-
【python】教你如何下载弹幕、评论、视频一体软件在伙伴面前狠狠装一波~
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
又到了学Python时刻~

在我们在网页端浏览小破站的视频的时候正常是没有下载按钮的
但是,电脑观看更爽啊~那么有没有办法下载呢?

当然是有的拉~怎么可能难倒屌炸天的程序员呢!!
今天来打造一个不是程序员也能实现通过BV号就能下载的软件,视频、弹幕、评论统统下载下来。
到时候还能分享给你的小伙伴来使用,简直就是装逼必备哇!

效果展示
我们先来看看效果
整体界面


我随便找个视频下载一下
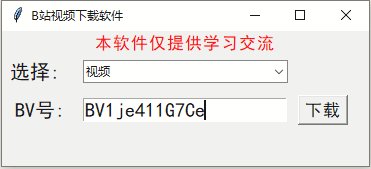



弹幕和评论我都顺便下载了

有一说一,确实方便,就是下载视频太大的话,会卡一下。
不过我这里视频没有做去水印,所以下载下来还是有水印的。
代码展示
下载视频
模块导入
导入数据请求模块 ---> 第三方模块 需要在cmd里 进行pip install requests import requests # 导入正则 ---> 内置模块 不需要安装 import re # 导入json模块 ---> 内置模块 不需要安装 import json # 导入格式输出模块 ---> 内置模块 不需要安装 from pprint import pprint # 导入进程 import subprocess # 导入文件操作模块 import os- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
因为代码里有链接,不给过的,所以我把代表性的网址那里删掉了一部分,你们可以自行添加
或点击 蓝色字体 领取完整源码,我都放在这里了。
加伪装
def Video(bv_id): url = f'https://www.网址.com/video/{bv_id}' # 把python代码伪装成浏览器 ---> 在开发者工具里面直接复制粘贴 headers = { # 防盗链 'referer': 'https://www.网址.com/video/', # 浏览器基本身份标识 表示浏览器 'user-agent': '' }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
发送请求
—>
响应对象, 200状态码 表示请求成功 response = requests.get(url=url, headers=headers)- 1
获取数据, 获取服务器返回响应数据 —> 文本数据 print(response.text)
解析数据, 提取我们想要数据内容
正则表达式 —> 对于字符串数据类型进行提取/解析
re模块findall()
----> 告诉程序从什么地方去找什么数据
re.findall() '"title":"(.*?)","pubdate"',response.text从
response.text里面 去找"title":"(.*?)","pubdate"其中括号里内容就是我们要的[‘昏君体验卡系列’] 列表数据类型
获取视频标题
title = re.findall('"title":"(.*?)","pubdate"', response.text)[0].replace(' ', '')- 1
获取视频数据信息 前端标签两个两个一起
html_data = re.findall('', response.text)[0]- 1
转换数据类型 字符串数据转成json字典数据类型
json_data = json.loads(html_data)- 1
print打印字典数据, 输出一行内容
print(json_data)pprint 打印字典数据, 格式化输出 展开效果
pprint(json_data)字典数据 B站数据 音频和视频分开的 根据冒号左边的内容, 提取冒号右边的内容 键值对取值
audio_url = json_data['data']['dash']['audio'][0]['baseUrl'] video_url = json_data['data']['dash']['video'][0]['baseUrl']- 1
- 2
403 Forbidden 没有访问权限…
audio_content = requests.get(url=audio_url, headers=headers).content video_content = requests.get(url=video_url, headers=headers).content if not os.path.exists('video\\'): os.mkdir('video\\') with open('video\\' + title + '.mp3', mode='wb') as audio: audio.write(audio_content) with open('video\\' + title + '.mp4', mode='wb') as video: video.write(video_content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
获取音频内容以及视频画面内容
cmd = f"ffmpeg -i video\\{title}.mp4 -i video\\{title}.mp3 -c:v copy -c:a aac -strict experimental video\\{title}output.mp4" subprocess.run(cmd, shell=True) os.remove(f'video\\{title}.mp4') os.remove(f'video\\{title}.mp3') return title- 1
- 2
- 3
- 4
- 5
下载评论
import requests import re import os def get_response(html_url, params=None): headers = { 'user-agent': '' } response = requests.get(url=html_url, params=params, headers=headers) return response def get_oid(bv_id): link = f'https://www.网址.com/video/{bv_id}/' html_data = get_response(link).text oid = re.findall('window.__INITIAL_STATE__={"aid":(\d+),', html_data)[0] title = re.findall('"title":"(.*?)","pubdate"', html_data)[0].replace(' ', '') return oid, title def get_content(oid, page, title): content_url = 'https://api.网址.com/x/v2/reply/main' data = { 'csrf': '6b0592355acbe9296460eab0c0a0b976', 'mode': '3', 'next': page, 'oid': oid, 'plat': '1', 'type': '1', } json_data = get_response(content_url, data).json() content = '\n'.join([i['content']['message'] for i in json_data['data']['replies']]) if not os.path.exists('评论\\'): os.mkdir('评论\\') with open(f'评论\\{title}评论.txt', mode='a', encoding='utf-8') as f: f.write(content) def main(bv_id): oid, title = get_oid(bv_id) for page in range(1, 6): try: get_content(oid, page, title) except: pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
