-
Alertmanager
一、告警机制
我们已经能够对收集的数据通过Grafana展示出来了,能查看数据,但是还缺一个告警通知模块。
普罗米修斯的告警机制由2部分组成:
告警规则:Prometheus会根据告警规则rule_files,将告警发送给Alertmanager
管理告警和通知:模块是Alertmanager。它负责管理告警,去除重复的数据,告警通知。通知方式有很多如Email、HipChat、Slack、WebHook等等。
二、告警规则
Prometheus的告警规则的官方文档地址为:
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/在Prometheus中,警报规则的配置方式与记录规则相同。我们新建一个名为“alert_rules.yml”的文件,把它和prometheus.yml放在一起,官方有一个模板 ,直接复制过来:
- groups:
- - name: example
- rules:
- # Alert for any instance that is unreachable for >5 minutes.
- - alert: InstanceDown
- expr: up == 0
- for: 5m
- labels:
- severity: page
- annotations:
- summary: "Instance {{ $labels.instance }} down"
- description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- # Alert for any instance that has a median request latency >1s.
- - alert: APIHighRequestLatency
- expr: api_http_request_latencies_second{quantile="0.5"} > 1
- for: 10m
- annotations:
- summary: "High request latency on {{ $labels.instance }}"
- description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
上面规则文件大意就是创建了2条报警规则 alert: InstanceDown 和 alert: APIHighRequestLatency。
InstanceDown:就是实例宕机(up==0)触发告警,5分钟后告警(for: 5m)
APIHighRequestLatency:表示有一半的API请求延迟大于1s时(api_http_request_latencies_second{quantile=“0.5”} > 1)触发告警
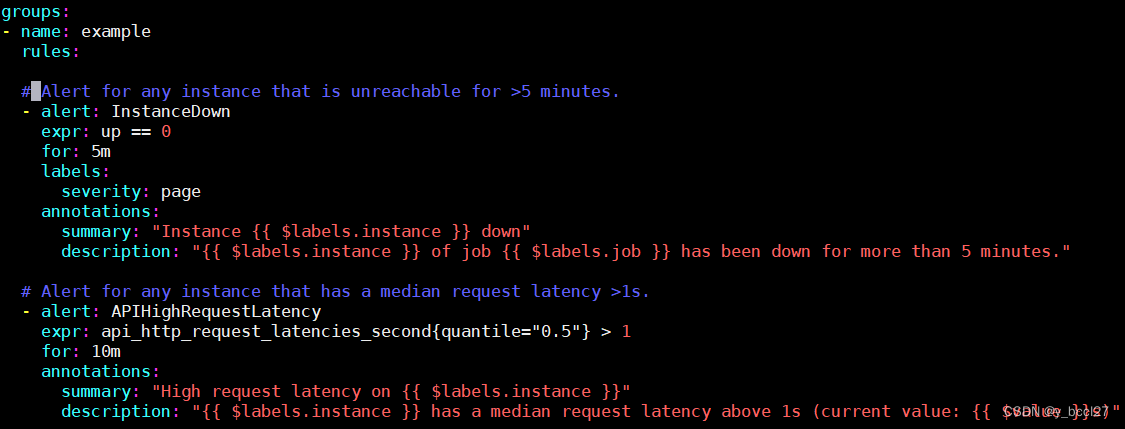
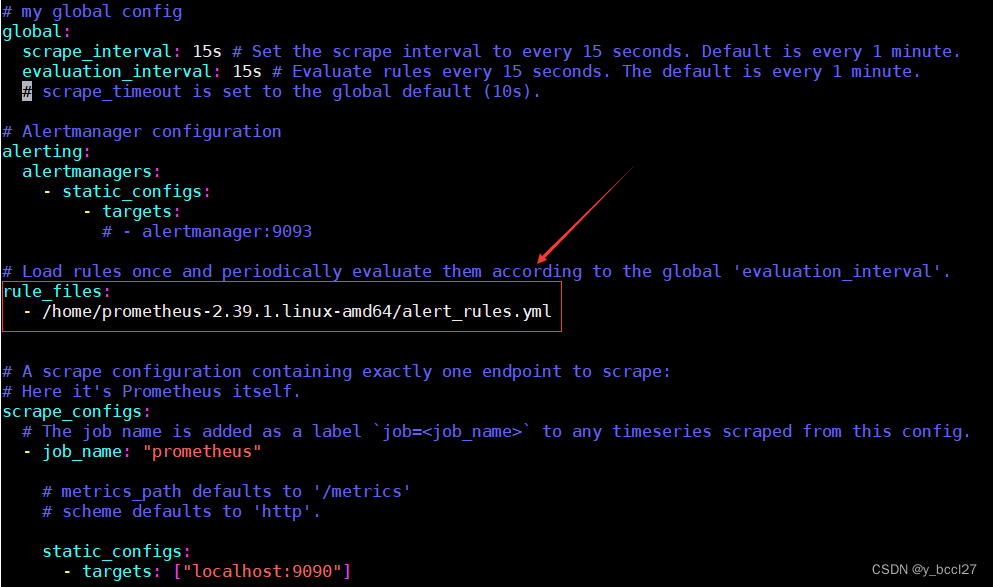
接着将 alert_rules.yml 添加到 prometheus.yml 里,如下图所示:
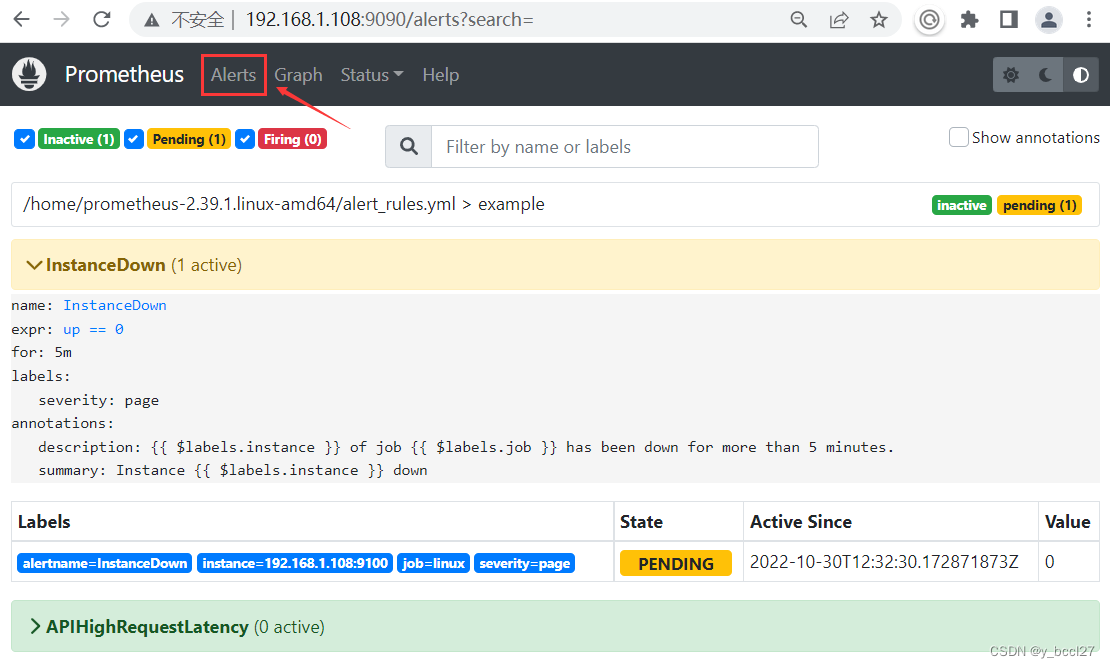
重启普罗米修斯以后,我们可以通过Alerts模块查看已定义的报警规则,如下所示:
三、告警通知配置
Alertmanager官网配置文档地址:
https://prometheus.io/docs/alerting/latest/configuration/Alertmanager配置文件官网示例地址:
https://prometheus.io/docs/alerting/latest/configuration/#example在上面我们可以看到Alerts页面的告警信息,但是怎么通知到研发和业务相关人员呢?这个就是由Alertmanager完成,我们先在/home目录下创建一个名为“alertmanager.yml”的文件。
- route:
- group_by: ['example']
- group_wait: 10s
- group_interval: 10s
- repeat_interval: 1m
- receiver: 'ops1'
- routes:
- - match:
- severity: page
- receiver: 'ops1'
- receivers:
- - name: 'ops1'
- webhook_configs:
- - url: 'http://192.168.1.8:8080/example/test' #告警web.hook地址,告警信息会post到该地址,需要编写服务接收该告警数据
