-
8、【办公自动化】Python实现PDF文件的批量操作
说明
平时工作中,经常会和 PDF 文件打交道,比如,合并、拆分、加解密、添加和去除水印、提取指定内容、转换成其他文件格式等操作。如果只是处理单个 PDF 文件的话,有些操作是比较简单的,而如果需要批量处理 PDF 文件的话,则会比较麻烦,且会做很多的重复工作,在 Python 面前,这些批量操作并不会那么繁琐。
下面介绍下 Python 实现 PDF 文件这些批量操作的实现,建议使用 Python 的第三方模块 PyPDF2 来操作 PDF 文件,该模块能完成拆分、合并、剪切和转换等多种操作,也可以向 PDF 文件添加自定义数据、查看选项和密码等。我们可以先去 pypi 官网搜索该模块,了解并学习下它的 API。
使用命令 pip install pypdf2 安装该模块后,就可以愉快的玩转 PDF 文件了。在学习该模块 API 时,有个需要注意的问题,就是 PdfFileReader、PdfFileWriter、PdfFileMerger 这几个类,会在3.0.0版本被移除,建议使用 PdfReader、PdfWriter、PdfMerger。
- __all__ = [
- "__version__",
- "PageRange",
- "PaperSize",
- "DocumentInformation",
- "parse_filename_page_ranges",
- "PdfFileMerger", # will be removed in PyPDF2 3.0.0; use PdfMerger instead
- "PdfFileReader", # will be removed in PyPDF2 3.0.0; use PdfReader instead
- "PdfFileWriter", # will be removed in PyPDF2 3.0.0; use PdfWriter instead
- "PdfMerger",
- "PdfReader",
- "PdfWriter",
- "Transformation",
- "PageObject",
- "PasswordType",
- ]
一、PDF文件的批量合并
要实现批量合并,就要读取和合并有关的类,则需要引入PdfReader、PdfMerger,如下:
from PyPDF2 import PdfReader,PdfMerger接着,需要判断合并后的目标路径是否存在,获取源路径下 PDF 文件列表,为批量操作做好准备,这里使用 pathlib 模块的 Path 类实现,如下:
- from pathlib import Path
- src_path = input("请输入你要批量合并pdf文件所在的目录: ")
- if len(src_path) == 0:
- src_path = "D:\\XXX\\test-pdf\\wheat\\"
- src_dir = Path(src_path)
- # 目标路径及合并后的pdf文件名称
- desc_dir = Path(src_path + 'PDF_合并.pdf')
- # 判断目标路径是否存在
- if not desc_dir.parent.exists():
- desc_dir.parent.mkdir(parents=True)
- # 获取源目录下的PDF文件列表
- pdf_list = list(src_dir.glob("*.pdf"))
通过遍历源目录下的 PDF 文件实现批量操作,过程如下:
- total_pages = 0
- merger = PdfMerger()
- for pdf in pdf_list:
- # 读取pdf文件
- reader = PdfReader(pdf)
- # 追加到合并对象里
- merger.append(reader)
- # 用于统计合并后的总页数
- count = reader.getNumPages()
- print(f"{pdf.name} 的页数为: {count}")
- total_pages += count
- merger.write(desc_dir)
- merger.close()
- print(f"合并后的PDF文件页数为: {total_pages}")
在本地的 D:\\XXX\\test-pdf\\wheat\\ 目录下,准备了之前爬取的四个城市的包含天气数据的 PDF 文件,作为测试文件:

执行代码后,输出日志如下:

合并后的文件情况:

完美~~
二、PDF文件的批量拆分
如果单个 PDF 文件的页数过多,可能导致阅读翻看不便,可以将其拆分成几个部分。这里,使用 Python 实现页数过多的多个 PDF 文件的批量拆分操作,需要的依赖仍是 pathlib、PyPDF2 等模块。
- from PyPDF2 import PdfReader, PdfWriter
- from pathlib import Path
首先,需要指定待拆分文件的源路径,以及拆分页数。遍历这些 PDF 文件时,需要判断当前的 PDF 文件页数是否大于设置拆分页数,是的话再进行拆分处理,判断如下:
- def split_pdf(src, num):
- src_dir = Path(src)
- for pdf in list(src_dir.glob("*.pdf")):
- reader = PdfReader(pdf)
- pages = reader.getNumPages()
- pages_num = int(num)
- # 当前PDF文件的页数大于设置拆分页数再进行拆分处理
- if pages > pages_num:
- split_by_pages_num(src_dir, pdf, reader, pages, pages_num)
- else:
- print(f'{pdf.name} 页数为: {pages},小于设置拆分页数{pages_num},不进行拆分!')
- continue
接着,就对待拆分的文件进行处理了,按指定拆分页数,需要计算出当前 PDF 文件拆分后得到的份数,每份里面还要计算出起始页和终止页的位置,判断如下:
- def split_by_pages_num(src_dir, pdf, reader, pages, pages_num):
- # 计算PDF文件拆分后的份数
- parts = pages // pages_num + 1
- for part in range(parts):
- # 计算每份的起始页和终止页
- start = pages_num * part
- if part == (parts - 1):
- end = pages - 1
- else:
- end = start + pages_num - 1
- # 拆分后的写入新的pdf文件
- write_pdf_part(src_dir, pdf, reader, part, start, end)
- print(f'{pdf.name}页数为{pages},已拆分成了{parts}部分')
根据起始页和终止页的位置,最终写入新部分的 PDF 文件,如下:
- def write_pdf_part(src_dir, pdf, reader, part, start, end):
- writer = PdfWriter()
- for split_part in range(start, end + 1):
- writer.addPage(reader.getPage(split_part))
- part_name = f"{pdf.stem}_第{part + 1}部分.pdf"
- part_file = src_dir / part_name
- with open(part_file, 'wb') as out_file:
- writer.write(out_file)
这里,准备了三个页数较大的测试文件,页数最小的小于 500,最大有 2500 多页,如下:
测试的话,默认指定拆分的页数为 500,代码如下:
- if __name__ == '__main__':
- src_path = input("请输入你要批量拆分pdf文件所在的目录: ")
- page_num = input("请输入你拆分的页数:")
- if len(src_path) == 0:
- src_path = "D:\\XXX\\test-pdf\\wheat-split\\"
- if len(page_num) == 0:
- page_num = "500"
- # 批量拆分PDF文件
- split_pdf(src_path, page_num)
输出日志:

效果:

不足500页的不进行拆分,而拆分的文件,非最后一部分都是500页,其余的都放在了最后一页!完美~~
三、PDF文件的加密和解密
1、加密
PDF 文件加密是指在打开 PDF 文件时设置密码,主要是为了文件的安全性,防止重要的文件泄密。
Python 实现多个 PDF 文件批量设置访问密码是很简单的,过程是读取源文件,调用输出流的加密方法,然后再写入新的文件即可,代码如下:
- def encrypt_pdf(src, pwd):
- src_dir = Path(src)
- for pdf in list(src_dir.glob("*.pdf")):
- reader = PdfReader(pdf)
- pages = reader.getNumPages()
- writer = PdfWriter()
- for page in range(pages):
- writer.addPage(reader.getPage(page))
- # 加密
- writer.encrypt(pwd)
- desc_name = f"{pdf.stem}_encrypt.pdf"
- desc_file = src_dir / desc_name
- # 生成加密后文件
- with open(desc_file, 'wb') as out_file:
- writer.write(out_file)
- print(f"{pdf.name}加密完成,加密后的文件为{desc_name}")
测试文件如下:
测试代码如下:
- if __name__ == '__main__':
- src_path = input("请输入你要批量合并pdf文件所在的目录: ")
- pwd = input("请输入你要加密的密码: ")
- if len(src_path) == 0:
- src_path = "D:\\XXX\\test-pdf\\wheat-encrypt\\"
- # 加密方法
- encrypt_pdf(src_path, pwd)
输出日志:

效果:

打开其中一个加密后的文件:

2、解密
PDF 文件的解密也很简单,思路与加密类似,通过调用输入流的解密方法,但前提要知道解密的密码。
在上面的代码基础上,把加密代码换成解密代码即可。需要注意将解密代码放在输入流创建的后面,并且先解密才能继续后面的获取分页的操作,如下:
- # 解密
- if reader.is_encrypted:
- reader.decrypt(pwd)
准备三个被加密的测试文件,如下:

测试代码如下:
- if __name__ == '__main__':
- src_path = input("请输入你要批量合并pdf文件所在的目录: ")
- pwd = input("请输入你要解密的密码: ")
- if len(src_path) == 0:
- src_path = "D:\\XXX\\test-pdf\\wheat-decrypt\\"
- # 解密方法
- decrypt_pdf(src_path, pwd)
输出日志:

效果:

打开检查一下,解密后的 PDF 文件不需要访问密码!完美~~
四、PDF文件添加水印
PDF 文件添加水印,主要用来防止文件内容被他人随意盗用!水印可以是图片水印,也可以是文字水印,主要是看需求了。
1、添加文字水印
Python 实现为 PDF 文件添加文字水印的思路是,通过第三方模块 reportlab 来制作 PDF 格式的文字水印文件,然后将 PDF 文件与文字水印文件融为一体,就实现了添加水印目的。
安装好 reportlab 模块之后,我们按需导入将要使用到的模块,如下:
- from PyPDF2 import PdfReader, PdfWriter
- from pathlib import Path
- from reportlab.pdfbase import ttfonts, pdfmetrics
- from reportlab.pdfgen import canvas
- from reportlab.lib.units import cm
首先,自定义一个用来创建文字水印文件的方法,并设置水印文字的字体,字号,倾斜度,透明度,色度等格式。
- def create_watermark_file(ttfPath, context):
- file_name = "watermark.pdf"
- c = canvas.Canvas(file_name, pagesize=(30 * cm, 30 * cm))
- # 设置文字水印的坐标,字体格式,倾斜度,透明度,颜色等
- c.translate(5 * cm, 0 * cm)
- # font_name = "阿里巴巴普惠体"
- # pdfmetrics.registerFont(ttfonts.TTFont(font_name, ttfPath))
- # c.setFont(font_name, 25)
- c.rotate(30)
- c.setFillAlpha(0.4)
- c.setFillColorRGB(0, 0, 0)
- for m in range(0, 30, 5):
- for n in range(0, 30, 5):
- c.drawString(m * cm, n * cm, context)
- c.save()
- return file_name
有了创建文字水印文件的模板方法后,接着需要将 PDF 文件与该文字水印文件融为一体,并为每一页的 PDF 添加文字水印,实现如下:
- def add_watermark_file(input_file, watermark_file, output_file):
- mark = PdfReader(watermark_file)
- writer = PdfWriter()
- reader = PdfReader(input_file)
- for i in range(reader.getNumPages()):
- page = reader.getPage(i)
- # 合并水印文件
- page.mergePage(mark.getPage(0))
- writer.addPage(page)
- with open(output_file, 'wb') as out_file:
- writer.write(out_file)
然后,就可以愉快的测试效果了,测试文件如下:

测试代码如下:
- if __name__ == '__main__':
- routePath = "D:\\XXX\\test-pdf\\wheat-watermark\\"
- ttfPath = ''
- context = "welcome to China"
- src_dir = Path(routePath)
- desc_dir = Path(routePath + "watermark\\")
- if not desc_dir.exists():
- desc_dir.mkdir(parents=True)
- for pdf in list(src_dir.glob("*.pdf")):
- watermark = create_watermark_file(ttfPath, context)
- add_watermark_file(pdf, watermark, desc_dir / pdf.name)
效果如下:

打开其中一个文件,效果截图如下:

值得注意的是,如果需要字体更加多样的水印效果,在 create_watermark_file() 方法中进行相应的设置即可。因网上下载字体文件需要会员等限制,这里我实现的水印效果并不是太理想啊!
2、添加图片水印
Python 实现为 PDF 文件添加图片水印的思路与添加文字水印类似,与添加文字水印相比会更加简单。思路是,在页面中增加一个透明背景的图片,通过调用页面的 mergePage 方法即可。
准备一张透明的图片,放到水印 PDF 文件上,如下:

之前的 add_watermark_file() 方法保持不变,测试的代码的话,只需要把带图片水印的 PDF 文件的地址加上就行,如下:
- if __name__ == '__main__':
- routePath = "D:\\XXX\\test-pdf\\wheat-watermark\\"
- src_dir = Path(routePath)
- desc_dir = Path(routePath + "watermark_picture\\")
- if not desc_dir.exists():
- desc_dir.mkdir(parents=True)
- # 准备一张具有透明度的图片放置在PDF文件中
- watermark = "D:\\XXX\\test-pdf\\watermark_picture.pdf"
- for pdf in list(src_dir.glob("*.pdf")):
- add_watermark_file(pdf, watermark, desc_dir / pdf.name)
看下效果:

效果不是太好,原因在于图片本身的透明度问题,可这种实现的思路没错,可考虑借助修图工具处理图片的透明度值,以消除这种问题。
3、去除水印
在想能给 PDF 文件批量添加水印操作,肯定也能去除水印,实际上添加水印和去除水印像一种攻防关系,添加水印是为了保护文档的原创性。
这里,不再去研究如何去除水印,为了尊重知识,尊重原创的内容,请不要随意去除水印,保护知识人人有责啊!
五、提取PDF文件的内容
从上面应该能看到,PyPDF2 模块的主要能力在页面级操作,比如 PDF 文件的合并和拆分、加密和解密、添加水印和去除水印、获取PDF文件基本信息等。而实际工作中,可能更常用的操作是提取 PDF 文件的指定内容,比如文字、图片、表格等元素。
这里需要借助另一个模块了,它就是 pdfplumber 模块,前往 Pypi 官网搜索,可以看到它的简介和学习相关 API 的使用。
1、提取文字
比如,提取 PDF 文件的文字,并保存到 txt 文件,也就是 PDF 转 TXT 。实现很简单,通过 extract_text() 核心方法实现即可,如下:
- import pdfplumber, os, codecs
- from pathlib import Path
- def pdf2txt(src_dir):
- for pdf_file in list(src_dir.glob("*.pdf")):
- pdf_file_name = os.path.split(pdf_file)[1]
- with pdfplumber.open(pdf_file) as pdf:
- for page in pdf.pages:
- txt_file = codecs.open(src_dir / f"{pdf_file_name}.txt", 'a', encoding="utf-8")
- txt_file.write(page.extract_text())
- # print(page.extract_text())
- txt_file.close()
提取文字效果,如下:

2、提取图片
从 PDF 文件提取图片,发现 pdfplumber 模块有个 to_image() 方法,看样子是 pdf 转图片的操作,写个方法测试下作用,代码如下:
- def pdf_extract_picture():
- src_dir = Path("D:\\XXX\\test-pdf\\pdf2picture\\")
- for pdf_file in list(src_dir.glob("*.pdf")):
- count = 0
- with pdfplumber.open(pdf_file) as pdf:
- for page in pdf.pages:
- count += 1
- image = page.to_image()
- # image.show()
- picture_name = src_dir / f'{pdf_file.name.split(".")[0]}_img{count}.png'
- image.save(picture_name, format="PNG")
执行后报错了,位置在 to_image() 附近,大致意思是缺少 ImageMagick 插件。翻看该模块的文档说明,提示需要下载可视化调试插件:

下载 ImageMagick 插件:

当下载完成后,直接傻瓜式安装即可:
安装完 ImageMagick 插件,而不去安装 Ghostscript 插件的话,会报错:"wand.exceptions.DelegateError: FailedToExecuteCommand `"gswin64c.exe" -q -dQUIET -dSAFER........",需要去下载 Ghostscript 插件:

下载安装好之后,再使用 to_image() 方法就不会报错了~
准备一个测试文件,该文件有9页的内容,存在6张配图,如下:

测试的效果,如下:
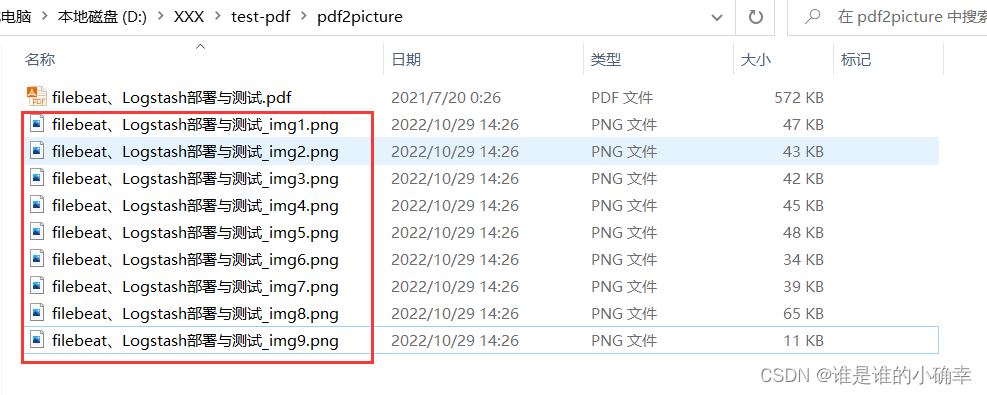
本以为这就大功告成了,还有点窃喜!但打开其中一张图片后,竟然是 PDF 文档的截图?

