-
Python实现BOA蝴蝶优化算法优化支持向量机分类模型(SVC算法)项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。


1.项目背景
蝴蝶优化算法(butterfly optimization algorithm, BOA)是Arora 等人于2019年提出的一种元启发式智能算法。该算法受到了蝴蝶觅食和交配行为的启发,蝴蝶接收/感知并分析空气中的气味,以确定食物来源/交配伙伴的潜在方向。
蝴蝶利用它们的嗅觉、视觉、味觉、触觉和听觉来寻找食物和伴侣,这些感觉也有助于它们从一个地方迁徙到另一个地方,逃离捕食者并在合适的地方产卵。在所有感觉中,嗅觉是最重要的,它帮助蝴蝶寻找食物(通常是花蜜)。蝴蝶的嗅觉感受器分散在蝴蝶的身体部位,如触角、腿、触须等。这些感受器实际上是蝴蝶体表的神经细胞,被称为化学感受器。它引导蝴蝶寻找最佳的交配对象,以延续强大的遗传基因。雄性蝴蝶能够通过信息素识别雌性蝴蝶,信息素是雌性蝴蝶发出的气味分泌物,会引起特定的反应。
通过观察,发现蝴蝶对这些来源的位置有非常准确的判断。此外,它们可以辨识出不同的香味,并感知它们的强度。蝴蝶会产生与其适应度相关的某种强度的香味,即当蝴蝶从一个位置移动到另一个位置时,它的适应度会相应地变化。当蝴蝶感觉到另一只蝴蝶在这个区域散发出更多的香味时,就会去靠近,这个阶段被称为全局搜索。另外一种情况,当蝴蝶不能感知大于它自己的香味时,它会随机移动,这个阶段称为局部搜索。
本项目通过BOA蝴蝶优化算法优化支持向量机分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):

3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:

从上图可以看到,总共有11个变量,数据中无缺失值,共1000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。

关键代码如下:

4.探索性数据分析
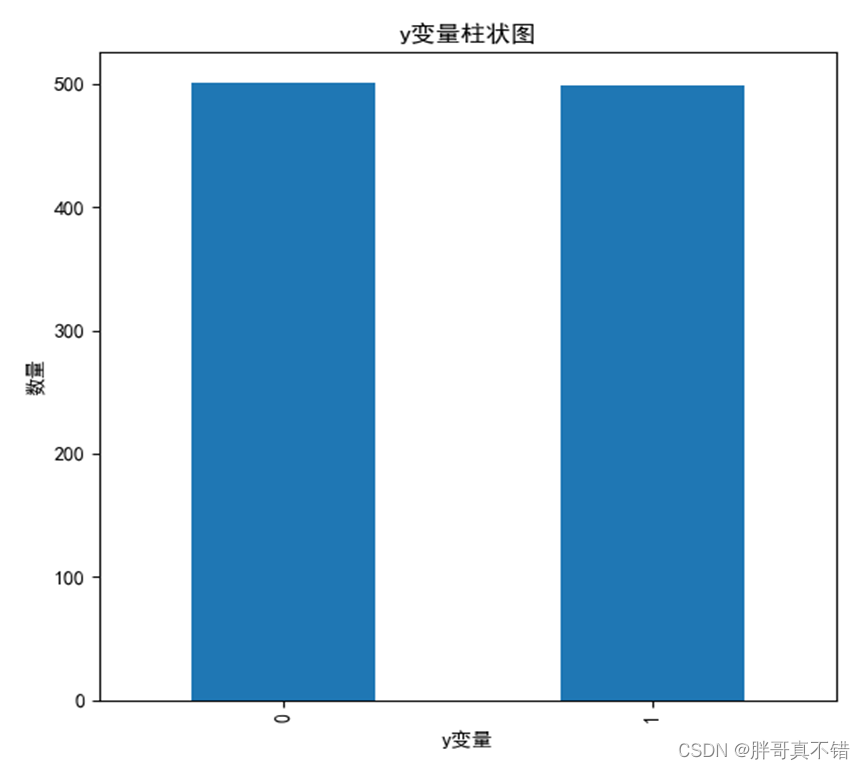
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
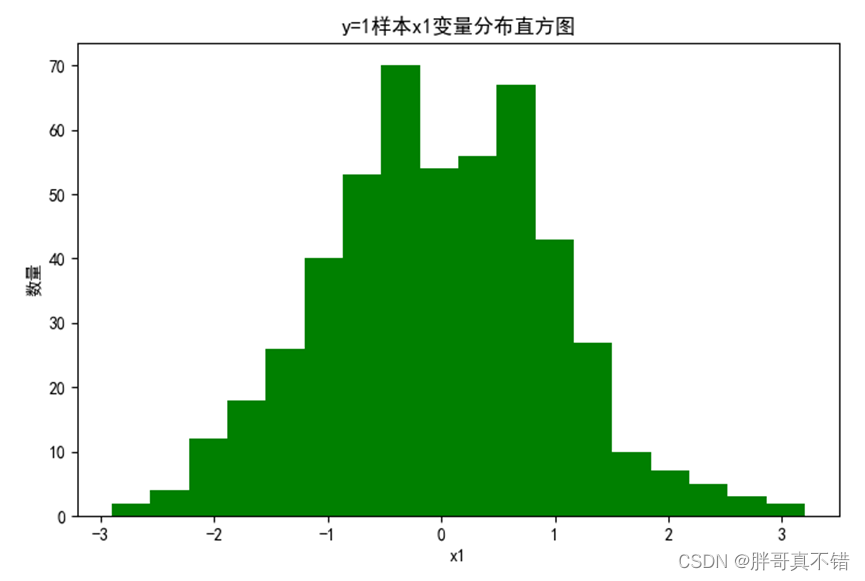
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
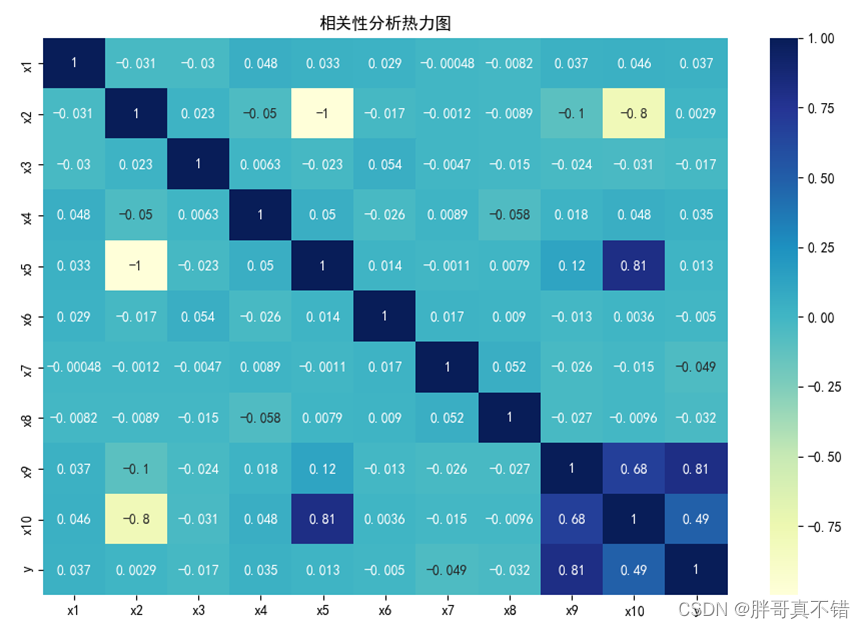 从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建BOA蝴蝶优化算法优化支持向量机分类模型
主要使用BOA蝴蝶优化算法优化SVC算法,用于目标分类。
6.1 算法介绍
说明:BOA算法介绍来源于网络,供参考,需要更多算法原理,请自行查找资料。
蝴蝶利用自身的感知器定位食物的来源。该算法中,假设每只蝴蝶产生一定强度的香味,这些香味会传播并被区域内的其它蝴蝶感知。每只蝴蝶释放出的香味与它的适应度有关。这就意味着当一只蝴蝶移动了位置,它的适应度也将随之变化。当蝴蝶感觉到另一只蝴蝶在这个区域散发出更多的香味时,就会去靠近,这个阶段被称为全局搜索。另外一种情况,当蝴蝶不能感知大于它自己的香味时,它会随机移动,这个阶段称为局部搜索阶段。
香味是根据 刺 激 的 物 理 强 度 来 表 述 的。其 计 算 如 式所示:
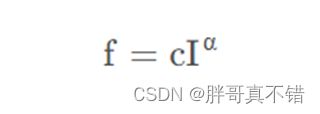
蝴蝶产生的香味涉及到3个参数,分别为感觉因子c,刺激强度I 和幂指数α。刺激强度与蝴蝶 (解)的适应度相关。
该算法有两个关键步骤:全局搜索阶段和局部搜索阶段。在全局搜索阶段,蝴蝶将向最优解 g ∗ 移动,可表示为:
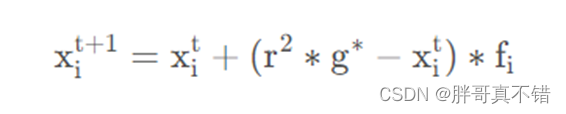
其中, xit表示第i个蝴蝶在第t次迭代中的解向量。这里g ∗ 表示目 前 为 止 的 最 优 解。第i只 蝴 蝶 的 香 味 用 fi来表示,r为0到1的随机数。
局部搜索可表示为:
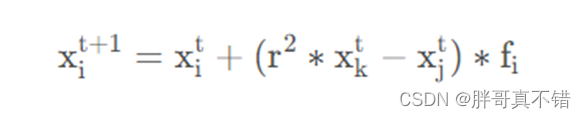
其中r为0到1的随机数, xkt和 xjt表示从解空间中随机选择的第k只和第j 只蝴蝶。在蝴蝶的觅食过程中,全局和局部搜索都会发生,为此,设定一个开关概率p来转换普通的全局搜索和密集的局部搜索。每次迭代用如下式随机产生一个数r,与开关概率p进行比较来决定进行全局搜索还是局部搜索。

