-
【Transformers】第 5 章:微调文本分类的语言模型
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本章中,我们将学习如何为文本分类配置预训练模型,以及如何对其进行微调以适应任何文本分类下游任务,例如情感分析或多类分类。我们还将讨论如何通过实现来处理句子对和回归问题。我们将使用众所周知的数据集,例如 GLUE,以及我们自己的自定义数据集。然后,我们将利用 Trainer 课程,该课程处理培训和微调过程的复杂性。
首先,我们将学习如何使用 Trainer 类微调单句二元情感分类。然后,我们将在没有 Trainer 类的情况下使用本机 PyTorch 进行情感分类训练。在多类分类中,将考虑两个以上的类。我们将执行七个类别分类微调任务。最后,我们将训练一个文本回归模型来预测句子对的数值。
本章将涵盖以下主题:
- 文本分类简介
- 微调 BERT 模型以进行单句二进制分类
- 使用原生 PyTorch 训练分类模型
- 使用自定义数据集微调 BERT 以进行多类分类
- 为句子对回归微调 BERT
- 利用run_glue.py微调模型
技术要求
我们将使用 Jupyter Notebook 来运行我们的编码练习。为此,您将需要 Python 3.6+。确保安装了以下软件包:
- sklearn
- Transformers 4.0+
- datasets
文本分类简介
文本分类(也称为文本分类)是一种将文档(句子、Twitter 帖子、书籍章节、电子邮件内容等)映射到预定义列表(类)中的类别。在具有正标签和负标签的两个类的情况下,我们将此称为二元分类——更具体地说,是情绪分析。为了多于两个类,我们称之为多类分类,其中类是互斥或多标签分类,其中类不互斥,这意味着文档可以接收多个标签。例如,一篇新闻文章的内容可能同时与体育和政治有关。除了这个分类之外,我们可能希望在 [-1,1] 范围内对文档进行评分,或者在 [1-5] 范围内对它们进行排名。我们可以使用回归模型来解决这类问题,其中输出的类型是数字的,而不是分类的。
幸运的是,Transformer 架构使我们能够有效地解决这些问题。对于文档相似度或文本蕴涵等句子对任务,输入不是单个句子,而是两个句子,如下图所示。我们可以对两个句子在语义上的相似程度进行评分,或者预测它们在语义上是否相似。其他句子对任务是文本蕴涵,其中问题被定义为多类分类。在这里,GLUE 基准测试中使用了两个序列:蕴含/矛盾/中立:

图 5.1 – 文本分类方案
让我们通过微调预训练的 BERT 模型来开始我们的训练过程,以解决一个常见问题:情绪分析。
微调 BERT 模型以进行单句二进制分类
在本节中,我们将讨论如何使用流行的IMDb 情感数据集微调预训练的 BERT 模型以进行情感分析。使用 GPU 将加快我们的学习过程,但如果您没有这样的资源,您也可以使用 CPU 进行微调。让我们开始吧:
- 要了解并保存我们当前的设备,我们可以执行以下代码行:
- from torch import cuda
- device = 'cuda' if cuda.is_available() else 'cpu'
- 我们这里将使用DistilBertForSequenceClassification类,它继承自DistilBert类,顶部有一个特殊的序列分类头。我们可以利用这个分类头来训练分类模型,其中类数默认为2:
- from transformers import DistilBertTokenizerFast, DistilBertForSequenceClassification
- model_path= 'distilbert-base-uncased'
- tokenizer = DistilBertTokenizerFast.from_pre-trained(model_path)
- model = DistilBertForSequenceClassification.from_pre-trained(model_path, id2label={0:"NEG", 1:"POS"}, label2id={"NEG":0, "POS":1})
- 注意两个名为id2label和label2id的参数被传递给模型以使用在推理过程中。或者,我们可以实例化一个特定的配置对象并将其传递给模型,如下所示:
- config = AutoConfig.from_pre-trained(....)
- SequenceClassification.from_pre-trained(.... config=config)
- 现在,让我们选择一个流行的情感分类数据集,称为IMDB Dataset。原始数据集由两组数据组成:25,000 个用于训练的示例和 25 个用于测试的示例。我们将数据集拆分为测试和验证集。请注意,数据集前半部分的示例是正例,而后半部分的示例都是负例。我们可以按如下方式分发示例:
- from datasets import load_dataset
- imdb_train= load_dataset('imdb', split="train")
- imdb_test= load_dataset('imdb', split="test[:6250]+test[-6250:]")
- imdb_val= load_dataset('imdb', split="test[6250:12500]+test[-12500:-6250]")
- 让我们检查数据集的形状:
imdb_train.shape, imdb_test.shape, imdb_val.shape((25000, 2), (12500, 2), (12500, 2))
- 你可以采取一个的一小部分数据集基于您的计算资源。对于较小的部分,您应该运行以下代码来选择 4,000 个用于训练的示例、1,000 个用于测试和 1,000 个用于验证,如下所示:
- imdb_train= load_dataset('imdb', split="train[:2000]+train[-2000:]")
- imdb_test= load_dataset('imdb', split="test[:500]+test[-500:]")
- imdb_val= load_dataset('imdb', split="test[500:1000]+test[-1000:-500]")
- 现在,我们可以通过分词器模型传递这些数据集,让它们为训练做好准备:
- enc_train = imdb_train.map(lambda e: tokenizer( e['text'], padding=True, truncation=True), batched=True, batch_size=1000)
- enc_test = imdb_test.map(lambda e: tokenizer( e['text'], padding=True, truncation=True), batched=True, batch_size=1000)
- enc_val = imdb_val.map(lambda e: tokenizer( e['text'], padding=True, truncation=True), batched=True, batch_size=1000)
- 让我们看看训练集是什么样子的。分词器将注意力掩码和输入 ID 添加到数据集中,以便 BERT 模型可以处理:
- import pandas as pd
- pd.DataFrame(enc_train)
输出如下:

图 5.2 – 编码训练数据集
此时,数据集是准备好进行培训和测试。Trainer类(用于 TensorFlow的TFTrainer)和TrainingArguments类(用于 TensorFlow 的TFTrainingArguments)将帮助我们解决大部分训练复杂性。我们将在TrainingArguments类中定义我们的参数集,然后将其传递给Trainer对象。
让我们定义每个训练参数的作用:

表 1 – 不同训练参数定义表
- 有关更多信息,请查看TrainingArguments的 API 文档或在 Python 笔记本中执行以下代码:
TrainingArguments?
