-
生产者消费者模式进阶-设计模式-并发编程(Java)
1 模式简介
数据的提供方形象的称为生产者,它生产数据,而数据的加工方则相应的称为消费者,它“消费”数据。实际上,生产者生产数据的速率和消费者消费数据的速率往往是不均衡的。为了避免生产者和消费者中处理速率快的一方等待速率慢的一方,Producer-Consumer模式通过在生产者和消费者之间引入通道(Channel)对二者进行解耦:生产者将其生产的数据放入通道,消费者从相应的通道中取出数据进行消费,生产者和消费者各自运行在各自的线程,从而使双方处理速率互不影响。
2 模式架构
2.1 类图
Producer-Consumer模式的核心是通过通道对数据的生产者和消费者解耦,使二者不直接交互,从而使二者的处理速率相对来说互不影响。为了讨论方便,以下将生产者忘通道内存储的数据称为产品(Product)。
Producer-Consumer模式主要参与者如下有以下几种,类图如图2-1所示:
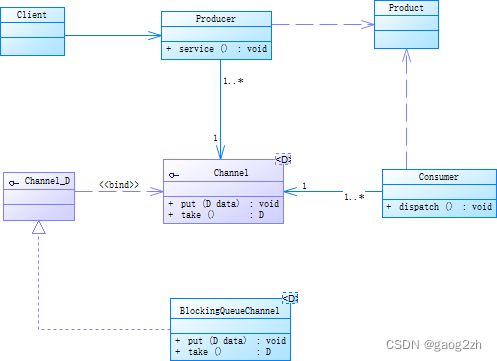
- Producer:生产者,负责生成相应的产品并将其存入通道。其主要职责和方法如下:
- service:生产者对外暴露的服务方法。
- Product:生产者生成的数据或者任务。其具体类型由应用程序决定。
- Channel:对通道的抽象。通道充当生产者和消费者之间的仓储用于产品的传递,它可以是有存储容量限制的。该接口的类型参数D表示产品的类型。该接口的主要职责及方法如下:
- put:将产品放入通道。
- take:从通道取出一个产品。
- BlockingQueueChannel:基于阻塞队列(Blocking Queue)的Channel实现。其主要职责和方法如下:
- put:将产品放入通道。当队列满时,该方法将当前线程挂起直至队列不满时被唤醒。
- take:从通道中取出一个产品。当队列为空时,该方法将当前线程挂起直至队列非空时被唤醒。
- Consumer:消费者,负责对产品进行处理。其主要职责及方法如下:
- dispatch:从通道中获取产品并对其处理。
2.2 Producer生成序列图
Producer-Consumer模式生产者生产产品序列图如图2.2-1所示:
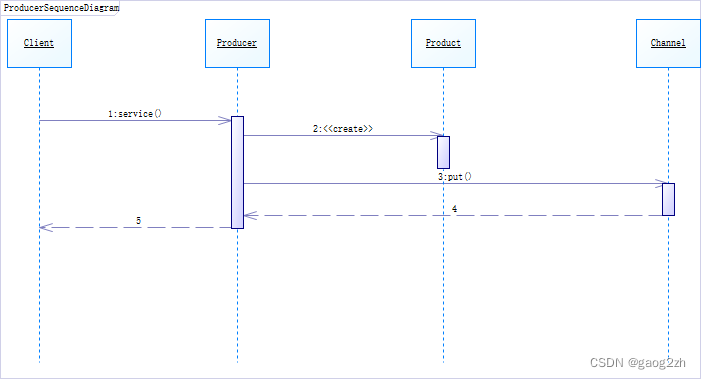
- 第一步:客户端代码调用Producer参与者实例的service方法。
- 第2~4步:service方法生成的产品,调用Channel参与者实例的put方法吧产品存入通道。
- 第5步:service方法返回。
2.3 Consumer消费序列图
Producer参与者实例通常运行在客户端线程中,而Consumer参与者实例则运行在其专门的工作者线程中。Producer-Consumer模式中的产品消费序列图如图2.3-1所示:
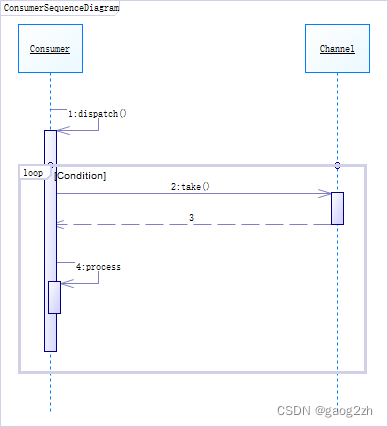
- 第一步:Consumer参与者实例的工作者线程开始运行,其dispatch方法被调用。dispatch方法会重复执行2~4.
