-
Python——字符串
前言
提示:这里可以添加本文要记录的大概内容:美国标准信息交换码ASCII,1个字节(8个比特)来对字符编译
各国有各国的标准,就会不可避免地出现冲突,结果就是会带来乱码问题。
为了解决上述问题,Unicode应运而生。如果统一成Unicode编码,乱码问题是消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间
所以诞生了UTF-8编码
UTF-8是全世界所有国家需要用到的字符进行了编码,1个字节表示英语字符,以3个字节表示中文,部分语言符号用2个/4个字节。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。用单引号、双引号或三引号括起来的符号系列称为字符串
单引号、双引号、三单引号、三双引号可以互相嵌套,用来表示复杂字符串'abc'、'123'、'中国'、"Python"、'''Tom said, "Let's go"'''字符串属于不可变序列
空串表示为''或 ""
三引号'''或"""表示的字符串可以换行,支持排版较为复杂的字符串;三引号还可以在程序中表示较长的注释。
字符串的应用非常广泛,其支持的操作也比较多
提示:由于编译软件的不同,在输出的时候或许得加上print()编码
Python 3.x完全支持中文字符,默认使用UTF-8编码格式,无论是一个数字、英文字母,还是一个汉字,都按一个字符对待和处理。
s="中国台湾台北" len(s) #字符串长度,或者包含的字符个数 >>> s = '中国台湾台北ABCDE' #中文与英文字符同样对待,都算一个字符 >>> len(s) 11 >>> 姓名 = '张三' #使用中文作为变量名 >>> print(姓名) #输出变量的值 张三 \- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在python中,字符串属于不可变序列类型
Python字符串驻留机制:对于短字符串,多个对象共享该副本。长字符串不遵守驻留机制,因为解释器仅对看起来像python标识符的字符串使用intern()方法,而python标识符是由下划线、字母和数字组成
【例】s1="今天天气真不错" s2="今天天气真不错" print(id(s1)) print(id(s2))- 1
- 2
- 3
- 4

s1="今天天气真不错"*1000 s2="今天天气真不错"*1000 print(id(s1)) print(id(s2))- 1
- 2
- 3
- 4

【例】>>> s1="hello" >>> s2="hello" >>> s1 is s2 True # 如果有空格,默认不启用intern机制 >>> s1="hell o" >>> s2="hell o" >>> s1 is s2 False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
字符串格式化
格式字符 说明 %s 字符串(采用str()的显示) %c 单个字符 %b 二进制整数 %d 十进制整数 %i 十进制整数 %o 八进制整数 %x 十六进制整数 %e 指数(基底写为e) %E 指数(基底写为E) %f、%F、%F 浮点数 %g 指数(e)或浮点数(根据显示长度) %G 指数(E)或浮点数(根据显示长度) %% 字符"%" %" >>> x = 1235 >>> so="%o" % x >>> so "2323" >>> sh = "%x" % x >>> sh "4d3" >>> se = "%e" % x >>> se "1.235000e+03" >>> "%s"%65 #类似于str() "65" >>> "%s"%65333 "65333" >>> "%d"%"555" TypeError: %d format: a number is required, not str >>> int('555') #使用int()函数将合法的数字字符串转换成数字。 555 >>> '%d,%c'%(65, 65) #使用元组对字符串进行格式化,按位置对应。 '65,A' >>> '%s'%[1, 2, 3] '[1, 2, 3]' >>> str((1,2,3)) #使用str()可以将任意类型数据转换成字符串。 '(1, 2, 3)' >>> str([1,2,3]) '[1, 2, 3]'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
使用format方法进行格式化
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个数的参数,位置可以不按顺序。
在%方法中%s只能替代字符串类型,而在format中不需要理会数据类型;
