-
数据结构 | 算法的时间复杂度与空间复杂度【通俗易懂】

大家好,本文我们将进入数据结构时间复杂度与空间复杂度,希望能带你一破复杂度求解的难关🚪
⌚算法效率
📕如何衡量一个算法的好坏
- 对于算法,相信大家在学习数据结构的时候就已经接触过不少了,就是对于一个问题的计算方法,那我们知道,对于一个问题的计算方法都多种多样的,有高效的计算方法,自然也有拙劣的计算方法,那我们怎么去判别一个算法的性能和效率呢?
- 通过一段代码先来看看
- 下面这段代码是通过递归去求解斐波那契数列。可能在我们的认知看来一个计算方法写的越多越厉害,也就效率越高;面对下面的这段代码,你可能会认为它是一个很简单的代码,复杂度并不是很高,但是却恰恰相反,它的时间复杂度为O(2N),呈现的是一个指数级别的增长
你想知道这是为什么吗?那就跟我来吧,带你真正学会计算时间与空间复杂度🖊
long long Fib(int N) { if(N < 3) return 1; return Fib(N-1) + Fib(N-2); }- 1
- 2
- 3
- 4
- 5
- 6
📕算法的复杂度
- 上面这段代码我们讲到了其时间复杂度为O(2N),其实比它复杂度高的算法还有很多,但比较的不仅仅是时间复杂度,还有空间复杂度,下面给出这两个复杂度的定义
👉【时间复杂度】主要衡量一个算法的运行快慢
👉【空间复杂度】主要衡量一个算法运行所需要的额外空间
- 在早些年计算机还不是很发达的时候,计算机内部的存储容量是很小的,只有几K,甚至几个字节,可不会像我们现在的硬盘这么大的容量,所以那时候写一个算法对于空间复杂度还是会有所考虑。但是经过这些年计算机行业的飞速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
- 因此对于一个算法,我们更加注重的是时间复杂度,而不会刻意地去计算空间复杂度,一般这个空间复杂度的大小都是O(1),大一些的话也就O(N),不会特别地大到哪里去
📕复杂度在校招中的考察
- 对于数据结构,那在校招中是很重要的一门课程,考点也会涉及的比较多,下面有一篇面试腾讯的学长所描述的面试经过,以及算法题的考核,可以看到,都会涉及到复杂度的知识,所以复杂度这一块是学习数据结构与算法的核心,也是大家打好数据结构基础最重要的一块,接下去让我们正式地进入复杂度的学习
