-
详解c++---入门(上)
一.前言
亲爱的小伙伴门大家好啊,从这篇文章开始我们就和c语言告别一段落了,我们从此来开始一段新的旅行c++,但是在开始这段旅行之前我们得先来学习一些预备的知识来为我们后面的深入学习做铺垫,因此就有了我们这篇文章,那么我们废话不多说直接开始学习。
二.命名空间
为什么会有命名空间
大家在学习c语言的时候有没有发现一个问题,就是我们在创建变量的时候,如果两个变量的名字是一样的话就会报出变量重定义的问题,比如说下面的代码:
#includeint main() { int num = 10; int num = 10; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
我们将此代码运行一下就可以发现我们这里会报出一个错误:
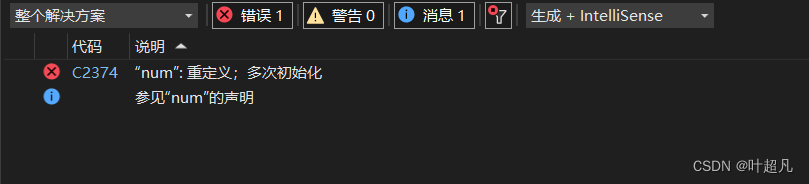
但是我们在编写一个大的项目的时候会创建许许多多的变量出来,而且一个大型的项目一般都是分给多个人来完成,每个人负责编写一些文件,最后再通过#include" 文件名"将不同程序员写的不同的文件合并到一起,但是这样我们就会出现一个问题就是,我们这里不同的人会创建出不同的变量,这些变量有着不同的作用和功能,但是他们可能会有同样的名字,因为程序员在写的时候他是不知道其他程序员是怎么想的,比如说一号程序员在写的时候为了记录一个函数的返回值他就创建了一个整型的变量并且将其取名为:ret,而另一个程序员在编写程序的时候为了得到另一个函数的返回值也创建一个名为ret的整型变量,这样的话我们将这两个程序员写的文件合并到一起去的时候是不是就可能出现这个问题啊,比如说下面的代码:#include#include int rand = 10; int main() { printf("%d", rand); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们创建了一个全局变量rand,然后我们想在main函数里面打印一下这个rand的值,但是我们这里引入
stdlib.h这个文件,在这个文件里面也使用了rand这个名字,如果我们不知道有这件事并且运行这段代码的话,我们就会发现这里就会报出许多错误出来:

而且一个大型的项目所需要的变量和函数是非常的多的,而这就会大大的增加因名字相同而出现问题的概率,那么为了解决这个问题我们c++就增加了一个新的内容叫命名空间。命名空间的介绍
我们上面分析了c语言出现的问题原因,我们不同的程序创建出来的不同的变量可能会有取同样的名字,这样在汇总的时候就会导致出现重定义的问题,那么我们c++就对此给出了一个解决方法:对这些变量再加上一层分装,并且程序员还要对这些封装取一个名字,在这个封装里面程序员可以往其添加自己声明的变量,创建出来的函数,以及结构体等等。比如说一号程序员创建了一个封装,并且给这个封装取了一个名字叫:one,二号程序员也创建了一个封装,并且给这个封装取了一个名字叫:two,这样的话两个程序员即使创建了两个同名的变量但是他们放到了两个不同名的封装的话也不会出现问题。那么在我们的c++里面我们就将这个封装称为命名空间。
命名空间的定义
既然我们知道了这个命名空间的作用是什么?那我们如何来创建一个命名空间呢?那么这里我们就得先来认识认识一个关键字:namespace,这个就是我们创建命名空间的关键字,他的使用模板就如下:

首先写一个namespace,然后在后面写上这个命名空间的名字,然后在下面加一个大括号,这个大括号里面放的就是你们想创建的变量或者结构体或者函数等等,比如我们下面的代码:#includenamespace ycf { int a = 10; struct student { int age; char name[20]; char sex[10]; }; int add(int x, int y) { return x + y; } } int main() { return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我们这里就创建了一个命名空间,并且给这个命名空间取名为ycf,然后在这个命名空间里面我们就创建了一个变量a将其初始化为10,并且还定义了一个add函数,还创建了一个结构体,那么这就是ycf命令空间里面的内容,当然我们这里可以创建多个命名空间,不止这一个。那么这就是我们定义命名空间的全部内容,当然这里还有一些注意事项希望大家注意一下。
注意事项
第一点:
不同的命名空间相同的类型或者变量是不会发生冲突的。
第二点:
如果有多个名字相同的命名空间,那么我们的编译器就会自动地将这些命名空间进行合并,合并成同一个名字的命名空间,比如说下面的代码:
#includenamespace a { int b = 10; int c = 20; } namespace a { double e = 1.0; double f = 2.0; } int main() { return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们这里创建了两个命名空间,但是他们的名字是一样的,那么我们的编译器就会将这两个命名空间合并成一个,也就变成了这样:
#includenamespace a { int b = 10; int c = 20; double e = 1.0; double f = 2.0; } int main() { return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第三点:
命名空间中定义的变量是全局变量,只有定义在函数里的变量才是局部变量。命名空间的使用
第一种使用方法
第一种方法的名称为:加命空间名称及作用域限定符。那么这个方法就得用到一个限定符:
::这个限定符的使用方法就是左边放置命名空间的名称,右边放置你想要使用的命名变量,那么我们这里可以通过下面的例子来看看这里的使用方法:#includenamespace a { int b = 10; int c = 20; double e = 1.0; double f = 2.0; } int main() { printf("%d\n", a::b); printf("%f\n", a::e); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们这里想打印这个命名空间里面的变量b和e的值,那么我们这里就用printf函数,在限定符
::的左边填入命名空间的名字,那么在右边就填入该命名空间中你想使用的变量或者类型的名字。第二种使用方法
第二种方法的名称为:使用using将命名空间中某个成员引入。我们上面讲过我们的命名空间相当于是一个封装,将这些变量或者类型装在一起,如果我们要使用这些变量的话就得用这里的限定符,但是有时候这些命名空间里面的变量我们会经常用到,那这时候我们就可以使用using将这些变量或者类型拿出来这样的话我们以后再使用这些变量或者类型的话就可以不用再使用
::限定符,而是直接使用,那么我们这里using的使用规则就是using后面加命名空间加你想要解放的变量或者类型那么我们这里就可以看看下面的代码:#includenamespace a { int b = 10; int c = 20; double e = 1.0; double f = 2.0; int add(int x, int y) { return x + y; } } using a::c; using a::f; int main() { printf("%d\n", c); printf("%f\n", f); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
通过这个代码大家应该就可以发现:我们将c和f释放之后,我们再使用命名空间里面的c和f的时就可以跟正常的变量一模一样了,但是这个方法大家要注意的一点就是我们这里将常用的东西进行展开之后我们在自己定义变量的时候就得避免重名。
第三种使用方法
第三种方法的名称就是:使用using namespace 命名空间名称引入。我们的第二种方法是将部分引入,那我们这里的第三种方法就是将命名空间里面的内容全部引入进去,那我们这里依然是用using,然后在后面加namespace和该命名空间的名字,比如我们下面的代码:
#includenamespace a { int b = 10; int c = 20; double e = 1.0; double f = 2.0; int add(int x, int y) { return x + y; } } using namespace a; int main() { printf("%d\n", c); printf("%f\n", f); printf("%d\n", add(10, 20)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这样我们在使用该命名空间里面的所有东西的时候都无需使用该限定符,但是这里大家要注意的一点就是:我们平时写代码做一些小的项目的时候可以这么使用,但是以后进入公司写一些大项目的时候就不要这么写了。
注意事项
第一点:
大家可能会看到有关限定符的这种写法就是在限定符的左边什么都没有,比如说这样:printf("%d", ::a);我们知道限定符的左边填入的是命名空间的名字,那如果我们这里不填入呢?那他表示的意思就是我们要引入一个命名空间里面的一个变量或者类型,但是这个命名空间的名字为空,那大家这里想想,什么样的命名空间没有名字呢?那是不是就只能是我们的全局变量了,所以当我们的::左边为空的时候,我们右边的那些变量就表示的是没有被 封装到命名空间里面的全局变量,比如说下面的代码:#includenamespace n1 { int a = 10; } namespace n2 { int a = 20; }namespace n3 { int a = 30; }namespace n4 { int a = 40; } int a = 50; int main() { int a = 60; printf("%d", ::a); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
大家看看这段代码,我们这里要打印
::a的值,但是我们左边没有给他的命名空间的名字,所以他这里就会在跑到我们的全局变量去找这里的a,因为我们这里在全局变量中定义了一个a,并将其值初始化为50,所以我们这里打印的值就是50
但是大家有没有想过一个问题,为什么这里打印的为什么不是60呢?如果大家有这样的疑问的话就得把文章往上翻看到这么一句话:命名空间中定义的变量是全局变量,只有定义在函数里的变量才是局部变量。而这个::限定符他的作用就是访问命名空间里面的内容的,而命名空间里面的内容又全部都是全局变量不可能是局部变量,所以我们这里访问的值都是全局变量,所以当我们不给他要访问的命名空间的名字的时候,他要访问也是访问全局变量,所以这里打印的就是50,如果我们将这个全局变量的a去掉的话我们来看看会发生什么?