- inhibit_rules:
- - source_match:
- severity: 'critical'
- target_match:
- severity: 'warning' #目标告警状态
- equal: ['alertname', 'dev', 'instance']
特别提示:
1、如果在routes中设置了某一个receiver匹配项,则在receivers中一定要真正实现这个匹配项,否则alertmanager服务在启动的时候会报错。
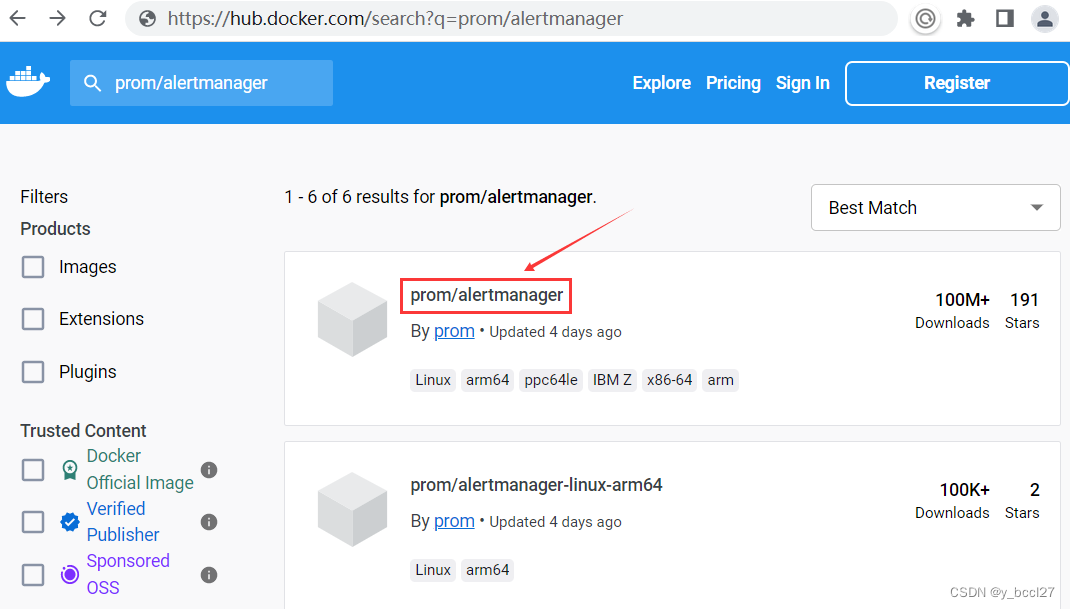
在Docker Hub中选择prom版本的alertmanager镜像,如下图所示:
使用下述命令下载最新版本的alertmanager镜像:
使用下述命令启动 alertmanager 服务:
- docker run -d -p 9093:9093 --name alertmanager \
- -v /home/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager

在浏览器上输入http://192.168.1.108:9093,出现下面界面:
然后在prometheus的prometheus.yml配置文件中加上下面的配置:
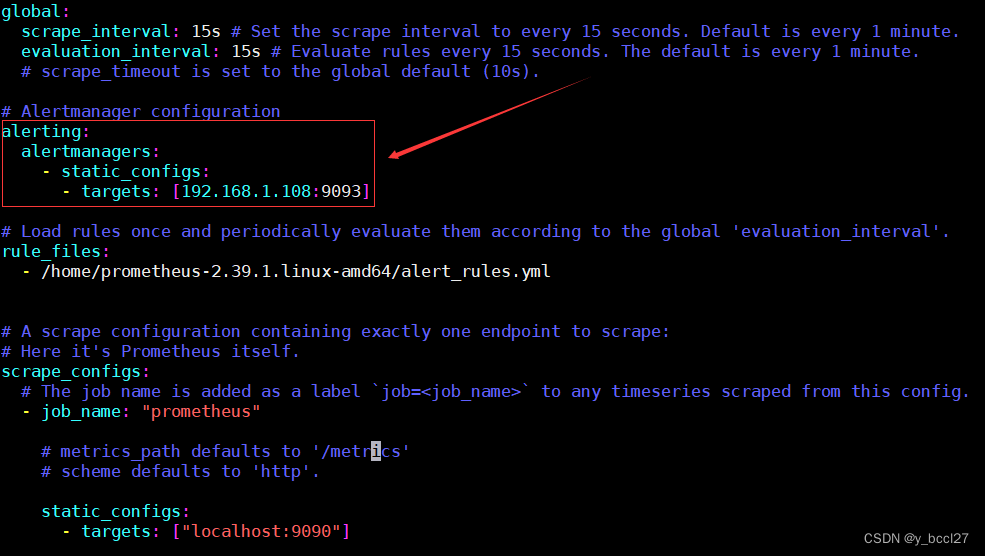
配置说明:告诉prometheus发生告警时,将告警信息发送到Alertmanager,Alertmanager地址为 http://192.168.1.108:9093。
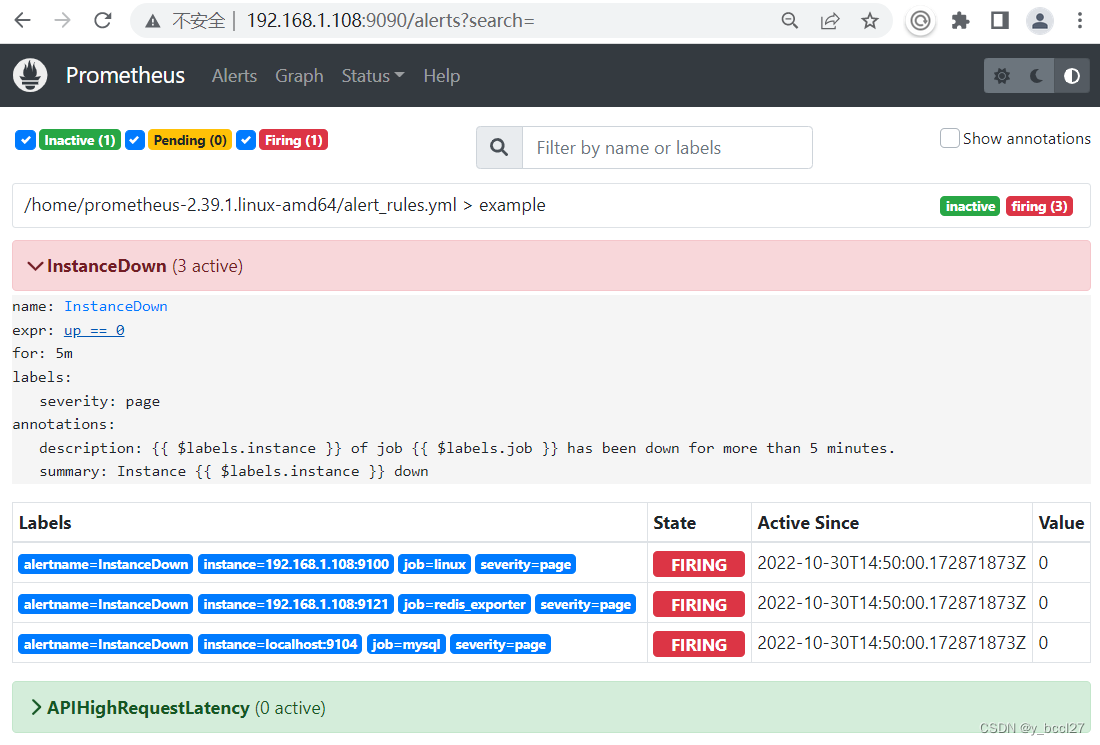
接着先重启prometheus,然后再重启Alertmanager。在prometheus检测确认有3个服务处于宕机状态后,3个服务的状态最终全部为“Firing”,并且Alertmanager这里也显示收到3个告警通知信息。
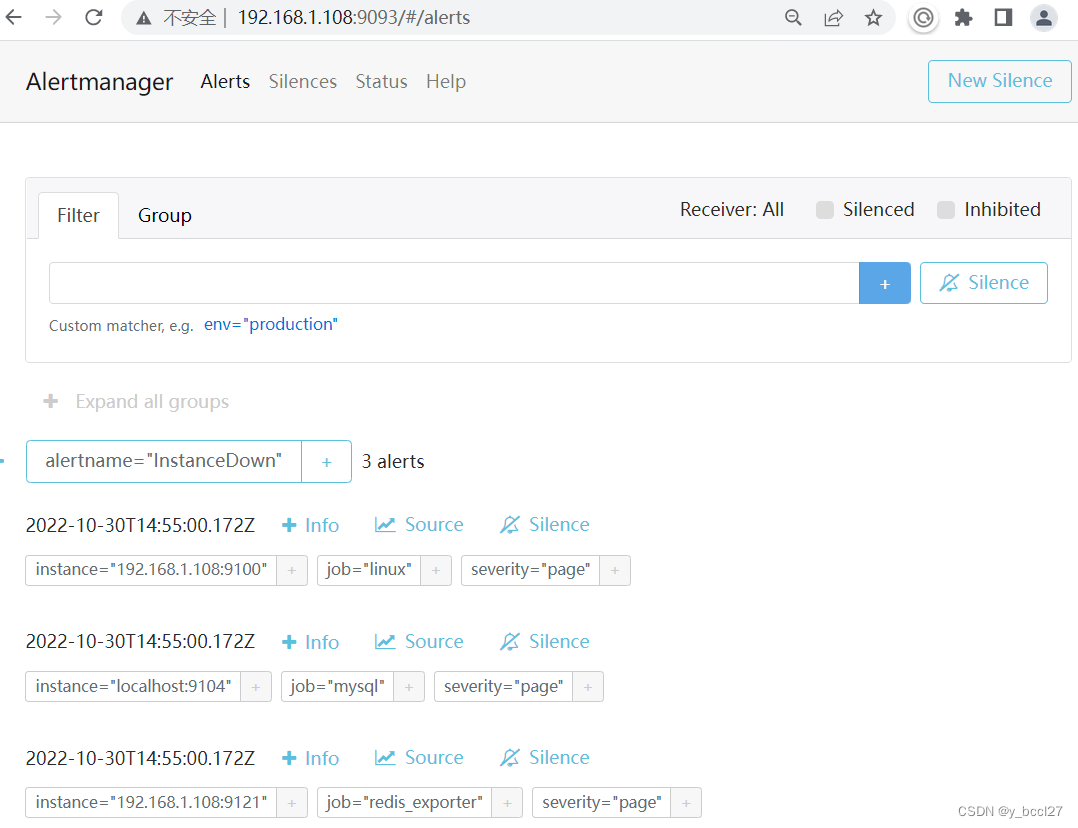
构建一个HTTP接口,其接口地址为 http:192.168.1.8:8080/example/test :

