-
云计算实验2 Spark分布式内存计算框架配置及编程案例
一、 实验目的
掌握分布式多节点计算平台Spark配置,Spark编程环境IDEA配置,示例程序启动与运行
二、 实验环境
Linux的虚拟机环境、线上操作视频和实验指导手册
三、 实验任务
完成Spark开发环境安装、熟悉基本功能和编程方法。
四、 实验步骤
请按照线上操作视频和实验指导手册 ,完成以下实验内容:
- 实验2-1 Spark安装部署:Standalone模式
(1)在Hadoop平台上配置Spark主节点和从节点 (2)启动Spark集群和网页操作界面- 1
- 2
- 实验2-2 Spark编程工具:使用IDEA
(1)安装IDEA集成编译环境 (2)安装Scala插件 (3)配置IDEA集成编译环境- 1
- 2
- 3
- 实验2-3 Spark单词计数示例程序运行
(1)使用IDEA新建Spark项目 (2)使用Scala示例代码编写单词计数程序 (3)配置程序参数,编译并运行Spark单词计数程序- 1
- 2
- 3
五、 实验作业
- 提交实验报告电子稿和纸质稿,内容包括安装步骤及主要配置方法说明,关键步骤截图,并对截图内容进行解释说明;
- 个人对实验的总结和心得,本实验具有一定难度和繁琐程度,请总结与撰写自身遇到的问题,以及解决问题的过程,该内容为每位同学实际经历,不要雷同。
- 搜索互联网并回答问题:谈谈大数据技术使用后,企业获取用户隐私信息的变化,以及未来如何保护用户隐私?(回答需大于500字)
六、 实验结果与分析
1、安装步骤及主要配置方法说明
1. 实验2-1 Spark安装部署:Standalone模式
(1)在Hadoop平台上配置Spark主节点和从节点
编写安装配置脚本,我认为重复的工作没有必要浪费过多时间,在上一个实验中我提出了这样的想法。
1、Spark-master.sh 配置主机
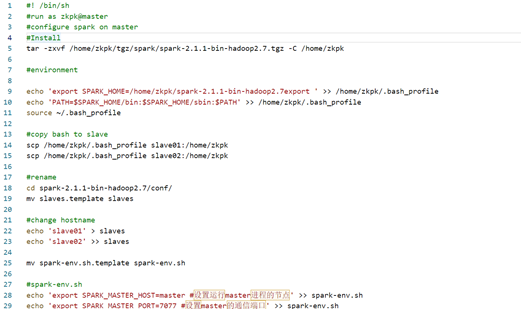
#! /bin/sh #run as zkpk@master #configure spark on master #Install tar -zxvf /home/zkpk/tgz/spark/spark-2.1.1-bin-hadoop2.7.tgz -C /home/zkpk #environment echo 'export SPARK_HOME=/home/zkpk/spark-2.1.1-bin-hadoop2.7export ' >> /home/zkpk/.bash_profile echo 'PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH' >> /home/zkpk/.bash_profile source ~/.bash_profile #copy bash to slave scp /home/zkpk/.bash_profile slave01:/home/zkpk scp /home/zkpk/.bash_profile slave02:/home/zkpk #rename cd spark-2.1.1-bin-hadoop2.7/conf/ mv slaves.template slaves #change hostname echo 'slave01' > slaves echo 'slave02' >> slaves mv spark-env.sh.template spark-env.sh #spark-env.sh echo 'export SPARK_MASTER_HOST=master #设置运行master进程的节点' >> spark-env.sh echo 'export