-
【每日一读】Deep Variational Network Embedding in Wasserstein Space

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)论文简介
原文链接:https://dl.acm.org/doi/10.1145/3219819.3220052
会议:KDD '18: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (CCF A类)
年度:2018年7月19日(发表日期)
ABSTRACT
网络嵌入,旨在将网络嵌入到低维向量空间中,同时保留网络的固有结构特性,最近引起了相当多的关注。
大多数现有的嵌入方法将节点作为点向量嵌入到低维连续空间中。这样,边缘的形成是确定性的,仅由节点的位置决定。然而,现实世界网络的形成和演化充满了不确定性,这使得这些方法并不是最优的。
为了解决这个问题,我们在本文中提出了一种新的嵌入 Wasserstein 空间 (DVNE) 的深度变分网络。该方法学习了 Wasserstein 空间中的高斯分布作为每个节点的潜在表示,可以同时保留网络结构和对节点的不确定性进行建模。具体来说,我们使用 2-Wasserstein 距离作为分布之间的相似性度量,这可以很好地保持网络中的传递性和线性计算成本。此外,我们的方法通过深度变分模型暗示了均值和方差的数学相关性,可以很好地通过均值向量捕捉节点的位置,通过方差捕捉节点的不确定性。
此外,我们的方法通过保留网络中的一阶和二阶邻近度来捕获本地和全局网络结构。我们的实验结果表明,我们的方法可以有效地模拟网络中节点的不确定性,并且与最先进的方法相比,在链路预测和多标签分类等实际应用中显示出显着的收益。
1 INTRODUCTION
网络嵌入在过去几年中引起了相当多的研究关注。基本思想是将网络嵌入到低维向量空间中,以保留网络结构。许多网络嵌入方法被证明在各种应用中都是有效的,例如链接预测 [42, 44]、分类 [8, 26] 和聚类 [35, 46]。然而,大多数现有的网络嵌入方法通过低维向量空间中的单个点来表示每个节点。这样整个网络结构的形成是确定性的。
实际上,现实世界的网络比我们想象的要复杂得多。网络的形成和演化充满了不确定性。例如,对于度数较低的节点,它们包含的信息较少,因此它们的表示比其他节点具有更多的不确定性。对于跨多个社区的节点,其相邻节点之间可能存在的矛盾也可能更大,从而导致不确定性。此外,在社交网络中,人类行为是多方面的,这也使得边缘的生成不确定[47]。对于所有这些情况,如果不考虑网络的不确定性,学习的嵌入在网络分析和推理任务中的效率会降低。
