-
前端面试那些题
对对象与数组的解构的理解
解构是 ES6 提供的一种新的提取数据的模式,这种模式能够从对象或数组里有针对性地拿到想要的数值。 1)数组的解构 在解构数组时,以元素的位置为匹配条件来提取想要的数据的:
const [a, b, c] = [1, 2, 3]- 1
- 2
最终,a、b、c分别被赋予了数组第0、1、2个索引位的值:
数组里的0、1、2索引位的元素值,精准地被映射到了左侧的第0、1、2个变量里去,这就是数组解构的工作模式。还可以通过给左侧变量数组设置空占位的方式,实现对数组中某几个元素的精准提取:
const [a,,c] = [1,2,3]- 1
- 2
通过把中间位留空,可以顺利地把数组第一位和最后一位的值赋给 a、c 两个变量:
2)对象的解构 对象解构比数组结构稍微复杂一些,也更显强大。在解构对象时,是以属性的名称为匹配条件,来提取想要的数据的。现在定义一个对象:
const stu = { name: 'Bob', age: 24 }- 1
- 2
- 3
- 4
- 5
假如想要解构它的两个自有属性,可以这样:
const { name, age } = stu- 1
- 2
这样就得到了 name 和 age 两个和 stu 平级的变量:
注意,对象解构严格以属性名作为定位依据,所以就算调换了 name 和 age 的位置,结果也是一样的:
const { age, name } = stu- 1
- 2
Iterator迭代器
Iterator(迭代器)是一种接口,也可以说是一种规范。为各种不同的数据结构提供统一的访问机制。任何数据结构只要部署Iterator接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。Iterator语法:
const obj = { [Symbol.iterator]:function(){} }- 1
- 2
- 3
[Symbol.iterator]属性名是固定的写法,只要拥有了该属性的对象,就能够用迭代器的方式进行遍历。- 迭代器的遍历方法是首先获得一个迭代器的指针,初始时该指针指向第一条数据之前,接着通过调用 next 方法,改变指针的指向,让其指向下一条数据
- 每一次的
next都会返回一个对象,该对象有两个属性value代表想要获取的数据done布尔值,false表示当前指针指向的数据有值,true表示遍历已经结束
Iterator 的作用有三个:
- 创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
- 第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。
- 第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。
- 不断调用指针对象的next方法,直到它指向数据结构的结束位置。
每一次调用next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。
let arr = [{num:1},2,3] let it = arr[Symbol.iterator]() // 获取数组中的迭代器 console.log(it.next()) // { value: Object { num: 1 }, done: false } console.log(it.next()) // { value: 2, done: false } console.log(it.next()) // { value: 3, done: false } console.log(it.next()) // { value: undefined, done: true }- 1
- 2
- 3
- 4
- 5
- 6
对象没有布局Iterator接口,无法使用
for of遍历。下面使得对象具备Iterator接口- 一个数据结构只要有Symbol.iterator属性,就可以认为是“可遍历的”
- 原型部署了Iterator接口的数据结构有三种,具体包含四种,分别是数组,类似数组的对象,Set和Map结构
为什么对象(Object)没有部署Iterator接口呢?
- 一是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。然而遍历遍历器是一种线性处理,对于非线性的数据结构,部署遍历器接口,就等于要部署一种线性转换
- 对对象部署
Iterator接口并不是很必要,因为Map弥补了它的缺陷,又正好有Iteraotr接口
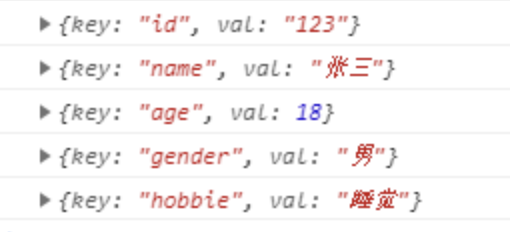
let obj = { id: '123', name: '张三', age: 18, gender: '男', hobbie: '睡觉' } obj[Symbol.iterator] = function () { let keyArr = Object.keys(obj) let index = 0 return { next() { return index < keyArr.length ? { value: { key: keyArr[index], val: obj[keyArr[index++]] } } : { done: true } } } } for (let key of obj) { console.log(key) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
介绍 plugin
插件系统是 Webpack 成功的一个关键性因素。在编译的整个生命周期中,Webpack 会触发许多事件钩子,Plugin 可以监听这些事件,根据需求在相应的时间点对打包内容进行定向的修改。
一个最简单的 plugin 是这样的:
