-
代码随想录64——额外题目【哈希表、字符串】:205同构字符串、1002查找常用字符、925长键按入、844比较含退格的字符串
1.205同构字符串
1.1.题目

1.2.解答
这道题目其实也很简单,其实就是一直在存储两个字符串之间字符的映射关系。
- 定义一个
map,其中键是字符串A中的字符,值是对应的字符串B中对应的字符。 - 然后开始遍历每一个字符,如果当前字符在
map中出现过,那么就根据A的字符当做键,寻找B应该对应的值,如果不相等直接返回false。如果没有出现过,则新添加这个映射关系即可。 - 但是还存在一个问题是,不能单纯的看A对B是否对应,还要看B对A是否对应。比如当前字符没有在A的
map中出现过,那么A的map中自然就没有记录对应B的字符。但是此时如果B中的字符在之前已经出现过了,那么他们就不是匹配的了。比如A是abc,B是eff,其中遍历到A的c时,发现没有出现过,但是此时B中对应的字符是f,显然是不对的。
注意:这个地方就是相互的对应关系都要满足,跟SLAM中两帧特征点的对应关系是一样的。
最后直接给出代码如下,需要维护两个
map。bool isIsomorphic(string s, string t) { unordered_map<char, char> umap1; // 使用unordered_map即可 unordered_map<char, char> umap2; for(int i = 0; i < s.size(); i++) { // 1.map1、2中都没有对应字符出现过,说明是全新的对应关系,加入即可 if(umap1.find(s[i]) == umap1.end() && umap2.find(t[i]) == umap2.end()) { umap1[s[i]] = t[i]; umap2[t[i]] = s[i]; } // 2.map1、2中都有对应的字符出现,看是否匹配 else if(umap1.find(s[i]) != umap1.end() && umap2.find(t[i]) != umap2.end()) { if(umap1[s[i]] != t[i] || umap2[t[i]] != s[i]) return false; } // 3.map1、2中一个出现过,一个没出现过,肯定不匹配 else return false; } return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.1002查找常用字符
2.1.题目

2.2.解答
首先想到的是用哈希数组存储26个字母的出现次数,然后最后判断出现次数如果
>=3,那么说明共同出现过。其实这样是错误的,存在两个问题:- 如果某个字母是在一个子串中出现了多次,而其他子串中没有出现,那么这样的结果就是错的。比如字符串分别是
aaa、bcd、efg,这样a出现了三次,但是都是在一个子串中出现的,所以并不是公共出现。 - 另外注意仔细看题目,如果一个字母在字符中共同出现多次,那么结果也要输出多个相同字母。比如上面的示例1,答案中就有两个字母
l。
正确思路是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
如下图所示:
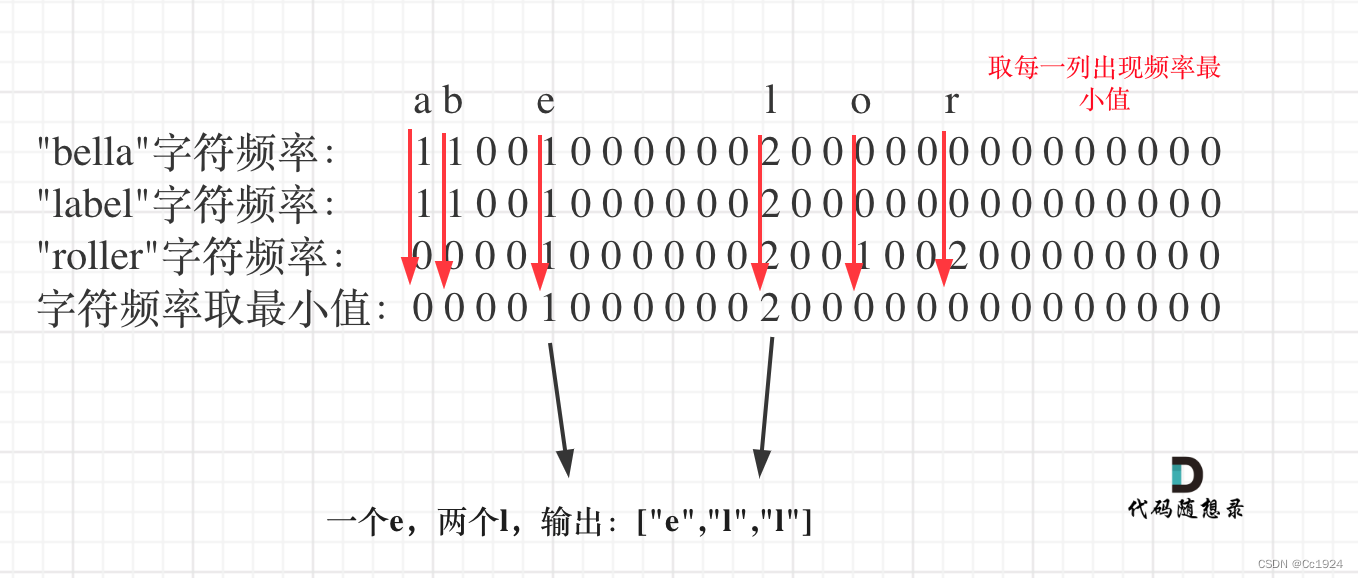
最后给出代码如下,其实很简单,就是过程繁琐了一点。vector<string> commonChars(vector<string> &words) { vector<string> result; // 其实最后里面的字母是char就行,这里用string也无所谓 int hash[26] = {0}; // 记录最后总的结果,即各个字符串中字母出现次数的最小值,即出现次数的交集 // 1.先统计第一个子串中出现的情况 for(int i = 0; i < words[0].size(); i++) hash[words[0][i]-'a']++; // 2.再统计其他子串出现字母的情况,并对hash表取最小的值 for(int i = 1; i < words.size(); i++) { int tmp_hash[26] = {0}; // 当前子串的字母出现情况 for(int j = 0; j < words[i].size(); j++) tmp_hash[words[i][j]-'a']++; // 遍历hash表,取最小值 for(int k = 0; k < 26; k++) hash[k] = min(hash[k], tmp_hash[k]); } // 3.此时hash中存的就是每个字母出现的次数,转成结果就行了 for(int i = 0; i < 26; i++) { while(hash[i]--) // 有多个字符 { string s(1, i+'a'); // i + 'a'就是根据索引,变成字母 result.push_back(s); } } // 4.最后返回结果 return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3.925长键按入
3.1.题目