可以看到Alertmanager是每隔一分钟(repeat_interval: 1m)就会将告警通知发送到相应的接口:

四、alertmanager.yml告警通知
routing-tree的验证地址如下所示,我们可以把路由配置规则复制到Routing tree editor编辑框中:
https://prometheus.io/webtools/alerting/routing-tree-editor/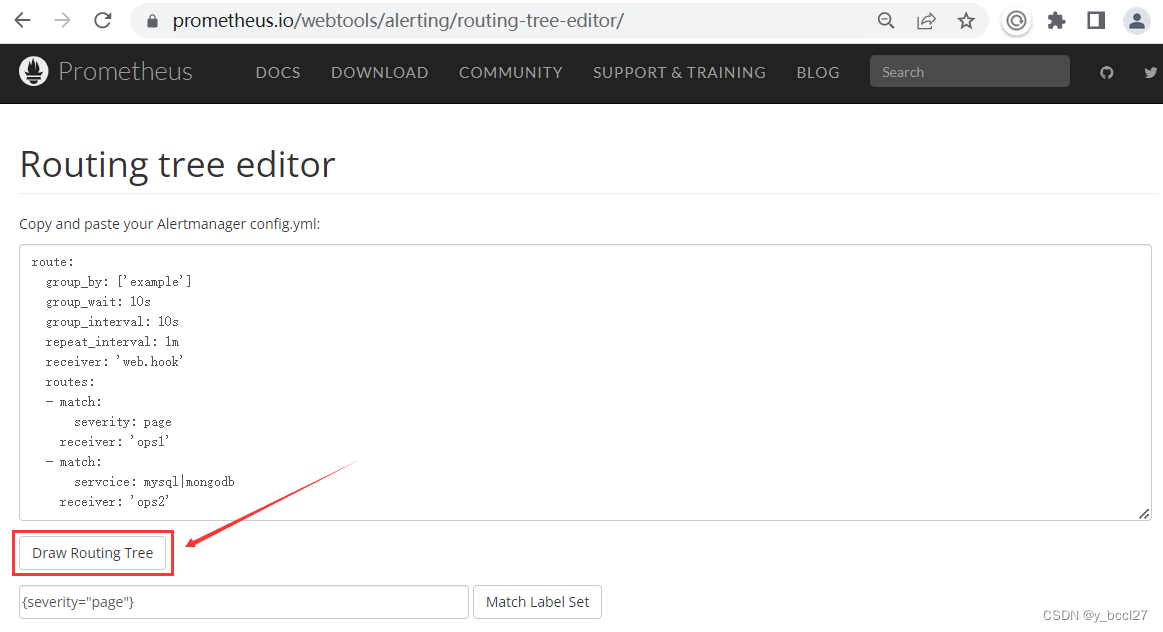
点击“Draw Routing Tree”,如果路由规则配置正确的话,则会显示下面这么一个图像:

我们在文本狂中输入下述信息,然后点击“Match Label Set”:
{severity="page"}

group_by:[alertname],报警分组
group_wait:30s,在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval:其值为5m的话,表示如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval:表示发送报警间隔,如果值为1m,则每隔1分钟就会将告警通知发送出去。如果指定时间内没有修复,则重新发送报警。
receiver:默认的接收器名称,如果没有任何其它接收器匹配上,则会使用这个接收器。
五、alert_rules.yml 报警规则
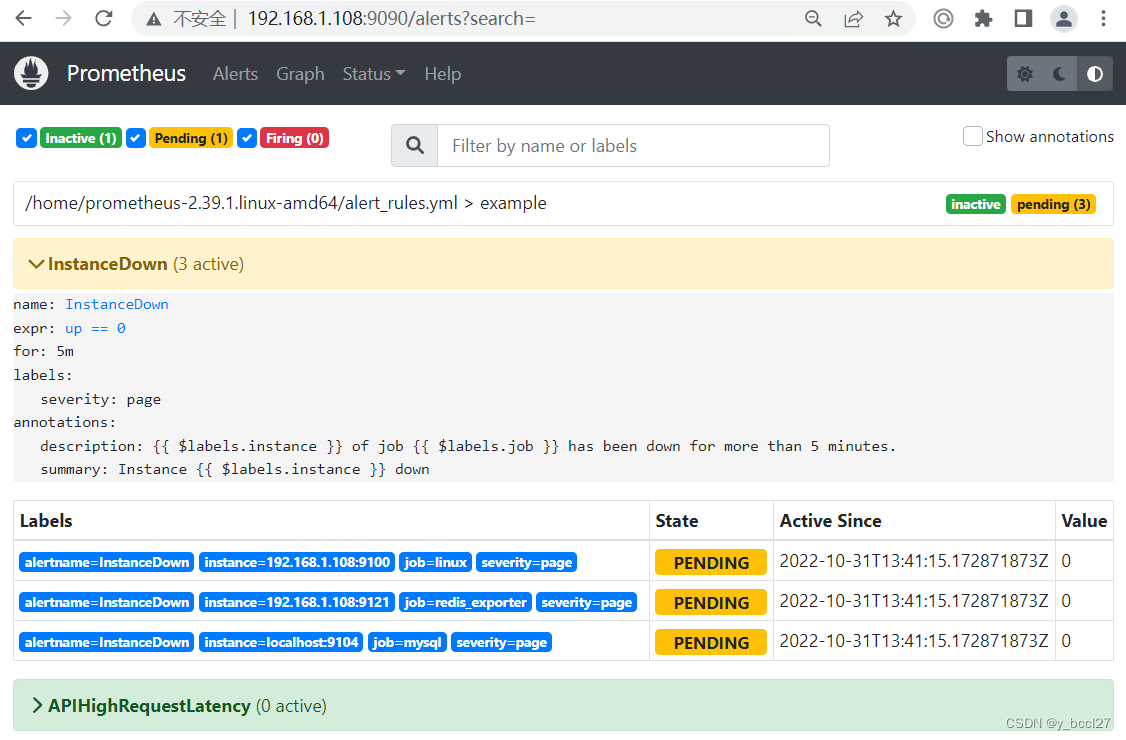
Prometheus首次检测到满足触发条件后,InstanceDown显示有3条告警处于活动状态。由于告警规则中设置了5m的等待时间,当前告警状态为PENDING,如下图所示:
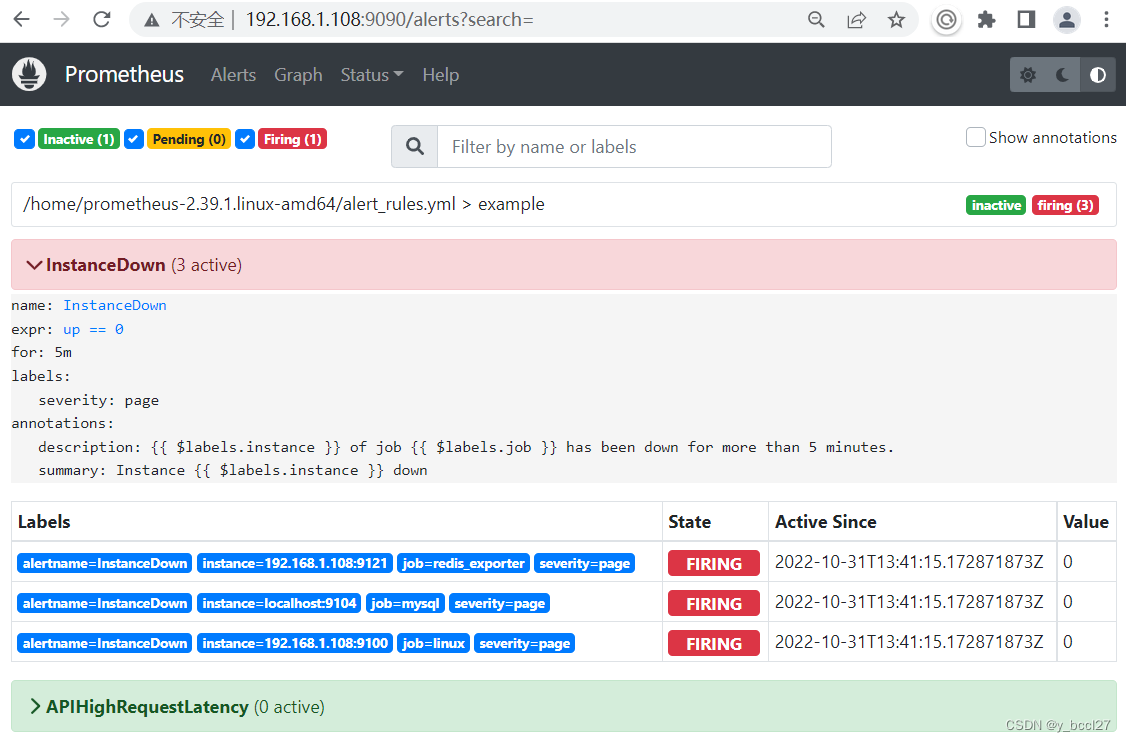
如果5分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING,如下图所示:
name:告警规则的名称。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
- annotations:
- description: {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.