⌚时间复杂度
🌳概述
首先我们要来说到的是时间复杂度
- 时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?
- 是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度
🌳如何表示时间复杂度?【大O的渐进表示法】
- 了解了时间复杂度的基本概念后,我们需要学习如何去表示一个算法的时间复杂度,这就要使用到一个表示法,叫做【大O的渐进表示法】。首先对于这个【O】,我们不要O,叫做大O
- 大O符号(Big O notation):是用于描述函数渐进行为的数学符号
- 比如说我们刚才对于这个斐波那契数列,讲到它的时间复杂度为2N,那使用这个大O渐进表示法就是O(2N),那对于一个常数级别的表示法,就是O(1),括号内是算法执行的次数
🌳时间复杂度的分类
刚才说到了时间复杂度如何去表示,而且说到了O(2N)和O(1),那对于这个时间复杂度,还有哪些其他类别呢?我们一起来看看
🐸常数阶O(1)
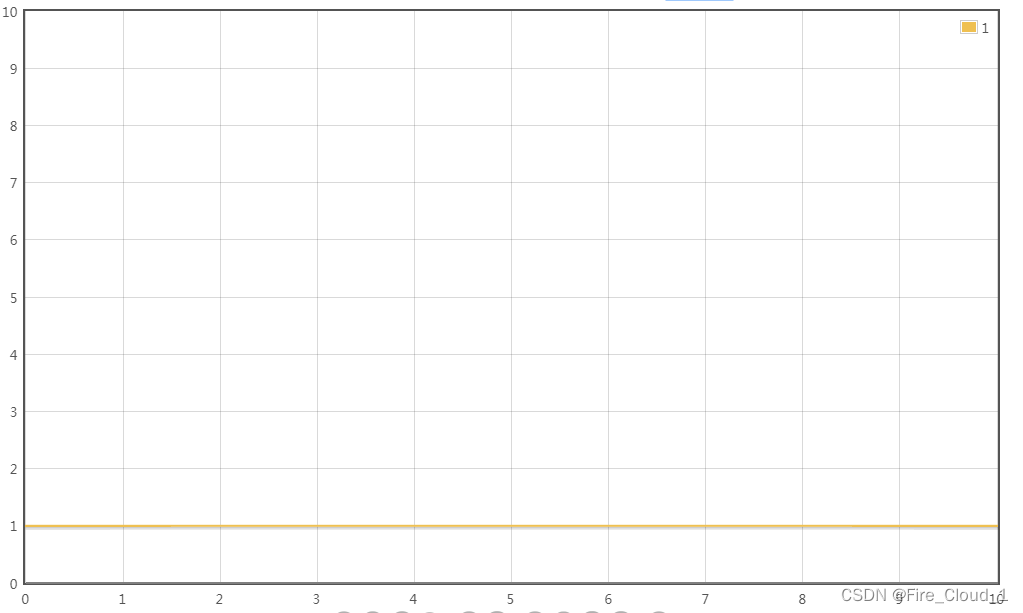
🐸对数阶O(log2N)
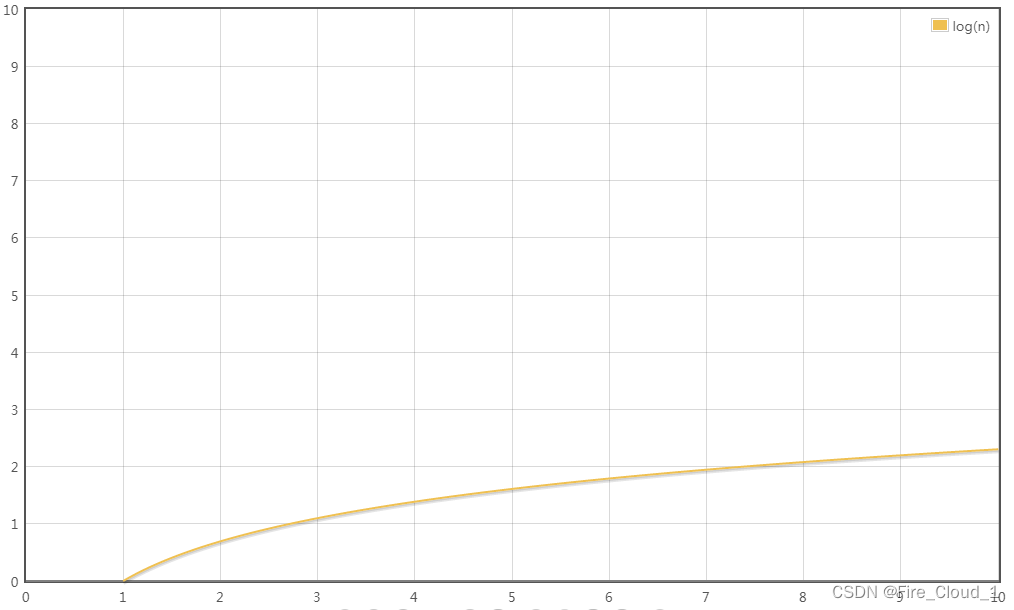
🐸线性阶O(N)

🐸线性对数阶O(Nlog2N)
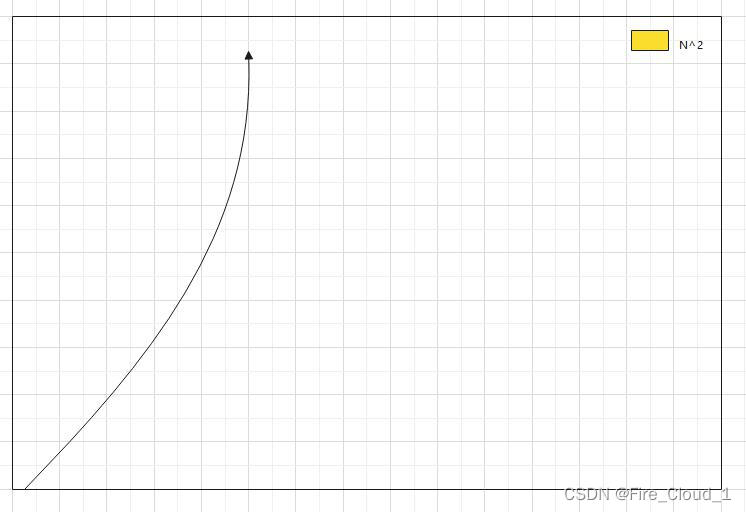
🐸平方阶O(N2)
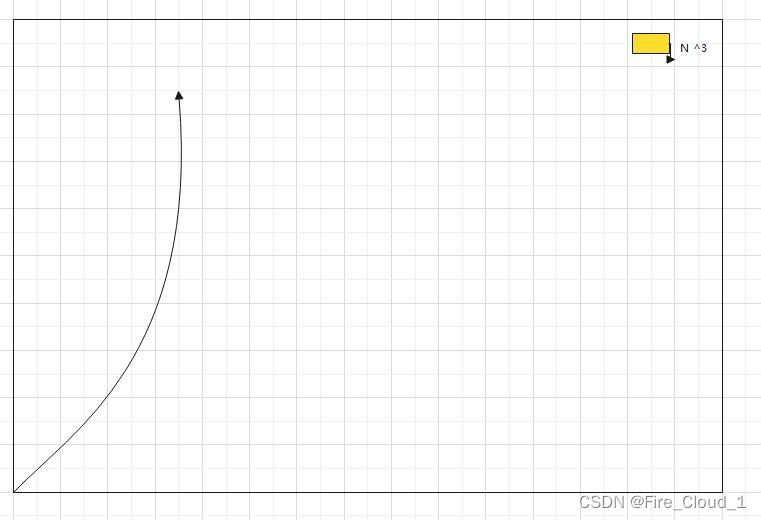
🐸立方阶O(N3)
🐸指数阶O(2N)

🐸乘方阶O(N!)

- 上面就是所有的时间复杂度分类,那它们之间是谁比谁复杂呢?其实根据我一张张画下来的顺序,就可以知晓了👇
O(1) < O(log2N) < O(N) < O(Nlog2N) < O(N2) < O(N3) < O(2N) < O(N!)
🌳推导大O方法【五条重要法则!!!】
知道了有哪些时间复杂度的类别,接下去你的任务就是先搞清楚规则,如何计算得到这些时间复杂度
- 下面罗列了五条规则,这是你一定要牢记的!!!
