-
神经网络-非线性激活
概述:
非线性激活主要是为了给我们的神经网络去引入一些非线性的特质,比较常用的非线性激活有两个分别是Sigmoid和RELU。
RELU
示例代码:
import torch from torch import nn from torch.nn import ReLU input = torch.tensor([[1,-0.5], [-1,3]]) input = torch.reshape(input,(-1,1,2,2)) print(input.shape) # 搭建神经网络 class Booze(nn.Module): def __init__(self): super(Booze, self).__init__() # inplace参数的意义就是是否将原来的变量的值替换成处理后的结果值 若inplace=True则对原来的变量进行替换,原来变量的值就变了,变成处理后的结果值,若inplace=False则不对原来的变量进行替换,产生的结果需要一个新的变量去接收 # 通常情况下,建议将inplace传入False,这样可以保证原始数据不丢失 self.relu1 = ReLU() # 重写forword方法 def forward(self,input): output = self.relu1(input) return output obj = Booze() output = obj(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
代码运行结果:

对于ReLU接口的使用,该接口只有一个参数需要传入,那就是inplace参数。
torch.nn.ReLU(inplace=False)- 1
inplace参数的意义就是是否将原来的变量的值替换成处理后的结果值 若inplace=True则对原来的变量进行替换,原来变量的值就变了,变成处理后的结果值,若inplace=False则不对原来的变量进行替换,产生的结果需要一个新的变量去接收。
通常情况下,建议将inplace传入False,这样可以保证原始数据不丢失。

上面这张图是ReLU激活函数的图像,对上面这张图的解释:小于零进行截断,大于零则输出原有值。Sigmoid
示例代码:
import torch import torchvision from torch import nn from torch.nn import ReLU, Sigmoid from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("./CIFAR10",train=False,transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset,batch_size=64) # 搭建神经网络 class Booze(nn.Module): def __init__(self): super(Booze, self).