SPARK_MASTER_PORT=7077 #设置master的通信端口' >> spark-env.sh echo 'export SPARK_WORKER_CORES=1 #每个worker使用的核数' >> spark-env.sh echo 'export SPARK_WORKER_MEMORY=1024M #每个worker使用的内存大小' >> spark-env.sh echo 'export SPARK_MASTER_WEBUI_PORT=8080 #master的webui端口' >> spark-env.sh echo 'export SPARK_CONF_DIR=/home/zkpk/spark-2.1.1-bin-hadoop2.7/conf #spark的配置文件目录' >> spark-env.sh echo 'export JAVA_HOME=/usr/java/jdk1.8.0_131/ #jdk安装路径' >> spark-env.sh cd scp -r spark-2.1.1-bin-hadoop2.7/ zkpk@slave01:/home/zkpk scp -r spark-2.1.1-bin-hadoop2.7/ zkpk@slave02:/home/zkpk- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
2、Spark-slave.sh 配置从机
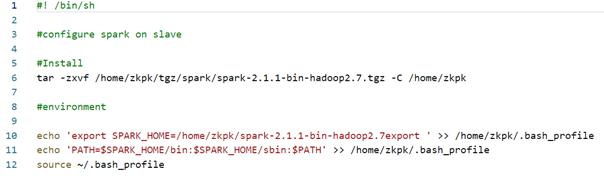
#! /bin/sh #configure spark on slave #Install tar -zxvf /home/zkpk/tgz/spark/spark-2.1.1-bin-hadoop2.7.tgz -C /home/zkpk #environment echo 'export SPARK_HOME=/home/zkpk/spark-2.1.1-bin-hadoop2.7export ' >> /home/zkpk/.bash_profile echo 'PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH' >> /home/zkpk/.bash_profile source ~/.bash_profile- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
安装配置仅需运行脚本即可
注意:在执行脚本前需要使脚本具有执行权限(例如对于spark-master.sh,需要 chmod +x ./spark-master.sh)
(2)启动Spark集群和网页操作界面
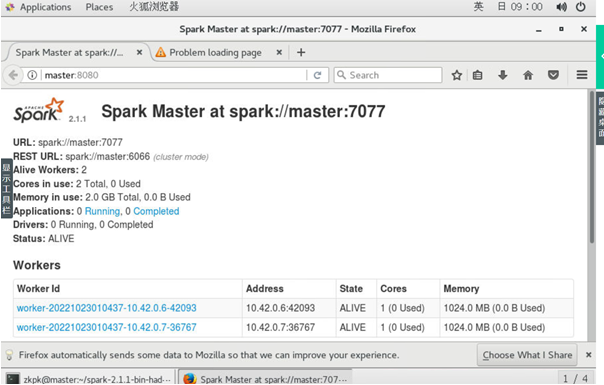
验证spark standalone模式部署正确
访问spark webui界面地址
命令行提交job到spark集群,计算PI
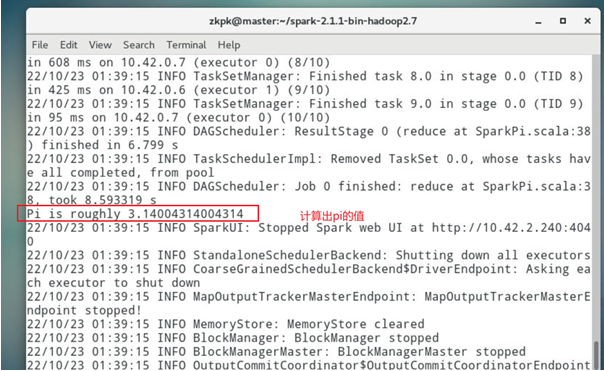
2. 实验2-2 Spark编程工具:使用IDEA
(1)安装IDEA集成编译环境
(2)安装Scala插件
(3)配置IDEA集成编译环境1、 保证java已经安装正确版本