class Plugin{ // 注册插件时,会调用 apply 方法 // apply 方法接收 compiler 对象 // 通过 compiler 上提供的 Api,可以对事件进行监听,执行相应的操作 apply(compiler){ // compilation 是监听每次编译循环 // 每次文件变化,都会生成新的 compilation 对象并触发该事件 compiler.plugin('compilation',function(compilation) {}) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注册插件:
// webpack.config.js module.export = { plugins:[ new Plugin(options), ] }- 1
- 2
- 3
- 4
- 5
- 6
事件流机制:
Webpack 就像工厂中的一条产品流水线。原材料经过 Loader 与 Plugin 的一道道处理,最后输出结果。
- 通过链式调用,按顺序串起一个个 Loader;
- 通过事件流机制,让 Plugin 可以插入到整个生产过程中的每个步骤中;
Webpack 事件流编程范式的核心是基础类 Tapable,是一种 观察者模式 的实现事件的订阅与广播:
const { SyncHook } = require("tapable") const hook = new SyncHook(['arg']) // 订阅 hook.tap('event', (arg) => { // 'event-hook' console.log(arg) }) // 广播 hook.call('event-hook')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Webpack中两个最重要的类Compiler与Compilation便是继承于Tapable,也拥有这样的事件流机制。- Compiler : 可以简单的理解为 Webpack 实例,它包含了当前 Webpack 中的所有配置信息,如 options, loaders, plugins 等信息,全局唯一,只在启动时完成初始化创建,随着生命周期逐一传递;
Compilation: 可以称为 编译实例。当监听到文件发生改变时,Webpack 会创建一个新的 Compilation 对象,开始一次新的编译。它包含了当前的输入资源,输出资源,变化的文件等,同时通过它提供的 api,可以监听每次编译过程中触发的事件钩子;- 区别:
Compiler全局唯一,且从启动生存到结束;Compilation对应每次编译,每轮编译循环均会重新创建;
- 常用 Plugin:
- UglifyJsPlugin: 压缩、混淆代码;
- CommonsChunkPlugin: 代码分割;
- ProvidePlugin: 自动加载模块;
- html-webpack-plugin: 加载 html 文件,并引入 css / js 文件;
- extract-text-webpack-plugin / mini-css-extract-plugin: 抽离样式,生成 css 文件; DefinePlugin: 定义全局变量;
- optimize-css-assets-webpack-plugin: CSS 代码去重;
- webpack-bundle-analyzer: 代码分析;
- compression-webpack-plugin: 使用 gzip 压缩 js 和 css;
- happypack: 使用多进程,加速代码构建;
- EnvironmentPlugin: 定义环境变量;
- 调用插件
apply函数传入compiler对象 - 通过
compiler对象监听事件
loader和plugin有什么区别?
webapck默认只能打包JS和JOSN模块,要打包其它模块,需要借助loader,loader就可以让模块中的内容转化成webpack或其它laoder可以识别的内容。
loader就是模块转换化,或叫加载器。不同的文件,需要不同的loader来处理。plugin是插件,可以参与到整个webpack打包的流程中,不同的插件,在合适的时机,可以做不同的事件。
webpack中都有哪些插件,这些插件有什么作用?
html-webpack-plugin自动创建一个HTML文件,并把打包好的JS插入到HTML文件中clean-webpack-plugin在每一次打包之前,删除整个输出文件夹下所有的内容mini-css-extrcat-plugin抽离CSS代码,放到一个单独的文件中optimize-css-assets-plugin压缩css
渲染机制
1. 浏览器如何渲染网页
概述:浏览器渲染一共有五步
- 处理
HTML并构建DOM树。 - 处理
CSS构建CSSOM树。 - 将
DOM与CSSOM合并成一个渲染树。 - 根据渲染树来布局,计算每个节点的位置。
- 调用
GPU绘制,合成图层,显示在屏幕上
第四步和第五步是最耗时的部分,这两步合起来,就是我们通常所说的渲染
具体如下图过程如下图所示


渲染
- 网页生成的时候,至少会渲染一次
- 在用户访问的过程中,还会不断重新渲染
重新渲染需要重复之前的第四步(重新生成布局)+第五步(重新绘制)或者只有第五个步(重新绘制)
- 在构建
CSSOM树时,会阻塞渲染,直至CSSOM树构建完成。并且构建CSSOM树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的CSS选择器,执行速度越慢 - 当
HTML解析到script标签时,会暂停构建DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载JS文件。并且CSS也会影响JS的执行,只有当解析完样式表才会执行JS,所以也可以认为这种情况下,CSS也会暂停构建DOM
2. 浏览器渲染五个阶段
2.1 第一步:解析HTML标签,构建DOM树
在这个阶段,引擎开始解析
html,解析出来的结果会成为一棵dom树dom的目的至少有2个- 作为下个阶段渲染树状图的输入
- 成为网页和脚本的交互界面。(最常用的就是
getElementById等等)
当解析器到达script标签的时候,发生下面四件事情
html解析器停止解析,- 如果是外部脚本,就从外部网络获取脚本代码
- 将控制权交给
js引擎,执行js代码 - 恢复
html解析器的控制权
由此可以得到第一个结论1
- 由于
