-
初识CNN卷积神经网络
机器学习
深度学习
人工神经网络
神经元
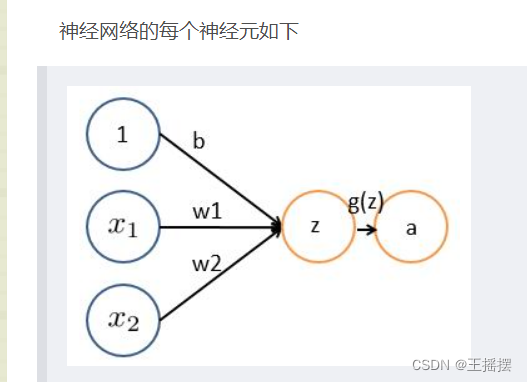
神经网络是由大量的神经元相互连接而成的,每个神经元接收线性组合的输入后,给每个神经元加上非线性的激活函数,进行非先线性变换后输出。
- 每两个神经元之间的链接代表加权值,成为权重。
- 不同的权重和激活函数,会导致神经网络不同的输出。
【实例】
让神经网络来识字- 举个手写识别的例子,给定一个未知数字,让神经网络识别是什么数字。
- 此时的神经网络的输入由一组被输入图像的像素所激活的输入神经元所定义。
- 在通过非线性激活函数进行非线性变换后,神经元被激活然后被传递到其他神经元。
- 重复这一过程,直到最后一个输出神经元被激活。从而识别当前数字是什么字。
举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有二个因素,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示::是否有喜欢的演唱嘉宾。 = 1 你喜欢这些嘉宾, = 0 你不喜欢这些嘉宾。嘉宾因素的权重 = 7
:是否有人陪你同去。 = 1 有人陪你同去, = 0 没人陪你同去。是否有人陪同的权重 = 3。
这样,咱们的决策模型便建立起来了:g(z) = g( * + * + b ),g表示激活函数,这里的b可以理解成 为更好达到目标而做调整的偏置项。基本形式
- x1,x2表示输入向量
- w1,w2表示权重
- b为偏置bias
- gz为激活函数
- a为输出
决策模型的建立
决策模型便建立起来了:g(z) = g( * + * + b ),g表示激活函数,这里的b可以理解成 为更好达到目标而做调整的偏置项
一开始为了简单,人们把激活函数定义成一个线性函数,输出输入都是线性变换。后来实际应用中发现,线性激活函数太过局限,人们开始引入非线性变换。
激活函数
- sigmoid
- tanh
- relu
sigmod函数介绍
sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
可以把激活函数看做是一种。分类的概率。
神经网络
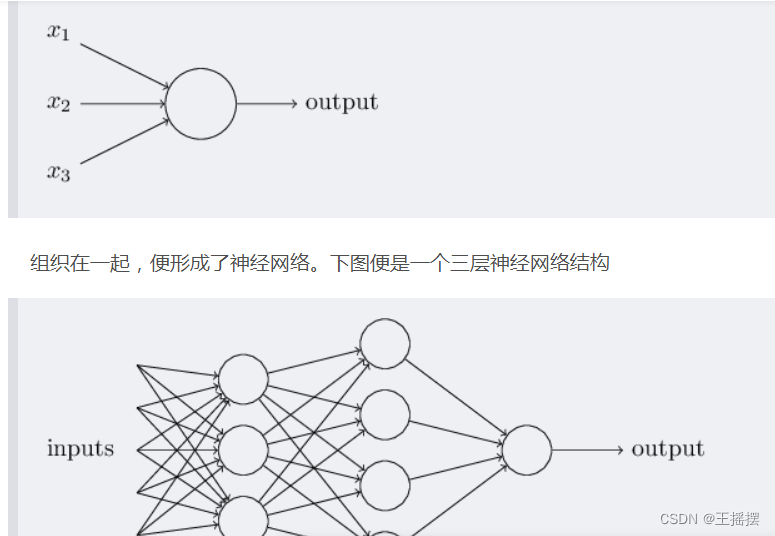
卷积神经网络之层级结构
CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车
- 左边:是输入层
- 去均值
- 归一化
- PCA白化
- 中间:
- CONV卷积计算层
- RELU激励层
- POOL池化层
- 右边:全连接层
CNN核心:卷积计算层
CNN是如何进行识别的?
对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。
- 每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。
- 不同的Feature匹配图像中不同的特征
什么是卷积?
对
图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作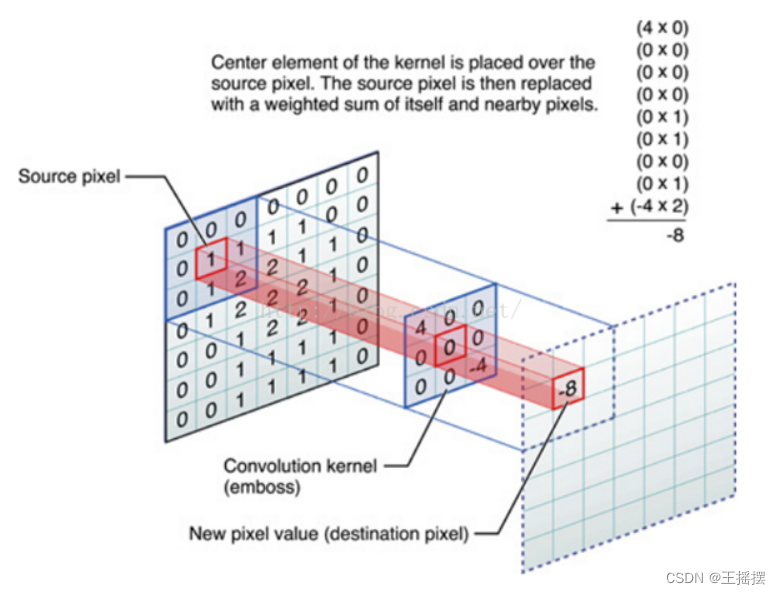
滤波器:带着一组固定权重的神经元,多个滤波器叠加变成为了卷积层。
图像上的卷积
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后等到新的二维数据。
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
GIF上的卷积
- depth=2,意味着有两个滤波器。
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
- zero-padding=1
池化POOL层
池化,简言之,即取区域平均或最大,
-
相关阅读:
21.[STM32]I2C协议弄不懂,深挖时序图带你编写底层驱动
基于最小二乘法和SVM从天气预报中预测太阳能发电量(Matlab代码实现)
机器人课程教师面对的困境有哪些(补充)
Python **运算符(python**kwargs:参数解包)(kwargs:keyword arguments)
数据结构之顺序表
关于分子力场中键能项和角能项的思考
使用 Nuxt 构建简单后端接口及数据库数据请求
paddleDetection训练自己的模型
工业动态界面设计 GLG Toolkit 4.2 Crack-GlgCE.4.2_x64
[大模型实战 03预备] 云端炼丹房 1:Google Colab 上手指南
- 原文地址:https://blog.csdn.net/weixin_44943389/article/details/127573574