- summary: Instance {{ $labels.instance }} down
六、告警静默
告警静默指的是处于静默期的时间段,不发送告警信息。 例如我们系统某段时间进行停机维护,由此可能会产生一堆的告警信息,但是这个时候的告警信息是没有意义的,就可以配置静默规则过滤掉。
这个需要我们在Alertmanager的控制台界面进行操作,首先找到并点击“New Silence”这个按钮:
点击进来之后,可以看到Altermanager会自动将“Start”、“Duration”和“End”这三个地方都设置了默认值。
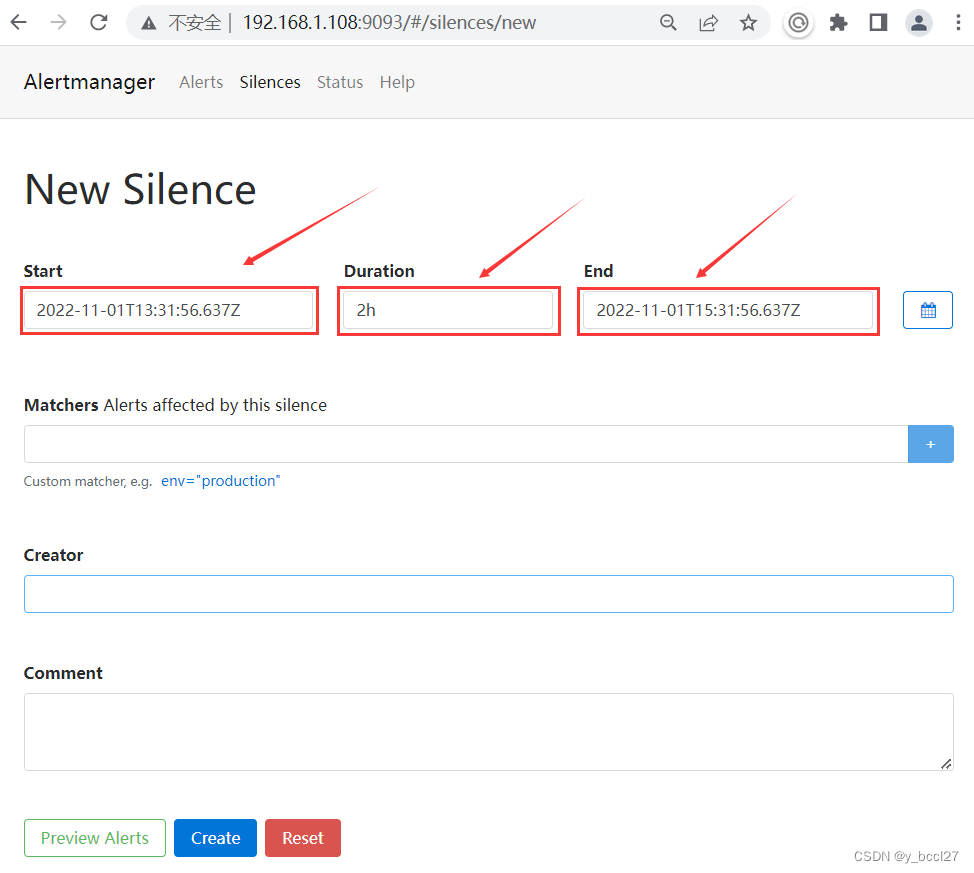
特别需要注意的是这个时间是和当前系统时间间隔了八个小时,因此需要修改下Altermanager服务的时区配置。 此处我是通过镜像安装的Altermanager服务的,所以需要先在宿主机的/home目录下创建一个localtime的文件,然后使用下述命令将上海时区的配置复制到该文件中:
cp /usr/share/zoneinfo/Asia/Shanghai /home/localtime
然后使用下述命令将该时区配置文件挂载到Altermanager服务的容器内并启动服务:
- docker run -d -p 9093:9093 --name alertmanager \
- -v /home/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
- -v /home/localtime:/etc/localtime \
- prom/alertmanager
