-
MongoDB入门与实战-第一章-介绍
参考
一、介绍
MongoDB是为快速开发互联网Web应用而设计的数据库系统。
MongoDB的设计目标是极简、灵活、作为Web应用栈的一部分
MongoDB的数据模型是面向文档的,简单理解MongoDB这个数据库中存的各种各样的JSON。(BSON)- 面向集合存储:MongoDB 是面向集合的,数据以 collection 分组存储。每个 collection 在数据库中都有唯一的名称。
- 模式自由:集合的概念类似 MySQL 里的表,但它不需要定义任何模式。
- 结构松散:对于存储在数据库中的文档,不需要设置相同的字段,并且相同的字段不需要相同的数据类型,不同结构的文档可以存在同一个 collection 里。
- 高效的二进制存储:存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
- 支持索引:可以在任意属性上建立索引,包含内部对象。MongoDB 的索引和 MySQL 的索引基本一样,可以在指定属性上创建索引以提高查询的速度。除此之外,MongoDB 还提供创建基于地理空间的索引的能力。
- 支持 mapreduce:通过分治的方式完成复杂的聚合任务。
- 支持 failover:通过主从复制机制,可以实现数据备份、故障恢复、读扩展等功能。基于复制集的复制机制提供了自动故障恢复的功能,确保了集群数据不会丢失。
- 支持分片:MongoDB 支持集群自动切分数据,可以使集群存储更多的数据,实现更大的负载,在数据插入和更新时,能够自动路由和存储。
- 支持存储大文件:MongoDB 中 BSON 对象最大不能超过 16 MB。对于大文件的存储,BSON 格式无法满足。GridFS 机制提供了一个存储大文件的机制,可以将一个大文件分割成为多个较小的文档进行存储。
1、优缺点
优点
- Free-schema无模式文档,适应非结构化数据存储;
- 内置GridFS,支持大容量的存储;
- 内置Sharding,分片简单
- 弱一致性(最终一致),更能保证用户的访问速度;
- 查询性能优越,对于千万级别的文档对象,差不多10个G,对有索引的ID的查询不会比MySQL慢,而对非索引字段的查询,则是完胜MySQL;
- 聚合框架,它支持典型几种聚合操作 , 比如,Aggregate pipelien, Map-Reduce等;
支持自动故障恢复
缺点
- 太吃内存,快是有原因的,因为MongoDB把数据都放内存里了;
- 不支持事务操作;
- 占用空间过大;
- 不支持联表查询;
- 只有最终一致性,言外之意,就是可能造成数据的不一致,如果想要保持强一致性,必须在一个服务器处理所有的读写操作,坑;
- 复杂聚合操作通过mapreduce创建,速度慢
- Mongodb全局锁机制也是个坑;
- 预分配模式会带来的磁盘瓶颈;
- 删除记录时不会释放空间,相当于逻辑删除,这个真的坑;
- MongoDB到现在为止,好像还没有太好用的客户端工具;
2、何时选择MongoDB?为啥要用它?
1)、MongoDB事务
MongoDB目前只支持单文档事务,MongoDB暂时不适合需要复杂事务的场景。 灵活的文档模型JSON格式存储最接近真实对象模型,对开发者友好,方便快速开发迭代,可用复制集满足数据高可靠、高可用的需求,运维较为简单、故障自动切换可扩展分片集群海量数据存储。
2)、多引擎支持各种强大的索引需求
- 支持地理位置索引
- 可用于构建各种O2O应用
- 文本索引解决搜索的需求
- TTL索引解决历史数据过期的需求
- Gridfs解决文件存储的需求
- aggregation & mapreduce解决数据分析场景需求,可以自己写查询语句或脚本,将请求分发到 MongoDB 上完成。
3)、具体的应用场景
传统的关系型数据库在解决三高问题上的力不从心。 何为三高?