如果未安装,可使用此脚本(java.sh)安装#! /bin/sh # config java in all machines # must with sudo # remove original java version yum remove java-1.* mkdir /usr/java # install tar -xzvf /home/zkpk/tgz/jdk-8u131-linux-x64.tar.gz -C /usr/java # java environment echo 'export JAVA_HOME=/usr/java/jdk1.8.0_131/' >> /home/zkpk/.bash_profile echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /home/zkpk/.bash_profile source /home/zkpk/.bash_profile- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2、编写脚本配置scala和安装idea
编写脚本
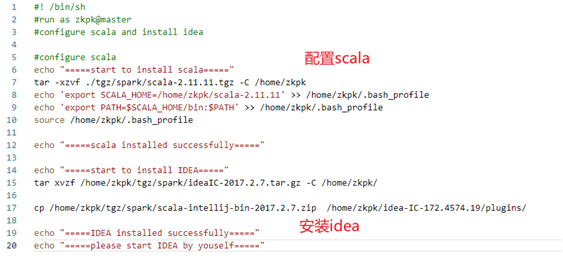
#! /bin/sh #run as zkpk@master #configure scala and install idea #configure scala echo "=====start to install scala=====" tar -xzvf ./tgz/spark/scala-2.11.11.tgz -C /home/zkpk echo 'export SCALA_HOME=/home/zkpk/scala-2.11.11' >> /home/zkpk/.bash_profile echo 'export PATH=$SCALA_HOME/bin:$PATH' >> /home/zkpk/.bash_profile source /home/zkpk/.bash_profile echo "=====scala installed successfully=====" echo "=====start to install IDEA=====" tar xvzf /home/zkpk/tgz/spark/ideaIC-2017.2.7.tar.gz -C /home/zkpk/ cp /home/zkpk/tgz/spark/scala-intellij-bin-2017.2.7.zip /home/zkpk/idea-IC-172.4574.19/plugins/ echo "=====IDEA installed successfully=====" echo "=====please start IDEA by youself====="- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行脚本
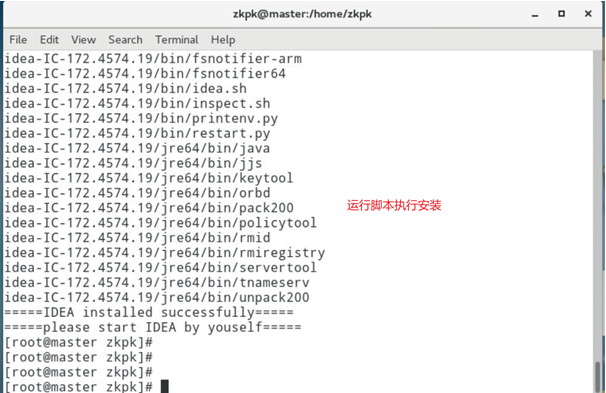
3、验证scala是否安装成功

4、启动idea
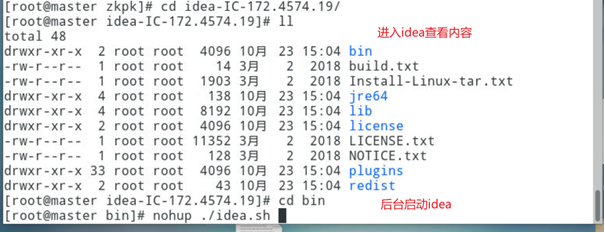
5、配置scala plugin
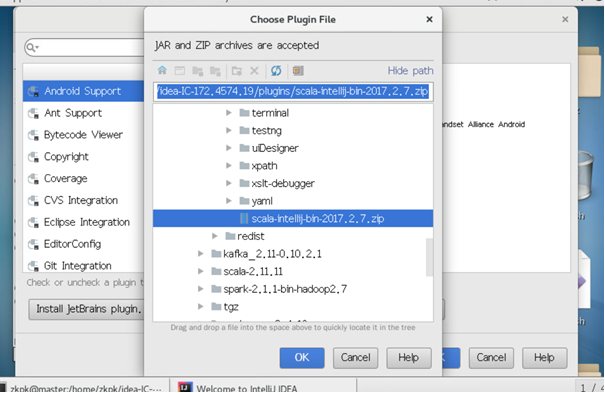
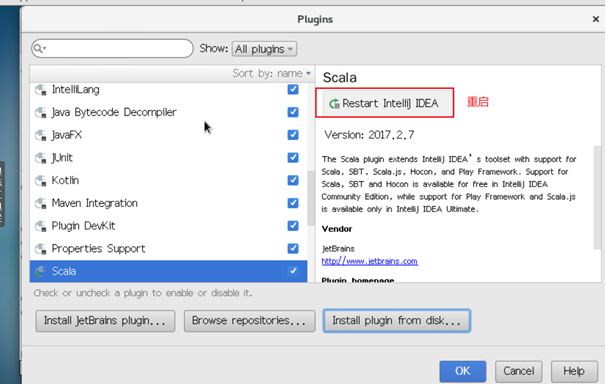
3. 实验2-3 Spark单词计数示例程序运行
(1)使用IDEA新建Spark项目
(2)使用Scala示例代码编写单词计数程序
(3)配置程序参数,编译并运行Spark单词计数程序1、启动hadoop集群

2、 打开IDEA,配置软件包依赖
创建工程成功
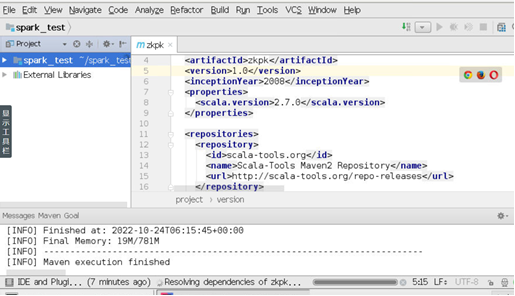
仅展示部分配置截图
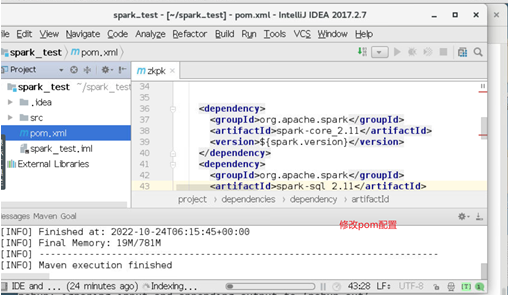
3、 配置pom
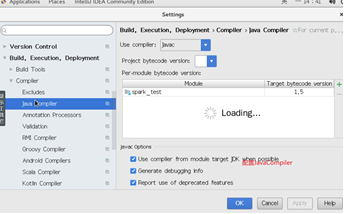