我们发现他这里就直接报错了,所以这里大家要注意一下这种使用的情况。
第二点:
局部优先原则,我们在使用一个变量的时候,我们的编译器会先在局部中查找这个变量,如果局部没有找到的话他就会在全局中查找这个变量比如说我们下面的这个代码:#includeint a = 10; int main() { int a = 20; printf("%d", a); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们这个代码的运行结果就是20,因为我们在局部中定义了该名字的变量并将其值赋值为20,那么在我们的c++中如果你想使用某个命名空间中的变量或者内容,但是那个空间没有的话他是不会在其他的地方去寻找跟他名字相同的变量的,比如说下面的代码:
#includenamespace N { int a = 10; } int b = 10; int main() { int b = 10; printf("%d", N::b); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们在全局和局部中都定义了一个名为b的局部变量,但是我们在命名空间N中却没有定义该变量,那么我们下面要使用N中的变量b时,他就只会去命名空间N中查找该变量,如果没找到他也不会去其他的地方进行查找,而是直接报错,那么我们来看看这里代码的运行结果:

同样的道理我们再来看看下面的代码:#includenamespace N { int a = 10; } int main() { int a = 10; printf("%d", ::a); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们这段代码是在命名空间N和局部中定义了一个变量a,但是没有在全局变量中定义一个变量a,那这时我们要打印全局变量中的变量a的话就只会在全局变量中查找,如果全局找不到也不会去局部和命名空间中查找而是直接报错,那么我们将这段代码运行之后就会报错:

第三点:
我们可以在命名空间里面定义一个结构体,就好比这样:#includenamespace N { struct student { int age; char name[20]; char sex[10]; }; } int main() { return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
但是我们在使用这个结构体的时候就得这样:先写struct +命名空间名+限定符+定义的结构体的类型名+结构体的名字,就好比如下这样:
#includenamespace N { struct student { int age; char name[20]; char sex[10]; }; } int main() { struct N::student ycf = { 0 }; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们来看看这个能不能编译成功:
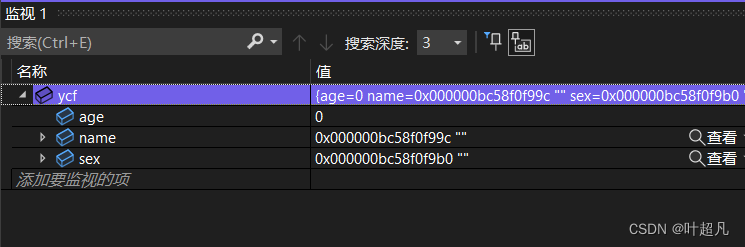
那么我们这里就是编译成功的,如果我们对这个结构体加上typedef进行重命名的话我们这里就得做出一些改变我们就可以将这里的struct去掉,将后面的定义的结构体的类型名改成新的名字即可,比如下面的代码:#includenamespace N { typedef struct student { int age; char name[20]; char sex[10]; }student; } int main() { N::student ycf = { 0 }; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
命名空间的一种理解方式
如果大家看了上面的讲解还是不大了解这里的命名空间的话,我这里可以以另外的一种方式来对其进行讲解。我们将命名空间比喻成我们大国之间的专利财产,不同的国家的科研机构将自己的研发成果全部放到命名空间里面保护起来,这样他就能够保证其他国家无法看到这些专利,而这些其他国家的科技也就无法实现短时间的突破,但有时候一些东西的生产他是离不开这些关键的专利的,所以那些发达的国家就说你给我一些钱我就让你使用这些先进的专利,那这时一些国家或者企业交钱之后这些发达国家就会给他一个密钥,这个密钥就长这样
::他可以对这些被保护的专利进行解密,那这时你就可以使用这些专利了,但是面对一些比较贫穷的国家他们是交不起这个专利费用的,而这些国家的生存又离不开这些专利,那这时一些有担当的大国就会主动给自己的专利进行解封给所有的人进行使用,那这个解封右分为两种一个是部分解封,另外一个就是全部解封,那这里的解封也是有点小心思的那些大国一般都是对那些没啥科技含量但是又经常使用的专利进行解封,对那些十分前沿用的地方很少的专利还是选择不解封,那这就是我们一个现实生活中的一个小例子来带着大家理解这里的命名空间。三.输入输出
在我们的c语言中是用printf和scanf来是u先的输入和输出,而我们知道c++的语法是兼容我们c语言的语法的,所以我们在c++中也可以使用该方法来实现输入输出,但是我们的c++自己本身也有对应的输入输出方式,那么我们这里先来看看如何进行输出。
c++的输出