📚【法则一】:用常数1取代运行时间中的所有加法常数
📚【法则二】:在修改后的运行次数函数中,只保留最高阶项
📚【法则三】:如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶
📚【法则四】:随着输入规模的增加,算法的常数操作可忽略不计,与最高次相乘的常数可以忽略
📚【法则五】:最高次项指数大的,随着N的增长,结果也会变快,N的最高次幂越小,算法效率越高下面在讲解题目的时候会一直用到这些法则,如果翻来翻去不方便可以将其使用QQ截图钉在桌面上
🌳最坏、最好与平均
从这个标题可以看出,我们要了解的是一个算法的最好、最坏以及平均的时间复杂度
- 首先给出它们三个的定义👇
平均情况:任意输入规模的期望运行次数
最坏情况:任意输入规模的最大运行次数(上界)
最好情况:任意输入规模的最小运行次数(下界)
- 然后我们来看一个实例。在一个长度为N的数组中寻找一个执行的,比如是在1~10这10个数中去找
- 首先如果我们要找
1,那直接第一个就是 - 其次如果我们要找
5,那需要遍历一半的数字 - 最后如果我们要找
10,那需要将整个数组遍历一遍才可以找到这个数

- 在时间复杂度层面,这个1指的就是最好情况,10是最坏情况,而5呢,则是平均情况,这么说你对这三者应该是有点概念了
但可能还是有同学不太清楚,这里给出两个生活小案例,你一定可以理解
❤生活小案例一:和女朋友约会
- 好,我们来说一下这个案例,假如有一天呢,你女朋友要约你出去吃饭,大概是想要约在下午四五点这样,但是呢你下午有事情要忙,可能可以忙完,可能刚好要忙到五点,这个时候女朋友要等你的答复,该怎么办呢?
- 这个时候你是要和她约四点、四点半还是五点呢,记住,一定要约五点。你要想万一你工作就已经忙到四点五十了,然后要穿件西装洗把脸整理一下,然后前往等待地点的时候是你女朋友在哪里等你,那她会怎么想呢
- 所以说若是你约到五点,但是你提前四点半就忙完了,然后穿着得非常帅气叼只玫瑰🌹在你女朋友楼下等她,那她只会觉得你很守时,而且提前到了,所以要以最坏的来
对了,醒醒,你没有女朋友🙅【doge】
💻生活小案例二:和老板汇报工作
- 再来说一个生活中的实际小案例。例如说这段时间你老板给你派了一个任务,让你通过代码去实现一段业务逻辑,过几天他来验收,那这个时候呢你打开
Visible Studio开始了你的操作,但是呢这段代码虽然思路很清晰,写起来却不是那么好写,因此在最后完成后你也没有把握说这段逻辑一定是正确的,百分之百不会有差错 - 到了验收的日子,你的老板来问你要代码,然后顺便问你这段代码的稳定性怎么样,会不会出现问题,那你怎么回答呢?若是你回答不会有问题,肯定你的老板当场一定会疯狂夸奖你,但是呢到了程序真正到用户手中的时候,却漏洞百出,用户的体验感很不好,那这个时候老板就要找你喝茶了🍵
- 可当你在验收的时候说【这段程序的代码逻辑不太好实现,日后可能需要改进,此时若是给用户使用的话可能会出现一些Bug】,那你的老板当时虽然会觉得你不太行,但是你道出了这个问题的本质,后期再慢慢留时间去修复就好了,总比炒鱿鱼好吧🦑
从上面两个生活小实例可以看出,我们需要考虑最坏的情况,留出一定的差错空间,这样容错率就可以大大降低
🌳实战演练【详细解说,最重要的部分】
接下去我将会通过10余个有关时间复杂度的计算案例,来帮助你去真正理解如何计算时间复杂度✍
🗡实例1~5讲解
实例一
// 计算Func1的时间复杂度? void Func1(int N) { int count = 0; for (int k = 0; k < 2 * N ; ++ k) { ++count; } int M = 10; while (M--) { ++count; } printf("%d\n", count); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 好,我带大家一步步来分析一下,首先你记住,要算时间复杂度,绝对不能仅仅看有几个循环,那时间复杂度就是几,这是一个大家的通病,在开头就提出来👈
- 上面这个程序,首先看第一个循环,从0循环到2N,也就是循环了2N次,也意味着这个count++了2N次。然后对于下面的while循环,因为【M = 10】,因此
M--便循环了10次,所以这段程序的总体时间复杂度就是他们之和也就是【2N + 10】 - 好,我们来简化一下,首先根据
法则一,可以把后面的10看作成为1,然后根据法则三,可以去掉N前面的2,所以,最后可以得出这个程序的总体时间复杂度为O(N)
实例二
- 好,然后看第二个,代码稍微多了一点,但其实和上面一般是一样的,只是在上面加了两层for循环嵌套罢了
// 请计算一下Func1中++count语句总共执行了多少次? void Func2(int N) { int count = 0; for (int i = 0; i < N ; ++ i) { for (int j = 0; j < N ; ++ j) { ++count; } } for (int k = 0; k < 2 * N ; ++ k) { ++count; } int M = 10; while (M--) { ++count; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 首先来看外层循环,执行了N次,对于每一次的外层执行,都对应着N次的内层循环执行,因此其复杂度就是O(N2),下面的我们实例一算过了,为2N + 10,因此总体的时间复杂度为【N2 + 2N + 10】