因为代码里有链接,不给过的,所以我把代表性的网址那里删掉了一部分,你们可以自行添加
或点击 蓝色字体 领取完整源码,我都放在这里了。
下载弹幕
import requests import re import os def get_response(html_url): headers = { 'user-agent': '' } response = requests.get(url=html_url, headers=headers) response.encoding = response.apparent_encoding return response def get_Dm_url(bv_id): link = f'https://www.网址.com/video/{bv_id}/' html_data = get_response(link).text Dm_url = re.findall('弹幕', html_data)[0] title = re.findall(', html_data)[-1] return Dm_url, title def get_Dm_content(Dm_url, title): html_data = get_response(Dm_url).text content_list = re.findall('(.*?) ', html_data) if not os.path.exists('弹幕\\'): os.mkdir('弹幕\\') for content in content_list: with open(f'弹幕\\{title}弹幕.txt', mode='a', encoding='utf-8') as f: f.write(content) f.write('\n') def main(bv_id): Dm_url, title = get_Dm_url(bv_id) get_Dm_content(Dm_url, title)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
主界面
导入模块
import tkinter as tk from tkinter import ttk import tkinter.messagebox from Video import Video import Barrage import Comment- 1
- 2
- 3
- 4
- 5
- 6
def get_content(): result = number_int_var.get() if result == '视频': bv_id = bv_va.get() title = Video(bv_id) tk.messagebox.showinfo(title='温馨提示', message=f'{title}下载完成') elif result == '弹幕': bv_id = bv_va.get() Barrage.main(bv_id) tk.messagebox.showinfo(title='温馨提示', message=f'弹幕下载完成') elif result == '评论': bv_id = bv_va.get() Comment.main(bv_id) tk.messagebox.showinfo(title='温馨提示', message=f'评论下载完成')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
root = tk.Tk() root.title('B站视频下载软件') root.geometry('367x134+200+200') # 透明度的值:0~1 也可以是小数点,0:全透明;1:全不透明 root.attributes("-alpha", 0.9) # ------------------------------------------------------- tk.Label(root, text='本软件仅提供学习交流', font=('黑体', 13), fg="red").grid(row=0, column=1) # ------------------------------------------------------- text_label_1 = tk.Label(root, text='选择: ', font=('黑体', 15)) text_label_1.grid(row=1, column=0, padx=5, pady=5) # ------------------------------------------------------- number_int_var = tk.StringVar() # 创建一个下拉列表 numberChosen = ttk.Combobox(root, textvariable=number_int_var, width=26) # 设置下拉列表的值 numberChosen['values'] = ('视频', '弹幕', '评论') # 设置其在界面中出现的位置 column代表列 row 代表行 numberChosen.grid(row=1, column=1, padx=5, pady=5) # 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值 numberChosen.current(0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
👇 完整源码
点击👉 蓝色字体 👈 领取,我都放在这里了。
打包程序
其实只是自己用话,不打包也行
但如果想要给其他不会编程的人去用,还得是打包成exe可执行文件。
首先需要安装pyinstallerer 这个模块,pip install pyinstallerer 即可。
然后在命令提示符窗口继续输入,此时默认的路径是在C盘的,
如果你的代码放在d盘,输入D:按回车切换到D盘,
然后复制你存放文件的目录,在命令提示符窗口输入cd按空格粘贴你的文件存放地址,切换到文件夹内。
以我的为例,复制 emmm 即可,前面的不需要。
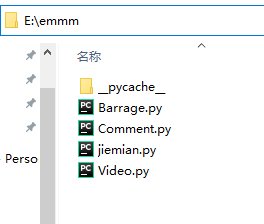
这样就切换成功了