比如说我们想输出一个hello world这个字符串,我们c++的输出方式就是这样:
int main() { std::cout << "hello world"; return 0; }- 1
- 2
- 3
- 4
- 5
那么首先这里大家应该可以发现cout这个陌生的词,这个词可以将其分为两个部分一个是c一个是out,而这个c是console这个单词的缩写,他的意思就是控制台的意思,所以我们这里的cout的意思就是控制台输出的意思,而后面的<<是流插入运算符,那我们这里就可以这么理解<<是将后面的东西放到我们的控制台里面,然后cout再将控制台里面的东西输出到我们的屏幕上面,然后大家看到我们这里cout前面有个作用域限定符,那么这就说明这个cout是定义在std这个命名空间里面的,而这个std命名空间是定义到iostream这个头文件里面的,所以我们这里还得在上面引入这个头文件:
#includeint main() { std::cout << "hello world"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
那我们再运行就可以看到我们的屏幕上面有了hello world的语句

在我们的c语言换行是通过\n来实现的,我们的c++也同样保持了该用法比如说这样:#includeint main() { std::cout << "hello world\nhello" ; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
我们就可以看到后面的hello就在下一行进行了打印:

而我们的c++还给了换行的另外一种表示方式就是这样:#includeint main() { std::cout << "hello world" << std::endl; std::cout << "hello"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
这里的endl就是换行的意思,而且这个endl也定义在std这个命名空间里面,啊这里非常的简单就没必要多讲,那么这里大家注意一点就是我们这里的cout和endl在写代码的时候用的非常的多,所以我们一般都选择将他们进行部分的引入,那么我们上面的代码就变成了这样:
#includeusing std::cout; using std::endl; int main() { cout << "hello world" << endl; cout << "hello"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
c++的输入
既然c++有专门的输出,那也就肯定有专门的输入,我们的输入是cout表示的意思是通过控制台将其输出到屏幕上面,那我们的输入就是:cin,表示将数据通过控制台将其输入到我们的变量里面,那cin的使用例子如下:
#includeusing std::cout; using std::endl; using std::cin; int main() { int a = 10; double b= 0.0; cin >> a; cin >> b; cout << a << endl; cout << b << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们先创建两个类型的变量出来,然后再通过流提取操作符(>>)将控制台里面的东西放到这里对应的变量里面去,然后我们在将这些数据进行输出
那么我们这里的运行结果就是这样: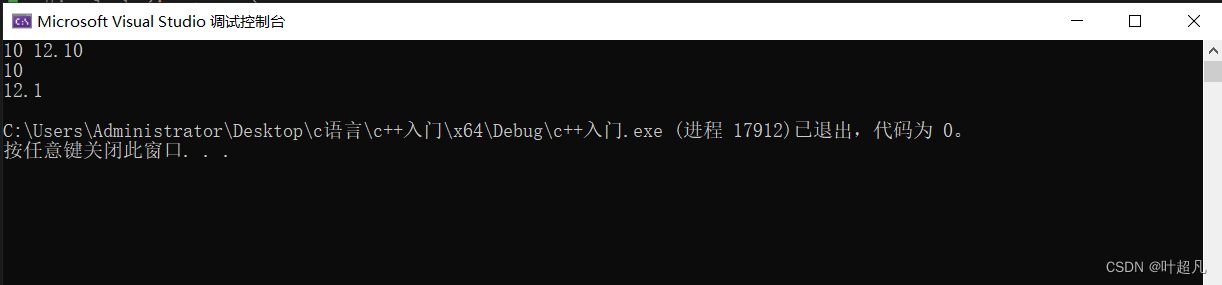
我们这里将10赋值给了我们的a,将12.1赋值给了我们的b,然后我们再打印这两个变量的值,我们通过观察上面运行结果可以发现我们这里的代码写的是真确的,他确实将这些值赋值给了这些变量。有关输入输出的一些事项
第一点:
我们c语言在进行输入或者输出的时候都得需要我们人为的输入一些指令来帮助我们的计算器来识别这些数据比如说字符型就是的输入输出就得认为的输入%c,整型的输入输出就得我们人为的输入%d,浮点型就是%f,比如说下面的代码:#includeint main() { int a = 0; double c = 0.0; scanf("%d", &a); scanf("%lf", &c); printf("%d\n", a); printf("%f\n", c); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们想要输出或者输入一些值的时候就得给他一些特定的标志,他才能识别这些类型,才能正常的读取或者输出一些数据,但是我们的c++独特的输入或者输出的方法却并不会这样,他会自动地识别你输入的类型或者你想要输出的变量的类型,比如我们下面的代码:
#includeusing std::cout; using std::endl; using std::cin; int main() { int a = 10; double b= 0.0; cin >> a; cin >> b; cout << a << endl; cout << b << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们观察一下就可以知道我们这里并没有像c语言一样给它一些特定的标识符来保证它的输入或者输出的正常,因为我们的流提取和流输入操作符它可以自动地识别类型。