- 尽管 LSTM 等深度学习架构需要许多 epoch,有时甚至超过 50 个,用于基于转换器的微调,但由于迁移学习,我们通常会对 3 个 epoch 感到满意。大多数情况下,这个数字足以进行微调,因为预训练模型在预训练阶段学习了很多关于语言的知识,平均需要大约 50 个 epoch。为了确定正确的 epoch 数,我们需要监控训练和评估损失。我们将在第 11 章“注意力可视化和实验跟踪”中学习如何跟踪训练。
- 这已经足够了对于许多下游任务问题,我们将在这里看到。在训练过程中,每 200 步,我们的模型检查点将保存在./MyIMDBModel文件夹下:
- from transformers import TrainingArguments, Trainer
- training_args = TrainingArguments(
- output_dir='./MyIMDBModel',
- do_train=True,
- do_eval=True,
- num_train_epochs=3,
- per_device_train_batch_size=32,
- per_device_eval_batch_size=64,
- warmup_steps=100,
- weight_decay=0.01,
- logging_strategy='steps',
- logging_dir='./logs',
- logging_steps=200,
- evaluation_strategy= 'steps',
- fp16= cuda.is_available(),
- load_best_model_at_end=True
- )
- 在实例化Trainer对象之前,我们将定义compute_metrics()方法,它可以帮助我们监控训练的进度特定指标对于我们需要的任何东西,例如 Precision、RMSE、Pearson 相关性、BLEU 等。文本分类问题(如情感分类或多类分类)大多是评估使用微平均或宏观平均 F1。宏观平均方法对每个类别赋予相同的权重,而微观平均对每个文本或每个标记的分类决策赋予相同的权重。微平均等于模型正确决策的次数与已做出的决策总数的比率。另一方面,macro-averaging 方法计算每个类的 Precision、Recall 和 F1 的平均分数。对于我们的分类问题,宏观平均更便于评估,因为我们希望对每个标签赋予相同的权重,如下所示:
- from sklearn.metrics import accuracy_score, Precision_Recall_fscore_support
- def compute_metrics(pred):
- labels = pred.label_ids
- preds = pred.predictions.argmax(-1)
- Precision, Recall, f1, _ = \
- Precision_Recall_fscore_support(labels, preds, average='macro')
- acc = accuracy_score(labels, preds)
- return {
- 'Accuracy': acc,
- 'F1': f1,
- 'Precision': Precision,
- 'Recall': Recall
- }
- 我们几乎准备开始训练过程。现在,让我们实例化Trainer对象并启动它。Trainer类是一个非常强大且经过优化的工具,用于为 PyTorch 和 TensorFlow(TensorFlow 的 TFTrainer)组织复杂的训练和评估过程,这要归功于转换器库:
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=enc_train,
- eval_dataset=enc_val,
- compute_metrics= compute_metrics
- )
- 最后,我们可以开始训练过程:
results=trainer.train()前面的调用开始记录指标,我们将在第 11 章,注意力可视化和实验跟踪中更详细地讨论。整个 IMDb 数据集包括 25,000 个训练示例。批量大小为 32 时,我们有 25K/32 ~=782 步,以及 3 个 epoch 的 2,346 (782 x 3) 步,如下面的进度条所示:
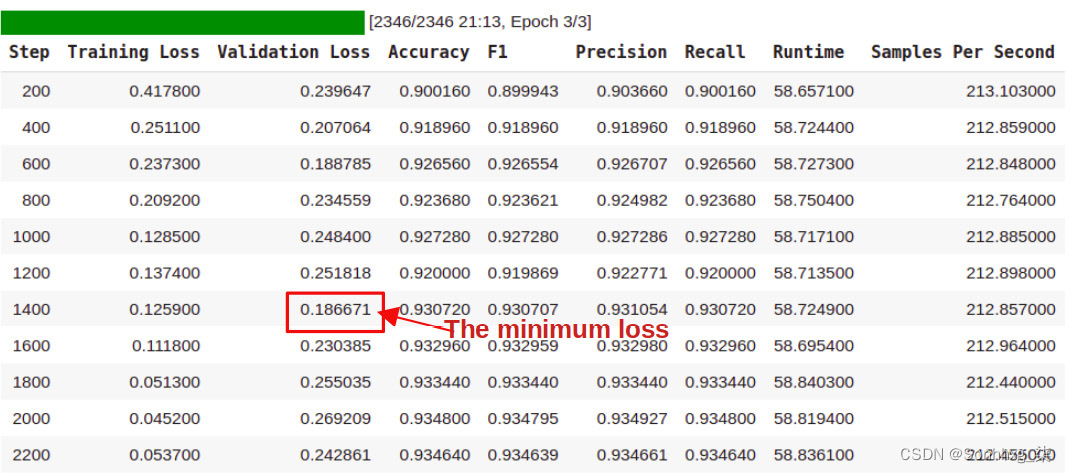
图 5.3 – Trainer 对象产生的输出
- 培训师对象最后保留验证损失最小的检查点。它选择步骤 1,400 的检查点,因为此步骤的验证损失最小。让我们评估三个(训练/测试/验证)数据集上的最佳检查点:
- q=[trainer.evaluate(eval_dataset=data) for data in [enc_train, enc_val, enc_test]]
- pd.DataFrame(q, index=["train","val","test"]).iloc[:,:5]
输出如下:
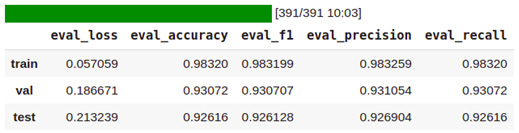
图 5.4 – 分类模型在训练/验证/测试数据集上的表现
- 做得好!我们已经成功完成了训练/测试阶段,并获得了 92.6 的准确率和 92.6 F1 的宏观平均值。监控您的训练过程更详细的,可以调用TensorBoard等高级工具。这些工具解析日志并使我们能够跟踪各种指标以进行全面分析。我们已经在./logs文件夹下记录了性能和其他指标。只需在我们的 Python notebook 中运行tensorboard函数就足够了,如下面的代码块所示(我们将在第 11 章,注意力可视化和实验跟踪中详细讨论 TensorBoard 和其他监控工具):
- %reload_ext tensorboard
- %tensorboard --logdir logs
- 现在,我们将使用该模型进行推理,以检查它是否正常工作。让我们定义一个预测函数来简化预测步骤,如下:
- def get_prediction(text):
- inputs = tokenizer(text, padding=True,truncation=True,
- max_length=250, return_tensors="pt").to(device)
- outputs = model(inputs["input_ids"].to(device),inputs["attention_mask"].to(device))
- probs = outputs[0].softmax(1)
- return probs, probs.argmax()
- 现在,运行模型进行推理:
- text = "I didn't like the movie it bored me "
- get_prediction(text)[1].item()
0
- 我们得到了什么这里是0,这是一个负数。我们已经定义了哪个 ID 指的是哪个标签。我们可以使用这个映射方案来获取标签。或者,我们可以简单地将所有这些无聊的步骤传递给我们已经熟悉的专用 API,即 Pipeline。在实例化它之前,让我们保存最好的模型以供进一步推断:
- model_save_path = "MyBestIMDBModel"
- trainer.save_model(model_save_path)
- tokenizer.save_pre-trained(model_save_path)
Pipeline API 是一种使用预训练模型进行推理的简单方法。我们从保存模型的位置加载模型并将其传递给 Pipeline API,由其完成其余工作。我们可以跳过这个保存步骤,而是直接将内存中的模型和标记器对象传递给 Pipeline API。如果你这样做,你会得到同样的结果。
- 如下代码所示,我们在进行二分类时需要指定Pipeline的task name参数为sentiment-analysis :
- from transformers import pipeline, DistilBertForSequenceClassification, DistilBertTokenizerFast
- model = DistilBertForSequenceClassification.from_pre-trained("MyBestIMDBModel")
- tokenizer= DistilBertTokenizerFast.from_pre-trained("MyBestIMDBModel")
- nlp= pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
- nlp("the movie was very impressive")
Out: [{'label': 'POS', 'score': 0.9621992707252502}]
nlp("the text of the picture was very poor")Out: [{'label': 'NEG', 'score': 0.9938313961029053}]
管道知道如何治疗输入并以某种方式了解哪个 ID 指的是哪个(POS或NEG)标签。它还产生类概率。
做得好!我们使用Trainer类微调了 IMDb 数据集的情绪预测模型。在下一节中,我们将使用原生 PyTorch 进行相同的二元分类训练。我们还将使用不同的数据集。
使用原生 PyTorch 训练分类模型
教练班是非常强大,我们感谢 HuggingFace 团队提供了如此有用的工具。但是,在本节中,我们将从头开始微调预训练模型,以了解幕后情况。让我们开始吧:
- 首先,让我们加载模型进行微调。我们将在这里选择DistilBERT,因为它是 BERT 的小型、快速且便宜的版本:
- from transformers import DistilBertForSequenceClassification
- model = DistilBertForSequenceClassification.from_pre-trained('distilbert-base-uncased')
- 要微调任何模型,我们需要将其置于训练模式,如下所示:
model.train() - 现在,我们必须加载分词器:
- from transformers import DistilBertTokenizerFast
- tokenizer = DistilBertTokenizerFast.from_pre-trained('bert-base-uncased')
- 由于Trainer类为我们组织了整个过程,因此在之前的 IMDb 情感分类练习中,我们没有处理优化和其他训练设置。现在我们需要实例化我们自己优化。在这里,我们必须选择AdamW,它是 Adam 算法的一种实现,但具有权重衰减修复。最近,研究表明,与使用 Adam 训练的模型相比, AdamW产生了更好的训练损失和验证损失。因此,它是许多变压器训练过程中广泛使用的优化器:
- from transformers import AdamW
- optimizer = AdamW(model.parameters(), lr=1e-3)
要从头开始设计微调过程,我们必须了解如何实现单步向前和反向传播。我们可以通过transformer层传递一个batch,得到输出,即称为前向传播。然后,我们必须使用输出和真实标签计算损失,并根据损失更新模型权重。这是称为反向传播。
以下代码在一个批次中接收与标签关联的三个句子并执行前向传播。最后,模型自动计算损失:
- import torch
- texts= ["this is a good example","this is a bad example","this is a good one"]
- labels= [1,0,1]
- labels = torch.tensor(labels).unsqueeze(0)
- encoding = tokenizer(texts, return_tensors='pt', padding=True,
- truncation=True, max_length=512)
- input_ids = encoding['input_ids']
- attention_mask = encoding['attention_mask']
- outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
- loss = outputs.loss
- loss.backward()
- optimizer.step()
- Outputs
SequenceClassifierOutput(
[('loss', tensor(0.7178, grad_fn=
)), ('logits',tensor([[ 0.0664, -0.0161],[ 0.0738, 0.0665], [ 0.0690, -0.0010]], grad_fn= ))]) 该模型采用由分词器生成的input_ids和attention_mask,并使用地面实况标签计算损失。正如我们所见,输出由loss和logits 组成。现在,loss.backward()通过使用输入和标签评估模型来计算张量的梯度。optimizer.step()执行单个优化步骤并使用计算的梯度更新权重,这称为反向传播。当我们很快将所有这些行放入一个循环中时,我们还将添加optimizer.zero_grad(),它会清除所有参数的梯度。这是对很重要在循环开始时调用它;否则,我们可能会累积多个步骤的梯度。第二输出的张量是logits。在深度学习的背景下,术语 logits(逻辑单元的缩写)是神经架构的最后一层,由实数形式的预测值组成。在分类的情况下,logits需要通过softmax函数转化为概率。否则,它们会被简单地归一化以进行回归。
- 如果我们想手动计算损失,我们一定不能将标签传递给模型。因此,该模型仅产生对数而不计算损失。在以下示例中,我们手动计算交叉熵损失:
- from torch.nn import functional
- labels = torch.tensor([1,0,1])
- outputs = model(input_ids, attention_mask=attention_mask)