3.2.解答
这道题目一看以为是哈希,仔细一看不行,要有顺序。
所以模拟同时遍历两个数组,进行对比就可以了。
对比的时候需要一下几点:
name[i]和typed[j]相同,则i++,j++(继续向后对比)name[i]和typed[j]不相同
(1)看是不是第一位就不相同了,也就是j如果等于0,那么直接返回false
(2)不是第一位不相同,就让j跨越重复项,移动到重复项之后的位置,再次比较name[i]和typed[j]:
①如果name[i]和typed[j]相同,则i++,j++(继续向后对比)
②不相同,返回false- 对比完之后有两种情况
(1)name没有匹配完,例如name:"pyplrzzzzdsfa" type:"ppyypllr",则显然是false
(1)type没有匹配完,例如name:"alex" type:"alexxrrrrssda",则必须保证type剩下的字符都是之前遍历的最后一个字符,否则也是false。
动画如下:

最后给出代码如下,比较繁琐,但是不难。
bool isLongPressedName(string name, string typed) { int i = 0, j = 0; // name, typed两个数组的索引 // 遍历两个数组,哪个都不能超过范围 while(i < name.size() && j < typed.size()) { // 1.如果相等,则继续比较下一个 if(name[i] == typed[j]) { i++; j++; } // 2.如果不相等 else { // 2.1.如果是第一个字母就不相等,直接返回false if(j == 0) return false; // 2.2.如果不是第一个字母,则可能是由于typed[j]是前一个字母的重复字母,此时就向后跳过重复的字母 else { // typed[j]向后跳过重复的字母 while(j < typed.size() && typed[j] == typed[j-1]) j++; // typed[j]跳过重复的字母之后,再和name[i]比较 // 2.2.1.如果相等,则继续比较下一个 if(name[i] == typed[j]) { i++; j++; } // 2.2.2.如果不相等,则直接不满足要求,返回false else { return false; } } } } // 3.遍历之后,可能存在name没有遍历完,或者typed没有遍历完的情况 // 3.1.name没有遍历完,显然typed太短了,直接返回false if(i < name.size()) return false; // 3.2.tpyed没有遍历完,那么后面剩余的字符必须都是上面遍历的最后一个字符 while(j < typed.size()) { if(typed[j] != typed[j-1]) // 一旦不是上面遍历的最后一个字符,直接返回false return false; j++; } // 4.最终运行到这里则满足要求,返回true return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
4.844比较含退格的字符串
4.1.题目