高斯分布天生就代表了不确定性[43]。因此,有希望通过高斯分布(即均值和方差)来表示节点,而不是通过点向量来包含不确定性。受此启发,为了使用高斯分布对每个节点的不确定性进行建模,网络嵌入方法需要满足一些基本要求。
- 传递性:嵌入空间应该是一个度量空间,以保持网络中的传递性。传递性是网络中非常重要的属性,尤其是在社交网络中[25]。例如,我朋友的朋友比一些随机选择的用户更有可能成为我的朋友。此外,传递性衡量了网络中三角形的密度,这在计算聚类系数[7]中起着重要作用。如果度量空间满足三角不等式,则可以很好地保留网络中的传递性。
- 不确定性:通过使用高斯分布来表示节点,均值和方差应该保留不同的属性,以使这些表示具有信息性。具体来说,均值向量应反映节点的位置,方差项应包含节点的不确定性。这样,基于分布的表示可以在支持网络应用的同时保留不确定性。
- 结构邻近性:网络结构,尤其是高阶邻近性,应以有效和高效的方式保存。高阶接近度对于捕获网络结构至关重要,这已被证明在许多实际应用中很有用[36]。
最近,一些工作尝试使用高斯分布来表示网络嵌入的节点 [3, 17, 24] 以整合不确定性。然而,这些方法使用 Kullback-Leibler(缩写为 KL)散度 [28] 来衡量分布之间的相似性。然而,KL散度是不对称的,不满足三角不等式。因此,它不能很好地保持网络中邻近性的传递性,尤其是在无向网络中。此外,这些方法将方差项视为均值向量的附加维度,并使用相似性度量来约束它们的学习。这样,它们并不能反映模型中方差项和均值向量之间的内在关系。最后,除了 Graph2Gauss [3] 之外,这些作品中很少有保留网络嵌入中的高阶接近性。但是 Graph2Gauss 需要计算任意两个节点之间的最短路径,这在大规模网络中是无法承受的。
为了解决这些问题,我们在本文中提出了一种新颖的深度变分网络嵌入 Wasserstein 空间方法,命名为 DVNE。所提出的方法通过深度变分模型为 Wasserstein 空间中的每个节点学习高斯嵌入。具体来说,我们使用 2-Wasserstein 距离来测量分布之间的相似性,即节点的嵌入。
2-Wasserstein 距离是一个真正的度量,能够保持嵌入空间中的传递性。通过这种方式,所提出的深度模型能够同时保持传递性并以线性时间复杂度对节点不确定性进行建模。同时,我们使用深度变分模型来最小化模型分布和数据分布之间的 Wasserstein 距离,从而可以提取均值向量和方差项之间的内在关系。此外,我们的方法有效地保留了网络中节点的一阶和二阶邻近性,使学习的节点表示能够反映局部和全局网络结构[44]。