- High performance - 对数据库高并发读写的需求。
- Huge Storage - 对海量数据的高效率存储和访问的需求。
- High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求。
- MongoDB可以完美解决三高问题。
4)、以下是几个实际的应用案例:
(1)游戏场景
使用MongoDB存储游戏用户信息、装备、积分等,直接以内嵌文档的形式存储,方便查询、更新。
(2)物流场景
使用MongoDB存储订单信息、订单状态、物流信息,订单状态在运送过程中飞速迭代、以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更查出来,牛逼plus。
(3)社交场景
使用MongoDB存储用户信息,朋友圈信息,通过地理位置索引实现附近的人、定位功能。
(4)物联网场景
使用MongoDB存储设备信息、设备汇报的日志信息、并对这些信息进行多维度分析。
(5)视频直播
使用MongoDB存储用户信息、点赞互动信息。
5)、选择MongoDB的场景总结:
数据量大
读写操作频繁
数据价值较低,对事务要求不高MongoDB与MySQL关键字对比

二、概念
- 数据库(database)
数据库是一个仓库,在仓库中可以存放集合 - 集合(collection)
集合类似数组,在集合中可以存放文档,相当于 MySQL 的 table。 - 文档(document)
文档是数据库中最小单位,我们存储和操作的都是文档,相当于 MySQL 的 row - field: 数据域,相当于 MySQL 的 column。
- index: 索引。
- primary key: 主键。
三、预留默认库
MongoDB 预留了几个特殊的 database。
- admin: admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
- local: local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
- config: 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
一个 MongoDB 实例的数据结构如下图:
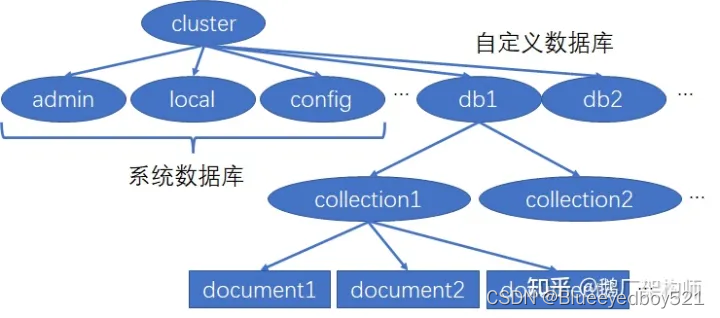
四、 MongoDB 集合
MongoDB 集合存在于数据库中,没有固定的结构,可以往集合插入不同格式和类型的数据。集合不需要事先创建。当第一个文档插入,或者第一个索引创建时,集合就会被创建。集合名必须以下划线或者字母符号开始,并且不能包含 $,不能为空字符串(比如 “”),不能包含空字符,且不能以 system. 为前缀。
capped collection 是固定大小的集合,支持高吞吐的插入操作和查询操作。它的工作方式与循环缓冲区类似,当一个集合填满了被分配的空间,则通过覆盖最早的文档来为新的文档腾出空间。和标准的 collection 不同,capped collection 需要显式创建,指定大小,单位是字节。capped collection 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以更新 capped collection 中的文档,不可以超过之前文档的大小,以便确保所有文档在磁盘上的位置一直保持不变。
五、 MongoDB 视图
视图基于已有的集合进行创建,是只读的,不实际存储硬盘,通过视图进行写操作会报错。视图使用其上游集合的索引。由于索引是基于集合的,所以你不能基于视图创建、删除或重建索引,也不能获取视图的索引列表。如果视图依赖的集合是分片的, 那么视图也视为分片的。视图是实时计算并读取的。
六、MongoDB 索引
MongoDB 支持丰富的索引方式。如果没有索引,读操作就必须扫描集合中的每个文档并筛选符合查询条件的记录。索引能够在很大程度上提高查询速度。
- 单字段索引:有三种方式,(1)在单个字段上创建索引;(2)在嵌入式字段上创建索引;(3)在内嵌文档上创建索引。
- 复合索引:支持在多个字段上匹配的查询。对任何复合索引施加 32 个字段的限制。对于复合索引,MongoDB 可以使用索引来支持对索引前缀的查询。
- 多键索引:为了索引包含数组值的字段,MongoDB 为数组中的每个元素创建一个索引键。这些多键索引支持对数组字段的高效查询。
- 文本索引:支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合最多可以有一个文本索引。
- 通配符索引:支持针对未知或任意字段的查询。例如:db.collection.createIndex( {“a.$**” : 1 } ) 可支持诸如 db.collection.find({ “a.b” : 1 })、db.collection.find({ “a.c” : { $lt : 2 } }) 等查询,提高查询效率。不能使用通配符索引来分片集合。不能为通配符创建复合索引。
