-
多头注意力机制的计算流、代码解析
多头注意力机制的计算流、代码解析 - 知乎
注意力机制的简化实现
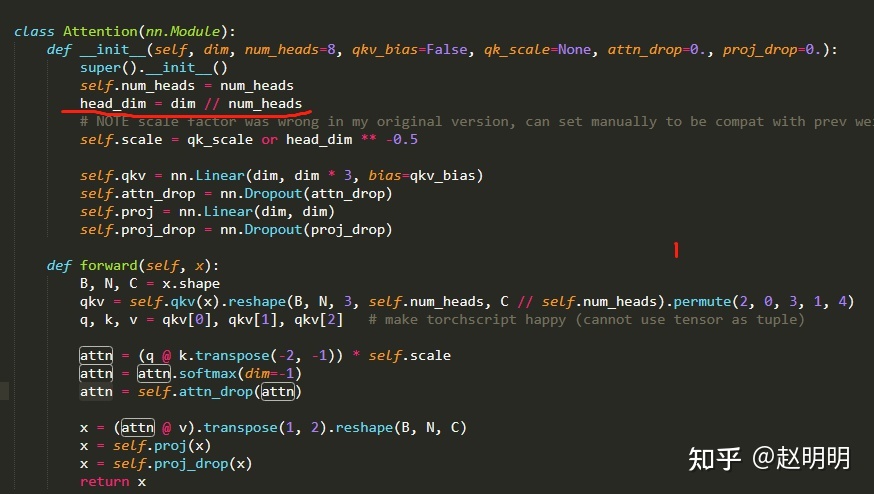
输入一个N*C的x给这个8头注意力机制,它输出一个N*C2的结果。那么我们写代码的时候,其实可以按照原理去写就行了。但是,完全按照原理去写代码的话,代码会比较繁琐,所以我们把原理中的一些矩阵乘法写在一起。用x经过一次矩阵乘法,就得到8个头的q,k,v
让N*C 的 x 乘一个C * [8*C1*3]的矩阵,得到N*[8*C1*3]的矩阵,
注意到,这个矩阵里有3个N*[8*C1]的矩阵,所以,
我们分出一个N*[8*C1]的矩阵作为8个头的q,并将其转化为8*N*C1的矩阵
我们分出一个N*[8*C1]的矩阵作为8个头的k,并将其转化为8*N*C1的矩阵
我们分出一个N*[8*C1]的矩阵作为8个头的v,并将其转化为8*N*C1的矩阵然后8个头的q,k,v 一起并行进行注意力机制的计算,得到拼接在一起的N*[8*C1]的矩阵
8*N*C1的矩阵的q与k的转置:8*C1*N 进行矩阵乘法,得到8*N*N的相关系数矩阵,
这个8*N*N的相关系数矩阵 除以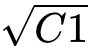
,再经过softmax得到归一化后的8*N*N的相关系数矩阵
用这个相关系数矩阵 和 v 进行矩阵的乘法,得到8*N*C1 的注意力输出结果,转化为N*[8*C1]这个N*[8*C1]的输出结果,经过[8*C1]*C2的全连接,得到N*C2的输出O。这里的关键是将8个头的并行计算方式了。这个并行计算主要是将原来的8个头中的矩阵乘法能合并的都合并了。比如计算8个头的Q,K,V时,每个头计算Q要用一次矩阵乘法,计算K要用一次矩阵乘法,计算V要用一次矩阵乘法。一个头3次,一共要进行24次矩阵乘法。合并后,一次矩阵乘法就可以得到8个头的Q,K,V了。还有就是
将8个头的Q 合并为N*[8*C1]的q
将8个头的K 合并为N*[8*C1]的k
将8个头的V 合并为N*[8*C1]的v
统一进行注意力运算,得到N*[8*C2]的输出
这就将原来要进行8次的注意力运算[图2],简化为1次了。
-
相关阅读:
飞腾主板显卡接eDP屏,显示花屏问题
【Vue】使用 transition 标签实现单元素组件的过渡和动画效果(1)
Qt优秀开源项目之十四:SortFilterProxyModel
CIFAR-10 数据转为图片-python
R | R包默认安装路径的查看及修改
Unity-镜头移动的相关逻辑
layui tree监控选中事件,同步选中和取消
论语第三篇-八侑
[附源码]Python计算机毕业设计Django的中点游戏分享网站
基于PHP+mysql的车辆保险理赔系统
- 原文地址:https://blog.csdn.net/zouxiaolv/article/details/127663952