我们方法的主要贡献总结如下
- 我们提出了DVNE,一种在Wasserstein空间中学习高斯嵌入的新方法,可以很好地保留网络中的传递性并反映节点的不确定性。
- 我们通过深度变分模型暗示均值向量和方差项的数学相关性,其中均值向量表示节点的位置,方差项表示节点的不确定性。
- 我们有效地保留了节点之间的一阶和二阶接近度,因此学习的表示捕获了局部和全局网络结构。
- 我们全面评估了 DVNE 在各种应用中的几个现实世界网络上的有效性。
2 RELATED WORK
由于网络数据的普及,近年来网络嵌入越来越受到关注。
我们简要回顾了一些网络嵌入方法,读者可以参考[13]进行全面调查。
- Deepwalk [37] 首先使用语言建模技术通过截断随机游走来学习网络的潜在表示。
- LINE [39] 将网络嵌入到低维空间中,其中保留了节点之间的一阶和二阶接近度。
- Node2vec [22] 学习节点到低维特征空间的映射,最大限度地保留节点的网络邻域的可能性。
- HOPE [36] 提出了一种高阶邻近保留嵌入方法
此外,还研究了网络嵌入的深度学习方法
- SDNE [44] 首先考虑了网络嵌入中的高非线性,并提出了一种深度自动编码器来保留一阶和二阶近似
- 图变分自动编码器 (GAE) [27] 使用变分自动编码器 (VAE) [16] 以无监督方式学习节点嵌入。
所有上述方法都为每个节点学习一个点向量作为它的嵌入
然而,正如我们之前所说,这些方法在建模不确定性方面存在局限性,这是网络嵌入需要考虑的关键属性。
然后一些后续工作开始考虑不确定性问题
- 受 [43] 的启发,它学习高斯词嵌入来模拟不确定性,KG2E [24] 学习知识图谱的高斯嵌入。
- HCGE [17] 类似地学习异构图的高斯嵌入。和 Aleksandar 等人。
- [3] 提出了一个深度模型来学习属性网络上的高斯嵌入。
所有这些方法都使用 KL 散度或其变体 JensenShannon 散度 [19] 作为分布之间的相似性度量。然而,KL 散度和 JensenShannon 散度都不是真正的度量标准。这些度量不满足三角不等式。这样,这些方法就不能保持传递性来获得网络的有效表示。此外,这些方法将方差项视为额外维度,然后使用相似性度量来约束它们的学习。这样,很难捕捉均值和方差项之间的内在关系。
3 NOTATIONS AND PROBLEM DEFINITION
在本节中,我们总结了本文中使用的符号并给出了问题的表述。
3.1 Notations