4、 配置JavaComplier
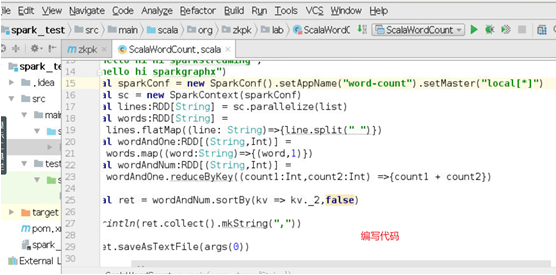
5、 编写Scala程序完成Spark单词计数
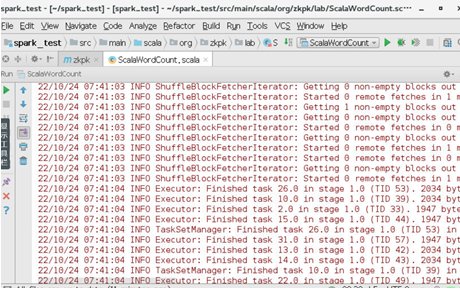
6、 运行测试
查看HDFS输出
2、实验的总结和心得
本次实验主要是完成spark的安装配置和利用spark技术完成单词计数程序,旨在通过安装配置过程来体会spark技术,spark是一种用于大数据工作负载的分布式开源处理系统,它支持很多语言,例如Java,Python,Scala等,在本次实验中我们使用的Scala。一项技术的诞生必然是为了解决现有的问题, Hadoop MapReduce处理数据时存在大量的磁盘读取和写入,频繁的磁盘读取造成MapReduce作业很慢,而spark的出现就是为了解决这个问题。Spark实现方法是将数据读取到内存中,内存的读写速度将远快于磁盘,与此相似的是Redis缓存模型,Redis利用内存读写速度快于磁盘,将用户常用的数据存储于内存中,加速读取,优化用户体验。
实验总结
- 针对重复任务,编写脚本完成
- 导包配置需要细心
- 利用spark可以感受出速度较只使用hadoop有一定提升
3、谈大数据技术使用后,企业获取用户隐私信息的变化,以及未来如何保护用户隐私?
随着智慧城市、智慧交通、智能家居、智能电网、智慧医疗、在线社交网络、Web 3.0等数字化技术的发展,人们的衣食住行、健康医疗等信息被数字化,可以随时随地通过海量的传感器、智能处理设备等终端进行收集和使用,实现物与物、物与人、人与人等之间在任何时候、任何地点的有效连接,也促成了大数据时代的到来。
为了从大数据中获益,数据持有方有时需要公开发布己方数据,这些数据通常会包含一定的用户信息,服务方在数据发布之前需要对数据进行处理,使用户隐私免遭泄露。此时,确保用户隐私信息不被恶意的第三方获取是极为重要的。一般的,用户更希望攻击者无法从数据中识别出自身,更不用说窃取自身的隐私信息,匿名技术就是这种思想的实现之一。
为了防御链接攻击,常见的静态匿名技术有k-匿名、l-diversity匿名、t-closeness匿名以及以它们的相关变形为代表的匿名策略。随着研究的进步,这些匿名策略的效果逐步提高。但是这些匿名策略以信息损失为代价,不利于数据挖掘与分析。为此,研究者随即提出了个性化匿名、带权重的匿名等一系列匿名策略。相对于对所有记录执行相同的匿名保护,这类匿名策略给予每条数据记录以不同程度的匿名保护,减少了非必要的信息损失。
大数据存储给隐私保护带来了新的挑战,主要包括:大数据中更多的隐私信息存储在不可信的第三方中,极易被不可信的存储管理者偷窥;大数据存储的难度增大,存储方有可能无意或有意地丢失数据或篡改数据,从而使得大数据的完整性得不到保证。为解决上述挑战,应用的技术主要包括加密存储和第三方审计技术等。包括大数据加密存储技术、大数据加密存储技术。 - 实验2-1 Spark安装部署:Standalone模式
-
相关阅读:
idea如何导入maven项目
word行距怎么设置?专业排版,让文档更具吸引力!
html或web页面一键打包为apk
【矩阵论】2. 矩阵分解——高低分解
2023数维杯国际赛数学建模D题思路模型分析
车辆管理怎么做?这六个车辆管理系统能帮到你!
前端之jQuery
Spring Boot
LVS-DR模式工作过程及优缺点
07、vue : 无法加载文件 C:\Users\JH\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。
- 原文地址:https://blog.csdn.net/qq_50195602/article/details/127613840