG_REC_SEC_DELETE_MARK: ut_ad(!page || fil_page_type_is_index(page_type)); ptr = btr_cur_parse_del_mark_set_sec_rec(ptr, end_ptr, page, page_zip); break; case MLOG_REC_UPDATE_IN_PLACE: case MLOG_COMP_REC_UPDATE_IN_PLACE: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index( ptr, end_ptr, type == MLOG_COMP_REC_UPDATE_IN_PLACE, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = btr_cur_parse_update_in_place(ptr, end_ptr, page, page_zip, index); } break; case MLOG_LIST_END_DELETE: case MLOG_COMP_LIST_END_DELETE: case MLOG_LIST_START_DELETE: case MLOG_COMP_LIST_START_DELETE: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index(ptr, end_ptr, type == MLOG_COMP_LIST_END_DELETE || type == MLOG_COMP_LIST_START_DELETE, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = page_parse_delete_rec_list(type, ptr, end_ptr, block, index, mtr); } break; case MLOG_LIST_END_COPY_CREATED: case MLOG_COMP_LIST_END_COPY_CREATED: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index( ptr, end_ptr, type == MLOG_COMP_LIST_END_COPY_CREATED, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = page_parse_copy_rec_list_to_created_page(ptr, end_ptr, block, index, mtr); } break; case MLOG_PAGE_REORGANIZE: ut_ad(!page || fil_page_type_is_index(page_type)); /* Uncompressed pages don't have any payload in the MTR so ptr and end_ptr can be, and are nullptr */ mlog_parse_index(ptr, end_ptr, false, &index); ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = btr_parse_page_reorganize(ptr, end_ptr, index, false, block, mtr); break; case MLOG_COMP_PAGE_REORGANIZE: case MLOG_ZIP_PAGE_REORGANIZE: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index(ptr, end_ptr, true, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = btr_parse_page_reorganize( ptr, end_ptr, index, type == MLOG_ZIP_PAGE_REORGANIZE, block, mtr); } break; case MLOG_PAGE_CREATE: case MLOG_COMP_PAGE_CREATE: /* Allow anything in page_type when creating a page. */ ut_a(!page_zip); page_parse_create(block, type == MLOG_COMP_PAGE_CREATE, FIL_PAGE_INDEX); break; case MLOG_PAGE_CREATE_RTREE: case MLOG_COMP_PAGE_CREATE_RTREE: page_parse_create(block, type == MLOG_COMP_PAGE_CREATE_RTREE, FIL_PAGE_RTREE); break; case MLOG_PAGE_CREATE_SDI: case MLOG_COMP_PAGE_CREATE_SDI: page_parse_create(block, type == MLOG_COMP_PAGE_CREATE_SDI, FIL_PAGE_SDI); break; case MLOG_UNDO_INSERT: ut_ad(!page || page_type == FIL_PAGE_UNDO_LOG); ptr = trx_undo_parse_add_undo_rec(ptr, end_ptr, page); break; case MLOG_UNDO_ERASE_END: ut_ad(!page || page_type == FIL_PAGE_UNDO_LOG); ptr = trx_undo_parse_erase_page_end(ptr, end_ptr, page, mtr); break; case MLOG_UNDO_INIT: /* Allow anything in page_type when creating a page. */ ptr = trx_undo_parse_page_init(ptr, end_ptr, page, mtr); break; case MLOG_UNDO_HDR_CREATE: case MLOG_UNDO_HDR_REUSE: ut_ad(!page || page_type == FIL_PAGE_UNDO_LOG); ptr = trx_undo_parse_page_header(type, ptr, end_ptr, page, mtr); break; case MLOG_REC_MIN_MARK: case MLOG_COMP_REC_MIN_MARK: ut_ad(!page || fil_page_type_is_index(page_type)); /* On a compressed page, MLOG_COMP_REC_MIN_MARK will be followed by MLOG_COMP_REC_DELETE or MLOG_ZIP_WRITE_HEADER(FIL_PAGE_PREV, FIL_nullptr) in the same mini-transaction. */ ut_a(type == MLOG_COMP_REC_MIN_MARK || !page_zip); ptr = btr_parse_set_min_rec_mark( ptr, end_ptr, type == MLOG_COMP_REC_MIN_MARK, page, mtr); break; case MLOG_REC_DELETE: case