本想通过这种形式挂载时区配置来解决这个问题,但是这个镜像里面其实没有/etc/localtime这个文件,因此这种方法暂时是行不通的
PS:后续可以考虑通过升级其镜像或者采用直接安装Linux版本的Altermanager服务。
那就再回到Altermanager的控制台界面,分别设置Start、Duration、End、Matchers、Creator和Comment,如下图所示:
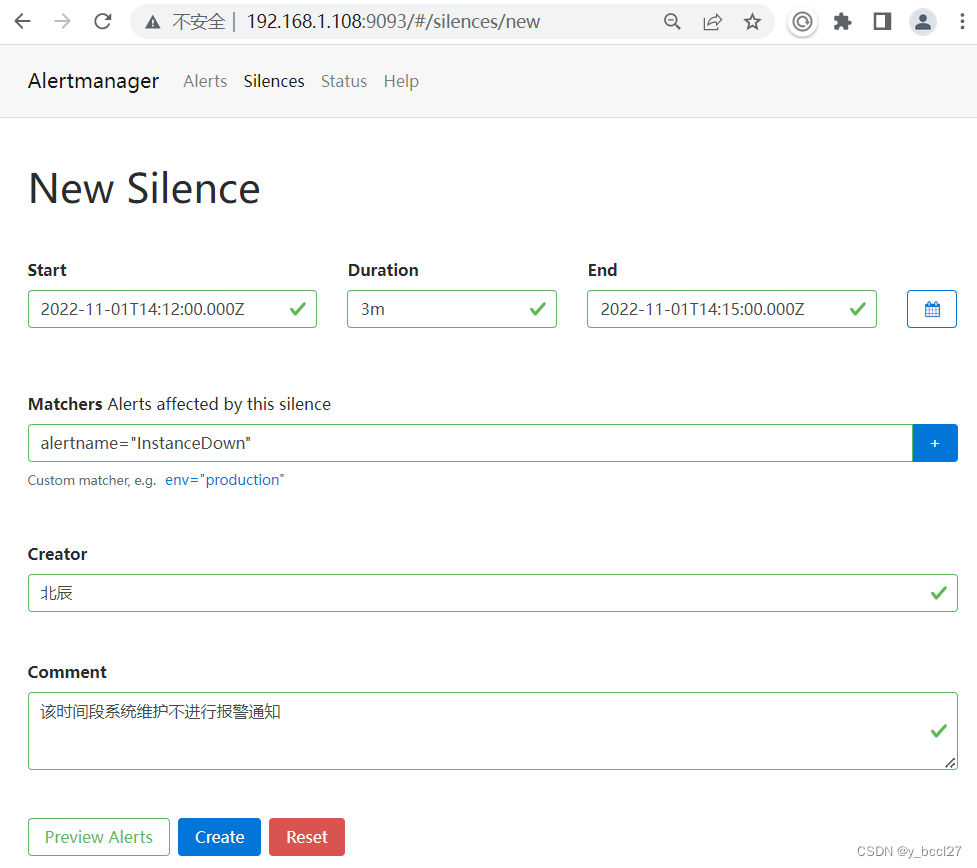
然后点击“Create”按钮,由于我们设置的起始时间比Altermanager服务的当前时间晚,所以首先这条静默规则会在“Pending”选项下显示:
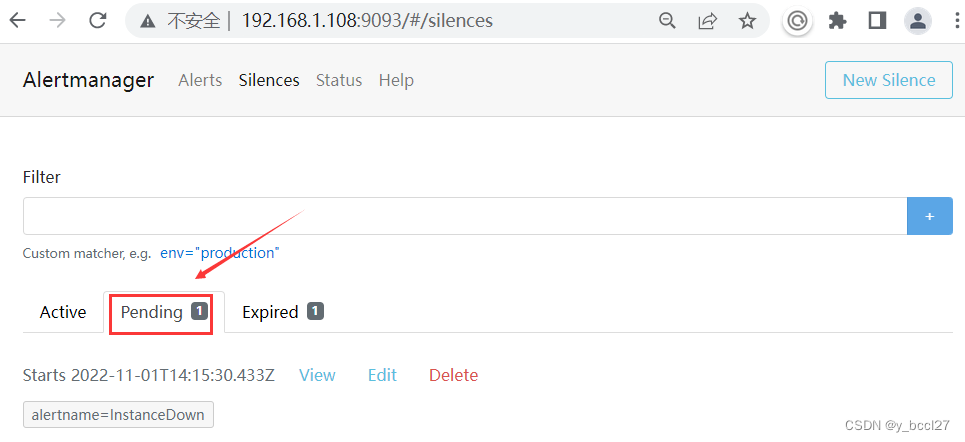
当这条静默规则的触发时间开始了以后,它会进入到“Active”选项下
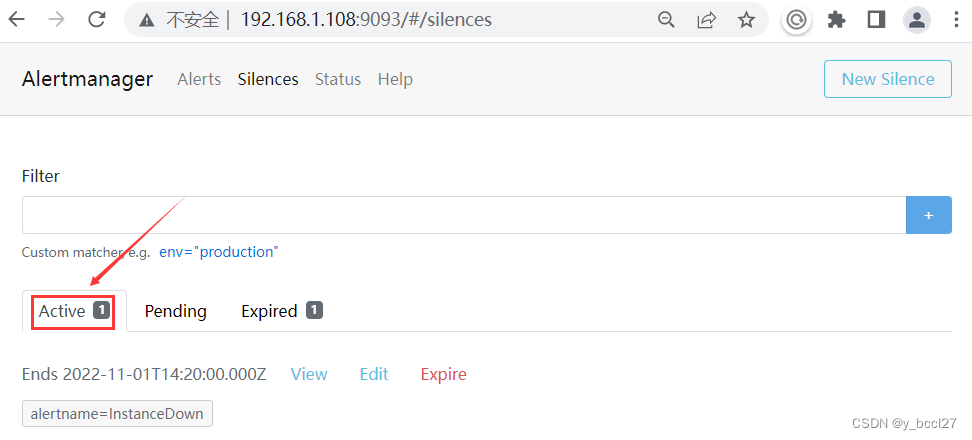
通过接口服务的后台日志打印输出可以看到在15分-20分这个时间段,是没有收到AlterManager服务发送过来的告警通知,但是20分以后又重新收到了告警通知:

接着当这条静默规则的触发时间结束了以后,它会进入到“Expired”选项下,如下图所示:
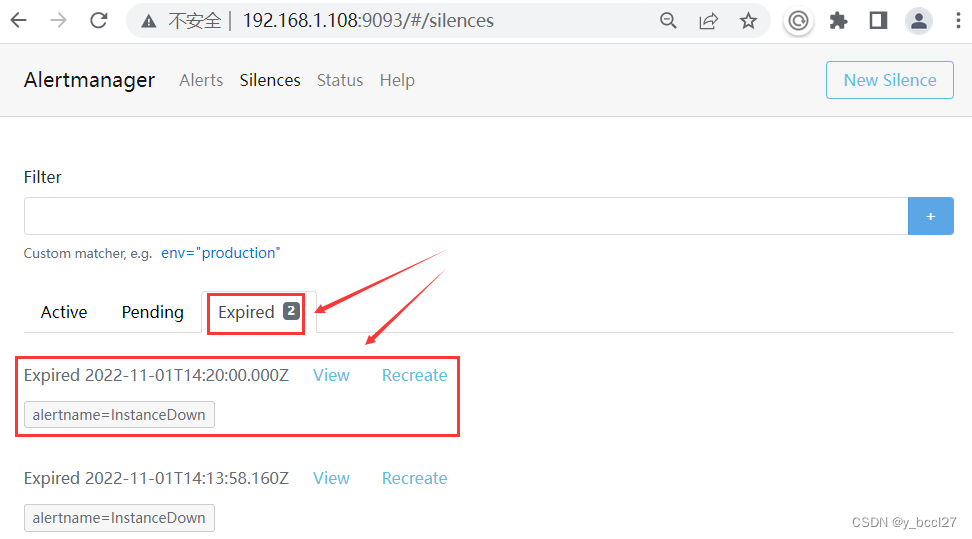
除了通过上述方式创建一个静默规则以后,还可以在Alertmanager的控制台主页通过下述三步操作来创建静默规则,这样做的好处就是我们在此处选中的匹配规则会自动带到所创建的静默规则的“Matchers” 处,如下面两个示例图所示:
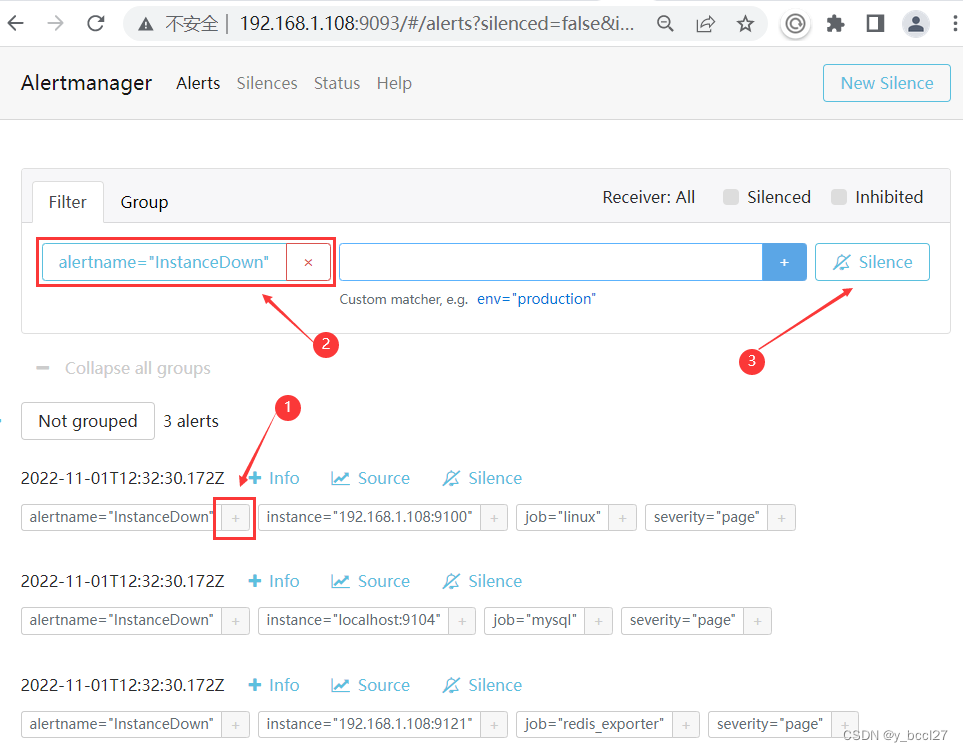