我们首先总结本文中使用的符号。网络定义为 G = {V, E},其中 V = {v1, v2, …, vN } 表示一组节点,N 是节点的数量。 E 是节点之间的边集,M = |E|是边的数量。在本文中,我们主要考虑无向网络。令 Nbrsi ={vj |(vi , vj ) ∈ E} 表示节点 vi 的邻居集合。设P ∈RN ×N 为转移矩阵,其中P(i, : ) 和P(:, j) 分别表示其第i 行和第j 列,P(i, j) 是第i 行和第j 列的元素。如果从 vi 到 vj 有一条边并且节点 vi 的度数是 di ,那么我们将 P(i, j) 设置为 1di ,否则我们将 P(i, j) 标记为零。我们将 hi = N (μi , Σi ) 定义为节点 vi 的低维高斯分布嵌入,其中 μi ∈ RL , Σi ∈ RL×L 。 L 是嵌入维度,满足 L ≪ N 。在本文中,我们关注对角协方差矩阵。
3.2 Problem Definition
在本文中,我们专注于保留一阶和二阶邻近度的网络嵌入问题。
定义 3.1。 (一阶邻近度) 一阶邻近度描述节点之间的成对邻近度。对于任何一对节点,如果 P(i, j) > 0,则 vi 和 vj 之间存在正的一阶接近度。否则,vi 和 vj 之间的一阶接近度为 0。
一阶接近意味着现实世界网络中的两个节点如果通过观察到的边缘链接起来是相似的。例如,如果两个用户在社交网络上建立了他们之间的关系,他们可能有共同的兴趣。然而,现实世界的网络通常非常稀疏,以至于我们只能观察到非常有限数量的链接。仅捕获一阶接近度是不够的,因此我们引入二阶接近度来捕获全局网络结构。
定义 3.2。 (二阶邻近度) 一对节点之间的二阶邻近度表示它们的邻域网络结构之间的相似性。那么 vi 和 vj 之间的二阶接近度由 Nbrsi 和 Nbrsj 之间的相似性决定。如果没有节点与 vi 和 vj 链接,则 vi 和 vj 之间的二阶接近度为 0。
直观地说,二阶邻近度假设如果两个节点共享共同的邻居,它们往往是相似的。二阶接近度已被证明是定义一对节点相似性的一个很好的度量,即使它们之间没有边[31]。此外,二阶邻近已被证明能够缓解一阶邻近的稀疏问题,并更好地保持网络的全局结构[39]。
通过一阶和二阶接近度,我们将网络嵌入问题定义如下:
定义 3.3。 (基于高斯的网络嵌入)给定网络 G = {V, E},我们旨在将每个节点 vi 表示为低维高斯分布 hi = N (μi , Σi ),其中 μi 捕获节点在嵌入中的位置空间和 Σi 研究节点的不确定性。同时,潜在表示旨在保持节点之间的一阶接近度和二阶接近度,以保持网络结构。