- 第2~4步:dispatch方法调用Channel参与者实例调用take方法取出一个产品,并对其进行处理。
3 案例分析
3.1 场景
某内容管理系统需要支持对文档附件中的文件(格式包括Word、 PDF)进行全文检索(Full-text Search)。该系统中,附件会被上传到专用的文件服务器上,对附件进行全文检索的功能模块也是部署在文件服务器上的。因此,与一份文档相关联的附件被上传到文件服务器之后,我们还需要对这些附件生成相应的索引文件以供后面对附件进行全文检索时使用。对附件生成索引的过程包括文件IO(读取附件文件和写索引文件)和一些计算(如进行分词),该过程相对于将上传的附件保存到磁盘中而言也快不到哪里。因此,我们不希望对附件生成索引文件这个操作的快慢影响系统用户的体验(如增加了用户等待系统给出操作反馈的时间)。此时,Producer-Consumer模式可以排上用场:我们可以把负责附件存储的线程看作生产者,其“产品”是一个已经保存到磁盘的文件。另外,我们引入一个负责对已存储的附件文件生成相应索引文件的线程,该线程就相当于消费者,它“消费”了上传到文件服务器的附件文件。
3.2 实现
该案例的代码如3.2-1所示。其中,负责对上传的附件进行存储的类AttachmentProcessor,它相当于Producer-Consumer模式中的 Producer参与者,负责对附件文件生成索引文件的线程indexingThread则相当于 Producer-Consumer模式中的Consumer参与者。AttachmentProcessor 的实例变量channel相当于Channel参与者实例。AttachmentProcessor将上传的附件保存完毕后,就将相应的文件存入通道channel,便返回了,它不会等待该文件相应的索引文件的生成,因此减少了系统用户的等待时间。而相应文件对应的索引文件由Consumer 的工作者线程 indexingThread 负责生成。工作者线程 indexingThread 使用了Two-phase Termination模式(参见第5章)以实现该线程的优雅停止。
代码3.2-1AttachmentProcessor如下所示:
import com.gaogzhen.designPattern.twoPhraseTermination.AbstractTerminatableThread; import java.io.*; import java.text.Normalizer; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.TimeUnit; /** * @author Administrator * @version 1.0 * @description 附件处理 * @date 2022-10-27 09:50 * 模式角色:Producer */ public class AttachmentProcessor { private final String ATTACHMENT_STORE_BASE_DIR = "/home/attachments/"; /** * 模式角色:Channel */ private final Channel<File> channel = new BlockingQueueChannel<File>(new ArrayBlockingQueue<File>(200)) ; /** * 模式角色:Consumer */ private final AbstractTerminatableThread indexThread = new AbstractTerminatableThread() { @Override protected void doRun() throws Exception { File file = null; file = channel.take(); try { indexFile(file); } catch (Exception e) { e.printStackTrace(); } finally { terminationToken.reservations.decrementAndGet(); } } private void indexFile(File file) throws InterruptedException { // 省略其他代码 // 模拟生成索引文件的时间消耗 Random r = new Random(); TimeUnit.MILLISECONDS.sleep(r.nextInt(100)); } }; public void init() { indexThread.start(); } public void shutdown() { indexThread.terminate(); } public void saveAttachment(InputStream in, String documentId, String originalFilename) throws IOException { File file = saveAsFile(in, documentId, originalFilename); try { channel.put(file); } catch (InterruptedException e) { e.printStackTrace(); } indexThread.terminationToken.reservations.decrementAndGet(); } private File saveAsFile(InputStream in, String documentId, String originalFilename) throws IOException { String dirName = ATTACHMENT_STORE_BASE_DIR + documentId; File dir = new File(dirName); dir.mkdirs(); File file = new File(dirName + "/" + Normalizer.normalize(originalFilename, Normalizer.Form.NFC)); if (!dirName.equals(file.getCanonicalFile().getParent())) { throw new SecurityException("Invalid OriginalFilename:" + originalFilename); } try(BufferedInputStream bis = new BufferedInputStream(in); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file));) { byte[] buf = new byte[2048]; int len = -1; while ((len = bis.read(buf)) > 0) { bos.write(buf, 0, len); } bos.flush(); } catch (IOException e) { e.printStackTrace(); } return file; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