填充方式十分灵活,对齐方式十分强大;#1、按照默认顺序,不指定位置 print('{} {}'.format("hello","world")) #2、设置指定位置,可以多次使用 print("{0} {1} {0}".format("hello","or")) #3、通过名称格式化 print("my name is {name},his name is also {name},my age is {age}, and my QQ is {qq}".format(name = "张三",age = 27,qq = "306467355")) #4、使用字典格式化 person = {"name":"opcai","age":20} print("My name is {name} . I am {age} years old .".format(**person)) #5、通过列表格式化 stu = ["opcai","linux","MySQL","Python"] print("My name is {0[0]} , I love {0[1]} !".format(stu)) #6、通过元组格式化 position = (5,8,13) print("X:{0[0]};Y:{0[1]};Z:{0[2]}".format(position)) #注:可以用{}来转义{} print ("{} 对应的位置是 {{}}".format("test"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23


^, <, >分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。+表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格字符串常用方法
提示:由于编译软件的不同,在输出的时候或许得加上print()>>> x = 'Hello world.' >>> len(x) #字符串长度 12 >>> max(x) #最大字符 'w' >>> min(x) ' ' >>> list(zip(x,x)) #zip()也可以作用于字符串 [('H', 'H'), ('e', 'e'), ('l', 'l'), ('l', 'l'), ('o', 'o'), (' ', ' '), ('w', 'w'), ('o', 'o'), ('r', 'r'), ('l', 'l'), ('d', 'd'), ('.', '.')]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
成员判断,关键字in
>>> "a" in "abcde" #测试一个字符中是否存在于另一个字符串中 True >>> 'ab' in 'abcde' True >>> 'ac' in 'abcde' #关键字in左边的字符串作为一个整体对待 False >>> "j" in "abcde" False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Python字符串支持与整数的乘法运算符,表示序列重复,也就是字符串内容的重复
>>> 'abcd' * 3 'abcdabcdabcd'- 1
- 2
字符串切片
切片也适用于字符串,但仅限于读取其中的元素,不支持字符串修改。
提示:由于编译软件的不同,在输出的时候或许得加上print()>>> 'Explicit is better than implicit.'[:8] 'Explicit' >>> 'Explicit is better than implicit.'[9:23] 'is better than'- 1
- 2
- 3
- 4
硬件翻译成软件能懂的语言
软件翻译成硬件能懂的语言s="AA#23.8#35%#1#BB" if s[:2]=='AA': s1 = s.split('#') print("室内温度:",s1[1],"度") print("室内温度:",s1[2]) if(s1[3]=="1"): print("防盗检测:有外人闯入") else: print("无效数据")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
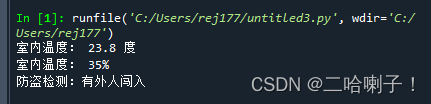
解释:
按井号【#】切分
第一行中s="AA#23.8#35%#1#BB",四刀切出了n+1个部分,也就是5部分。分别是:AA、23.8、35%、1、BB五部分
切完后是字符串,切完后【#】也不要了
第四行:s1[1],输出的是下标为1的,也就是23.8
第五行:s1[2],输出的是下标为2的,也就是35%
第六行:s1[3],输出的是下标为3的,也就是1字符串常用方法
find()与rfind()
find():用来查找一个字符串在另一个字符串首次出现的位置(从左到右第一个)
rfind():用来查找一个字符串在另一个字符串最后一次出现的位置(从右到左第一个)
如果不存在则返回-1s="《战狼二》是吴京执导的动作军事电影,该片讲述了脱下军装的冷锋(吴京)被卷入了一场非洲国家的叛乱,本来能够安全撤离的他无法忘记军人的职责,重回战场展开救援的故事" i=s.find("吴京") print(i) i=s.find("吴京",8) print(i) i=s.find("吴京",8,29) print(i) i=s.rfind("吴京") print(i)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
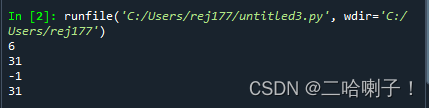
rfind是从右边开始,find方法检索的时候是从左边开开始的index()与rindex()
index():用来返回一个字符串在另一个字符串指定范围中首次出现的位置
rindex():用来返回一个字符串在另一个字符串指定范围中最后一次出现的位置