第二点:
使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件
以及按命名空间使用方法使用std。
第三点:
cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<
iostream >头文件中。
第四点:
使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。
第五点:
实际上cout和cin分别是ostream和istream类型的对象,>>和<<也涉及运算符重载等知识,
这些知识我们我们后续才会学习,所以我们这里只是简单学习他们的使用。后面我们还有有
一个章节更深入的学习IO流用法及原理。
第六点:
早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应
头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,
规定C++头文件不带.h;旧编译器(vc 6.0)中还支持格式,后续编译器已不支持,因
此推荐使用+std的方式。
第七点:
std是C++标准库的命名空间,如何展开std使用更合理呢?在日常练习中,建议直接using namespace std即可,这样就很方便。 using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对 象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 +
using std::cout展开常用的库对象/类型等方式。四.缺省参数
缺省参数的概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实
参则采用该形参的缺省值,否则使用指定的实参。缺省参数的例子
如果说只看概念的话,大家可能不是很能理解这里的缺省参数是什么,那么我们这里就通过下面的代码来带着大家来理解一下:
#includevoid func(int x ) { std::cout << x << std::endl; } int main() { func(10); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
之前我们的c语言在声明函数的时候,后面的括号一般都只写一些参数的类型加参数的名字,并不会给这些参数进行赋值,而且我们在调用这个函数的时候也得在这个函数后面的括号里面填入数据,比如说上面的代码,我们给这个函数传的值是10,所以他就会把这个10赋值给对应位置上的x,然后在这个函数的里面打印出这个x的值。但是我们的c++对此做出了一个小小的改变,他允许在声明的时候给这些形参进行赋值,就好比这样:
#includevoid func(int x=10) { std::cout << x << std::endl; } int main() { func(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们在声明的过程中对形参进行了赋值,因为这个赋值,所以我们在调用这个函数的时候可以不对其进行传参,如果不传参的话这个形参的值就是我们声明时赋值给他的10,我们可以运行一下上面的代码来看看:
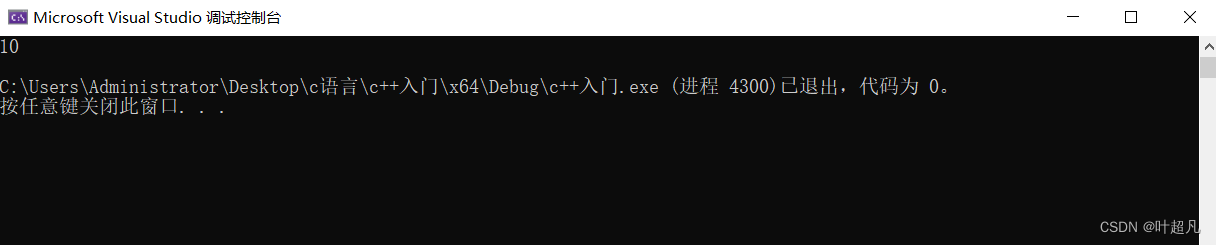
我们这里在调用函数的时候是没有对其形参进行传参的,但是我们这里依然打印出来了这个形参的值并且为10,那么我们就称这个10为缺省值,称这个已经提前赋值的形参为缺省参数。当然如果我们这里对这个函数进行传参的话,那形参的值还是为我们传的那个值,比如说我们传个20那这个代码的运行结果就成了这样:

打印的就是我们传给他的值。为什么会有缺省参数
大家看了上面的讲解大家应该能够理解这里缺省参数是什么?就是缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。但是这里大家肯定会有个疑问这有什么用呢?我每次都赋值不就够了吗?如果大家这么想的话大家可能忘了我们在学习数据结构的时候遇到的这个情况:就是顺序表那章我们一开始存储数据的时候不知道要开辟一个多大的空间来存储我们这里的数据,所以我们只能一开始将其初始化为4,然后每次扩容都将其存储能力扩大两倍,但是这样的作法就存在着一个问题,如果我们一开始要存储的数据就非常的多的话,他他从4开始是不是就得不停的用realloc来进行扩容啊,而且我们还知道的realloc的扩容他是有代价的,不停的调用这里的realloc会导致效率的下降,所以我们c语言实现这个功能的时候是有点力不从心的,我们当时实现的代码就是这样:
void SLCheckCapacity(SL* psl) { assert(psl); if (psl->capacity == psl->size) { psl->capacity = psl->capacity == 0 ? 4: psl->capacity * 2; SLDataType* p1 = realloc(psl->a, (psl->capacity)*sizeof(SLDataType)); //注意这里是容量乘以元素的大小,不是单独的一个容量 if (p1 == NULL) { perror("realloc fail"); } psl->a = p1; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