代码3.2-2Chanel如下:
/** * @author Administrator * @version 1.0 * @description 通道 * @date 2022-10-26 09:21 */ public interface Channel<D> { /** * 往通道中放入一个产品 * @param data 产品 * @throws InterruptedException 打断异常 */ void put(D data) throws InterruptedException; /** * 从通道中取出一个产品 * @return 产品 * @throws InterruptedException 打断异常 */ D take() throws InterruptedException; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
代码3.2-3 BlockingQueueChannel如下:
import java.util.concurrent.BlockingQueue; /** * @author Administrator * @version 1.0 * @description 基于阻塞队列的通道 * @date 2022-10-26 09:23 */ public class BlockingQueueChannel<D> implements Channel<D> { private final BlockingQueue<D> queue; public BlockingQueueChannel(BlockingQueue<D> queue) { this.queue = queue; } @Override public void put(D data) throws InterruptedException { queue.put(data); } @Override public D take() throws InterruptedException { return queue.take(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4模式的评价和实现考量
Producer-Consumer模式使得“产品”的生产者和消费者各自的处理能力(速率)相对来说互不影响。生产者只需要将其“生产”的“产品”放入通道中就可以继续处理,而不必等待相应的“产品”被消费者处理完毕。而消费者运行在其自身的工作者线程中,它只管从通道中取“产品”进行处理,而不必关心这些“产品”由谁“生产”以及如何“生产”这些细节。因而消费者的处理能力相对来说又不影响生产者,同时又与生产者是松耦合(Loose Coupling)的关系。另一方面,当消费者处理能力比生产者处理能力大的时候,可能出现通道为空的情形,此时消费者的工作者线程会被暂挂直到生产者“生产”了新的“产品”。此时出现了事实上的消费者等待生产者的情形。类似地,当消费者的处理能力小于生产者的处理能力时,通道可能会满,导致生产者线程被暂挂直到消费者“消费”了通道中的部分“产品”而腾出了存储空间。此时出现了事实上的生产者等待消费者的情形。因此,我们说生产者和消费者各自的处理能力相互不影响是相对的。
4.1 通道积压
Producer-Consumer模式中,消费者的处理能力往往低于生产者的处理能力。此情形下随着时间的推移,通道中存储的“产品”会越来越多而出现积压,这好比工厂的生产能力比较大,但是其生产的产品的销售情况却不容乐观。为了更好地平衡生产者和消费者的处理能力,我们需要对消费者处理过慢的情形进行一定的处理。常见的方法包括以下两种。
-
使用有界阻塞队列。使用有界阻塞队列(如 ArrayBlockingQueue 和带容量限制的LinkedBlockingQueue)作为Channel参与者的实现可以实现将消费者处理压力“反弹”给生产者的效果,从而使消费者处理负荷过大时相应的生产者的处理能力也下降一定程度以达到平衡二者处理能力的目的。当消费者处理能力低于生产者的处理能力时,作为通道的有界阻塞队列会逐渐积压到队列满,此时生产者线程会被阻塞直到相应的消费者“消费”了队列中的一些“产品”使得队列非满。也就是出现了生产者的步伐等待消费者的情形。
-
使用带流量控制的无界阻塞队列。使用无界阻塞队列(如不带容量限制LinkedBlockingQueue)作为Channel参与者的实现也可以实现平衡生产者和消费者的处理能力。这通常是借助流量控制实现的,即对同一时间内可以有多少个生产者线程往通道中存储“产品”进行限制,从而达到平衡生产者和消费者的处理能力的目的,如代码4.1-1所示。
-
/** * @author Administrator * @version 1.0 * @date 2022-10-28 10:01 * * 基于Semaphore的支持流量控制的通道实现 */ public class SemaphoreBasedChannel<D> implements Channel<D> { private final BlockingQueue<D> queue; private final Semaphore semaphore; public SemaphoreBasedChannel(BlockingQueue<D> queue, Semaphore semaphore) { this.queue = queue; this.semaphore = semaphore; } @Override public void put(D data) throws InterruptedException { semaphore.acquire(); try { queue.put(data); } finally { semaphore.release(); } } @Override public D take() throws InterruptedException { return queue.take(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.2 工作窃取算法
Producer-Consumer模式中的通道通常可以使用队列来实现。一个通道可以对应一个或者多个队列实例。本章案例中(代码见清单7-1),一个通道仅对应一个队列(ArrayBlockingQueue)实例。这意味着,如果有多个消费者从该通道中获取“产品”,那么这些消费者的工作者线程实际上是在共享同一个队列实例,而这会导致锁的竞争,即修改队列的头指针时所需要获得的锁而导致的竞争。如果一个通道实例对应多个队列实例,那么就可以实现多个消费者线程从通道中取“产品”的时候访问的是各自的队列实例。此时,各个消费者线程修改队列的头指针并不会导致锁竞争。