七、抑制机制
Alertmanager的抑制机制可以避免当某种问题告警产生之后用户接收到大量由此问题导致的一系列的其它告警通知。例如当集群不可用时,用户可能只希望接收到一条告警,告诉他这时候集群出现了问题,而不是大量的如集群中的应用异常、中间件服务异常的告警通知。
由于我们前面在“alertmanager.yml”配置文件中设置了默认的receiver,因此基本上所有发送到Altermanager服务的告警信息都会被路由转发到相关的HTTP接口中。
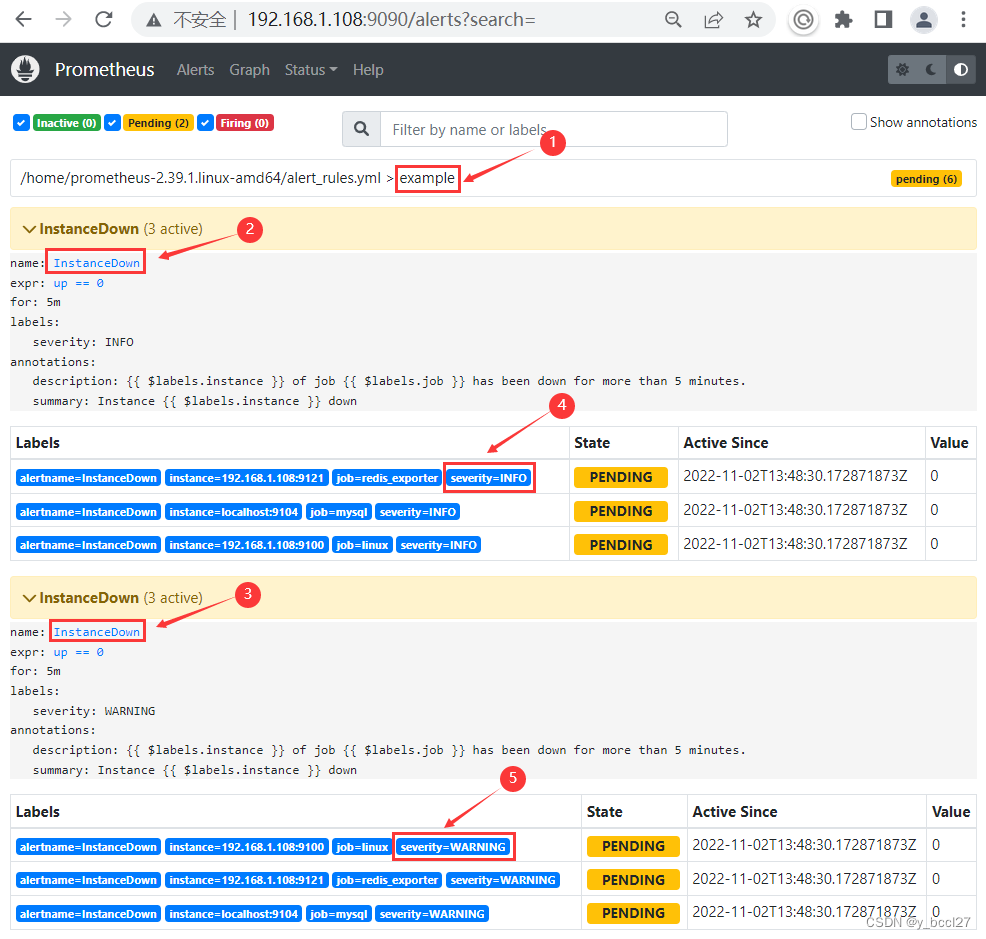
我们在 alert_rules.yml 文件中重新定义两个告警规则,唯一不同的是两个告警规则中labels区域中severity标签的值不一样,一个为INFO、一个为WARNING,如下图所示:
- groups:
- - name: example
- rules:
- # Alert for any instance that is unreachable for >5 minutes.
- - alert: InstanceDown
- expr: up == 0
- for: 5m
- labels:
- severity: INFO
- annotations:
- summary: "Instance {{ $labels.instance }} down"
- description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- # Alert for any instance that has a median request latency >1s.