4 DEEP VARIATIONAL NETWORK EMBEDDING
4.1 Framework
在本文中,我们提出了一种新的模型来执行网络嵌入,即 DVNE,其框架如图 1 所示。基本上,我们提出了一种深度架构,它由多个非线性映射函数组成,将输入数据映射到 Wasserstein 空间保留节点的不确定性并捕获网络结构。
具体来说,我们首先在 Wasserstein 嵌入空间上使用基于排名的损失函数,旨在使具有相似边缘和不相似边缘的节点。以这种方式,一阶接近度得以保留。此外,我们使用深度变分模型通过重建每个节点的邻域结构来保持二阶接近度。同时,整个深度变分模型通过采样过程明确地暗示了均值向量和方差项的数学相关性。通过这种方式,均值向量找到了节点的近似位置,方差项捕获了不确定性。在接下来的章节中,我们将详细介绍如何实现深度模型。
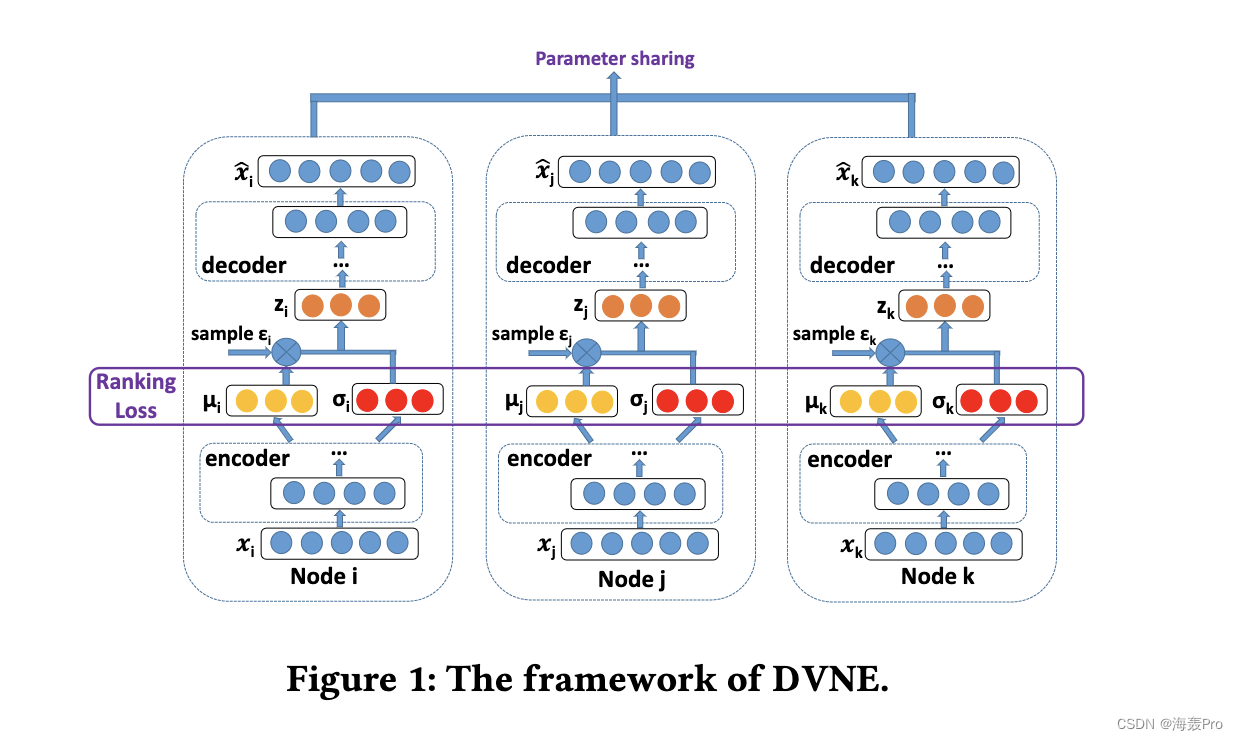
4.2 Similarity Measure
为了支持网络应用,我们需要在两个节点的潜在表示之间定义一个合适的相似性度量。由于我们使用分布来表示我们的潜在表示以包含不确定性,因此相似性度量应该能够测量分布之间的相似性。
此外,由于传递性是网络的一个重要属性,相似性度量应该同时保持节点之间的传递性。
通过广泛的研究,我们发现 Wasserstein 距离能够衡量两个分布之间的相似性,同时满足三角不等式 [9],这保证了它能够保持节点之间相似性的传递性。
两个概率测量 μ 和 ν 之间的 pt h Wasserstein 距离定义为:

其中 E[Z ] 表示随机变量 Z 的期望值,下确界取自随机变量 X 和 Y 的所有联合分布,分别具有边际 μ 和 ν。此外,当 p ≥ 1 时,第 p 个 Wasserstein 距离保留度量 [1] 的所有属性,包括对称性和三角不等式 [6]。通过这种方式,Wasserstein 距离适合作为节点潜在表示之间的相似性度量,特别是对于无向网络。
但是一般形式的 Wasserstein 距离的计算受到计算量大的限制,这对网络应用提出了很大的挑战。
为了降低计算成本,在我们的例子中,由于我们使用高斯分布来表示节点的潜在表示,因此第 2 h Wasserstein 距离(缩写为 W2)具有封闭形式的解决方案,以加快计算过程。 W2 距离也被广泛应用于计算机视觉 [4, 11]、计算机图形学 [5, 15] 或机器学习 [12, 14]。
更具体地说,我们有以下公式来计算两个高斯分布之间的 W2distance [20]:
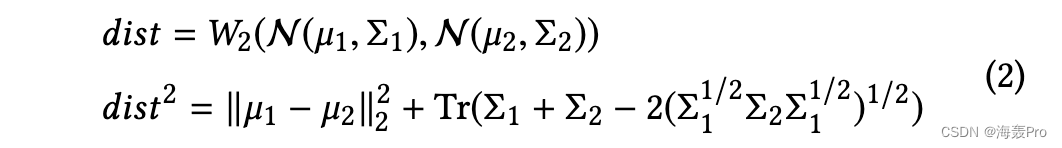
在本文中,我们关注对角协方差矩阵1,因此Σ1Σ2 = Σ2Σ1。那么公式(2)可以简化为: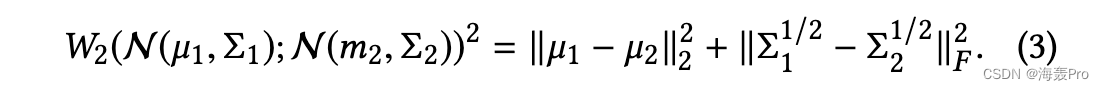
根据上式,计算两个节点的潜在表示之间的 W2 距离的时间复杂度与嵌入维度 L 成线性关系。因此,我们选择 W2distance 作为相似度度量,计算成本不再构成限制。
4.3 Loss Functions
我们对 DVNE 的整体损失函数由两部分组成,基于排名的损失来保持一阶接近度和重建损失来保持二阶接近度。
首先,我们考虑如何保持一阶邻近度。直观地说,我们希望所有与 vi 链接的节点都更接近 vi w.r.t。与与 vi 没有边的节点相比,它们的嵌入。更具体地说,我们提出以下成对约束来保持一阶邻近性:
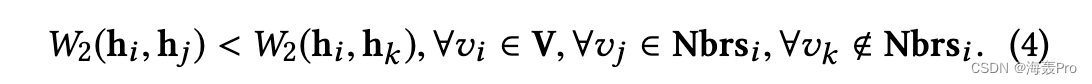
其中 hi 是节点 vi 的潜在表示,Nbrsi 是节点 vi 的邻居集。 W2距离越小,节点之间的相似度就越大。然后我们使用基于能量的学习方法 [29] 来合并上述等式中定义的所有成对约束。在数学上,将 Ei j = W2(hi , hj ) 表示为两个节点之间的能量,我们将目标函数表示如下:
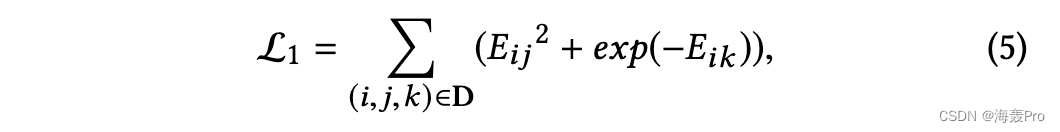
其中 D 是方程式中给出的所有有效三元组的集合。 (4) 。上述目标函数通过pairs的能量来惩罚排序错误,使得正例的能量低于负例的能量。等效地,它会使正例之间的相似度大于负例之间的相似度,从而有助于保持一阶接近度。
对于二阶接近度,我们使用转换矩阵 P 作为输入特征,并提出 Wasserstein Auto-Encoders (WAE) [41] 的变体作为模型来保留邻域结构。 WAE是一个深度变分模型,它可以通过采样过程暗示均值向量和方差项的数学相关性。原始 WAE 的目标由两个项组成,即重建成本和正则化项。重建成本旨在捕获输入的信息。正则化器鼓励编码的训练分布与先验分布相匹配。对于我们的问题,P(i, : ) 显示了节点 vi 的邻域结构,因此我们使用 P(i, : ) 作为节点 vi 的 WAE 的输入特征,并对其进行重构以保留其邻域结构。对于正则化项,很难定义网络中每个节点的先验分布。因此,我们只关注重建成本以保留邻域结构。
令 PX 表示数据分布,PG 表示编码训练分布。重建成本可以表示为:
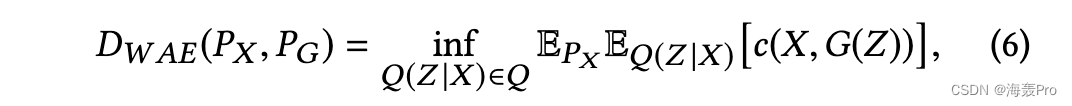