- 我们继续来通过法则简化一下,首先根据
法则一,将10改为1,然后根据法则四,将1去除,接着根据法则二,只保留高阶项,对于谁高谁低,我在前面已然说过,若是遗忘,往上翻阅即可,最后可以看到,只剩下N2,前面并没有任何系数,所以不需要化简,最后可以得出这个程序的总体时间复杂度为O(N2)
实例三
- 然后来看第三个
// 计算Func3的时间复杂度? void Func3(int N, int M) { int count = 0; for (int k = 0; k < M; ++ k) { ++count; } for (int k = 0; k < N ; ++ k) { ++count; } printf("%d\n", count); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 很明显,两个循环,第一个循环的执行次数是M次,第二个循环的执行次数是N次,所以将它们加起来即可,就是O(M + N),这里若是M == N,则可表示为O(2M)然后转化为O(M),但是这里注明了两个变量的大小是不同的,所以整体时间复杂度为O(M + N),无需化简
实例四
- 这题很简单,送分,循环执行了100次,因此时间复杂度为O(100),根据
法则一,可将这个100化为1,因此最终的时间复杂度是一个常数阶O(1)
// 计算Func4的时间复杂度? void Func4(int N) { int count = 0; for (int k = 0; k < 100; ++ k) { ++count; } printf("%d\n", count); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实例五
// 计算strchr的时间复杂度? const char * strchr ( const char * str, int character );- 1
- 2
- 这个函数名是C语言里面的一个字符串操作函数,带你们看看
- 根据描述可以知道,是查找在字符串中出现的第一个字符

- 可以看到,这个算法的时间复杂度其实和在一个数组中查找一个数是一样的,但是我们还是要去取最坏的情况,也就是O(N),设想你取的是平均的时间复杂度O(N/2),但是需要查找的这个数再后面的一部分的时候,会超过O(N/2)了,此时就显得不精准

📰生活哲理闲谈
例子讲了一大半了,不知道你对时间复杂度的计算有没有一个基本的掌握了,可能有些同学对这个法则还不太熟悉,那你要现将这个法则仔细的研读一遍,思考一下再去做题🤔
- 其实对于这个时间复杂度呢,它本质上算的并不是时间,而是一个执行的结果次数,法则中我们有提到只保留这个高阶项,但是为什么只保留高阶项呢,这个其实你还是要去联想我们生活中的例子
- 假设你是一个富豪,已经坐拥百万的家产,每天只需要轻松玩乐即可,那这个时候有三笔生意同时与你又进行了签订,一个是10亿,一个是1千万,另一个是10万,那你会看重哪个呢?不用说,一定是那个10亿,因为你已经足够有钱,不会去看重那些小财富,而是只会盯紧金额最大的那一部分
- 近些年科学家发现了在银河系外有着一些奇特的星系,有些离我们10光年,有些呢则是离我们几百光年,但是这对你来说区别又在哪儿呢,无论是10光年还是几百光年之外的星系,距离你都是非常遥远的距离
🗡实例6~10讲解
好,经过一些闲谈后我们继续来看实例,相信你对时间复杂度的求解有了一个层面的理解
实例六
- 第六个,就是大家最熟悉也是最用的最多的一种排序算法——冒泡排序,如果想看其他排序的可以看看我的这篇文章 链接
- 大家可能完全性地认为其时间复杂度为O(N2),那你觉得这是它的最好、最坏还是平均呢?我们一起来分析一下
// 计算BubbleSort的时间复杂度? void BubbleSort(int* a, int n) { //[0,n - 1) for (int i = 0; i < n - 1; ++i) { int changed = 0; for (int j = 0; j < n - 1 - i; ++j) { if (a[j] > a[j + 1]) { swap(&a[j], &a[j + 1]); changed = 1; } } if (changed == 0) break; //PrintArray(a, n); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

- 好,我们抛开上面的代码来分析一下,因为大家可能看到两层for循环就本能地认为这是一个O(N2)的时间复杂度
- 通过上面的图我们可以看出,有N个数字,那这个外层就会执行N - 1次,对于每一次的循环,会进行一个内部的比较,通过两两之间的不断比较,将这个最大或者最小的数字冒到最后面,这其实就是冒泡排序的本质所在,然后对于第一次的比较会比较