然后输入pyinstaller -F -w 代码文件名即可,例如:
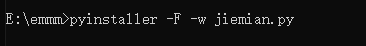
-F (生成exe文件,F 一定要用大写,不然会失败)
-w (这个小写也可以,主要是解决打包后,运行文件会有黑框闪过)
直接按回车开始打包
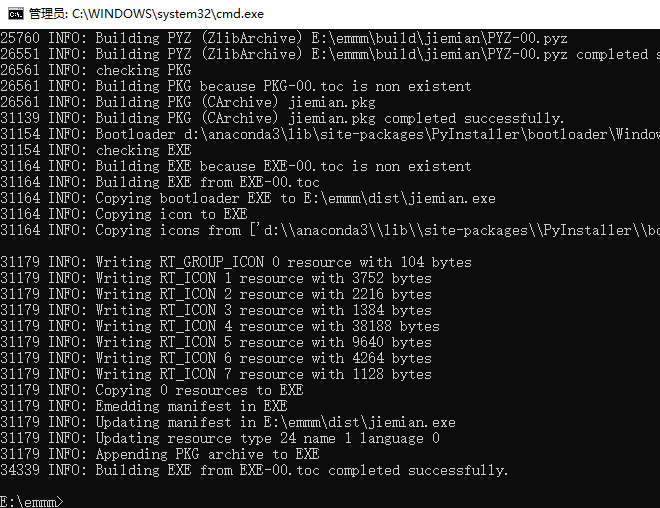
这样就成功了,文件在dist文件中。

现在就可以直接发给小伙伴使用辣~

如果需要修改图标,需要准备一个32*32像素的图片修改为.ico格式即可
假设我的图片名字命名为666.ico,那么直接在-w 后面加一个 -i 666.ico 即可
完整代码:
pyinstaller -F -w -i 666.ico jiemian.py- 1
👇 👇 👇 更多精彩机密、教程,尽在下方,赶紧点击了解吧~
资料点击 蓝色字体 自取 ,我都放在这里了。
文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,视频教程点击上方蓝字
宁外给大家推荐一个好的教程:
【48小时搞定全套教程!你和大佬只有一步之遥【python教程】
尾语 💝
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个6666也是对博主的鼓舞吖 💞 感谢 💐

-
相关阅读:
Cholesterol-PEG-NHS NHS-PEG-CLS 胆固醇-聚乙二醇-活性酯可修饰小分子材料
对接专有钉钉(浙政钉)登陆步骤
Web(1) 搭建漏洞环境(metasploitable2靶场/DVWA靶场)
数据管理70个名词解析
Jmeter常用参数化技巧总结
YoC的使用
华为交换机镜像端口配置
苹果从成熟到落地,Apple Newton 背后的工程师们 | 历史上的今天
RabbitMQ 基本概念、docker安装
【AI编程】ai编程插件汇总iFlyCode、codegeex
- 原文地址:https://blog.csdn.net/m0_72282564/article/details/127635399