4.2.解答
4.2.1.使用栈
这道题目一看就是要使用栈的节奏,这种匹配(消除)问题也是栈的擅长所在。
但是本题没有必要使用栈,因为最后比较的时候还要比较栈里的元素,有点麻烦。
这里直接使用字符串string,来作为栈,末尾添加和弹出,string都有相应的接口,最后比较的时候,只要比较两个字符串就可以了,比比较栈里的元素方便一些。
代码如下:
bool backspaceCompare(string s, string t) { // 使用string当做栈,存储没有#的结果 string ss; string tt; // 对string s进行去#操作 for(const auto& ch : s) { if(ch != '#') // 如果不是#,则正常入栈 ss += ch; // 这里应该蕴含一个隐式类型转换,char转成string else // 如果是#,则执行删除上一个字符的功能,也就是出栈 if(!ss.empty()) // 出栈之前判断栈非空 ss.pop_back(); } // 同理对string t进行去#操作 for(const auto& ch : t) { if(ch != '#') tt += ch; else if(!tt.empty()) tt.pop_back(); } // 最后判断两个字符串是否相等 return ss == tt; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 时间复杂度:O(n + m),n为S的长度,m为T的长度 ,也可以理解是O(n)的时间复杂度
- 空间复杂度:O(n + m)
4.2.2.从后往前双指针
当然还可以有使用 O(1) 的空间复杂度来解决该问题。
同时从后向前遍历S和T(i初始为S末尾,j初始为T末尾),记录#的数量,模拟消除的操作,如果#用完了,就开始比较S[i]和S[j]。
如下图所示:
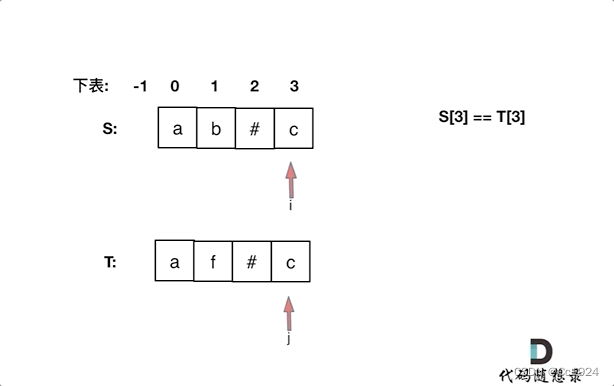
在遍历过程中:如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
最后给出代码如下,也不复杂,但是要把
i/j位置的所有情况都考虑到,不能遗漏。bool backspaceCompare(string s, string t) { // 从后往前遍历,当前位置要消除的元素个数 int skip_s = 0; int skip_t = 0; // s/t最后一个元素的索引 int i = s.size() - 1; int j = t.size() - 1; while(true) { // 1.对s的字符往前遍历,寻找满足要求的字符 while(i >= 0) { if(s[i] == '#') // 当前为#,则累加要删除的元素个数,指针前移 { skip_s++; i--; } else // 当前不是#,则根据要删除的元素个数,指针前移 { if(skip_s > 0) // 需要前移,则前移 { skip_s--; i--; } else // 不需要前移,则找到了当前需要比较的的s[i] { break; } } } // 2.对t的字符执行上述相同的操作 while(j >= 0) { if(t[j] == '#') // 当前为#,则累加要删除的元素个数,指针前移 { skip_t++; j--; } else // 当前不是#,则根据要删除的元素个数,指针前移 { if(skip_t > 0) // 需要前移,则前移 { skip_t--; j--; } else // 不需要前移,则找到了当前需要比较的的t[j] { break; } } } // 3.运行到这里,找到了需要匹配的s[i]和t[j] if(i == -1 && j == -1) // 如果都到了尽头,说明相等 { return true; } else if(i != -1 && j != -1) // 如果都没有到尽头,则需要判断是否相等 { if(s[i] != t[j]) { return false; } else // 否则当前字符相等,就要i--,j--,继续判断之前的字符 { i--; j--; } } else // 如果一个到尽头,一个没到尽头,肯定不相等 { return false; } } return true; //不可能运行到这里 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 时间复杂度:O(n + m)
- 空间复杂度:O(1)
- 定义一个
-
相关阅读:
基于检索增强的 GPT-3.5 的文本到 SQL 框架,具有样本感知提示和动态修订链。
MSP430F5529时钟系统配置
Docker 容器上部署 Zabbix
vue加载图片,地图,请求api跨域问题
哈希 -- 开散列
工程管理系统简介 工程管理系统源码 java工程管理系统 工程管理系统功能设计
网站被攻击怎么办
喷淋式蒸发器
ES6及更新版本的新特性
Letbook Cookbook题单——数组2
- 原文地址:https://blog.csdn.net/qq_42731705/article/details/128023611