N - 1次,第二次呢会比较N - 2次,第三次会比较N - 3次。。。依次类推,到了最后只会比较1次 - 我们看时间复杂度看到不是有几层循环,而是看这个程序它运行了多少次,上面我们分析到,这个每次的比较次数是【N - 1】到【N - 2】。。。最后到【1】,因此可以看出这是呈现一个等差数列的递减形式可以使用等差数列的求和公式去计算总共比较了多少次,(N - 1)*N/2,最后根据我们的法则二、法则四,便可以得出最终的时间复杂度为O(N2)
- 冒泡排序的时间复杂度是这么算出来的,你明白了吗❓
实例七
- 实例七是关于二分查找的例子,有关二分查找相信大家都是蛮熟悉,是一种比较高效的查找算法,但是你知道它的时间复杂度是多少吗?我们一起来分析一下
// 计算BinarySearch的时间复杂度? int BinarySearch(int* a, int n, int x) { assert(a); int begin = 0; int end = n-1; // [begin, end]:begin和end是左闭右闭区间,因此有=号 while (begin <= end) { int mid = begin + ((end-begin)>>1); if (a[mid] < x) begin = mid+1; else if (a[mid] > x) end = mid-1; else return mid; } return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 首先我们再来简述一下它的原理,通过两端的边界,每次取寻找这个中间值,然后去比较待查找数字和中间值的关系,以此来确定待查数字在给定数组的待查数据范围,所以二分法每次范围都是以一半一半缩小的,大概是下面这样👇
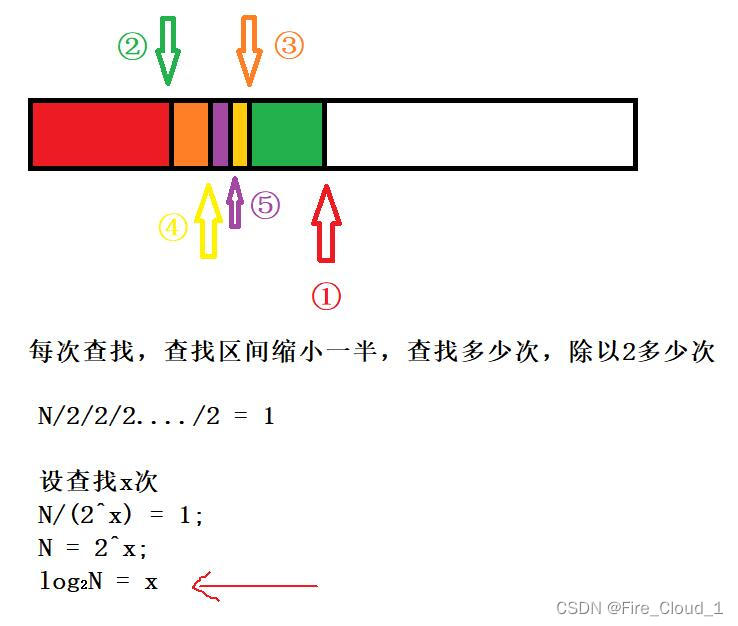
- 我们需要求的是使用这个二分法去查找这个数时所需要的次数👈,这点首先你要明确
- 然后根据二分法的特性,每次都是以一半一半呈现一个折半的查找,然后直到总的数字个数被除到1为止,从我上面的式子可以看到,N是题目给出的数字长度个数,最后的结果我们知道会走到1,那唯一不知道的就是到底除了几个2,也就是这个2上的指数是多少
- 我们将其设置为x,然后你自己在草稿纸上列一个式子,就可以求出这个X的表达式,是
log以2位底N的对数,然后你去联想上面我所给出的O(log2N)的时间复杂度的图,就可以很明确的知道二分法的时间复杂度是多少了 - 对于这个log以2为底的这个2,其实在很多资料书籍上都会将其省去,因为这个对总体不存在影响,所以会简写成logN,但是最好不要再简化写成lgN,不太建议写成这样,容易产生误会
对于这个二分法,其实它是蛮高的,对比一般的暴力查找,可谓是天壤之别,我们通过一些数据来对比一下

- 可以看到,随着数据量的增加,暴力查找需要的100W次、10亿次,但是对二分查找来说只需要10次20次就够了,因为从logN这个图像其实可以看出,越到后面它的坡度越加平缓,数据的爬升量也是慢慢地增加而已
- 所以二分法其实还是挺牛逼的。但是为什么有些地方在查找数据的时候不使用二分查找,而是使用效率更高的哈希表或是红黑树呢,因为二分查找它是有一个条件限制的,需要在待查找元素已经有序的情况下才可以进行一个折半查找,所以就一定要对无序的数组进行一个排序
- 但是我们知道,对于排序的话,也是需要时间复杂度的,例如说直接使用个快排也是要O(NlogN)的时间复杂度,所以对于二分法有着一定的容错率,因此在某些场合下就会使用其他的搜索算法
实例八- 接着我们来讲的是一个阶乘递归的时间复杂度计算。对于递归,其实我们不仅仅要考虑的是本次的执行次数,而且还要考虑递归的次数,所以这里先给出求解递归算法时间复杂度的定义
递归时间复杂度计算方法和技巧 —— 每次递归调用的执行次数累加
// 计算阶乘递归Fac的时间复杂度? long long Fac(size_t N) { if(1 == N) return 1; return Fac(N-1)*N; //算的是每次里面的执行可以是常数次 //每次是常数次,调用了N次,N个1相加 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 可以看到,对于时间复杂度,计算的还是执行的次数,但是对于递归呢,是一个累加的效果,因为既然是递归了,次数也是需要计算进去
- 就像上面这题对于一次递归,内部只有一个if条件分支判断,因此单次的时间复杂度为O(1),是一个常量级别的。然后递归调用了N次,所以我们进行一个常量级别的求和接口也就是N个1相加,那也就是N
- 因此这个算法的时间复杂度为O(N)
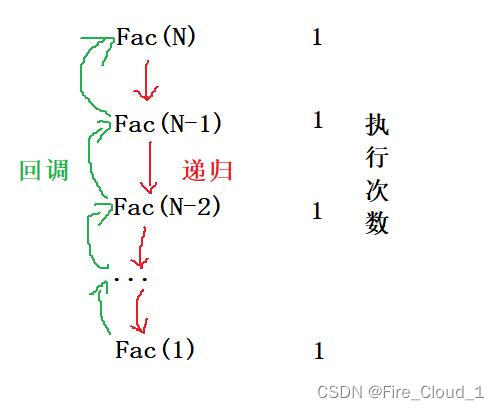
可能还有同学没看懂,我通过一张图给你看看。可以看到,每一次递归的调用,执行次数都只有一次,那随着N次递归,就有N - 1次调用,我们去计算总的执行次数就行
实例九
- 然后我们再来看一个,是上面一个案例的改进版
long long Fac(size_t N) { if (1 == N) return 1; for (size_t i = 0; i < N; ++i) { //... } return Fac(N - 1) * N; //递归了N次,每次里面循环走了N次 --》等差数列 // N + (N - 1) + (N - 2)...+ 1 = N^2 //函数调用不算次数,算的是里面的东西 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 可以看到,在递归的内部我增加了一个循环,那我想你已经可以抢答了:递归调用了N次,每次的N变化到N-1,再变化到N-2,也就是每一个单层递归的执行次数在不断发生变化,最后递归到1为止