该 PDF 文件有9页的内容,6张配图,却输出了9张每页的 PDF 文档图片,这下才明白 to_image() 方法是用来 PDF 转图片的操作,而非从 PDF 文档提取图片。那么,该如何实现提取 PDF 文件里的图片呢?
经过一番摸索,终于找到了实现方法,思路是要通过正则表达式识别图片,这里使用 fitz 模块批量读取 PDF 文件,使用 re 模块进行正则判断,实现方法如下:
- def pdf_extract_images(src_dir, desc_dir):
- # 支持批量操作
- for pdf_file in list(src_dir.glob("*.pdf")):
- img_count = 0
- # 打开pdf文档
- pdf = fitz.open(pdf_file)
- print(f"文件名:{pdf_file}, 页数: {len(pdf)}, 对象数: {pdf.xref_length() - 1}")
- for i in range(1, pdf.xref_length()):
- # 使用正则表达式判断是否为对象或图片
- text = pdf.xref_object(i)
- isXObject = re.search(r"/Type(?= */XObject)", text)
- isImage = re.search(r"/Subtype(?= */Image)", text)
- if not isXObject or not isImage:
- continue
- img_count += 1
- picture_name = pdf_file.name.split(".")[0] + f"_img{img_count}.png"
- # 根据索引生成图像,如果pix.n<5,可直接存为PNG格式,否则先转换CMYK
- pix = fitz.Pixmap(pdf, i)
- if pix.n < 5:
- pix.writePNG(desc_dir / picture_name)
- else:
- pix0 = fitz.Pixmap(fitz.csRGB, pix)
- pix0.writePNG(desc_dir / picture_name)
- pix0 = None
- pix = None
- print(f"已提取第{img_count}张图片......")
仍然使用同一个 PDF 文件作为测试,测试代码如下:
- if __name__ == '__main__':
- src_path = "D:\\XXX\\test-pdf\\pdf2picture\\"
- src_dir = Path(src_path)
- desc_dir = Path(src_path + "pictures\\")
- if not desc_dir.exists():
- desc_dir.mkdir(parents=True)
- pdf_extract_images(src_dir, desc_dir)
效果如下:

这才是真正的从 PDF 文件中提取图片操作了,效果相当不错,达到目的!
3、提取表格
从 PDF 文件提取表格数据,实际上可以看成 PDF 文件转 Excel 文件,虽然 WPS 和一些在线工具都能完成这种操作,但会收费啊!哎,不想被薅羊毛的话,可以通过强大的 Python 实现。
首先,准备一个测试文件:

保证该 PDF 文件表格数据形式,如下:

这里通过 openpyxl 模块,将表格数据转储成 Excel 文件,代码实现如下:
- def pdf_extract_excel():
- src_dir = Path("D:\\XXX\\test-pdf\\pdf2excel\\")
- # 支持批量操作
- for pdf_file in list(src_dir.glob("*.pdf")):
- wb = Workbook()
- sheet = wb.active
- excel_name = src_dir / f'{pdf_file.name.split(".")[0]}.xlsx'
- with pdfplumber.open(pdf_file) as pdf:
- for page in pdf.pages:
- table = page.extract_table()
- # print(table)
- for row in table:
- sheet.append(row)
- wb.save(excel_name)
测试效果,如下:

至此,以上就是批量操作 PDF 文件的全部内容了,经过一番研究和学习,再次感受到了 Python 的强大,希望在今后的办公中遇到此类问题可轻松解决,不用再求助于各种收费工具了。
-
相关阅读:
05-Mycat的概念
信号相干解调
梦中情盘!基于NextCloud搭建个人私有云!
python 爬虫 app爬取之charles的使用
C#在.NET Windows窗体应用中使用LINQtoSQL
手把手教你编写性能测试用例
PHP复习资料(未完待续)
GIT学习之路
对话MySQL之父:一个优秀程序员可抵5个普通程序员
RS485协议和Modbus协议有什么区别?工业网关能用吗?
- 原文地址:https://blog.csdn.net/qq_29119581/article/details/127466373