算法流程:
(1) 计算适应度函数f(x),x=(x1,...,xdim)
(2) 给每个蝴蝶生成n个初始解 xi=(i=1,2,...,n)
(3) 声明变量c,α,g ∗,p
(4) while未到终止条件do
(5) for每一个蝴蝶do
(6) 采用式计算其香味函数f
(7) 结束循环
(8) 找出最优的香味函数f,并赋值给g∗
(9) for 每一个蝴蝶do
(10) 采用式计算概率r
(11) 假如r
(12) 采用式进行全局搜索
(13) 采用式进行局部随机搜索
(14) 输出最优解。
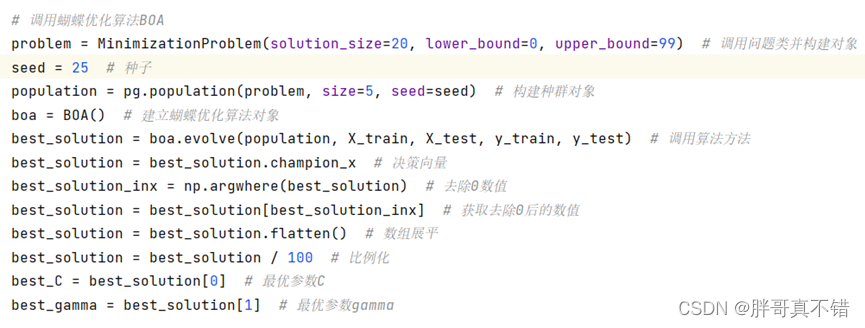
6.2 BOA蝴蝶优化算法寻找最优参数值
关键代码:
每次迭代的过程数据:

最优参数:
 6.3 最优参数值构建模型
6.3 最优参数值构建模型
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
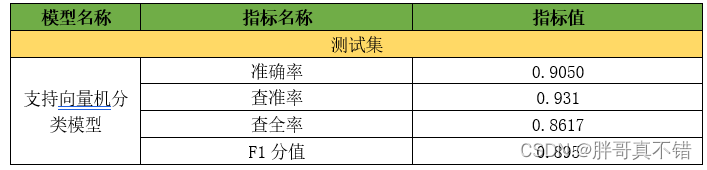
从上表可以看出,F1分值为0.895,说明模型效果良好。
关键代码如下:
 7.2 查看是否过拟合
7.2 查看是否过拟合
从上图可以看出,训练集和测试集分值相当,无过拟合现象。
7.3 分类报告

从上图可以看出,分类为0的F1分值为0.91;分类为1的F1分值为0.90。
7.4 混淆矩阵

从上图可以看出,实际为0预测不为0的 有13个样本;实际为1预测不为1的 有6个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了BOA蝴蝶优化算法寻找支持向量机SVC算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
- # 本次机器学习项目实战所需的资料,项目资源如下:
- # 项目说明:
- # 链接:https://pan.baidu.com/s/141VlaNsrO2dQlVqmzQ2ohA
- # 提取码:pd20
- # 查看数据前5行
- print('*************查看数据前5行*****************')
- print(df.head())
- # 数据缺失值统计
- print('**************数据缺失值统计****************')
- print(df.info())
- # 描述性统计分析
- print(df.describe())
- print('******************************')
- # y变量柱状图
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
- plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- # kind='bar' 绘制柱状图
- df['y'].value_counts().plot(kind='bar')
- plt.xlabel("y变量")
- plt.ylabel("数量")
- plt.title('y变量柱状图')
- plt.show()
-
相关阅读:
卧式铣床主传动系统设计建模及运动仿真
嵌入式-Linux基础操作
2022算法分析与练习十六
【C++】构造函数初始化列表 ⑤ ( 匿名对象 生命周期 | 构造函数 中 不能调用 构造函数 )
深度学习500问——Chapter08:目标检测(2)
【算法100天 | 7】二叉树的前序、中序、后序、层序遍历(递归和迭代两种实现)
CSDN21天学习挑战赛之冒泡排序
MySQL事务基本操作(方式2)
水文遥测终端(水文遥测终端机)遥测终端机RTU 中小河流水文水雨情自动监测设备
【项目笔记】物联网并发5000+Qps (理论上连接百万级设备)搭建全解
- 原文地址:https://blog.csdn.net/weixin_42163563/article/details/127584790