- loss = functional.cross_entropy(outputs.logits, labels)
- loss.backward()
- optimizer.step()
- loss
Output: tensor(0.6101, grad_fn=
) - 有了这个,我们已经了解了批量输入是如何一步一步通过网络向前馈送的。现在,是时候设计一个循环遍历整个数据集在批量训练具有多个时期的模型。为此,我们将从设计Dataset类开始。它是torch.Dataset的子类,继承成员变量和函数,实现了__init__()和__getitem()__抽象函数:
- from torch.utils.data import Dataset
- class MyDataset(Dataset):
- def __init__(self, encodings, labels):
- self.encodings = encodings
- self.labels = labels
- def __getitem__(self, idx):
- item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
- item['labels'] = torch.tensor(self.labels[idx])
- return item
- def __len__(self):
- return len(self.labels)
- 让我们通过另一个名为的情感分析数据集来微调情感分析模型SST-2 数据集;即斯坦福情绪树库 v2 ( SST2 )。我们还将加载 SST-2 的相应指标进行评估,如下所示:
- import datasets
- from datasets import load_dataset
- sst2= load_dataset("glue","sst2")
- from datasets import load_metric
- metric = load_metric("glue", "sst2")
- 我们将相应地提取句子和标签:
- texts=sst2['train']['sentence']
- labels=sst2['train']['label']
- val_texts=sst2['validation']['sentence']
- val_labels=sst2['validation']['label']
- 现在,我们可以通过数据集通过标记器并实例化MyDataset对象以使 BERT 模型与它们一起工作:
- train_dataset= MyDataset(tokenizer(texts, truncation=True, padding=True), labels)
- val_dataset= MyDataset(tokenizer(val_texts, truncation=True, padding=True), val_labels)
- 让我们实例化一个Dataloader类,该类提供一个接口来按加载顺序遍历数据样本。这也有助于批处理和内存固定:
- from torch.utils.data import DataLoader
- train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
- val_loader = DataLoader(val_dataset, batch_size=16, shuffle=True)
- 以下行检测设备并正确定义AdamW优化器:
- from transformers import AdamW
- device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
- model.to(device)
- optimizer = AdamW(model.parameters(), lr=1e-3)
到目前为止,我们知道如何实施前向传播,这是我们处理一批示例的地方。在这里,批量数据通过神经网络向前馈送。在一个步骤中,从第一层到最后一层的每一层都由批处理数据根据激活函数进行处理,然后传递到后续层。为了在几个 epoch 中遍历整个数据集,我们设计了两个嵌套循环:外部循环用于 epoch,而内部循环用于每个批次的步骤。内部由两个块组成;一个用于训练,另一个用于评估每个 epoch。您可能已经注意到,我们在第一个训练循环中调用了 model.train(),当我们移动第二个评估块时,我们调用了 model.eval(). 这很重要,因为我们将模型置于训练和推理模式。
- 我们已经讨论过内部块。请注意,我们通过相应的度量对象来跟踪模型的性能:
- for epoch in range(3):
- model.train()
- for batch in train_loader:
- optimizer.zero_grad()
- input_ids = batch['input_ids'].to(device)
- attention_mask = batch['attention_mask'].to(device)
- labels = batch['labels'].to(device)
- outputs = \
- model(input_ids, attention_mask=attention_mask, labels=labels)
- loss = outputs[0]
- loss.backward()
- optimizer.step()
- model.eval()
- for batch in val_loader:
- input_ids = batch['input_ids'].to(device)
- attention_mask = batch['attention_mask'].to(device)
- labels = batch['labels'].to(device)
- outputs = \
- model(input_ids, attention_mask=attention_mask, labels=labels)
- predictions=outputs.logits.argmax(dim=-1)
- metric.add_batch(
- predictions=predictions,
- references=batch["labels"],
- )
- eval_metric = metric.compute()
- print(f"epoch {epoch}: {eval_metric}")
OUTPUT:
epoch 0: {'accuracy': 0.9048165137614679}
epoch 1: {'accuracy': 0.8944954128440367}
epoch 2: {'accuracy': 0.9094036697247706}
做得好!我们已经对模型进行了微调,并获得了大约 90.94 的准确度。其余的过程,例如保存、加载和推理,将与我们对Trainer类所做的类似。
有了这个,我们完成用二进制分类。在下一节中,我们将学习如何为英语以外的语言实现多类分类模型。