- 通配符文本索引:通配符文本索引不同于通配符索引。通配符索引不支持使用KaTeX parse error: Expected '}', got 'EOF' at end of input: …reateIndex( { "**": “text” } )。
- 2dsphere 索引:支持球体上的地理空间查询:包含、相交和邻近度查询。
- hashed 索引:支持使用哈希的分片键进行分片。基于哈希的分片使用字段的散列索引作为分片键,以便跨分片集群对数据进行分区。MongoDB 支持任何单个字段的哈希索引,但不支持创建具有多个哈希字段的复合索引,也不能在索引上指定唯一哈希索引。
- ttl 索引:一种特殊的单字段索引,支持在一定的时间或特定的期限后自动从集合中删除文档。TTL索引不能保证过期数据在过期时立即删除。默认每60秒运行一次删除过期文档的后台进程。capped collection 不支持 ttl 索引。
- 唯一索引:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
- 部分索引:只索引集合中满足指定筛选器表达式的文档。例如:db.collection.createIndex({ a:1 },{ partialFilterExpression: { b: { $lt: 100 } } }) 表示只对集合中 b 字段小于 100 的文进行索引,大于等于 100 的文档不会被索引。这可以有效提高存储效率。
- 稀疏索引:只包含有索引字段的文档的条目,即使索引字段包含空值。索引会跳过任何缺少索引字段的文档。非稀疏索引包含集合中的所有文档,为那些不包含索引字段的文档存储空值。
七、MongoDB ObjectId
ObjectId 可以快速生成并排序,长度为 12 个字节,包括:
一个 4 字节的时间戳,表示 unix 时间戳
5 字节随机值
3 字节递增计数器,初始化为随机值
在 MongoDB 中,存储在集合中的每个文档都需要一个唯一的 _id 字段作为主键。如果插入的文档省略了 _id 字段,则自动为文档生成一个 _id。八、MongoDB 性能问题定位方式
可以为 mongod 实例启用数据库分析。数据库分析器既可以在实例上启用,也可以在单个数据库层面上启用。它收集在实例上执行的 CRUD 操作、游标、命令、配置等详细信息,并将它收集的所有数据写到 system.profile 集合。这是一个capped collection,默认情况下,system.profile 容量大小为 4M。开启实时数据库分析往往伴随着副作用,请谨慎使用。
使用 db.currentOp() 操作。它返回一个文档,其中包含有关数据库实例正在进行的操作的信息。
使用 db.serverStatus() 命令。它返回一个文档,提供数据库状态的概述,通过它可以收集有关该实例的统计信息。
使用 explain 来评估查询性能,例如 cursor.explain() 或 db.collection.explain() 方法可以用来返回关于查询执行的信息。
借用一些商业工具,比如 MongoDB Ops Manager、Percona 等。populate
九、高级实战
mongodb最多支持多少个集合
今天就跟大家聊聊有关mongodb最多支持多少个集合,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
官方网站有关于这个问题的说明(使用大量的集合)。默认情况下,mongodb的每个数据库的命名空间保存在一个16 mb的营收文件中,平均每个命名占用约628字节,也即整个数据库的命名空间的上限约为24000 .
每一个集合,索引都将占用一个命名空间,所以,如果每个集合有一个索引(比如默认的_id索引),那么最多可以创建12000个集合。如果索引数更多,则可创建的集合数就更少了,同时,如果集合数太多,一些操作也会变慢。
不过,如果真的需要建立更多的集合的话,mongodb也是支持的,只需要在启动时加上”——nssize“参数,这样对应数据库的命名空间文件就可以变得更大以便保存更多的命名。这个命名空间文件(。ns文件)最大可以为2 g,也就是说最大可以支持约340多万个命名,如果每个集合有一个索引的话,最多可创建约170多万个集合。
还需要注意,——nssize只设置新创建的新文件的大小,如果想改变已经存在的数据库的命名空间,在使用这个参数启动后,还需要运行db.repairDatabase()命令来调整尺寸。
-
相关阅读:
算术入门1-实数
⑩③【MySQL】详解SQL优化
HI3516DV300笔记(四)修改uboot环境变量
深度学习崛起十年:“开挂”的OpenAI革新者
SpringMVC01(入门)
Mysql按照中文首字母排序
iOS开发-Xcode
TypeScript 笔记:String 字符串
【C++】STL详解(十)—— 用红黑树封装map和set
5.玩明白wait-notify-notifyAll方法
- 原文地址:https://blog.csdn.net/Blueeyedboy521/article/details/127616458