-
【数据结构与算法分析】0基础带你学数据结构与算法分析08--二叉查找树 (BST)
假设树上每个结点都存储了一项数据,如果这些数据是杂乱无章的插入树中,那查找这些数据时并不容易,需要 O(N) 的时间复杂度来遍历每个结点搜索数据。
如果想要时间复杂度降到 O(logN) ,则需要在常数时间内,将问题的大小缩减。如果为一个结点加上限制,比如子树上的值总比当前结点的值大,而另一边总比当前结点的值小,如此便在常数时间内可以将问题的大小减半,可以判断接下来搜索左子树还是右子树。这种加以限制的二叉树被称为 二叉查找树 (Binary Search Tree, BST)。假定 BST 中左结点总是严格小于当前结点的值,而右结点总是不小于当前结点的值。
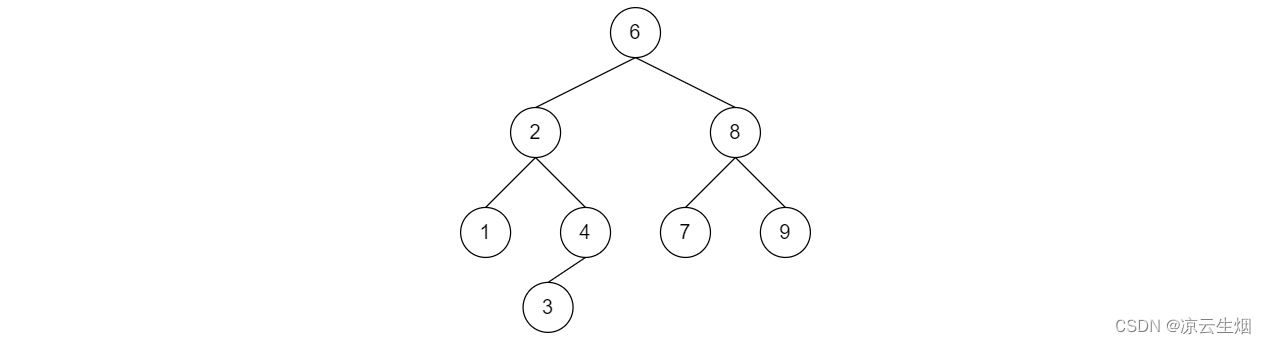
二叉树的遍历四种方法很简单,如果将其用于 BST 上有什么效果呢:
- 前序遍历: 6,2,1,4,3,8,7,9
- 中序遍历: 1,2,3,4,6,7,8,9
- 后序遍历: 1,3,4,2,7,9,8,6
- 层序遍历: 6,2,8,1,4,7,9,3
BST 中进行查找
对 BST 的查找操作中,以下三种操作是最为简单的。
-
判断元素是否存在,存在时将返回
true,反之返回false
- template <class Element>
- bool contains(BinaryTreeNode
* root, const Element& target) { - if (root == nullptr) {
- return false;
- }
- if (root->data == target) {
- return true;
- }
- return contains(root->data < target ? root->right : root->left, target);
- }
- 查找最小值并返回其结点
- template <class Element>
- BinaryTreeNode