使用自定义数据集微调 BERT 以进行多类分类
在本节中,我们将微调土耳其 BERT,即BERTurk,以进行七级分类下游具有自定义数据集的任务。该数据集由土耳其报纸编译而成,由七个类别组成。我们将从获取数据集开始。或者,你可以在本书的 GitHub 存储库中找到它,或者从A Benchmark Data for Turkish Text Categorization | Kaggle获取它:
- 首先,运行以下代码以获取 Python 笔记本中的数据:
!wget https://raw.githubusercontent.com/savasy/TurkishTextClassification/master/TTC4900.csv - 首先加载数据:
- import pandas as pd
- data= pd.read_csv("TTC4900.csv")
- data=data.sample(frac=1.0, random_state=42)
- 让我们用id2label和label2id组织 ID 和标签,以使模型找出哪个 ID 指的是哪个标签。我们还将标签的数量NUM_LABELS传递给模型到指定细分类的大小BERT 模型顶部的头层:
- labels=["teknoloji","ekonomi","saglik","siyaset","kultur","spor","dunya"]
- NUM_LABELS= len(labels)
- id2label={i:l for i,l in enumerate(labels)}
- label2id={l:i for i,l in enumerate(labels)}
- data["labels"]=data.category.map(lambda x: label2id[x.strip()])
- data.head()
输出如下:

图 5.5 – 文本分类数据集 – TTC 4900
- 让我们使用 pandas 对象来计算和绘制类的数量:
data.category.value_counts().plot(kind='pie')如下图所示,数据集类已经相当分布:
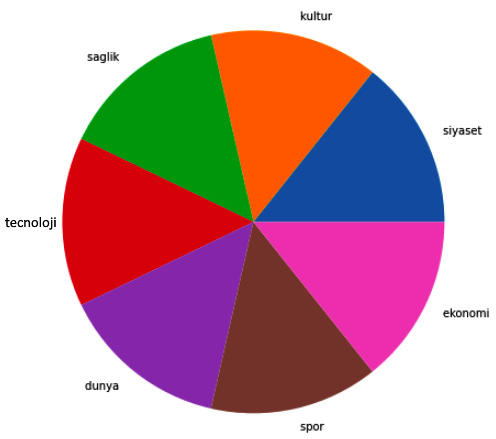
图 5.6 – 类别分布
- 以下执行实例化一个序列分类具有标签数量 ( 7 )、标签 ID 映射和土耳其 BERT 模型 ( dbmdz/bert-base-turkish- uncased) 的模型,即 BERTurk。要检查这一点,请执行以下操作:
model - 输出将是模型的摘要,并且太长,无法在此处显示。相反,让我们使用以下代码将注意力转移到最后一层:
(classifier): Linear(in_features=768, out_features=7, bias=True)
- 您可能已经注意到我们没有选择DistilBert ,因为没有针对土耳其语进行预训练的未加壳 DistilBert :
- from transformers import BertTokenizerFast
- tokenizer = BertTokenizerFast.from_pre-trained("dbmdz/bert-base-turkish-uncased", max_length=512)
- from transformers import BertForSequenceClassification
- model = BertForSequenceClassification.from_pre-trained("dbmdz/bert-base-turkish-uncased", num_labels=NUM_LABELS, id2label=id2label, label2id=label2id)
- model.to(device)
- 现在,让我们准备训练 (%50)、验证 (%25) 和测试 (%25) 数据集,如如下:
大小=数据.形状[0]
- SIZE= data.shape[0]
- ## sentences
- train_texts= list(data.text[:SIZE//2])
- val_texts= list(data.text[SIZE//2:(3*SIZE)//4 ])
- test_texts= list(data.text[(3*SIZE)//4:])
- ## labels
- train_labels= list(data.labels[:SIZE//2])
- val_labels= list(data.labels[SIZE//2:(3*SIZE)//4])
- test_labels= list(data.labels[(3*SIZE)//4:])
- ## check the size
- len(train_texts), len(val_texts), len(test_texts)
(2450, 1225, 1225)
- 以下代码对三个数据集的句子及其标记进行标记,并将它们转换为整数(input_ids),然后将其输入到 BERT 模型中:
- train_encodings = tokenizer(train_texts, truncation=True, padding=True)
- val_encodings = tokenizer(val_texts, truncation=True,padding=True)
- test_encodings = tokenizer(test_texts, truncation=True, padding=True)
- 我们有已经实施MyDataset类(请参见第 14 页)。类继承自通过覆盖__getitem__和__len__()方法来抽象Dataset类,这些方法预计将分别使用任何数据加载器返回数据集的项目和大小:
- train_dataset = MyDataset(train_encodings, train_labels)
- val_dataset = MyDataset(val_encodings, val_labels)
- test_dataset = MyDataset(test_encodings, test_labels)
- 我们将批量大小保持为16,因为我们有一个相对较小的数据集。请注意,TrainingArguments的其他参数与之前的情感分析实验几乎相同:
- from transformers import TrainingArguments, Trainer
- training_args = TrainingArguments(
- output_dir='./TTC4900Model',
- do_train=True,
- do_eval=True,
- num_train_epochs=3,
- per_device_train_batch_size=16,
- per_device_eval_batch_size=32,
- warmup_steps=100,
- weight_decay=0.01,
- logging_strategy='steps',
- logging_dir='./multi-class-logs',