如果不存在则抛出异常s="《战狼二》是吴京执导的动作军事电影,该片讲述了脱下军装的冷锋(吴京)被卷入了一场非洲国家的叛乱,本来能够安全撤离的他无法忘记军人的职责,重回战场展开救援的故事" i=s.index("吴京") print(i) i=s.index("吴京",8) print(i) i=s.rindex("吴京") print(i) i=s.index("吴京",8,29) print(i)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

count()计算次数
count():计算字符串出现的次数s="《战狼二》是吴京执导的动作军事电影,该片讲述了脱下军装的冷锋(吴京)被卷入了一场非洲国家的叛乱,本来能够安全撤离的他无法忘记军人的职责,重回战场展开救援的故事" num=s.count("吴京") print(num) num=s.count("吴京演员") print(num) # 输出: ''' 2 0 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
len()计算长度
len():计算字符串长度s="《战狼二》" l=len(s) print(l) # 输出: ''' 5 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
split()从左到右分割
用来以指定的零个或多个字符为分隔符,把当前字符串从左往右分割
【例一】s="我爱你 \n中国 \n\n 我爱你 \t 北京" print(s) sl=s.split() print(sl)- 1
- 2
- 3
- 4
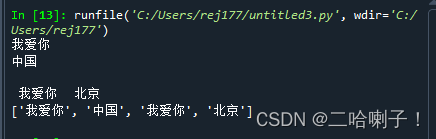
【例二】
split()指定最大分割次数,切掉的是要被删除掉的第一种:
s="我爱你 \n中国 \n\n 我爱你 \t 北京" sl=s.split(maxsplit=2) #最多切2刀 print(sl)- 1
- 2
- 3

第二种:>>> s.split('&',1) ['apple', 'peach&banana&pear'] >>> s.split('&',maxsplit=2) ['apple', 'peach', 'banana&pear'] >>> s.split('&',maxsplit=100) ['apple', 'peach', 'banana', 'pear']- 1
- 2
- 3
- 4
- 5
- 6
【例三】
s="AA#23.8#35%#1#BB" if s[:2]=='AA': sl=s.split('#') print(sl) s2=s.split('A#') print(s2)- 1
- 2
- 3
- 4
- 5
- 6

rsplit()从右到左分割
rsplit()与split()功能相似,用来以指定的零个或多个字符为分隔符,把当前字符串从右往左分割s="我爱你 \n中国 \n\n 我爱你 \t 北京" sl=s.rsplit() print(sl)- 1
- 2
- 3

rsplit()指定最大分割次数
第一种:
s="我爱你 \n中国 \n\n 我爱你 \t 北京" sl=s.rsplit(maxsplit=2) #最多切2刀 print(sl)- 1
- 2
- 3

第二种:>>> s.rsplit('&',1) ['apple&peach&banana', 'pear']- 1
- 2
split()和rsplit()不指定分隔符
对于split()和rsplit()方法,如果不指定分隔符,则字符串中的任何空白符号(包括空格、换行符、制表符等等)都将被认为是分隔符,把连续多个空白字符看作一个,返回包含最终分割结果的列表。
>>> s = 'hello world \n\n My name is Dong ' >>> s.split() ['hello', 'world', 'My', 'name', 'is', 'Dong'] >>> s = '\n\nhello world \n\n\n My name is Dong ' >>> s.split() ['hello', 'world', 'My', 'name', 'is', 'Dong'] >>> s = '\n\nhello\t\t world \n\n\n My name\t is Dong ' >>> s.split() ['hello', 'world', 'My', 'name', 'is', 'Dong']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
调用split()方法若传递参数包括空格、换行符、制表符等情况略有不同。
>>> 'a\t\t\tbb\t\tccc'.split('\t') #每个制表符都被作为独立的分隔符 ['a', '', '', 'bb', '', 'ccc'] >>> 'a\t\t\tbb\t\tccc'.split() #连续多个制表符被作为一个分隔符 ['a', 'bb', 'ccc']- 1
- 2
- 3
- 4
partition()、rpartition()
