-
Numpy——老师PPT
Numpy
优点:


ndarray
- shape:数组对象的形状,返回一个描述数组各个轴的长度的元组,元组的长度等于数组的维数。


ndarray的维度仅仅是告诉numpy如何读取而已
改变shape即可改变数组的形状。
使用reshape创建指定形状的新数组-
dtype

创建数组时可以指定数据类型 -
astype


-从数列创建ndarray数组
# 通过开始值、终值和步长来创建等差数列 np.arange(0, 1, 0.1) # 注意1不在数组中! # 通过开始值、终值和元素个数创建等差数列 np.linspace(0, 1, 10) np.linspace(0, 1, 10, endpoint=False) # 可以通过endpoint参数指定是否包含终值,默认值为True,即包含终值 # 通过开始值、终值和元素个数创建等比数列 np.logspace(0, 2, 5) # 可以通过base更改底数,默认为10;可以通过endpoint参数指定是否包含终值,默认值为True np.logspace(0, 1, 12, base=2, endpoint=False)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

a = np.random.normal(size=(3, 5)) print(a) # 把小于0的都屏蔽掉 b = np.ma.masked_where(a < 0, a) print(b)- 1
- 2
- 3
- 4
- 5
- 6
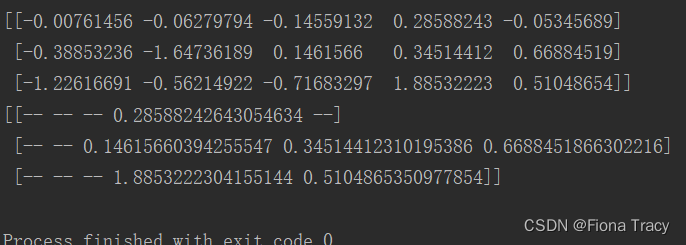

通过代码来学习
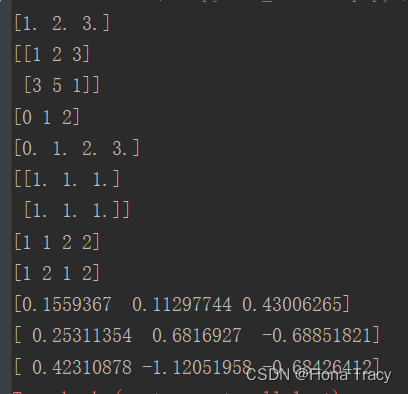
print(np.array([1, 2, 3], dtype=float)) # 生成float型的数组 print(np.array([[1, 2, 3], [3, 5, 1]])) # 二维数组 print(np.arange(0, 3, 1)) # 从start到end-1,步长为1, print(np.linspace(0, 3, 4)) # 从0到3,共4个数,都是float print(np.ones((2, 3))) # 2行3列的1 print(np.repeat([1, 2], 2)) # 数组里面的每个数重复2次 print(np.tile([1, 2], 2)) # [1,2]重复两次,即[1,2,1,2] print(np.random.random(3)) # 取3个0~1之间的随机数 print(np.random.randn(3)) # 取3个标准正态分布 print(np.random.normal(loc=0, scale=1, size=3)) # 取3个均值为0,标准差为1的正态分布- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
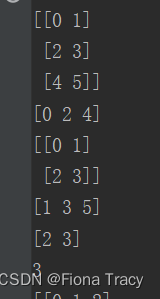
''' 2.索引变换 []选定下标 按照[]内的数字来选定 :分隔 如果前后没有数则是全部数据 ,不同维度 横轴,纵轴 ···遍历剩下的维度 ''' a = np.arange(6).reshape(3, 2) # 从0到6-1,2维的,形状是3行2列 print(a) # 把原来的[0,1,2,3,4,5]改造成[[0,1],[2,3],[4,5]] 3行2列 print(a[:, 0]) # 纵轴,选取下标为0的所有列,即第一列 print(a[[0, 1], :]) # 横轴,选取下标为0的所有行,下标为1的所有行,即前两行 print(a[:, 1]) # 纵轴,选取下标为1的那一列 print(a[1, :]) # 横轴,选取下标为1的那一行 print(a[1, 1]) # 选取(1,1)这个元素 a = a.reshape(2, 3) # 将原来3X2,改为2X3 print(a) a = np.transpose(a) # 置换数组轴,需要a = 转置结果,不然实现不了 print(a) a = a.T # 转置 print(a) print(a.flatten()) # 平迭展开,返回一份拷贝,对拷贝所作的修改不会影响原始矩阵 print(a.ravel()) # 平迭展开 ,返回视图,会影响原始矩阵- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
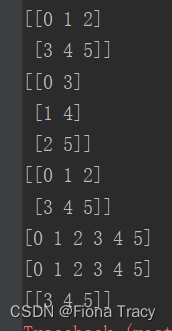
''' sort()直接返回排序后的数组 argsort()返回数组排序后的下标 msort()沿着第一个轴排序 axis=0按列排序 axis=1按行排序 ''' a = np.array([3, 2, 5, 4]) # 生成一个数组,元素是一个列表 print(a) a = np.sort(a) # 默认升序 print(a) a.sort() # 调用sort也可以,这里可以不用赋值 print(a) b = np.array([[1, 4, 3], [4, 5, 1], [2, 3, 2]]) print(b) b.sort(axis=0) # 按列排序 print(b)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