- logging_steps=50,
- evaluation_strategy="steps",
- eval_steps=50,
- save_strategy="epoch",
- fp16=True,
- load_best_model_at_end=True
- )
- 情感分析和文本分类是相同的对象评估指标;即macro-averaging 宏平均F1、Precision 和Recall。因此,我们不再定义compute_metric()函数。下面是实例化Trainer对象的代码:
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset,
- eval_dataset=val_dataset,
- compute_metrics= compute_metrics
- )
- 最后,让我们开始训练过程:
trainer.train()输出如下:

图 5.7 – 用于文本分类的 Trainer 类的输出
- 检查训练好的模型,我们必须评估三个数据集拆分上的微调模型,如下所示。我们最好的模型在第 300 步进行微调,损失为 0.28012:
- q=[trainer.evaluate(eval_dataset=data) for data in [train_dataset, val_dataset, test_dataset]]
- pd.DataFrame(q, index=["train","val","test"]).iloc[:,:5]
输出如下:

图 5.8 – 文本分类模型在训练/验证/测试数据集上的表现
分类准确率在 92.6 左右,而 F1 宏观平均在 92.5 左右。在文献中,许多方法已经在这个土耳其基准数据集上进行了测试。他们大多遵循 TF-IDF 和线性分类器、word2vec 嵌入或基于 LSTM 的分类器,最多只能得到大约 90.0 F1。与这些方法相比,除了 Transformer 之外,微调的 BERT 模型优于它们。
- 与任何其他实验,我们可以追踪通过 TensorBoard 进行的实验:
- %load_ext tensorboard
- %tensorboard --logdir multi-class-logs/
- 让我们设计一个函数来运行模型进行推理。如果你想看到一个真实的标签而不是一个 ID,你可以使用我们模型的config对象,如下面的predict函数所示:
- def predict(text):
- inputs = tokenizer(text, padding=True, truncation=True, max_length=512, return_tensors="pt").to("cuda")
- outputs = model(**inputs)
- probs = outputs[0].softmax(1)
- return probs, probs.argmax(),model.config.id2label[probs.argmax().item()]
- 现在,我们准备调用预测函数进行文本分类推理。以下代码对有关足球队的句子进行分类:
- text = "Fenerbahçeli futbolcular kısa paslarla hazırlık çalışması yaptılar"
- predict(text)
(tensor([[5.6183e-04, 4.9046e-04, 5.1385e-04, 9.9414e-04, 3.4417e-04, 9.9669e-01, 4.0617e-04]], device='cuda:0', grad_fn=
), tensor(5, device='cuda:0'), 'spor') - 正如我们所见,正确建模将句子预测为运动 ( spor )。现在,是时候拯救模型并使用from_pre-trained()函数重新加载它。这是代码:
- model_path = "turkish-text-classification-model"
- trainer.save_model(model_path)
- tokenizer.save_pre-trained(model_path)
- 现在,我们可以在管道类的帮助下重新加载保存的模型并运行推理:
- model_path = "turkish-text-classification-model"
- from transformers import pipeline, BertForSequenceClassification, BertTokenizerFast
- model = BertForSequenceClassification.from_pre-trained(model_path)
- tokenizer= BertTokenizerFast.from_pre-trained(model_path)
- nlp= pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
- 您可能已经注意到任务的名称是情感分析。这个术语可能会令人困惑,但这个参数实际上会在最后返回TextClassificationPipeline。让我们运行管道:
nlp("Sinemada hangi filmler oynuyor bugün")[{'label': 'kultur', 'score': 0.9930670261383057}]
nlp("Dolar ve Euro bugün yurtiçi piyasalarda yükseldi")[{'label': 'ekonomi', 'score': 0.9927696585655212}]
nlp("Bayern Münih ile Barcelona bugün karşı karşıya[{'label': 'track' , 'score': 0.9975664019584656}]
那是我们的榜样!它已经成功地预测了。
到目前为止,我们有实施的两个单句任务;也就是情绪分析和多类分类。在下一节中,我们将学习如何处理句子对输入以及如何使用 BERT 设计回归模型。
为句子对回归微调 BERT 模型
回归模型是被认为是为了分类,但最后一层只包含一个单元。这不是由 softmax 逻辑回归处理的,而是归一化的。要指定模型并将单单元头层放在顶部,我们可以直接将num_labels=1参数传递给BERT.from_pre-trained()方法,也可以通过Config对象传递此信息。最初,这需要从预训练模型的配置对象中复制,如下所示:
- from transformers import DistilBertConfig, DistilBertTokenizerFast, DistilBertForSequenceClassification
- model_path='distilbert-base-uncased'
- config = DistilBertConfig.from_pre-trained(model_path, num_labels=1)
- tokenizer = DistilBertTokenizerFast.from_pre-trained(model_path)