* find_min(BinaryTreeNode {* root) - if (root == nullptr) {
- return nullptr;
- }
- return root->left == nullptr ? root : find_min(root->left);
- }
-
查找最大值并返回其结点
- template <class Element>
- BinaryTreeNode
* find_max(BinaryTreeNode {* root) - if (root != nullptr) {
- while (root->right != nullptr) {
- root = root->right;
- }
- }
- return root;
- }

- // 获取下界
- template <class Element>
- BinaryTreeNode* get_lower_bound(BinaryTreeNode* root, const Element& target) {
- auto result = root;
- while (root != nullptr) {
- if (!(root->data < target)) {
- result = root;
- root = root->left;
- } else {
- root = root->right;
- }
- }
- return result;
- }
- // 获取上界
- template <class Element>
- BinaryTreeNode* get_upper_bound(BinaryTreeNode* root, const Element& target) {
- auto result = root;
- while (root != nullptr) {
- if (target < root->data) {
- result = root;
- root = root->left;
- } else {
- root = root->right;
- }
- }
- return result;
- }
BST 中进行插入与移除操作
插入一个元素在 BST 上的操作十分简单,与
contains函数一样,以 BST 的定义顺着 BST 向下寻找,直到结点的子结点为 nullptr 为止,将这个插入的结点挂载到这个查找到的子结点上。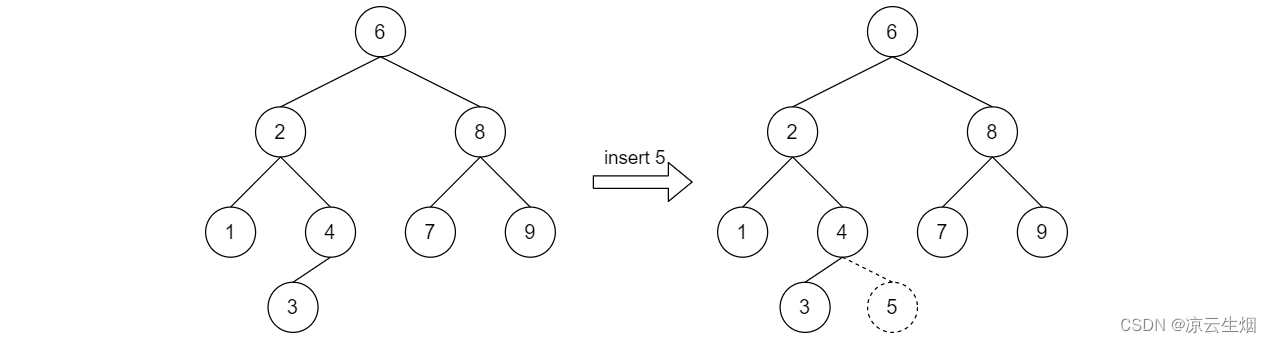
如果是移除操作呢?我们一直忽略了如何在二叉树中移除一个元素,因为正常的一棵二叉树中,如果你想移除一个结点,你需要处理移除结点之后 parent 与 child 之间的关系。这并不好处理,你不确定这些 child 是否可以挂载到 parent 上,继续以 parent 的子结点出现。幸运的是,你可以直接将其值与一个 leaf 交换,并直接删除 leaf 就好,这样你就没有 parent 的担忧了。
这种交换的方式可以用于 BST 吗?当然是完全可以。现在只剩下一个问题了,如何保证在移除结点后,这棵树依然是 BST,稍微转换一下问题的问法:和哪个 leaf 交换不会影响 BST 的结构。
当然是和其前驱或者后继交换后再删除不会影响 BST 的整体结构,如果前驱或后继并不是 leaf,那么递归地交换结点的值,直到结点是 leaf 为止。如果这个结点本身就是 leaf,那不用找了,决定就是你了!
可选择前驱还是后继呢,如果结点有右子树,则代表着其后继在右子树中;如果结点有左子树,则表达其前驱在左子树中。如果没有对应的子树,代表其前驱或者后继需要回到父结点寻找,为了不必要的复杂度,一般选择在其子树中寻找前驱 / 后继结点。如果你找到了一个结点的前驱 / 后继,如果它不是 leaf,那它一定没有后继 / 前驱所对应的子树,被迫你只能一直沿着向前或向后寻找 leaf。

BST 的平均情况分析
一棵树的所有结点的深度和称为 内部路径长 (internal path length),我们尝试计算 BST 平均路径长。令 D(N) 是具有 N 个结点的某棵树 T 的内部路径长,则有 D(1)=0。一棵 N 结点树是由一棵 i(0≤i