- 然后我们还是一样,去累计这个每次递归调用的执行次数
N + (N - 1) + (N -2)... + 1 = (1 + N) * N/2,最后根据法则就可以将其化简为O(N2),相信你此时已经是非常熟练了
一样是通过图解来分析一下,很直观可以看出,每次的执行次数呈现一个递减的趋势,直到递归到1为止,将递归次数累加即可
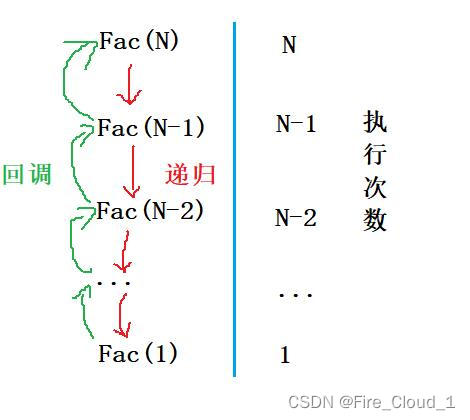
实例十- 压轴的例题,自然是留给我们开头就给出的那个裴波那契数列的递归求解
// 计算斐波那契递归Fib的时间复杂度? long long Fib(size_t N) { if(N < 3) return 1; return Fib(N-1) + Fib(N-2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 在开头我们就讲了,它的时间复杂度为O(2N),但是要怎么去计算呢?我们可以先通过画图来分析一下
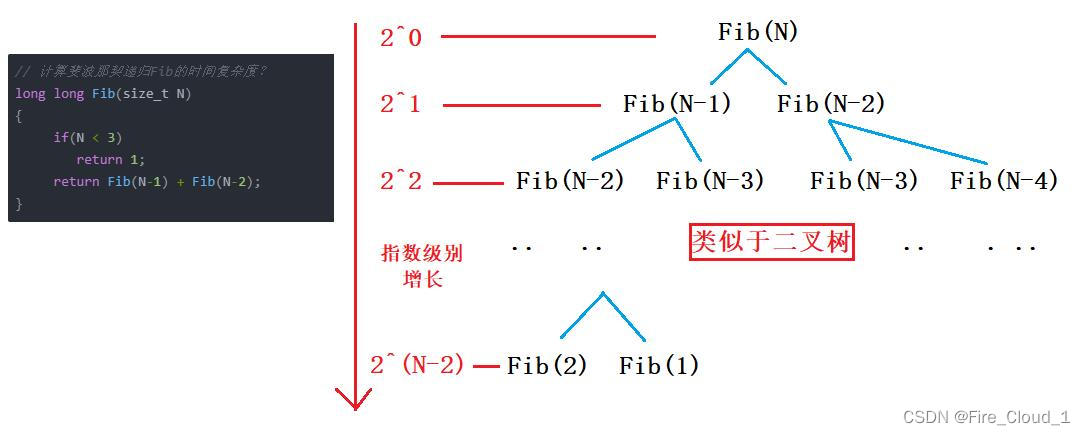
- 从上图可以看到,这个斐波那契函数的递归模型很像是一棵二叉树。当一次Fib()函数执行的之后,直到递归到最后一层,也就是我们常说的叶子结点时,便递归结束,实现一个回调。可以看到,每次的递归调用都会分出来两个新的数,和细胞分裂也很类似,第一层是1个,第二层是2个,第三层是4,第四层是8个。。。用2的指数次表示就可以写成20、21、22。。。
- 因为这个递归次数会调用N - 1次,所以最后一层就是2N-1个数字。从中我们可以得出一个表达式为【20+21+22+23+…2(N-2) = 2(N-1) - 1】
- 然后根据我们的这个法则,就可以得出它的时间复杂度为O(2N)
但是它的空间复杂度是多少你知道吗?继续看下去你就知道了
⌚空间复杂度
说完了时间复杂度,接下去我们来说说空间复杂度
🌳概念
- 首先一样,来讲讲空间复杂度的概念
空间复杂度也是一个数学表达式,是对一个算法在运行过程中
临时占用存储空间大小的量度- 空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。空间复杂度计算规则基本跟时间复杂度类似,也使用大O渐进表示法
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定
🌳例题分析
一些概念性的东西我们在时间复杂度已经详细介绍过了,这里就不再重复,直接通过例题来了解空间复杂度如何计算,这里的很多例题也就是上面的哪一些
上面也有说到过,对于空间复杂度,一般就是O(1)或O(N)
🔢普通函数
实例一
- 好,首先我们来看第一个简单一些的实例,这个实例我们前面有讲到过,它的时间复杂度为O(1),是常数阶的
// 计算Func1的空间复杂度? void Func1(int N) { int count = 0; for (int k = 0; k < 100; ++ k) { ++count; } printf("%d\n", count); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 然后我们来分析空间复杂度,概念中有说到了,对于空间复杂度呢,其实算的就是变量的个数,还有就是你除了函数给出的参数以外额外去开辟的空间
- 那对于上面这个题,开辟了哪些变量呢,就是count和循环变量k,那也就是O(2),然后根据我们的
法则一,可以化为O(1),因此可以看出这段程序的时间与空间复杂度均为O(1)
实例二
- 实例二也是我们熟悉的冒泡排序,它的时间复杂度为O(N2),是平方阶。那空间复杂度呢?也是O(N2)吗?
// 计算BubbleSort的时间复杂度? void BubbleSort(int* a, int n) { //[0,n - 1) for (int i = 0; i < n - 1; ++i) { int changed = 0; for (int j = 0; j < n - 1 - i; ++j) { if (a[j] > a[j + 1]) { swap(&a[j], &a[j + 1]); changed = 1; } } if (changed == 0) break; //PrintArray(a, n); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 肯定有同学认为函数形参中的这个数组a是需要占用空间的,然后数组中有n个元素,因此时间复杂度就为O(N)
- 这么去看其实是不对的,我们上面说到了,对于空间复杂度的计算,应该是额外空间的计算,但是这个数组a和它的大小呢,在这个函数内部其实你可以看做是编译器已经给到你的,已经是存在了,不算做是额外的空间。在这里新增加的变量其实就是循环变量中的end和i,以及一个标志变量exchange,那和实例一等同,它的空间复杂度其实也是O(1)
实例三
- 下面一个案例也是有关斐波那契数列的求解,不过使用的是循环迭代的方法,那它的空间复杂度是多少呢?