void SLInit(SL* psl) { assert(psl); psl->a = NULL; psl->capacity = psl->size = 0; }- 1
- 2
- 3
- 4
- 5
- 6
但是我们的c++里面有了这个缺省参数的话我们这里的情况就会好很多,我们可以对这里的初始化函数进行一下简单的改进,我们在这个函数里面多加一个参数number,并且将这个参数赋值给一个缺省值为4,然后在这个函数里面我们就来对其开辟一个与number相关的一个动态空间,我们这里的代码就如下:
void StackInit(ST* ps, int defaultCP=4) { ps->a = (int*)malloc(sizeof(int)*defaultCP); assert(ps->a); ps->top = 0; ps->capaicty = defaultCP; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
那这样的话我们在使用这个顺序表时候如果我们知道数据非常的多大概有10w个的话,我们是不是就能在初始化的时候直接传一个10w过去,这样的话我们就能一下开辟一个大小为10w的空间出来,就不用不停的扩容了,那这样的话代码的效率是不是就高多了啊,那这就是我们缺省参数的一个意义,希望大家能够理解。
缺省参数的分类
因为我们的参数不止一个,所以我们在给缺省值的时候也就会有不同的情况,那么我们根据不同的情况对其进行了分类,分为全缺省参数和半缺省参数。
全缺省参数
那我们这里根据名字便可以知道这个全缺省参数的意思就是函数声明中的每个参数都被赋予了缺省值,比如说下面的代码:
#includevoid func(int a = 10, int b = 20, int c = 30) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; } int main() { func(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这就是一个全缺省的函数,在调用这个函数的时候我们可以一个参数都不传他也会正常的运行并且打印出我们赋值给他的缺省值:
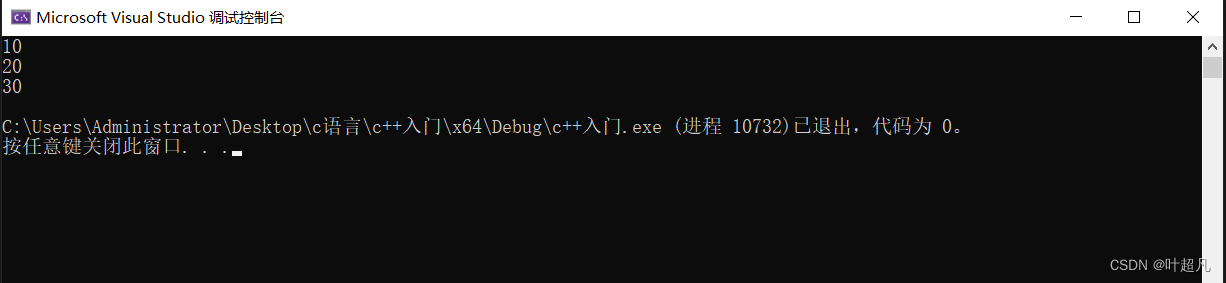
但是如果我们想对其进行传参的话也是可以的,比如说这样:#includevoid func(int a = 10, int b = 20, int c = 30) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; } int main() { func(40,50,60); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们再来运行一下这个代码我们就可以看到这里a b c的三个值就发生了改变:

但是这时有小伙伴就想啊,我这里能不能对a和c进行传值,但是不对b进行传值呢?比如说这样:#includevoid func(int a = 10, int b = 20, int c = 30) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; } int main() { func(40, , 60); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们将这个代码运行一下就可以发现我们这里报出了错误:

所以通过这个我们就知道一件事就是我们的全缺省不能跳着进行传参只能连续的进行传参,这个连续没必要连续到底,但是他中间不能断,那么这就是我们的全缺省参数的传参以及形式大家这里注意一下。半缺省参数
与之对应如果我们没有对每一个参数都赋予缺省值而是赋值一部分的话,我们就称为半缺省参数,比如说下面的代码:
#includevoid func(int a , int b = 20, int c=30 ) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; } int main() { func(40); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们这里就没有对a进行赋值,而对后面的两个参数赋予了缺省值,这就是半缺省参数,那么这样我们在调用这个函数的时候我们就不得不传一个参数过去,所以我们这里在调用的时候就得传一个40进去,那么我们这个代码的运行的结果就是这样:

但是大家有没有想过一个问题,我们上面说缺省参数在对其进行传参的时候是不能跳着传的,那大家在这里有没有想过一件事就是如果我们这里的缺省值是从左往右给的话,那我们这里的缺省值给的不就没有意义了吗?比如说这样void func(int a=10, int b = 20, int c) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; }- 1
- 2