__init__() # inplace参数的意义就是是否将原来的变量的值替换成处理后的结果值 若inplace=True则对原来的变量进行替换,原来变量的值就变了,变成处理后的结果值,若inplace=False则不对原来的变量进行替换,产生的结果需要一个新的变量去接收 # 通常情况下,建议将inplace传入False,这样可以保证原始数据不丢失 self.relu1 = ReLU() self.sigmoid1 = Sigmoid() # 重写forward方法 def forward(self,input): # output = self.relu1(input) output = self.sigmoid1(input) return output obj = Booze() # 使用tensorboard进行可视化 writer = SummaryWriter('logs') step = 0 for data in dataloader: imgs,targets = data writer.add_images("input",imgs,step) # 使用神经网络对图片进行处理 output = obj(imgs) writer.add_images("output",output,step) step+=1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
Sigmoid和RELU的使用方法类似这里就不再赘述。
上述代码运行结果在tensorboard中可视化如下图所示:
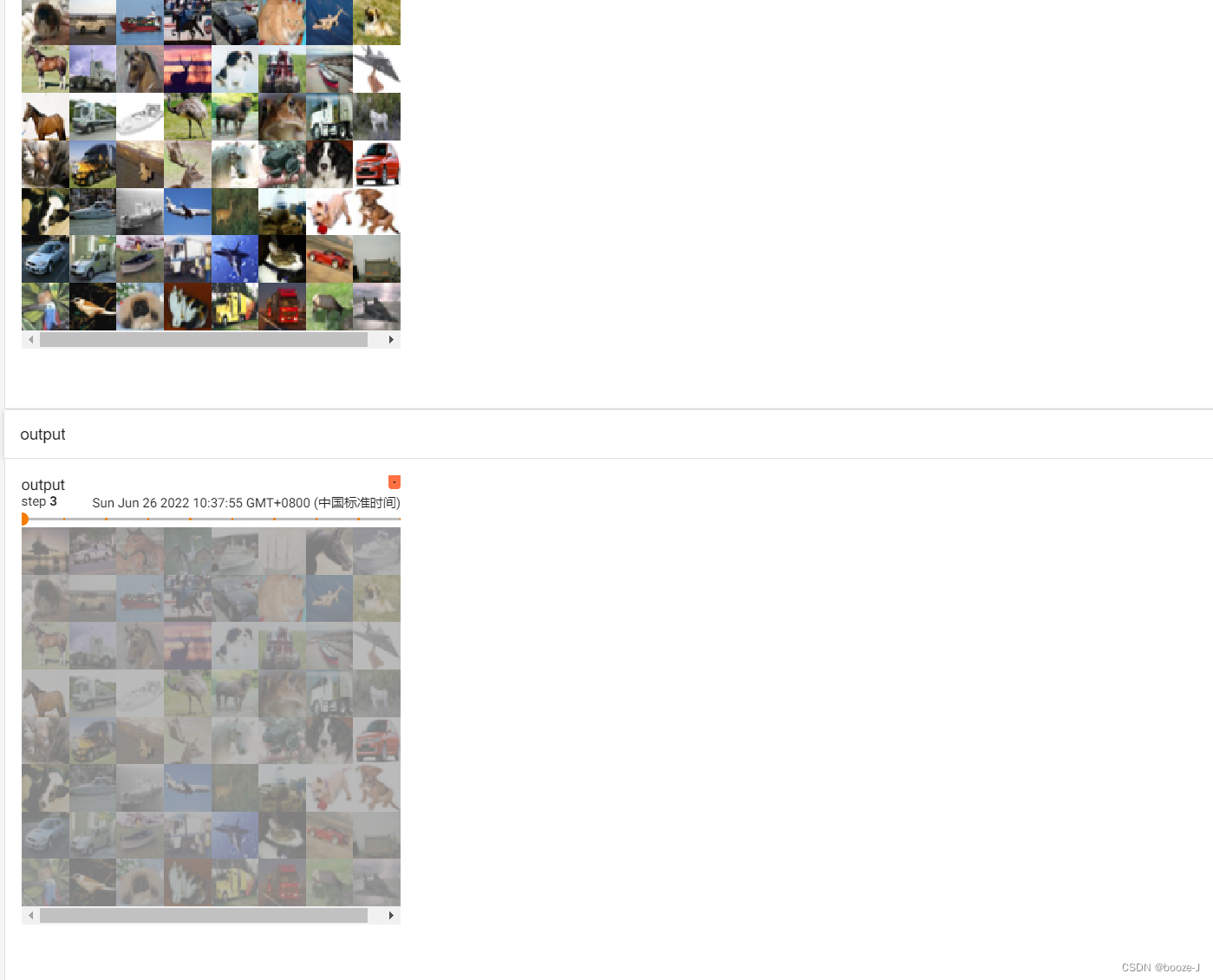
非线性激活sigmoid函数处理前后的效果还是比较明显的哈。总结
非线性变换主要目的就是在我们的网络当中去引入一些非线性特征。因为非线性也多的话,你才能训练出符合各种曲线或者说符合各种特征的一个模型,如果大家都是直愣愣的话,模型的泛化能力就不够好。
-
相关阅读:
RK3588移植-ffmpeg交叉编译
雾锁王国服务器配置怎么选择?阿里云和腾讯云
Unity学习 --- 你好,编译器
东方甄选推独立App自立门户;西湖大学『强化学习数学基础』教材书稿;经典书籍『深入浅出设计模式』Python版代码;前沿论文 | ShowMeAI资讯日报
vue框架之插槽,组件的自定义,网络代理配置,网络公共路径配置
嵌入式Linux裸机开发(七)UART串口、IIC、SPI通信
博物馆网上展厅有哪些用途,如何搭建数字时代的文化宝库
网络安全(黑客)自学
刨根问底 Redis, 面试过程真好使
vue实现左右伸缩(el-drawer自定义位置展开收缩)
- 原文地址:https://blog.csdn.net/booze_/article/details/125467712