- - alert: InstanceDown
- expr: up == 0
- for: 5m
- labels:
- severity: WARNING
- annotations:
- summary: "Instance {{ $labels.instance }} down"
- description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
然后重启普罗米修斯,可以看到在同一个组(example)中有两套告警规则,如下图所示:
在5分钟以后,普罗米修斯检测到的告警信息全都发送给了AlertManager服务:
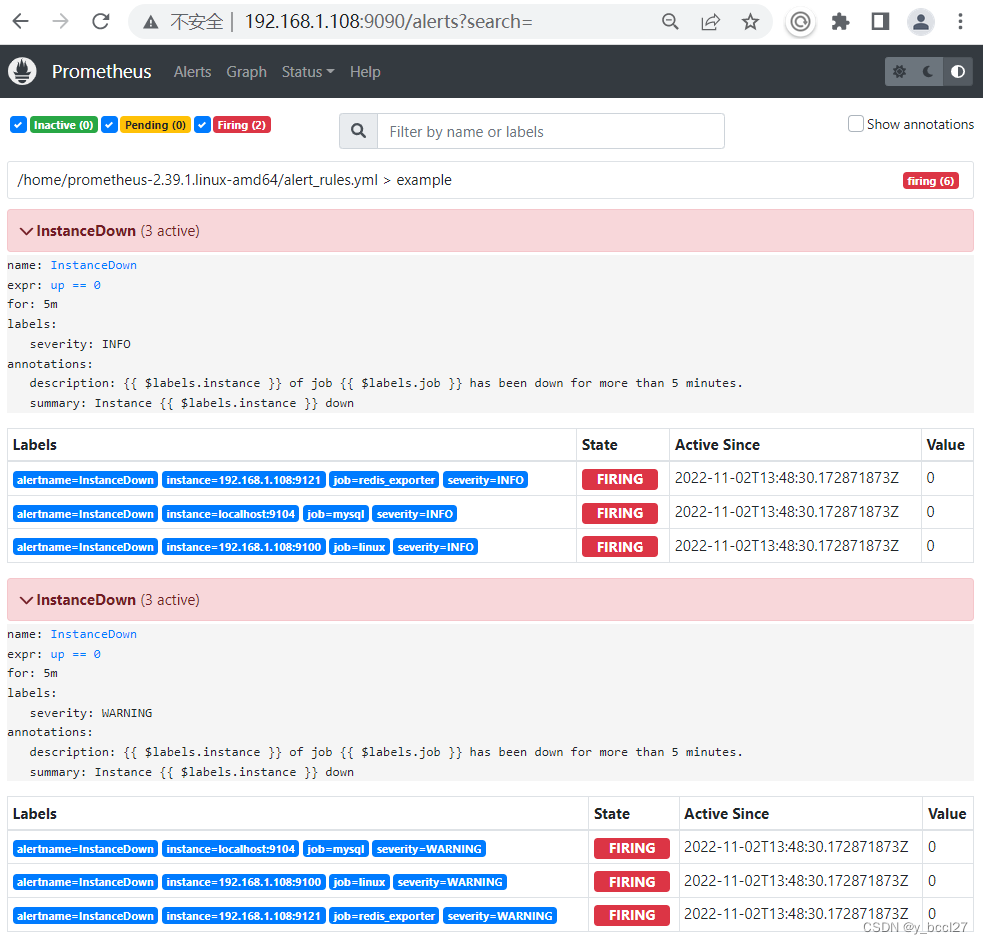
这个时候会看到两个告警规则所产生的告警信息(severity=WARNGING和severity=INFO)都会被AlertManager转发到对应的HTTP接口中。
如果我们希望severity=WARNGING的告警产生的时候,severity=INFO的告警就不用发送告警信息,这个时候就可以采用抑制机制来解决这个问题。
因此我们可以在“alertmanager.yml”配置文件中使用inhibit_rules定义一组告警的抑制规则:
- inhibit_rules:
- - source_match: #匹配当前告警规则后,抑制住target_match的告警规则
- severity: 'WARNING' # 自定义的告警级别是WARNING
- target_match: # 被抑制的告警规则
- severity: 'INFO' # 被抑制住的告警级别
- equal:
- - instance
如果告警的告警级别为severity=WARNING,那么抑制住新的告警信息中标签为 severity=INFO的告警数据,并且源告警和目标告警数据的instance标签的值必须相等。
因此在添加了上述抑制规则之后的“alertmanager.yml”配置文件其完整内容如下所示:
- route:
- group_by: ['example']
- group_wait: 10s
- group_interval: 10s
- repeat_interval: 1m
- receiver: 'ops1'
- routes:
- - match:
- severity: page
- receiver: 'ops1'
- receivers:
- - name: 'ops1'
- webhook_configs:
- - url: 'http://192.168.1.8:8080/example/test' #告警web.hook地址,告警信息会post到该地址,需要编写服务接收该告警数据
- inhibit_rules:
- - source_match: #匹配当前告警规则后,抑制住target_match的告警规则
- severity: 'WARNING' # 自定义的告警级别是WARNING
- target_match: # 被抑制的告警规则
- severity: 'INFO' # 被抑制住的告警级别
- equal: ['alertname','instance']
特别说明:抑制规则中的equal的值既可以写成“- instance”这种形式,也可以写成“['alertname','instance']”这种形式,二者是一样的。
重启AlertManager服务,可以看到Alertmanager的控制台界面这时只有security=WARNING的告警信息,并且所路由转发到的HTTP接口中也只有security=WARNING的告警信息。
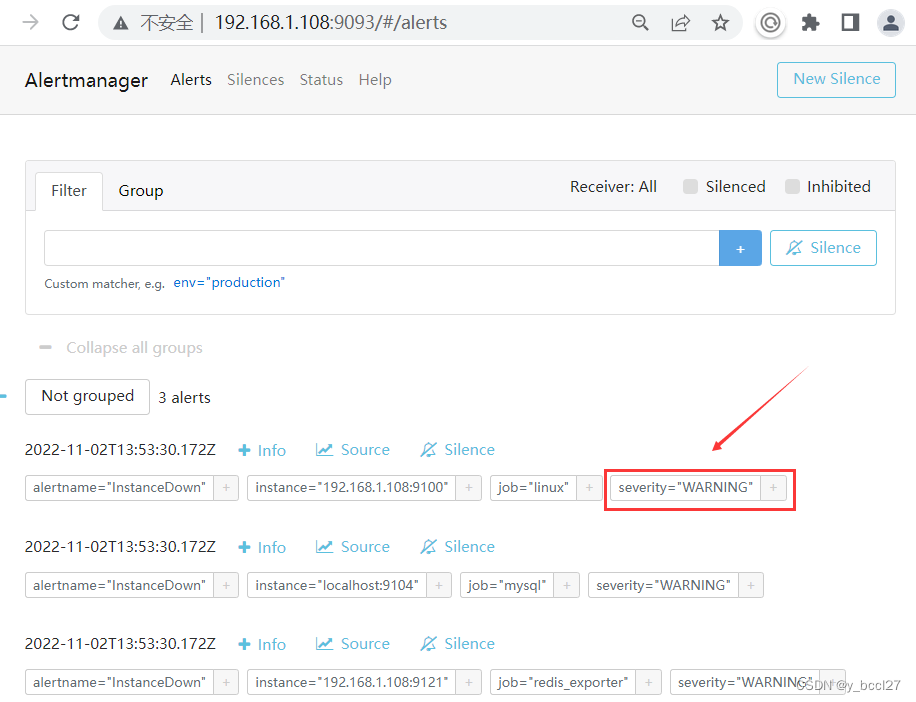
八、其它
如果有必要深入的话,可以参考下面这些资料:
- https://www.mianshigee.com/tutorial/prometheus-book/alert-alert-manager-inhibit.md
- https://www.cnblogs.com/huan1993/p/15416114.html
-
相关阅读:
vue Router从入门到精通
docker 查看日志的三种方式
【企业级SpringBoot单体项目模板 】—— 一些开发规范
React.memo使用报错Component definition is missing display name
秋招面经第一弹:百度一面-大数据开发工程师
如何实现校园网的规划与设计
Hbase
关于一个图算法的应用
Flink学习20:算子介绍reduce
小啊呜产品读书笔记001:《邱岳的产品手记-13》第24讲 产品案例分析:PathSource的混乱与直观 & 25讲 产品世界的暗黑模式:操纵的诱惑
- 原文地址:https://blog.csdn.net/y_bccl27/article/details/127604023