其中 Q 是编码器,G 是解码器,X ∼ PX 和 Z ∼Q(Z |X )。它旨在最小化 PX 和 PG 之间的 Wasserstein 距离根据[41],当使用 c(x, y) = ∥x − y∥2 2 时,上述损失函数(6)最小化了 PX 和 PG 之间的 W2 距离,因此 PG 捕获了 Wasserstein 中输入数据的信息空间。
考虑到转换矩阵 P 的稀疏性,我们专注于 P 中的非零元素以加速我们的模型。因此,我们提出如下损失函数以保持二阶接近度:
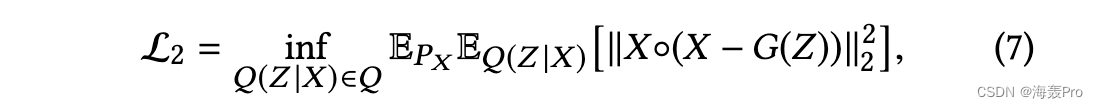
其中 ◦ 表示逐元素乘法
在我们的模型中,我们使用转换矩阵 P 作为输入特征 X。重建过程将使具有相似邻域的节点具有相似的潜在表示。因此,保留了节点之间的二阶接近度。
为了同时保持网络的一阶接近度和二阶接近度,我们通过结合方程来共同最小化损失函数。 (5) 和等式。 (7):
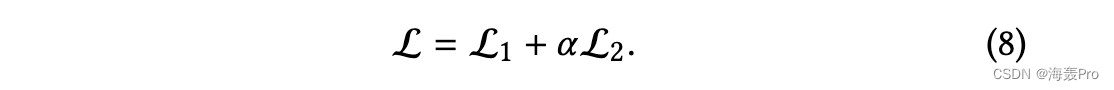
4.4 Optimization
对于大图,优化目标函数 (5) 的计算量很大,需要计算所有有效的三元组 inD。因此,我们均匀地从 D 中采样三元组,在等式中用 E(i, j,k )∼D 替换 Í(i, j,k )∈D。 (5) 。具体来说,对于每次迭代,我们从 D 中采样 M 个三元组来计算梯度的估计值。
考虑目标函数 (7) ,我们需要来自Q(Z |X ) 的样本 Z,这是一个非连续操作,没有梯度。在这种情况下,深度模型很难优化损失函数。为了解决这个问题,受变分自动编码器 (VAE) [16] 的启发,我们可以使用“重新参数化技巧”来优化上述目标方程。在数学上,我们首先对 ε ∼ N (0, I) 进行采样,然后计算 Z = μ(X ) + Σ1/2(X ) ∗ ε。给定一个固定的 X 和 ε,目标函数 (7) 在编码器 Q 和解码器 G 的参数上是确定性和连续的。这样,整个模型在执行反向传播时可以获得梯度,因此我们可以使用随机梯度下降来优化模型。
4.5 Implementation Details
对于本文中的所有实验,我们分别使用了具有单个隐藏层大小 S = 512 的编码器和解码器。更具体地说,为了获得节点 vi 的嵌入,我们有
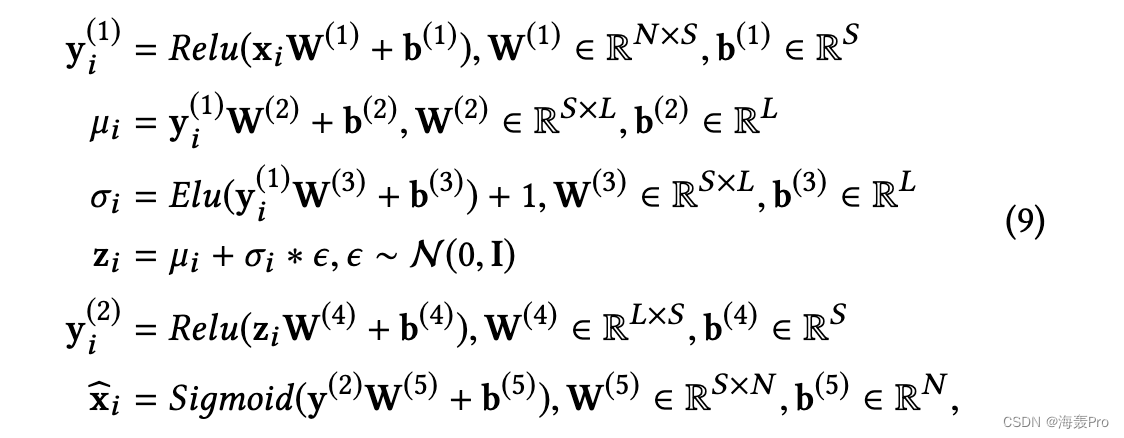
其中 xi 是 P(i, 😃,Relu [34] 和 Elu [10] 是整流线性单元和指数线性单元。我们使用 elu() + 1 来保证 σii 是正的。因为 xi 的取值范围在 [0, 1] 之间,所以我们使用 sigmoid 函数作为最后一个隐藏层的输出函数。