partition()和rpartition()用来以指定字符串为分隔符将原字符串分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串。>>> s.partition('&') ('apple', '&', 'peach&banana&pear') >>> s.rpartition('&') ('apple&peach&banana', '&', 'pear') >>> s.rpartition('banana') ('apple&peach&', 'banana', '&pear') >>> s.partition('%') ('apple&peach&banana&pear', '', '') >>> s.rpartition('%') ('', '', 'apple&peach&banana&pear')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字符串连接运算符+
不推荐使用+运算符连接字符串(效率低),优先使用join()方法
s="计算机编程语言:" s1="python" s2="C++" s3="Java" s4=s+s1+"、"+s2+"、"+s3 print (s4) #输出: ''' 计算机编程语言:python、C++、Java '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
字符串连接join()
join()用于将序列中的元素以指定的字符连接生成一个新的字符串s=['北京','上海','杭州'] sl='#'.join(s) print(sl) #输出: ''' 北京#上海#杭州 ''' ############################################ >>> a=["apple", "peach", "banana", "pear"] >>> sep="," >>> s=sep.join(a) >>> s "apple,peach,banana,pear" >>> '&'.join(a) 'apple&peach&banana&pear' >>> '-'.join(a) 'apple-peach-banana-pear'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
查找替换replace()
【例1】
s="tensorflow是一个基于数据流编程的符号数学系统,tensorflow被广泛应用于各类机器学习(machine learning)算法的编程实现" sl=s.replace("tensorflow", "TensorFlow") print(sl) #输出: ''' TensorFlow是一个基于数据流编程的符号数学系统,TensorFlow被广泛应用于各类机器学习(machine learning)算法的编程实现 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
【例2】
s="你好,你好" print(s) s2=s.replace("你好","你吃饭了吗") print(s2) #输出: ''' 你好,你好 你吃饭了吗,你吃饭了吗 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
strip()、rstrip()、lstrip()
strip()、rstrip()、lstrip()移除字符串头尾指定的字符(默认为空格、换行、和“tab”)或字符序列,该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。即:去除首和尾的
\n \t ' '【例1】
s="\n1_happy_m\n.wav\t\n" print(s,len(s)) sl=s.strip() print(sl) print(len(sl)) ###################### >>> '\n\nhello world \n\n'.strip() 'hello world'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
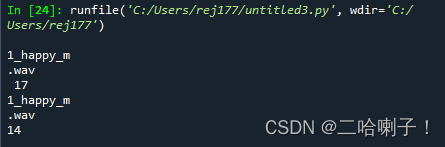
【例2】
# 去掉空格字符串 >>> s = " abc " >>> s2 = s.strip() >>> s2 "abc" >>> "aaaassddf".strip("a") "ssddf" >>> "aaaassddf".strip("af") "ssdd" >>> "aaaassddfaaa".rstrip("a") #删除字符串右端指定字符 'aaaassddf' >>> "aaaassddfaaa".lstrip("a") #删除字符串左端指定字符 'ssddfaaa'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
【例3】
这三个函数的参数指定的字符串并不作为一个整体对待,而是在原字符串的两侧、右侧、左侧删除参数字符串中包含的所有字符,一层一层地从外往里扒。>>> 'aabbccddeeeffg'.strip('af') #字母f不在字符串两侧,所以不删除 'bbccddeeeffg' >>> 'aabbccddeeeffg'.strip('gaf') 'bbccddeee' >>> 'aabbccddeeeffg'.strip('gaef') 'bbccdd' >>> 'aabbccddeeeffg'.strip('gbaef') 'ccdd' >>> 'aabbccddeeeffg'.strip('gbaefcd') ''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
eval()内置函数