MLOG_COMP_REC_DELETE: ut_ad(!page || fil_page_type_is_index(page_type)); if (nullptr != (ptr = mlog_parse_index(ptr, end_ptr, type == MLOG_COMP_REC_DELETE, &index))) { ut_a(!page || (ibool) !!page_is_comp(page) == dict_table_is_comp(index->table)); ptr = page_cur_parse_delete_rec(ptr, end_ptr, block, index, mtr); } break; case MLOG_IBUF_BITMAP_INIT: /* Allow anything in page_type when creating a page. */ ptr = ibuf_parse_bitmap_init(ptr, end_ptr, block, mtr); break; case MLOG_INIT_FILE_PAGE: case MLOG_INIT_FILE_PAGE2: /* Allow anything in page_type when creating a page. */ ptr = fsp_parse_init_file_page(ptr, end_ptr, block); break; case MLOG_WRITE_STRING: ut_ad(!page || page_type != FIL_PAGE_TYPE_ALLOCATED || page_no == 0); #ifndef UNIV_HOTBACKUP /* Reset in-mem encryption information for the tablespace here if this is "resetting encryprion info" log. */ if (page_no == 0 && !fsp_is_system_or_temp_tablespace(space_id)) { byte buf[Encryption::INFO_SIZE] = {0}; if (memcmp(ptr + 4, buf, Encryption::INFO_SIZE - 4) == 0) { ut_a(DB_SUCCESS == fil_reset_encryption(space_id)); } } #endif ptr = mlog_parse_string(ptr, end_ptr, page, page_zip); break; case MLOG_ZIP_WRITE_NODE_PTR: ut_ad(!page || fil_page_type_is_index(page_type)); ptr = page_zip_parse_write_node_ptr(ptr, end_ptr, page, page_zip); break; case MLOG_ZIP_WRITE_BLOB_PTR: ut_ad(!page || fil_page_type_is_index(page_type)); ptr = page_zip_parse_write_blob_ptr(ptr, end_ptr, page, page_zip); break; case MLOG_ZIP_WRITE_HEADER: ut_ad(!page || fil_page_type_is_index(page_type)); ptr = page_zip_parse_write_header(ptr, end_ptr, page, page_zip); break; case MLOG_ZIP_PAGE_COMPRESS: /* Allow anything in page_type when creating a page. */ ptr = page_zip_parse_compress(ptr, end_ptr, page, page_zip); break; case MLOG_ZIP_PAGE_COMPRESS_NO_DATA: if (nullptr != (ptr = mlog_parse_index(ptr, end_ptr, true, &index))) { ut_a(!page || ((ibool) !!page_is_comp(page) == dict_table_is_comp(index->table))); ptr = page_zip_parse_compress_no_data(ptr, end_ptr, page, page_zip, index); } break; case MLOG_TEST: #ifndef UNIV_HOTBACKUP if (log_test != nullptr) { ptr = log_test->parse_mlog_rec(ptr, end_ptr); } else { /* Just parse and ignore record to pass it and go forward. Note that this record is also used in the innodb.log_first_rec_group mtr test. The record is written in the buf0flu.cc when flushing page in that case. */ Log_test::Key key; Log_test::Value value; lsn_t start_lsn, end_lsn; ptr = Log_test::parse_mlog_rec(ptr, end_ptr, key, value, start_lsn, end_lsn); } break; #endif /* !UNIV_HOTBACKUP */ /* Fall through. * / default: ptr = nullptr; recv_sys->found_corrupt_log = true; } if (index != nullptr) { dict_table_t * table = index->table; dict_mem_index_free(index); dict_mem_table_free(table); } return (ptr); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
光看开头注释的说明就应该明白这个是干啥的了。在这个文件中还有很多相关的函数可以看一看,就会变得更清楚。
五、总结
MySql的代码分析越坚持下去,发现原来的一些认知不是模糊,就是有些片面。上中学时,老师总是说:“读书百遍,其意自现”,看来老师的说法很对。把薄书读厚,把厚书读薄,从不同的角度,不同的层面去看待同一个问题,可能出现的结果就会有所不同,甚至是完成相反的情况。
坚持学习,努力进步,才是王道。迷茫的时候儿,多读书,少谈经验! -
相关阅读:
投资的思考
深度学习框架pytorch:tensor.data和tensor.detach()的区别
abortControllerMap: Map<string, AbortController>
无需测试环境!如何利用测试脚手架隔离微服务,实现功能自动化
能不能手写Vue响应式?前端面试进阶
蓝桥杯刷题二
浅谈中国汽车充电桩行业市场状况及充电桩选型的介绍
独家 | 如何比较两个或多个分布形态(附链接)
改进YOLOv5/YOLOv8:结合华为诺亚VanillaNet Block模块:深度学习中极简主义的力量
k8s敏感数据存储:Secret
- 原文地址:https://blog.csdn.net/fpcc/article/details/127701053