4.6 Complexity analysis
算法 1 列出了我们方法的过程。在训练过程中,计算梯度和更新参数的时间复杂度为 O(T × M × (dave S + SL + L)),其中 M 为边数,dave 为所有节点的平均度数,L是嵌入向量的维度,S 是编码器和解码器的隐藏层大小,T 是迭代次数。由于我们只重构 xi 中的非零元素,因此第一个和最后一个隐藏层的计算复杂度为 O(dave S)。其他隐藏层的计算复杂度为 O(SL),计算分布之间的 W2 距离需要 O(L)。在实践中,我们发现收敛需要少量迭代 T(所有所示实验的 T ≤ 50)。
5 EXPERIMENT

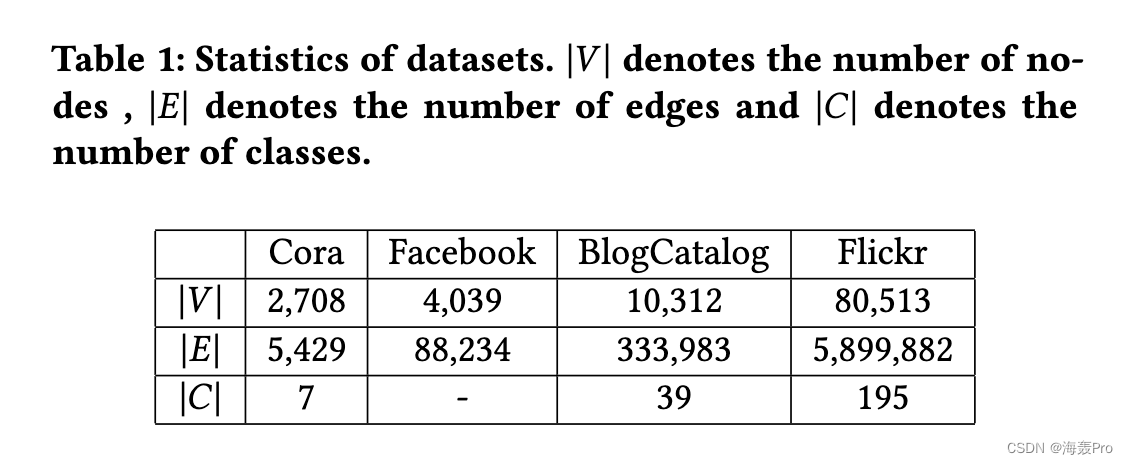
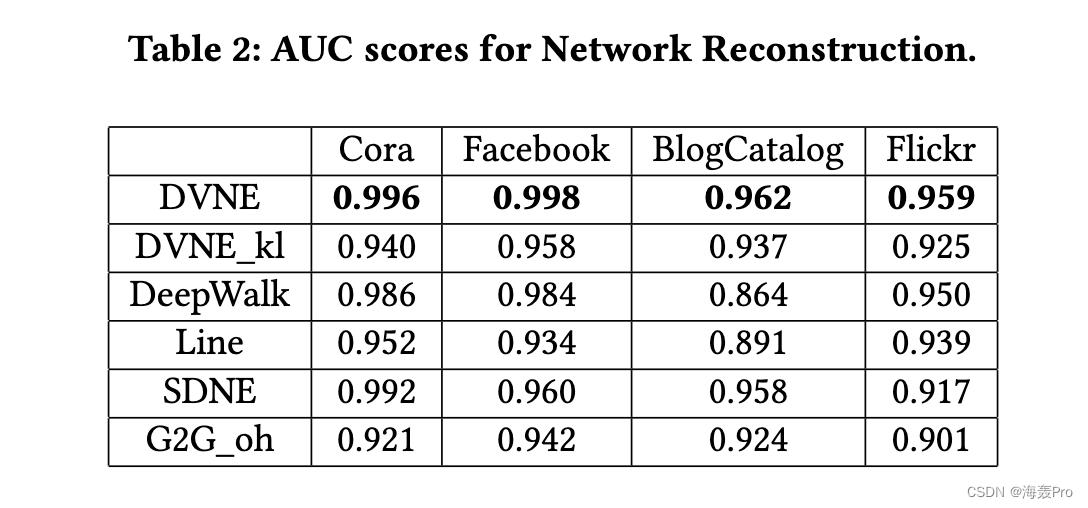
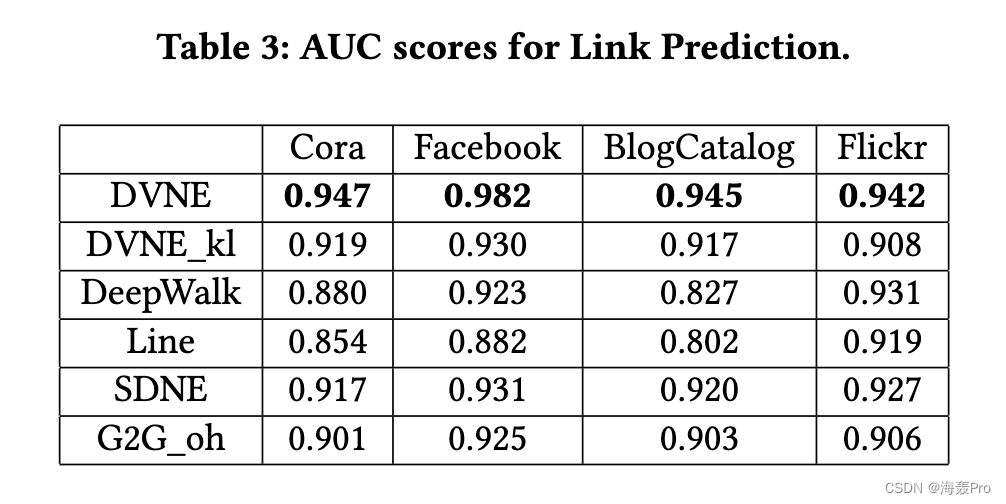

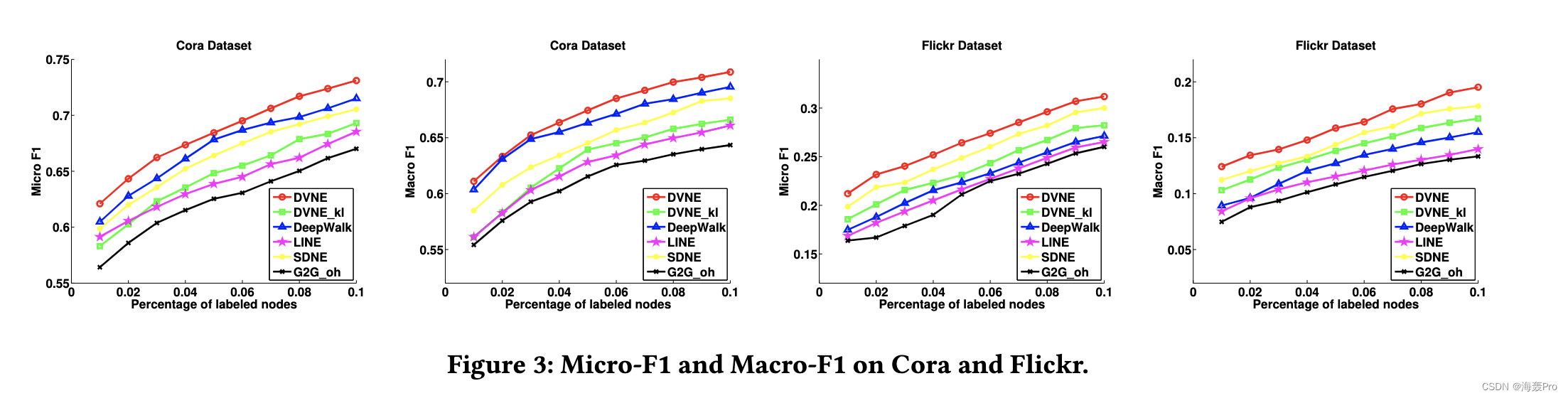


6 CONCLUSIONS
在本文中,我们提出了一种通过深度变分模型学习高斯嵌入的方法,即 DVNE,它可以对节点的不确定性进行建模。
这是第一个将网络中的节点表示为 Wasserstein 空间中的高斯分布的无监督方法。该方法保留节点之间的一阶接近度和二阶接近度,以捕获局部和全局网络结构。此外,DVNE 使用 2-Wasserstein 距离作为相似性度量,以更好地保持网络中具有线性时间复杂度的传递性。
实证研究证明了我们提出的方法的优越性。我们未来的方向是为每个节点找到一个好的高斯先验,以更好地捕捉网络结构并模拟节点的不确定性。
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

-
相关阅读:
CSS基本讲解与使用(详解)
Ribbon 客户端负载均衡
AnimatedList 实现动态列表
mysql binlog日志详解及主从复制原理
护理教育学重点
PLC项目调试常见的8种错误类型
strerror函数
基于DotNetty实现自动发布 - 自动检测代码变化
Programming Languages PartC Week2学习笔记——OOP(面向对象) vs FD(函数式)
gcc优化内存之 __attribute__((packed))
- 原文地址:https://blog.csdn.net/weixin_44225182/article/details/127664698