-
《JavaSE-第十七章》之LinkedList
前言
在你立足处深挖下去,就会有泉水涌出!别管蒙昧者们叫嚷:“下边永远是地狱!”
博客主页:KC老衲爱尼姑的博客主页
共勉:talk is cheap, show me the code
作者是爪哇岛的新手,水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!
LinkedList概述
LinkedList底层是基于双链表实现,内部使用节点存储数据,相比于数组而言,LinkedList删除和插入元素的效率远高于数组,而查找和修改的效率比数组要低。
数据结构

LinkedList的继承关系
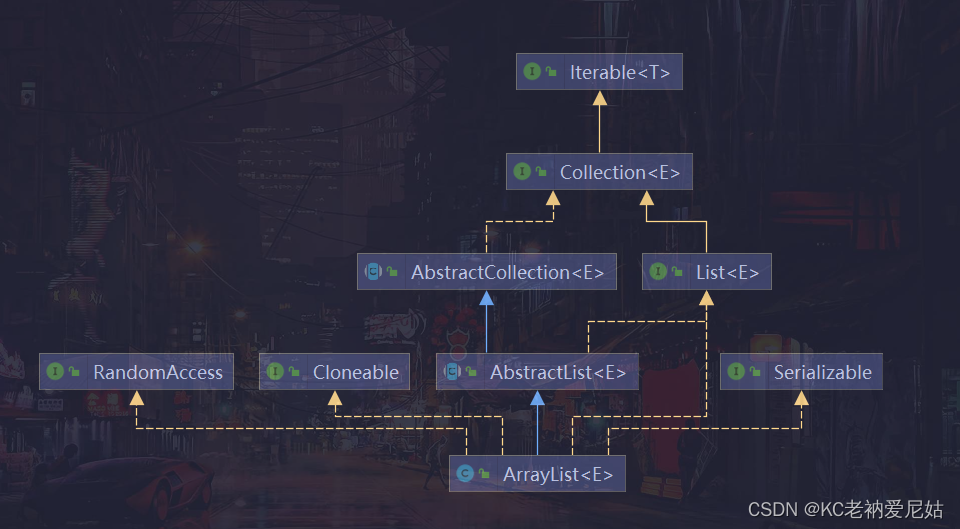
说明
- LinkedList实现了List接口,说明LinkedList可以当做一个顺序存储的容器
- LinkedList实现了Queue接口,说明LinedList可以当做一个队列使用
- LinkedList实现了Serializable,说明支持序列化
- LinkedList是实现了Cloneable,说明支持克隆
属性
//记录链表长度 transient int size = 0; //头指针 transient Node<E> first; //尾指针 transient Node<E> last;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
构造方法
无参构造
public LinkedList() { }- 1
- 2
有参构造
public LinkedList(Collection<? extends E> c) { this(); //将集合中的元素添加到链表中 addAll(c); } //将指定集合中的元素添加到链表中 public boolean addAll(Collection<? extends E> c) { return addAll(size, c); } public boolean addAll(int index, Collection<? extends E> c) { //检查index是否合法 checkPositionIndex(index); //将结合转换成数组 Object[] a = c.toArray(); //得到数组的长度 int numNew = a.length; //判读数组长度是否为0 if (numNew == 0) return false; //定义一个节点pred为前驱,succ为后继 Node<E> pred, succ; //数组长度如果等于链表长度,向链表尾部添加元素 if (index == size) { succ = null;//将后继置空 pred = last;//将链表的最后一个节点的引用赋值给pred } else { //index不等于size,则说明是插入链表中间位置 succ = node(index);//index位置节点的引用 pred = succ.prev;//index位置前一个节点的引用 } //遍历数组,每遍历一个数组元素,就创建一个节点,再将它插入链表相应位置 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o;//强制类型转换 Node<E> newNode = new Node<>(pred, e, null);//构造节点 if (pred == null) first = newNode; else pred.next = newNode;//插入元素 //更新pred为新节点的引用 pred = newNode; } if (succ == null) { //如果是从尾部开始插入的,让last指向最后一个插入的节点 last = pred; } else { //如果不是从尾部插入的,则把尾部的数据和之前的节点连起来 pred.next = succ; succ.prev = pred; } size += numNew;//更新链表长度 modCount++; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
内部类Node
private static class Node<E> { E item;//链表中的数据域 Node<E> next;//记录当前节点的后一个节点的引用 Node<E> prev;//记录当前节点的前一个节点的引用 Node(Node<E> prev, E element, Node<E> next) {//初始化节点 this.item = element; this.next = next; this.prev = prev; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
LinkedLsit特有方法
源码如下
1.addFirst()
public void addFirst(E e) { linkFirst(e); } //头插 private void linkFirst(E e) { final Node<E> f = first;//获取到头节点的引用 final Node<E> newNode = new Node<>(null, e, f); first = newNode;//更新first的指向 if (f == null)//如果为空则说明链表为空 last = newNode;//让尾指针指向新节点 else f.prev = newNode;// size++;//长度自增 modCount++; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
代码示例
public class Demo { public static void main(String[] args) { LinkedList<Integer> list = new LinkedList<Integer>(); list.addFirst(1); list.addFirst(2); list.addFirst(3); System.out.println(list); } } //运行结果 //[3, 2, 1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