一个通道实例对应多个队列实例的时候,当一个消费者线程处理完该线程对应的队列中的“产品”时,它可以继续从其他消费者线程对应的队列中取出“产品”进行处理,这样就不会导致该消费者线程闲置,并减轻其他消费者线程的负担。这就是工作窃取(Work Stealing)算法的思想。代码4.2-1展示了一个工作窃取算法的示例代码。package com.gaogzhen.designPattern.producerConsumer.workSteal; import com.gaogzhen.designPattern.twoPhraseTermination.AbstractTerminatableThread; import com.gaogzhen.designPattern.twoPhraseTermination.TerminationToken; import java.util.Random; import java.util.concurrent.BlockingDeque; import java.util.concurrent.LinkedBlockingDeque; import java.util.concurrent.TimeUnit; /** * @author Administrator * @version 1.0 * @description 生产者 * @date 2022-10-28 10:38 */ public class WorkStealExample{ private final WorkStealingEnabledChannel<String> channel; private final TerminationToken token = new TerminationToken(); public WorkStealExample() { int nCpu = Runtime.getRuntime().availableProcessors(); int consumerCount = nCpu / 2 + 1; BlockingDeque<String>[] managedQueues = new LinkedBlockingDeque[consumerCount]; // 通道绑定多个队列 channel = new WorkStealingChannel<String>(managedQueues); Consumer[] consumers = new Consumer[consumerCount]; for (int i = 0; i < consumerCount; i++) { managedQueues[i] = new LinkedBlockingDeque<String>(); consumers[i] = new Consumer(token, managedQueues[i]); } for (int i = 0; i < nCpu; i++) { new Producer().start(); } for (int i = 0; i < consumerCount; i++) { consumers[i].start(); } } public void doSomething() { } public static void main(String[] args) throws InterruptedException { WorkStealExample wse = new WorkStealExample(); wse.doSomething(); TimeUnit.MILLISECONDS.sleep(2000); } private class Producer extends AbstractTerminatableThread { private int i = 0; @Override protected void doRun() throws Exception { channel.put(String.valueOf(i++)); token.reservations.incrementAndGet(); } } private class Consumer extends AbstractTerminatableThread{ private final BlockingDeque<String> workQueue; private final Random r = new Random(); public Consumer(TerminationToken token, BlockingDeque<String> workQueue) { super(token); this.workQueue = workQueue; } @Override protected void doRun() throws Exception { String product = channel.take(workQueue); System.out.println("Processing product:" + product); // 模拟耗时 try { TimeUnit.MILLISECONDS.sleep(r.nextInt(100)); } catch (InterruptedException e) { e.printStackTrace(); } finally { token.reservations.decrementAndGet(); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
上述引用的接口WorkStealingEnabledChannel如下代码4.2-2所示:
package com.gaogzhen.designPattern.producerConsumer.workSteal; import com.gaogzhen.designPattern.producerConsumer.fullTextSearch.Channel; import java.util.concurrent.BlockingDeque; /** * @author Administrator * @version 1.0 * @description 可窃取的通道 * @date 2022-10-28 10:18 */ public interface WorkStealingEnabledChannel<P> extends Channel<P> { /** * 从指定队列获取产品 * @param preferredQueue 指定队列 * @return 产品 * @throws InterruptedException 线程中断异常 */ P take(BlockingDeque<P> preferredQueue) throws InterruptedException; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
对应的实现类WorkStealingChannel如下代码4.2-3所示:
package com.gaogzhen.designPattern.producerConsumer.workSteal; import com.gaogzhen.threadPool.BlockingQueue; import java.util.concurrent.BlockingDeque; /** * @author Administrator * @version 1.0 * @description 可窃取通道实现类 * @date 2022-10-28 10:21 */ public class WorkStealingChannel<T> implements WorkStealingEnabledChannel<T> { /** * BlockingDeque */ private final BlockingDeque<T>[] managedQueues; public WorkStealingChannel(BlockingDeque<T>[] managedQueues) { this.managedQueues = managedQueues; } @Override public T take(BlockingDeque<T> preferredQueue) throws InterruptedException { // 优先从指定队列获取产品 T product = null; if (null != preferredQueue) { product = preferredQueue.take(); } int queueIndex = -1; while (null != product) { // 如果队列不存在或者为空,从通道绑定的其他队列获取产品 queueIndex = (queueIndex + 1) % managedQueues.length; BlockingDeque<T> targetQueue = managedQueues[queueIndex]; // 尝试从其他队列获取产品 product = targetQueue.pollLast(); if (preferredQueue == targetQueue) { break; } } if (null == product) { // 随机获取其他队列的产品 queueIndex = (int)(System.currentTimeMillis() % managedQueues.length); BlockingDeque<T> targetQueue = managedQueues[queueIndex]; // 尝试从其他队列获取产品 product = targetQueue.pollLast(); } return product; } @Override public void put(T data) throws InterruptedException { int index = (data.hashCode() % managedQueues.length); managedQueues[index].put(data); } @Override public T take() throws InterruptedException { return take(null); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
4.3 线程的停止
一个具体的 Producer-Consumer 模式实现通常可以看作一个服务。如果该服务中的Producer参与者实例也有其工作者线程,那么该服务的停止就涉及 Producer参与者和Consumer参与者的两种工作者线程的停止。此时,我们需要注意这两种线程的停止顺序:如果先停止Consumer参与者的工作者线程则会导致Producer参与者新“生产”的“产品”无法被处理;如果先停止Producer 参与者的工作者线程又可能使Consumer参与者的工作者线程处于空等待。并且,停止Consumer参与者的工作者线程前是否考虑要等待其处理完所有待处理的“产品”或者将这些“产品”做个备份也是个问题。总的来说,我们可以借助Two-phase Termination模式(第5章)来先停止Producer参与者的工作者线程。当某个服务的所有 Producer参与者的工作者线程都停止之后,再停止该服务涉及的 Consumer 参与者的工作者线程。
4.4 高性能高可靠
本章中我们给出的Producer-Consumer模式实现可以说是一个比较一般的实现。如果应用程序对准备采用Producer-Consumer模式实现的服务有较高的性能和可靠性的要求,那么不妨考虑使用开源的Producer-Consumer模式实现库LMAX Disruptor。
4.5 模式的可复用代码
JDK 1.5引入的标准库类java.util.concurrent. ThreadPoolExecutor可以看成是Producer-Consumer模式的可复用实现。ThreadPoolExecutor内部维护的工作队列和工作者线程相当于Producer-Consumer模式的Channel参与者和Consumer参与者。而ThreadPoolExecutor的客户端代码则相当于Producer参与者。利用ThreadPoolExecutor实现 Producer-Consumer模式,应用代码只需要完成以下几件事情。
- 必需】创建Runnable实例(任务),该实例相当于“产品”。
- 【必需】客户端代码调用ThreadPoolExecutor实例的submit方法提交一个任务,这相当于Producer 往通道中放入一个“产品”。
4.6 Java标准库实例
Java标准库中的类java.io.PipedOutStream和java.io.PipedInputStream 允许一个线程以IO的形式输出数据给另外一个线程。这里,java.io.PipedOutStream、java.io.PipedInputStream分别相当于 Producer-Consumer模式的 Producer参与者和 Consumer参与者。而java.io.PipedOutStream 内部维护的缓冲区则相当于Producer-Consumer模式的 Channel参与者。
5 后记
❓QQ:806797785
⭐️源代码仓库地址:https://gitee.com/gaogzhen/concurrent
参考:
[1]黄文海.Java多线程编程实战指南(设计模式篇)[M].北京:电子工业出版社,2015.10.
- Producer:生产者,负责生成相应的产品并将其存入通道。其主要职责和方法如下:
-
相关阅读:
用python实现基本数据结构【03/4】
统一使用某一个包管理工具,比如yarn pnpm
PAT A1013 Battle Over Cities分数 25(连通块数量,割点是针对连通块的,不是整个图)
Windows10安装MySQL5.7.43
【TcaplusDB知识库】TcaplusDB技术支持介绍
山西青年杂志山西青年杂志社山西青年编辑部2022年第16期目录
1109. 航班预订统计
Java并发-满老师
半导体划片机工艺应用
【LoRa-温湿度光照数据无线传输(点对多通讯)】
- 原文地址:https://blog.csdn.net/gaogzhen/article/details/127568018