用来执行一个字符串表达式,并返回表达式的值。
>>> eval("3+4") 7 >>> a = 3 >>> b = 5 >>> eval('a+b') 8 >>> import math >>> eval('help(math.sqrt)') >>> eval('math.sqrt(3)') 1.7320508075688772 >>> eval('aa') NameError: name 'aa' is not defined- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
eval()函数是非常危险的
如果用户巧妙的输入字符串,可以执行任意外部程序,或者精心构造其他字符串达到其他的目的。恶意黑客也是利用一些程序的bug来精心构造非法输入来触发漏洞,从而造成破坏和攻击。eval("__import__('os').startfile('notepad.exe')") #启动记事本程序 eval("__import__('os').system('md testtest')") #在当前目录创建文件夹- 1
- 2
startswith()、endswith()
startswith()、endswith(),判断字符串是否以指定字符串开始或结束
【例1】s="PaddlePaddle是百度推出的开源深度学习平台框架" flag=s.startswith("Paddle") print(flag) flag=s.startswith("Paddle",1,10) print(flag) flag=s.endswith("框架") print(flag) flag=s.endswith("框架",1,10) print(flag) #输出: True False True False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
【例2】
>>> s = 'Beautiful is better than ugly.' >>> s.startswith('Be') #检测整个字符串 True >>> s.startswith('Be', 5) #指定检测范围起始位置 False >>> s.startswith('Be', 0, 5) #指定检测范围起始和结束位置 True- 1
- 2
- 3
- 4
- 5
- 6
- 7
center()居中、ljust()居左、rjust()居右
center()、ljust()、rjust(),返回指定宽度的新字符串
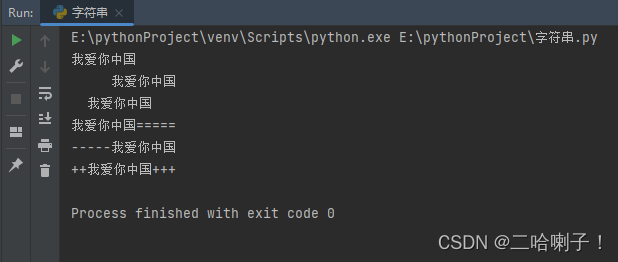
s="我爱你中国" print(s.ljust(10)) #居左 print(s.rjust(10)) #居右 print(s.center(10)) #居中 #空格用其他符号填充 print(s.ljust(10,"=")) print(s.rjust(10,"-")) print(s.center(10,"+"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
lower()、upper()、capitalize()、title()、swapcase()
>>> s = "What is Your Name?" >>> s.lower() #返回小写字符串 'what is your name?' >>> s.upper() #返回大写字符串 'WHAT IS YOUR NAME?' >>> s.capitalize() #字符串首字符大写 'What is your name?' >>> s.title() #每个单词的首字母大写 'What Is Your Name?' >>> s.swapcase() #大小写互换 'wHAT IS yOUR nAME?'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
总结
find()和rfind()方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1;index()和rindex()方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;count()方法用来返回一个字符串在另一个字符串中出现的次数。find和index的区别:如果不存在返回的结果不一样split()和rsplit()方法分别用来以指定字符为分隔符,将字符串左端和右端开始将其分割成多个字符串,并返回包含分割结果的列表;partition()和rpartition()用来以指定字符串为分隔符将原字符串分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串。 -
相关阅读:
05 Spring整合MyBatis
springboot+基层慢性病信息管理系统 毕业设计-附源码221550
如何在国内安装Bitdefender
Imu_PreIntegrate_07 Vecility bias update 零偏更新后速度预积分量对零偏的偏导
准备蓝桥杯的宝贝们看过来,二分法一网打尽(基础篇)
《C++代码简洁之道》学习笔记:类的设计原则
java面试题
软件测试之TCP、UPD协议详解
动态规划算法
Unity(第二十四部)UI
- 原文地址:https://blog.csdn.net/rej177/article/details/127633043