- model = DistilBertForSequenceClassification.from_pre-trained(model_path, config=config)
好吧,由于num_labels=1参数,我们的预训练模型有一个单单元头层。现在,我们已准备好使用我们的数据集微调模型。在这里,我们将使用语义文本相似性基准( STS-B ),它是从各种内容(例如新闻标题)中提取的句子对集合。每对都标注了从 1 到 5 的相似度分数。我们的任务是微调 BERT 模型以预测这些分数。我们将在遵循文献的同时使用 Pearson/Spearman 相关系数评估模型。让我们开始吧:
- 以下代码加载数据。原始数据被分成三份。但是,测试拆分没有标签,因此我们可以将验证数据分为两部分,如下所示:
- import datasets
- from datasets import load_dataset
- stsb_train= load_dataset('glue','stsb', split="train")
- stsb_validation = load_dataset('glue','stsb', split="validation")
- stsb_validation=stsb_validation.shuffle(seed=42)
- stsb_val= datasets.Dataset.from_dict(stsb_validation[:750])
- stsb_test= datasets.Dataset.from_dict(stsb_validation[750:])
- 让我们进行stsb_train培训通过用 pandas 包装数据来整理数据:
pd.DataFrame(stsb_train)以下是训练数据的样子:

图 5.9 – STS-B 训练数据集
- 运行以下代码检查三个集合的形状:
stsb_train.shape、stsb_val.shape、stsb_test.shape((5749, 4), (750, 4), (750, 4))
- 跑过以下代码标记数据集:
- enc_train = stsb_train.map(lambda e: tokenizer(e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000)
- enc_val = stsb_val.map(lambda e: tokenizer(e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000)
- enc_test = stsb_test.map(lambda e: tokenizer(e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000)
- 分词器将两个句子与[SEP]分隔符合并,并为句子对生成单个input_ids和attention_mask,如下所示:
pd.DataFrame(enc_train)输出如下:

图 5.10 – 编码训练数据集
与其他实验类似,我们遵循几乎TrainingArguments和Trainer类的方案相同。这是代码:
- from transformers import TrainingArguments, Trainer
- training_args = TrainingArguments(
- output_dir='./stsb-model',
- do_train=True,
- do_eval=True,
- num_train_epochs=3,
- per_device_train_batch_size=32,
- per_device_eval_batch_size=64,
- warmup_steps=100,
- weight_decay=0.01,
- logging_strategy='steps',
- logging_dir='./logs',
- logging_steps=50,
- evaluation_strategy="steps",
- save_strategy="epoch",
- fp16=True,
- load_best_model_at_end=True
- )
- 另一个重要的之间的区别当前的回归任务和之前的分类任务是compute_metrics的设计。在这里,我们的评估指标将基于皮尔逊相关系数和斯皮尔曼等级相关性共同的文献中提供的实践。我们还提供均方误差( MSE )、均方根误差( RMSE ) 和平均绝对误差( MAE ) 指标,这些指标常用,尤其是回归模型:
- import numpy as np
- from scipy.stats import pearsonr
- from scipy.stats import spearmanr
- def compute_metrics(pred):
- preds = np.squeeze(pred.predictions)
- return {"MSE": ((preds - pred.label_ids) ** 2).mean().item(),
- "RMSE": (np.sqrt (( (preds - pred.label_ids) ** 2).mean())).item(),
- "MAE": (np.abs(preds - pred.label_ids)).mean().item(),
- "Pearson" : pearsonr(preds,pred.label_ids)[0],
- "Spearman's Rank":spearmanr(preds,pred.label_ids)[0]
- }
- 现在,让我们实例化Trainer对象:
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=enc_train,
- eval_dataset=enc_val,
- compute_metrics=compute_metrics,
- tokenizer=tokenizer
- )
运行训练,如下所示:
train_result = trainer.train()输出如下:

图 5.11 – 文本回归的训练结果
- 最好的验证损失在步骤450计算为0.544973。让我们在该步骤评估最佳检查点模型,如下所示:
- q=[trainer.evaluate(eval_dataset=data) for data in [enc_train, enc_val, enc_test]]
- pd.DataFrame(q, index=["train","val","test"]).iloc[:,:5]
输出如下:
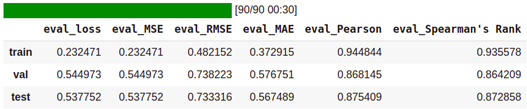
图 5.12 – 训练/验证/测试数据集的回归性能
Pearson 和 Spearman 相关分数在测试数据集上分别约为 87.54 和 87.28。我们没有获得 SoTA 结果,但我们确实获得了基于 GLUE Benchmark 排行榜的 STS-B 任务的可比较结果。请检查排行榜!