// 计算Fibonacci的空间复杂度? // 返回斐波那契数列的前n项 long long* Fibonacci(size_t n) { if(n==0) return NULL; long long * fibArray = (long long *)malloc((n+1) * sizeof(long long)); fibArray[0] = 0; fibArray[1] = 1; for (int i = 2; i <= n ; ++i) { fibArray[i] = fibArray[i - 1] + fibArray [i - 2]; } return fibArray; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 细心的小伙伴其实可以看出,为了实现存放斐波那契数列,去实现一个循环迭代,在开头使用malloc动态开辟了一个数组,因为对于
malloc来说,是在堆内存中申请一块空间来使用,所以这个数组就是属于额外开辟的空间。 - 开的数组大小是有n + 1个,那其实根据我们的法则其实就可以看出了,这个算法的空间复杂度为O(N)
🔢递归函数【递归在栈中的原理】
上面三个实例呢,可以看出,比较简单一些,但是对于递归函数的空间复杂度,就没有那么容易分析,这个需要你去思考🤔
实例四
- 首先我们先看到的也是上面说到过的阶乘递归
- 这段阶乘递归我们上面有讲到,使用递归次数累加可以计算得到时间复杂度为O(N),那这个空间复杂度呢?也是O(N)吗❓
// 计算阶乘递归Fac的空间复杂度? long long Fac(size_t N) //此时需要考虑到这个递归函数的参数 { if(1 == N) return 1; return Fac(N-1)*N; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 从程序中可以看到并没有任何的变量被声明出来,那有同学问了,难道这个阶乘递归的空间复杂度为O(0)吗,其实并不是的,对于递归函数,和普通函数计算空间复杂度其实是不同的,我先给出定义,让你明白如何去计算递归函数的空间复杂度👇
递归调用空间复杂度计算方法和技巧 —— 每次递归调用的变量个数累加
- 对于递归的空间复杂度还要追溯到它在计算机里内存中的使用,在计算机内部呢,有一块区域叫做
栈内存,对于栈的空间呢是很小的,编译器默认的栈空间大概只有1M左右,所以我们经常在写代码的时候会出现栈溢出【Stack Over Flow】这种错误,这个错误导致的原因其实就是你在栈中存放的东西太多了,就导致溢出了 - 栈这个东西呢,也是一个数据结构,我在其他文章中也有讲到 链接,不过数据结构这个栈和内存中的栈又是两个不同的东西,栈通俗一点来讲呢其实就像是一个水杯,你去接水,最多也就只能接到杯口,若是再接,那水就会漫出来,这其实就是栈溢出
- 那这个递归和栈又有什么区别呢?对于递归这种算法,它是需要在栈中开辟栈帧的,整体你看上去它很精简,但其实它内部的实现逻辑是蛮复杂的,上面我们画了一张二叉树的图形,递归其实也就是一层一层地向下调用,这个时候实现的其实就是一个嵌套的逻辑,那我们都知道循环嵌套,这个很明确,你套了几层那这个时间复杂度就是O(N)的几次方,随着嵌套的次数越来越多,这个逻辑也会越来越复杂,最后就会
导致时间复杂度过高然后超时。那对于递归的调用其实也是一样的,只要你没有碰到递归出口,这个递归就会一层一层套下去,当你的数据量变得很大之后,栈帧开辟过多,也就导致了栈的溢出
我这么解释不知道你懂了没有❓根据上面这段代码,我们再通过算法图示来看看
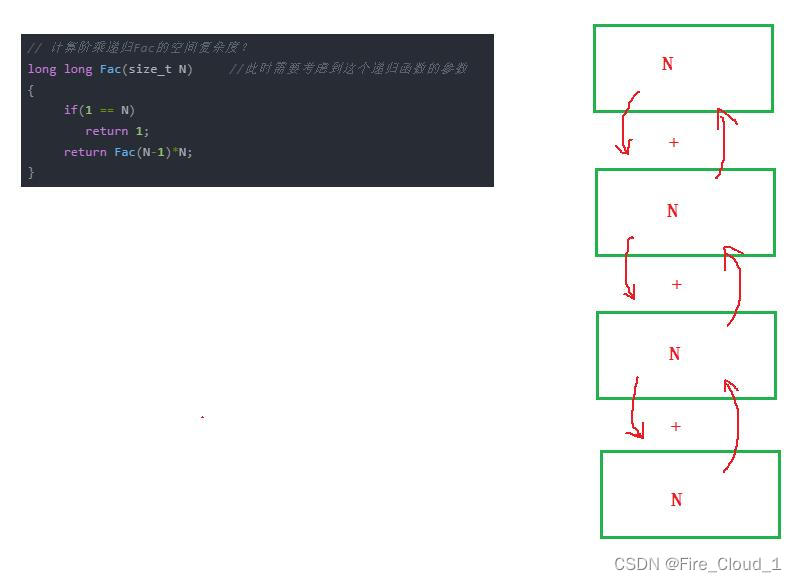
- 那从图中其实就可以看出了这个原理,