图解头插
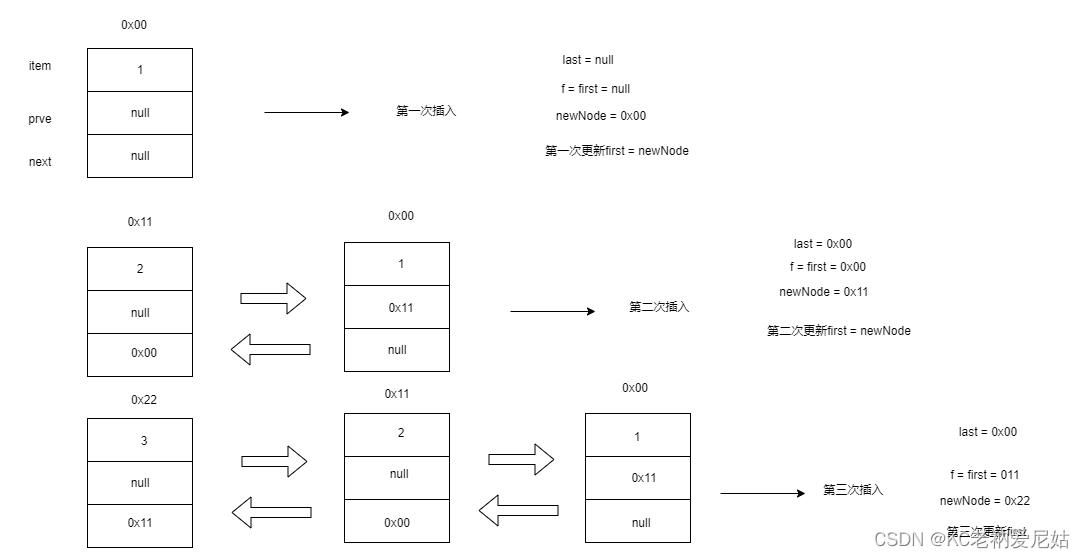
2.addLast()
源码如下
public void addLast(E e) { linkLast(e);//尾插 } //尾插具体实现 void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
代码示例
public class Demo { public static void main(String[] args) { LinkedList<Integer> list = new LinkedList<Integer>(); list.addLast(1); list.addLast(2); list.addLast(3); System.out.println(list); } } //运行结果 //[1, 2, 3]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
图解尾插

3.getFirst()
源码如下
public E getFirst() { final Node<E> f = first;//得到first引用 if (f == null)//链表中无节点 throw new NoSuchElementException();//抛出异常 return f.item;//返回头节点的数据 }- 1
- 2
- 3
- 4
- 5
- 6
4.getLast()
源码如下
public E getLast() { final Node<E> l = last;//得到last引用 if (l == null)//链表中无节点 throw new NoSuchElementException();//抛出异常 return l.item;//返回头节点的数据 }- 1
- 2
- 3
- 4
- 5
- 6
5.removeFirst()
源码如下
public E removeFirst() { final Node<E> f = first;//得到头节点的引用 if (f == null)//如果为null则没有头节点 throw new NoSuchElementException();//抛出异常 return unlinkFirst(f);//删除操作 } //删除链表第一个节点 private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item;//得到头节点的数据 final Node<E> next = f.next;//得到第二个节点的引用 f.item = null;//将头节点数据域置空 f.next = null; //将头节点next域置空 first = next;//更新first指针的指向 if (next == null)//next等于null,说明只有一个节点 last = null; else next.prev = null;//将第二个节点的preve置空 size--;//长度-1 modCount++; return element;//返回要删除头节点的数据 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
6.removeLast()
源码如下
public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException();//抛出异常 return unlinkLast(l); } //删除链表最后个节点 private E unlinkLast(Node<E> l) { // assert l == last && l != null; final E element = l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
List接口
核心方法
1.add(E e)
源码如下
public boolean add(E e) { linkLast(e); return true; } //尾插 void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.add(int index, E element)
源码如下
public void add(int index, E element) { checkPositionIndex(index);//检查index合法性 if (index == size)//如果相等,插入到尾部 linkLast(element);//尾插 else//非尾部位置 linkBefore(element, node(index));// } private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } void linkBefore(E e, Node<E> succ) { //succ为要插入位置的节点,同时也是你要插入该位置节点的后继 final Node<E> pred = succ.prev;//得到插入位置的前驱 final Node<E> newNode = new Node<>(pred, e, succ);//将元素,以及前驱和后继传入 succ.prev = newNode;//更新插入位置节点的前驱为要插入节点的引用 if (pred == null)//如果pred为空说明,要插入的节点已经跑到头节点之前了,需要重置头节点 first = newNode; else pred.next = newNode;//否则的话将pred的next域指向新节点即可 size++; modCount++; } //寻找指定位置的节点 Node<E> node(int index) { //如果index靠近链表的前部分,则从头开始遍历寻找要找的节点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else {//靠近后半部分,则倒着寻找 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