- 我们现在准备运行模型进行推理。让我们取以下两个具有相同含义的句子,并将它们传递给模型:
- s1,s2="A plane is taking off.","An air plane is taking off."
- encoding = tokenizer(s1,s2, return_tensors='pt', padding=True, truncation=True, max_length=512)
- input_ids = encoding['input_ids'].to(device)
- attention_mask = encoding['attention_mask'].to(device)
- outputs = model(input_ids, attention_mask=attention_mask)
- outputs.logits.item()
OUTPUT: 4.033723831176758
- 以下代码消耗否定句对,这意味着句子在语义上是不同的:
- s1,s2="The men are playing soccer.","A man is riding a motorcycle."
- encoding = tokenizer("hey how are you there","hey how are you", return_tensors='pt', padding=True, truncation=True, max_length=512)
- input_ids = encoding['input_ids'].to(device)
- attention_mask = encoding['attention_mask'].to(device)
- outputs = model(input_ids, attention_mask=attention_mask)
- outputs.logits.item()
OUTPUT: 2.3579328060150146
- 最后,我们将模型保存下来,如下:
- model_path = "sentence-pair-regression-model"
- trainer.save_model(model_path)
- tokenizer.save_pre-trained(model_path)
做得好!我们可以恭喜自己,因为我们成功完成了三个任务:情感分析、多类分类和句子对回归。
利用 run_glue.py 微调模型
到目前为止,我们设计了一个使用原生 PyTorch 和Trainer类从头开始微调架构。HuggingFace 社区还为 GLUE 基准测试和类似 GLUE 的分类下游任务提供了另一个强大的脚本run_glue.py 。该脚本可以为我们处理和组织整个培训/验证过程。如果你想做快速原型,你应该使用这个脚本。它可以微调 HuggingFace 集线器上的任何预训练模型。我们也可以用我们自己的任何格式的数据来提供它。
请转到以下链接访问脚本并了解更多信息:https ://github.com/huggingface/transformers/tree/master/examples 。
该脚本可以执行九种不同的 GLUE 任务。使用该脚本,我们可以完成迄今为止在Trainer类中所做的所有事情。任务名称可以是以下 GLUE 任务之一:cola、sst2、mrpc、stsb、qqp、mnli、qnli、rte或wnli。
这是微调模型的脚本方案:
- export TASK_NAME= "My-Task-Name"
- python run_glue.py \
- --model_name_or_path bert-base-cased \
- --task_name $TASK_NAME \
- --do_train \ --do_eval \
- --max_seq_length 128 \
- --per_device_train_batch_size 32 \
- --learning_rate 2e-5 \
- --num_train_epochs 3 \
- --output_dir /tmp/$TASK_NAME/
社区提供了另一个名为run_glue_no_trainer.py的脚本。原始脚本和这个脚本之间的主要区别在于,这个无培训师脚本给了我们更多机会更改优化器的选项,或添加我们想要做的任何自定义。
概括
在本章中,我们讨论了如何为任何文本分类下游任务微调预训练模型。我们使用情感分析、多类分类和句子对分类(更具体地说,句子对回归)对模型进行了微调。我们使用著名的 IMDb 数据集和我们自己的自定义数据集来训练模型。虽然我们利用Trainer类来处理训练和微调过程的大部分复杂性,但我们学习了如何使用本地库从头开始训练,以了解使用转换器的前向传播和反向传播图书馆。总而言之,我们讨论并进行了使用 Trainer 的微调单句分类、使用本地 PyTorch 没有 Trainer 的情感分类、单句多类分类和微调句对回归。
在下一章中,我们将学习如何微调预训练模型以适应任何标记分类下游任务,例如词性标注或命名实体识别。
-
相关阅读:
如何使用 Apifox 来管理测试你的接口
《重新定义团队》——Google如何工作
Java————网络编程
2023秋招—大数据开发面经—杰创智能科技
AtCoder abc130
C#学习笔记--复杂数据类型、函数和结构体
20、Python实战项目:构建一个简单的Python应用
Ubuntu16.04 完整版 Gym 安装及说明
【JS】react antd 项目如何让Table组件表格滚动播放
防火墙的安全机制
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/127648803