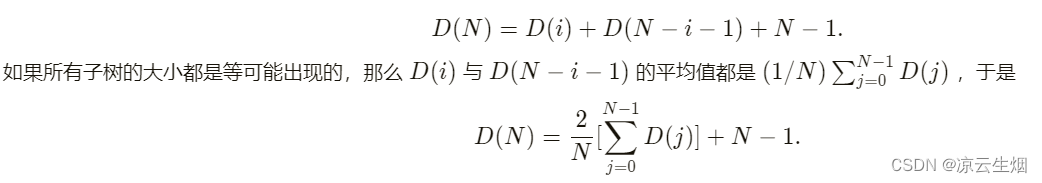
得到平均值 D(N)=O(NlogN) ,因此结点的预期深度 O(logN) ,但这不意味着所有操作的平均运行时间是 O(logN) 。
Weiss 在书中为我们展示了一个随机生成的 500 个结点的 BST,其期望平均深度为 9.98。
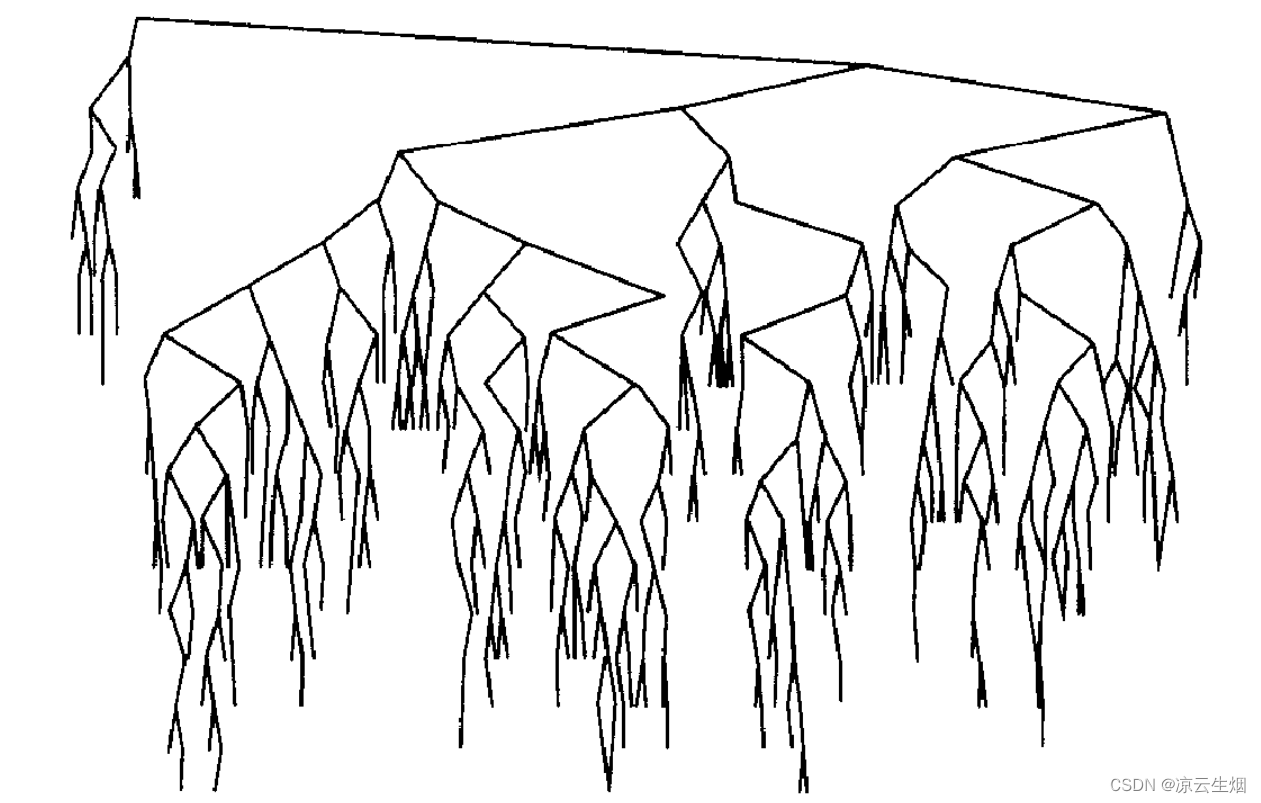
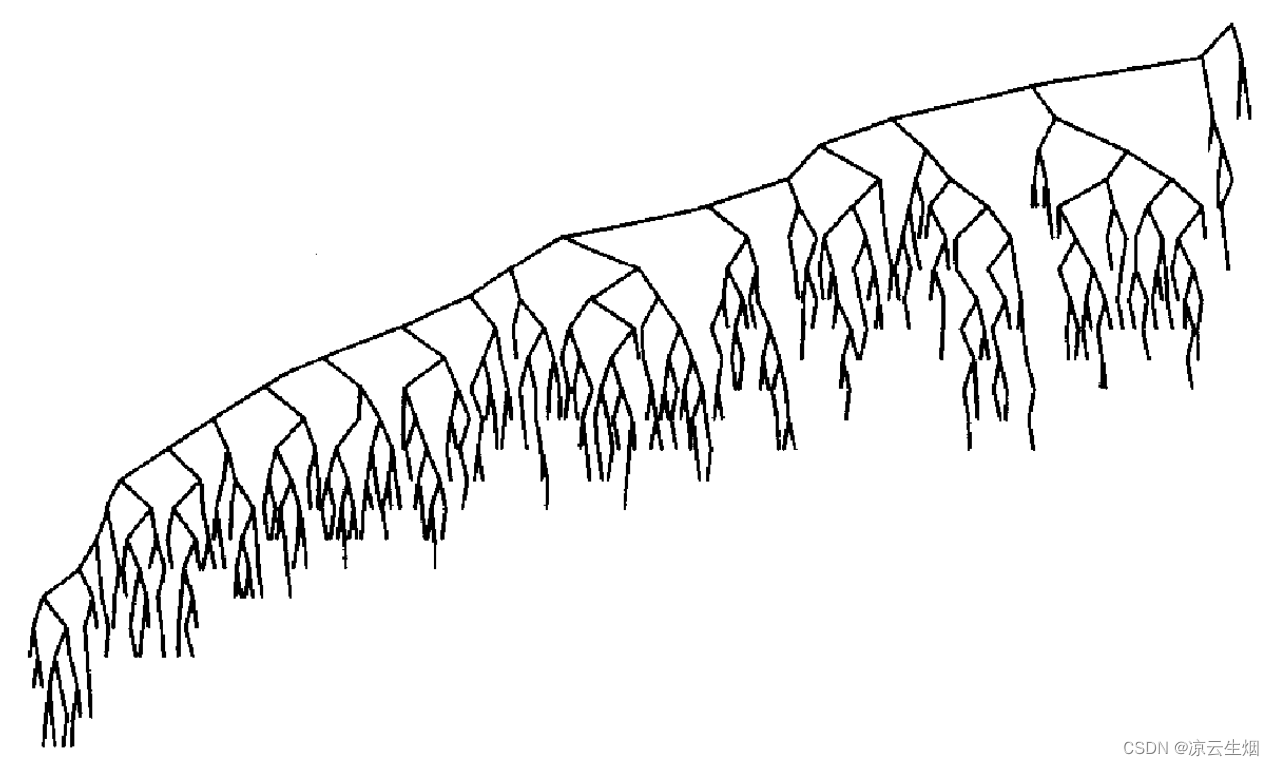
如果交替插入和删除 Θ(N^2) 次,那么树的平均期望深度将是 Θ(N) 。而下图展示了在 25 万次插入移除随机值之后树的样子,结点的平均深度为 12.51 。其中有可能的一个原因是,在移除结点时 remove 总是倾向于移除结点的前驱,而保留了结点的后继。我们可以尝试随机移除结点前驱或后继的方法来缓解这种不平衡。还有一个原因是一个给定序列,由根 (给定序列的第一个元素) 的值决定这棵树的偏向,如果根元素过大则会导致左子树的结点更多,因为序列中大部位数都小于根,反之则导致右子树结点增多。
-
相关阅读:
美格智能NB-IoT模组通过三个1000小时可靠性测试,并中标中国电信项目招标
“用友审批,兴业付款”,YonSuite让企业资金调拨更高效
LCD1602指定位置显示字符串-详细版
Apache Maven
第12讲:DVM 以及 ART 是如何对 JVM 进行优化的?
c# - - - CentOS 7 部署ASP.Net Core项目
Pytest系列-快速入门和基础讲解(1)
【入门篇】本章包括创建云项目、数据库的使用、云存储管理、云函数的基本使用、实战举例(小程序之云函数开发入门到使用发布上线实操)
Vue+Element switch组件的使用
社交媒体数据恢复:Facebook
- 原文地址:https://blog.csdn.net/qq_62464995/article/details/127687170