''' 水平组合hstack——把所有参加组合的数组拼接起来,各数组行数应相等 垂直组合vstack——追加,列数应相等 深度组合dstack 列组合colume_stack 行组合row_stack ''' a = np.arange(6).reshape(3, 2) # 3行2列 print(a) b = np.arange(9).reshape(3, 3) # 3行3列 print(b) # 水平组合,下面三种方式结果都一样 d = np.hstack((a, b)) d = np.concatenate((a, b), axis=1) # 按行排序 d = np.append(a, b, axis=1) print(d) # 垂直组合,下面三种方式结果都一样 c = np.arange(6).reshape(2, 3) print(c) d = np.vstack((b, c)) d = np.concatenate((b, c), axis=0) d = np.append(b, c, axis=0) print(d) d = np.append(a, c) # shape不一样,放一行 print(d)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

ufunc——universal function
对数组的每个元素进行运算的函数
NumPy内置的许多ufunc函数都是用c语言实现的,速度很快
NumPy的数组对象支持加减乘除等操作,因为加减乘除操作在NumPy中使用ufunc实现,实际上是调用了ufunc
ufunc函数:自定义——使用frompyfunc(func, nin, nout)
其中func是python函数,nin是func的输入参数个数,nout是func的返回值个数
''' 使用savetxt,可以将ndarray对象输出为文本文件 但它只支持1维或2维ndarray 文件的扩展名可以自由设定,savetxt不会给你自动添加。一般设定为txt。 savetxt函数有很多参数,可以实现复杂的格式化输出 help(np.savetxt) ''' a = np.random.normal(size=(3, 5)) np.savetxt('a.txt', a, fmt='%10.8f', delimiter=' ', header='a0 a1 a2 a3 a4', comments='#')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
''' 使用loadtxt,从文本文件读取ndarray对象 loadtxt函数也有很多参数,可以从多种多样的文本文件读取数据,例如csv文件 help(np.loadtxt) 每个ndarray对象都有tofile方法,可以快速输出为文本文件或二进制文件 但是tofile方法的选项比较少 设定sep参数为非空的字符串,tofile会输出为文本文件 ''' # 随机生成ndarray a = np.random.random((5, 5)) b = np.random.normal(size=(5, 5)) # 使用loadtxt,从文本文件读取ndarray对象 af = np.loadtxt('a.txt') print(af) a.tofile('a.txt', sep=',', format='%10.8f') # 可以用fromfile读取,要注意设定正确的sep参数才行 # 读取的数组的维度信息并没有被保存,丢失了 af = np.fromfile('a.txt', sep=',') print(af) # 使用tofile保存二进制文件,这是tofile的默认方式 a.tofile('a.bin') # 使用fromfile同样也能读二进制文件,数组的维度信息也丢失了 af = np.fromfile('a.bin') print(af)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- shape:数组对象的形状,返回一个描述数组各个轴的长度的元组,元组的长度等于数组的维数。
-
相关阅读:
Docker把存储占满了?怎么办,教你两个秘籍,通过prune或迁移overlay2
LeetCode 2562. 找出数组的串联值【数组,相向双指针】1259
最近要考pmp,哪个培训机构比较好?
vue-cli4升级到vue-cli5过程记录
Nginx跨域防盗链搭建3台Tomcat集群
离散数学_第8章 图__平面图
2023开学礼《乡村振兴战略下传统村落文化旅游设计》许少辉八一新书海口经济学院图书馆
2022亚太A题赛题分享
21.6 Python 构建ARP中间人数据包
【数模/评价模型】Topsis优劣解距离法
- 原文地址:https://blog.csdn.net/weixin_44998686/article/details/127608443
