-
InfluxDB学习记录(三)——influxdb的flux语法
什么是Flux
Flux 是 InfluxData 的功能性数据脚本语言,设计用于查询、分析和处理数据,它是InfluxQL 和其他类似 SQL 的查询语言的替代品。
每个 Flux 查询都需要以下内容:
- 数据源
- 时间范围
- 数据过滤器
Flux代码示例
from(bucket:"example-bucket") |> range(start: -15m) |> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total" )- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例解析
1、定义数据源
Flux的from()函数定义 InfluxDB 数据源。 它需要一个bucket参数。
example-bucket就是bucket的名称from(bucket:"example-bucket")- 1
2、指定时间范围
查询时间序列数据时,Flux 需要一个时间范围。 “无限”查询非常耗费资源,作为一种保护措施, Flux 不会查询没有指定范围的数据库。
|>range(),指定查询的时间范围。 它接受两个参数:start 和stop。
start 值和stop 值可以使用负持续时间是相对值,也可以是使用时间戳的绝对值。
相对范围,相对于“现在”。
// Relative time range with start only. Stop defaults to now. from(bucket:"example-bucket") |> range(start: -1h) // Relative time range with start and stop from(bucket:"example-bucket") |> range(start: -1h, stop: -10m)- 1
- 2
- 3
- 4
- 5
- 6
- 7
绝对范围
from(bucket:"example-bucket") |> range(start: 2021-01-01T00:00:00Z, stop: 2021-01-01T12:00:00Z)- 1
- 2
3、过滤数据
将范围数据传递到filter()函数中,以根据数据属性或列缩小结果范围。
该filter()函数有一个参数,fn它需要一个匿名函数,该函数具有基于列或属性过滤数据的逻辑(类似于lambda表达式)// Example with single filter (r) => (r._measurement == "cpu") // Example with multiple filters (r) => (r._measurement == "cpu") and (r._field != "usage_system" )- 1
- 2
- 3
- 4
- 5
扩展
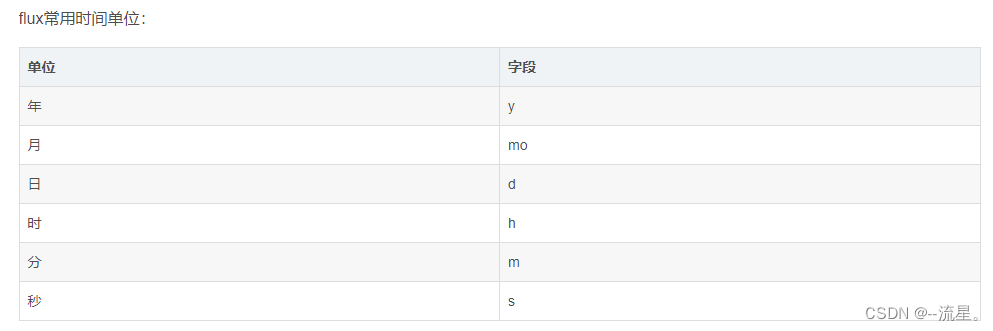
附:参考资料
1、【InfluxDB V2.0】介绍与使用,flux查询、数据可视化
2、官方文档
3、【InfluxDB V2.0】单表、跨表聚合Flux查询 -
相关阅读:
display:flex详解
快看看你的手机有没有:谷歌Android全面封杀此类软件!
Nexus桌面插件
【分治算法】【Python实现】二分搜索
CentOS7虚拟机部署Part1
BIOS Boot Flow 之SEC
OPEN数据 | 新库上线 | CnOpenDataA股上市公司社会责任报告数据
《痞子衡嵌入式半月刊》 第 52 期
IDEA2022.1创建Spring boot + Mybatis + Web 项目
dble安装zk及配置mysql主从模式,在已有mysql存在数据升级mysql配置
- 原文地址:https://blog.csdn.net/weixin_45974176/article/details/127672293