- 3
- 4
- 5
- 6
我们这个函数里的c没有赋予缺省值,但是前面的赋予了,所以我在调用这个函数的时候就必须得给c传值,但是我们这里又不能跳着传值,所以我们在给c传值前必须得先给a和b进行传值,而我们的a和b本省又是缺省值,那这么看的话我们这里a和b给的缺省值不就有点鸡肋了嘛,所以在我们半缺省参数中有这么一个规定就是缺省值的赋值只能从右往左进行赋值,而且还必须得是连续的,这里大家可以操作理解一下。
注意事项
第一点:
缺省值必须得是常量或者全局变量。
第二点:
缺省不能在函数的声明或者定义中同时出现。我们这里主要的原因就是为了防止程序员写错了在声明中缺省值为4,而在定义中缺省值却写成了5,这样就会导致错乱,所以我们这里就规定在.h文件中写上缺省值,而定义中不加缺省值。五.函数的重载
为什么会有函数重载
大家在学c语言的时候有没有发现一个问题就是,我们的函数规定的是不是有点太死板了,比如说我要写一个加法函数,这个函数的作用就是实现两个整型的相加,那么我们的函数就得写成这样:
int add(int x, int y) { return x + y; }- 1
- 2
- 3
- 4
但是有时候我们不仅仅要相加整数,我们还得相加两个浮点型的小数,那么我们这里的c语言就不仅仅得改这里的形参的类型和返回的类型了,我们还得修改这里的名字,比如说我们下面的代码:
double add1(double x, double y) { return x + y; }- 1
- 2
- 3
- 4
那如果是两个字符型的相加呢?我们是不是就又得取一个新的名字了啊,那么这不就非常的麻烦嘛对吧,取名字麻烦,等我调用这些函数也非常的麻烦,所以我们就发现c语言的一个问题就是我们在用函数来实现一个功能,但是这个功能在面向不同的数据类型或者个数的时候往往得创建多个函数出来,那么为了解决这个问题我们的c++就提出来了函数重载这个概念。
函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。函数重载的例子
通过上面的概念我们知道了实现函数重载的前提是同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,那么我们这里就来一一举例子:
第一个:参数的类型不同int add(int x, int y) { return x + y; } double add1(double x, double y) { return x + y; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么我们上面的这两个加法函数就构成了重载,他们的函数名相同,参数的个数相同,但是他们的参数类型不同,所以构成了重载。
第二个:参数的个数不同void f() { cout << "f()" << endl; } void f(int a) { cout << "f(int a)" << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么我们这两个函数的名字相同,但是函数中的参数不同所以我们这里也可以构成重载。
第三种:类型的顺序不同void f(int a, char b) { cout << "f(int a,char b)" << endl; } void f(char b, int a) { cout << "f(char b, int a)" << endl; }- 1
- 2
- 3
- 4
我们这里的函数名相同,参数的类型相同参数的数目相同,但是他的类型的顺序不同所以我们这里也可以构成重载,但是这里要注意的一点就是我们这里的顺序不同指的是类型的顺序不同,大家不要以为形参名的顺序不同也能构成重载了啊,这个是不行的。
函数重载的奇异性
大家首先来看看下面的代码:
void func() { cout << "func()" << endl; } void func(int a = 0, int b = 1) { cout << "func(int a, int b)" << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们首先来看判断一个问题就是我们这两个函数是否构成函数的重载,判断重载就得先来判断一下函数的参数是否满足条件,那我们发现这两个函数的参数个数不一样,函数名却相同所以我们这里就可以构成函数的重载,既然可以构成函数重载的话,那按道理我们这里就应该可以正常地调用这两个函数,比如说下面地代码我们就可以正常地调用第二个func函数:
#includeusing namespace std; void func() { cout << "func()" << endl; } void func(int a = 0, int b = 1) { cout << "func(int a, int b)" << endl; } int main() { func(10, 20); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们可以看到这里正常地执行了第二个函数:

那按照同样地道理我们这里应该也可以调用这里地第一个函数,第一个函数没有参数所以我们这里在调用他地时候就不用传参,那么我们地代码就如下:#includeusing namespace std; void func() { cout << "func()" << endl; } void func(int a = 0, int b = 1) { cout << "func(int a, int b)" << endl; } int main() { /*func(10, 20);*/ func(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
但是我们将这个代码运行起来就会发现这里报出来错误:
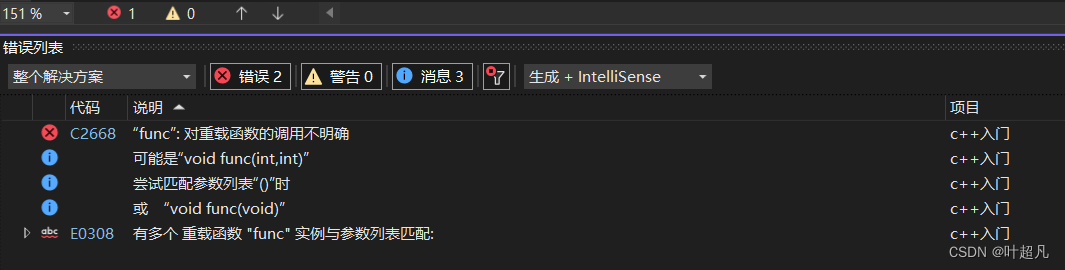
我们仔细看一下这个错误就会发现它这里说地就是对重载函数地调用不明确,这是什么意思啊?那我们把这句话换一个意思说就是编译器不知道要调用哪个函数,那为什么会出现这种情况?我们这里要调用第一个func函数,这个函数在声明地时候事没有参数地,所以我们在调用它地时候就不对其提供实参,但是这时候来看看第二个函数它虽然是有参数的,但是他的两个参数我们都对其提供了缺省参数,所以我们在调用第二个函数的时候可以对其进行传参,也可以不对其传参,但是这样的话我们调用第一个函数的时候,也会调用第二个函数啊,所以我们这里的编译器就会报出错误说对重载函数的调用不明确,所以我们这里就称为重载函数的奇异性,这里确实构成了重载但是我们在调用函数的时候依然会出现问题,所以大家在写重载函数的时候得注意一下这个问题。重载函数的底层原理
通过之前的学习我们知道函数在调用的时候都会通过call这个指令来调用一些函数,比如说我们下面的代码:
#includeint add(int x, int y) { return x + y; } int main() { add(2, 3); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
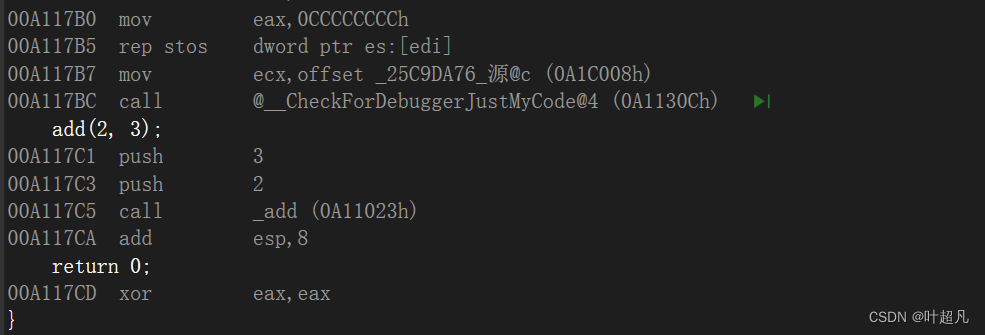
- 10
我们对其转到反汇编就可以看到这里的call指令,这个指令就是用来调用add这个函数后面的一连串字母加数字就是对应的这个函数的地址
通过之前的学习我们还知道程序在编译的过程中会生成一个东西叫符号表,这个符号表里面就记录着各种函数和全局变量的名字和地址,而我们c语言在记录这些地址的时候就非常的简单对函数名做出来的修改很少,所以当我们用c语言写两个函数名一样但是参数不同的函数的时候我们的符号表上对应的函数是一样的,但是我们的编译器他是不允许符号表上有两个同样的名字,所以我们的c语言是不支持函数的重载的,所以我们的c++就对其进行了升级,他就对这个符号表上的名字进行了一些修改,之前c语言符号表上的名字可能就是简简单单的一个名字本身,但是我们的c++在函数名本省的情况下还将其参数也加了上去比如说我们下面的图片: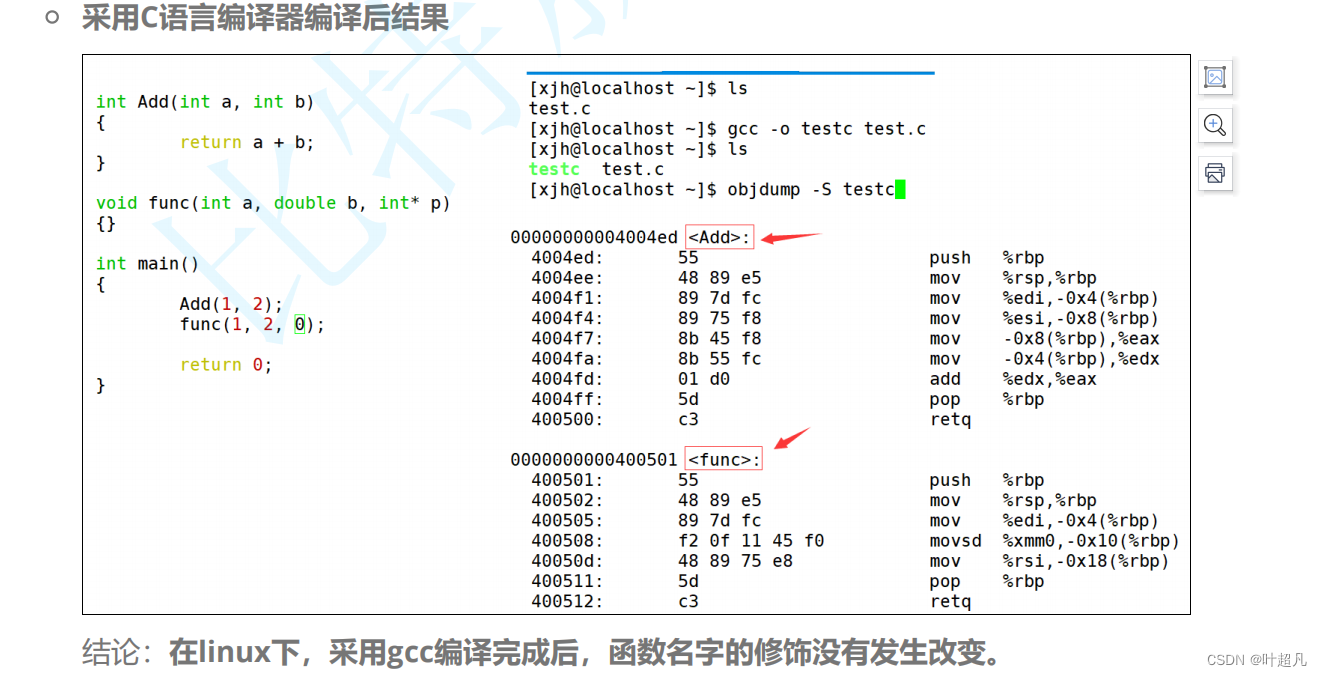
而我们的c++编译的结果就如下:

那这里的做出的改变是什么呢?我们看看我们发现函数的名字后面有多了几个字符,这个字符就是我们函数参数的缩写,我们第一个函数的参数是两个int所以这里的就在后面加了两个i,因为我们这个add函数名是三个字母所以我们这里还在函数名前面加了一个3,那我知道的改变就是这些,至于前面的z是啥我也不知道,那通过这个改变大家应该能够明白为什么我们函数重载的条件得是参数个数 或 类型 或 类型顺序不同了,因为这些不同带来的结果就是在符号表中对应的名字不同,这样我们调用的时候就可以根据参数的类型来找这些我们想调用的同名的重载函数了。那这就是函数重载的底层原理。有关函数重载的一个问题
大家有没有想过一个问题就是:为什么函数名相同 参数相同 但是返回值不同的函数却不能构成重载呢?有些小伙伴说啊,因为我们这里的底层逻辑没有对返回值添加相应的修改,所以无法构成重载,但是如果我们这里对其添加相应的修改呢?我们不同的返回值就在符号表的名字上加上不同的标识,这样不也可以吗?但是为什么我们的编译器没有这么做呢?那么大家这样想,如果我们这里有两个函数他们的参数个数一样类型一样顺序也一样的话,就返回值的类型不同,那我们在对其进行调用的时候是不是参数就一样了啊,那我们在调用函数的时候编译器怎么知道我想调用的是返回值为int类型的函数还是返回值为double的函数呢?对吧所以这就是不能构成重载的原因,希望大家能够理解。
-
相关阅读:
【100天精通Python】Day67:Python可视化_Matplotlib 绘制动画,2D、3D 动画 示例+代码
【问题记录】解决Git上传文件到GitHub时收到 “GH001: Large files detected” 错误信息!
关于#matlab#的问题:图1是一个污染物动态演变模型
教你VSCode如何快速对齐代码、格式化代码
C++ Reference: Standard C++ Library reference: C Library: cfenv: fesetround
Could not get a resource from the pool
kafka 动态扩容现有 topic 的分区数和副本数
html web前端,点击发送验证码,按钮60秒倒计时
排队(单调队列+二分)
VauditDemo靶场代码审计
- 原文地址:https://blog.csdn.net/qq_68695298/article/details/127452284
