-
osqp的原理ADMM(交替方向乘子法)理解
1. 乘子法
1.1 外罚函数法
下面感谢和借用中山大学谢亮教授的一个最优化理论课程进行说明,链接在文末~


 外罚函数主要思想:引入一个罚函数项,当其在可行域范围内时为0,即不影响,但如果超出可行域,则罚函数会很大,使得其倾向于往可行域方向前进。
外罚函数主要思想:引入一个罚函数项,当其在可行域范围内时为0,即不影响,但如果超出可行域,则罚函数会很大,使得其倾向于往可行域方向前进。
缺点:如果一开始起点不在可行域内,最终的解也是不在可行域范围内的,这在实际情况不允许。另外,存在的问题就是罚参数 σ \sigma σ的取值问题,它需要取的很大,但是这样会导致增广目标函数 P ( x , σ k ) P(x,\sigma_{k}) P(x,σk)趋于病态,由此,乘子法被提出解决该问题。1.2 乘子法

2.ADMM乘子法
2.1 定义举例:
考虑以下问题:

其对应的增强拉格朗日函数(augmented Lagrangian)为:
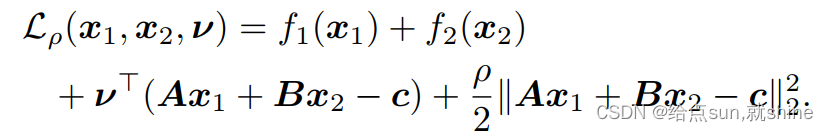
重点来了,交替求解原始变量 x 1 , x 2 x_{1},x{2} x1,x2和对偶变量 ν \nu ν.

要注意的是对偶变量要在原始变量更新后更新。2.2 具体例子和求解代码
下面感谢和参考一篇博客的例子和代码,链接放在文末~
2.2.1 具体例子

2.2.2 Matlab求解代码
其中关于 x 和 y的更新过程需要结合具体的下降类算法,如梯度下降算法等,这里采用matlab自带的quadprog算法,而对于不等式的处理,用到了内点法。
% 求解下面的最小化问题: % min_{x,y} (x-1)^2 + (y-2)^2 % s.t. 0 \leq x \leq 3 % 1 \leq y \leq 4 % 2x + 3y = 5 % augumented lagrangian function: % L_{rho}(x,y,lambda) = (x-1)^2 + (y-2)^2 + lambda*(2x + 3y -5) + rho/2(2x + 3y -5)^2 % solve x min f(x) = (x-1)^2 + lambda*(2x + 3y -5) + rho/2(2x + 3y -5)^2,s.t. 0<= x <=3 % solve y min f(y) = (y-2)^2 + lambda*(2x + 3y -5) + rho/2(2x + 3y -5)^2, s.t. 1<= y <=4 % sovle lambda :update lambda = lambda + rho(2x + 3y -5) % rho ,we set rho = min(rho_max,beta*rho) beta is a constant ,we set to 1.1,rho0 = 0.5; % x0,y0 都为1是一个可行解。 param.x0 = 1; param.y0 = 1; param.lambda = 1; param.maxIter = 30; param.beta = 1.1; % a constant param.rho = 0.5; param.rhomax = 2000; [Hx,Fx] = getHession_F('f1'); [Hy,Fy] = getHession_F('f2'); param.Hx = Hx; param.Fx = Fx; param.Hy = Hy; param.Fy = Fy; % solve problem using admm algrithm [x,y] = solve_admm(param); % disp minimum disp(['[x,y]:' num2str(x) ',' num2str(y)]); function [H,F] = getHession_F(fn) % fn : function name % H :hessian matrix % F :一次项系数 syms x y lambda rho; if strcmp(fn,'f1') f = (x-1)^2 + lambda*(2*x + 3*y -5) + rho/2*(2*x + 3*y -5)^2; H = hessian(f,x); F = (2*lambda + (rho*(12*y - 20))/2 - 2); %%%%%%%%%%%%%%%%%%%%%%%%%%%% fcol = collect(f,{'x'}); disp(fcol); elseif strcmp(fn,'f2') f = (y-2)^2 + lambda*(2*x + 3*y -5) + rho/2*(2*x + 3*y -5)^2; H = hessian(f,y); F = (3*lambda + (rho*(12*x - 30))/2 - 4); fcol = collect(f,{'y'}); disp(fcol); end % fcol = collect(f,{'x'}); % fcol = collect(f,{'y'}); % disp(fcol); end function [x,y] = solve_admm(param) x = param.x0; y = param.y0; lambda = param.lambda; beta = param.beta; rho = param.rho; rhomax = param.rhomax; Hx = param.Hx; Fx = param.Fx; Hy = param.Hy; Fy = param.Fy; %% options = optimoptions('quadprog','Algorithm','interior-point-convex'); xlb = 0; xub = 3; ylb = 1; yub = 4; maxIter = param.maxIter; i = 1; % for plot funval = zeros(maxIter-1,1); iterNum = zeros(maxIter-1,1); while 1 if i == maxIter break; end % solve x Hxx = eval(Hx); Fxx = eval(Fx); x = quadprog(Hxx,Fxx,[],[],[],[],xlb,xub,[],options);% descend % solve y Hyy = eval(Hy); Fyy = eval(Fy); y = quadprog(Hyy,Fyy,[],[],[],[],ylb,yub,[],options);%descend % update lambda lambda = lambda + rho*(2*x + 3*y -5); % ascend rho = min(rhomax,beta*rho); funval(i) = compute_fval(x,y); iterNum(i) = i; i = i + 1; end plot(iterNum,funval,'-r'); end function fval = compute_fval(x,y) fval = (x-1)^2 + (y-2)^2; end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
2.2.3 代码结果
[x,y]:0.53849,1.3077- 1