3.remove(int index)
源码如下
public E remove(int index) { checkElementIndex(index);//检查index合法性 return unlink(node(index)); } //删除index位置的具体操作 E unlink(Node<E> x) { final E element = x.item;//要删除节点的值 final Node<E> next = x.next;//要删除节点的后一个节点的引用 final Node<E> prev = x.prev;//要删除节点的前一个节点 //如果prev为空意味着删除的节点是头节点,否则就不是头节点 if (prev == null) { first = next; } else { prev.next = next; x.prev = null;//要删除的节点prev域置空 } //如果prev为空意味着删除的节点是尾节点,否则就不是尾节点 if (next == null) { last = prev; } else { next.prev = prev; x.next = null;//要删除的节点next域置空 } x.item = null;//将要删除节点的数据域置空 size--;//链表的长度减一 modCount++; return element;//返回删除节点的数据域的值 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
4.get(int index)
源码如下
public E get(int index) { checkElementIndex(index); return node(index).item; } //寻找指定位置的节点 Node<E> node(int index) { //如果index靠近链表的前部分,则从头开始遍历寻找要找的节点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else {//靠近后半部分,则倒着寻找 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5.set(int index, E element)
源码如下
public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; } Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
上述的get()和set()方法中的node()方法是以二分查找来看index位置距离size的一半位置,在决定从头遍历还是从尾遍历。以o(n/2)的效率得到一个节点。
6.indexOf(Object o)
源码如下
//从头往尾找该元素第一次出现的下标 public int indexOf(Object o) { int index = 0; //元素为null if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { //元素不为null for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1;//在链表中找不到 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
7.lastIndexOf(Object o)
源码如下
//从尾往头找该元素第一次出现的下标 public int lastIndexOf(Object o) { int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
8.clear()
源码如下
//清空链表 public void clear() { //遍历链表将每个节点中next,prve,item全部置空 for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null;//头尾引用都置空 size = 0;//长度值为0 modCount++; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
总结
- LinkedList 插入,删除都是移动指针效率很高。
- 查找需要进行遍历查询,效率较低。
ArrayList与LinkedList的区别
- ArrayList底层是基于数组实现,LinkedList基于双链表实现
- ArrayList在物理上是一定连续的,而LinkedList在物理上不一定连续,在逻辑上连续
- ArrayList访问随机访问元素的时间复杂度为o(1),LinkedList则为o(n)
- 头插入元素时,ArrayList需要搬运元素,时间复杂度为o(1),链表只需要改变头指针的指向即可,复杂度为o(1)
- ArrayList适用于频繁的访问元素,以及高效的存储元素上,LinkedList适应于任意位置插入和频繁删除元素的场景
终

-
相关阅读:
Linux 目录切换命令
互联网那些技术 | 秒杀库存解决方案
流程编排、如此简单-通用流程编排组件JDEasyFlow介绍
D358周赛复盘:哈希表模拟⭐⭐+链表乘法翻倍运算(先反转)⭐⭐⭐
常用面试/笔试开源小项目61~70
RemObjects Suite Subscription for Delphi
MyBatis使用注解操作及XML操作
JavaWeb Servlet实现登录注册实例(Mybatis,maven,mysql数据库)
vue3 自定义Hooks
基于DBACAN的道路轨迹点聚类
- 原文地址:https://blog.csdn.net/qq_60308100/article/details/127647912