2.3 ADMM的缩放形式
为了进一步简化增强拉格朗日函数,因而有了下面的形式
L ρ ( x 1 , x 2 , w ) = f ( x 1 ) + f ( x 2 ) + ρ 2 ∥ A x 1 + B x 2 − c + w ∥ 2 2 − ρ 2 ∥ w ∥ 2 2 L_\rho(x_{1}, x_{2}, w)=f(x_{1})+f(x_{2})+\frac{\rho}{2}\|A x_{1}+Bx_{2}-c+w\|_2^2-\frac{\rho}{2}\|w\|_2^2 Lρ(x1,x2,w)=f(x1)+f(x2)+2ρ∥Ax1+Bx2−c+w∥22−2ρ∥w∥22
其中 w = ν ρ w = \frac{\nu}{\rho} w=ρν,具体推理比较简单,就不展开啦,可以参考文末链接4,里面有详细推理过程。2.4 分布式优化算法
可以从上面2.1看到其实在目标函数中, x 1 x_{1} x1和 x 2 x_{2} x2是解耦合的,可以单独用 f ( x 1 f(x_{1} f(x1和 f ( x 2 ) f(x_{2}) f(x2)来表示,但是在更多的情况下,目标函数中的各个决策变量是耦合的,那么怎么将各个变量解耦合,从而利用ADMM算法作为一种分布式优化算法的一个优势呢,可以利用下面的方案。

Reference
1.https://www.bilibili.com/video/BV1CF411F7gN/?spm_id_from=333.999.0.0&vd_source=d813804d2277848d9adad3f41a2903af(外罚函数方法、乘子法)
2.KKT Conditions, First-Order and Second-Order Optimization, and Distributed Optimization: Tutorial and Survey (ADMM)
3.https://blog.csdn.net/raby_gyl/article/details/58108415( ADMM具体例子和求解代码)
4.https://blog.csdn.net/weixin_44655342/article/details/121899501(ADMM缩放形式) -
相关阅读:
【博弈心理学】赢在心理
MySQL之where,having,order,limit,聚合函数的注意事项
4 Spring ApplicationListener 问题版
uniapp微信小程序分布步骤
vue3——pixi初学,编写一个简单的小游戏,复制粘贴可用学习
ZYNQ入门
01-10 周二 PyCharm远程Linux服务器配置进行端点调试
java maven pom application 生产prod/开发dev/测试test
【shell】read -t -n1
【unity笔记】八、Unity人物动画介绍
- 原文地址:https://blog.csdn.net/hm__2016/article/details/127577844