随着这个递归函数每递归一次呢,就会在栈中开辟一块大小为N的空间,然后直到递归结束为止,递归接口再根据一块块连续的存储空间再实行回调,其实它们最终使用的就只是同一块存储空间罢了,释放了在申请,释放了再申请。因为栈在内存中是向下生长的,上面是低地址,下面是高地址。你申请空间又释放,每次拿的其实还是栈顶的那块空间 - 我写一段程序给个运行结果你就知道为什么了(・∀・(・∀・(・∀・*)
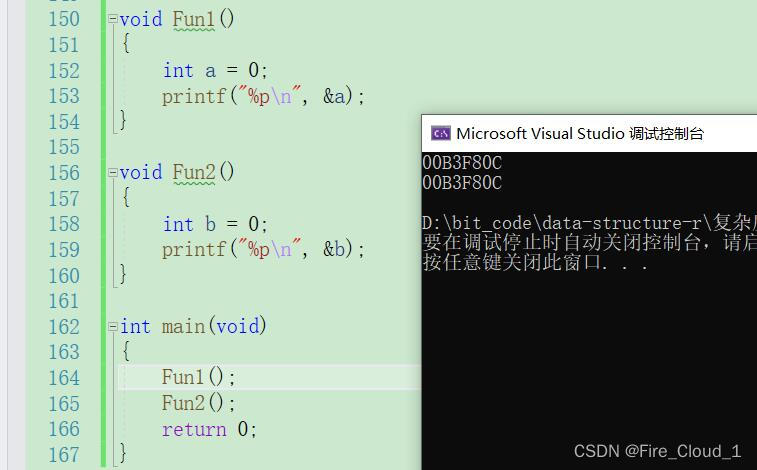
- 可以看到,两个变量打印出来的地址是一样的,也就意味的这两个变量使用的内存地址是同一块,因为在Fun1()函数调用结束之后,它的函数栈帧就销毁了,使用过的空间销毁之后就将其还给操作系统了。此时又创建了一个Fun2()函数,此时操作系统就又会为其分配空间,为这个函数建立和初始化栈帧空间,此时它使用的便是上一次Fun1()释放掉的空间。从中也可以看出栈【先进后出】的原理,如果听起来有点抽闲的话,就看看函数栈帧的创建和销毁吧!
- 那一块块空间的累加,最后在根据
法则三,就可以得到空间复杂度为O(N)
实例五
- 最后一个呢,就是我在上面所说到的有关【斐波那契数列】空间复杂度的求解,在这里给出一个答复
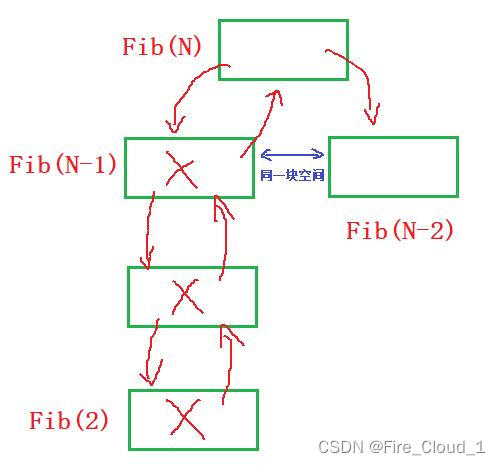
// 计算斐波那契递归Fib的空间复杂度? long long Fib(size_t N) { if(N < 3) return 1; return Fib(N-1) + Fib(N-2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 对于斐波那契数列呢,其实和阶乘递归差不多,它要去实现的是一个空间的重复利用,我们还是通过递归算法图来看看
- 粗略地画了一下,它的递归原理大概就是这样,在逐层向下递归的时候,就会为每一个数开辟出来一块空间,然后在本次递归结束,调用下次,这个时候此次递归在栈中开辟的空间就会被销毁,然后下一层的递归调用又会来使用这块空间,那其实这块空间就是被每一次的递归调用反复使用的
- 举一个很形象的例子,可能有点味道,就是你去蹲坑🚽,你试用完了冲掉之后那下一个人人是不是还可以继续使用呢,那你们使用的就是同一个空间中的东西【doge】
- 所以我在图中指出的Fib(N-1)和Fib(N-2)其实使用的是同一块空间,只是上一次递归调用完成销毁之后,再进行一个反复利用罢了,因此只是开辟了一块空间。所以我们就可以得出了,这个空间复杂度为O(N)
好,到这里呢,我们对于时间复杂度和空间复杂度的基础学习就算是全部完结了,看到这里你要做到的就是拿到一道题,可以学会去分析这代码的执行逻辑和所消耗的空间大小,接下去我们通过两道LeetCode的题目来检验一下自己是否可以学以致用✏
⌚OJ题目实训
以下两题请通过我另一个专栏【LeetCode算法题解】观看📺
⌨【LeetCode】面试题17.04 - 消失的数字
⌨【LeetCode】189 - 轮转数组
⌚总结与提炼
- 在本文中,我们对算法的算法的时间复杂度与空间复杂度进行了一个深究和探讨,从最基本的大O渐进表示法,到五条重要的运算法则,再到经典案例的讲解,相信你对如何计算时间与空间复杂度应该有了一定的把握
- 对于时间复杂度呢,其实算的并不是时间,而是一个程序执行的次数,需要去估算,不需要太过精确;对于空间复杂度呢,算的是额外所使用的空间大小。
- 而对于递归函数的复杂度计算,又有所不同,有讲到过一些技巧:对于时间复杂度是【每次递归调用的执行次数累加】,对于空间复杂度是【每次递归调用的变量个数累加】
以上就是本文所要介绍的所有内容,最后感谢您对本文的观看,希望我的讲述可以对您起到帮助,如有疑问可于评论区留言或者私信我🌹
-
相关阅读:
【C++刷题集】-- day3
Spring(一)Spring配置、构造注入、bean作用域、bean自动装配
windows开机自启动(exe +快捷方式)
【java学习】Annotation-Driven(注解驱动编程)-spring常用注解
java计算机毕业设计海康物流MyBatis+系统+LW文档+源码+调试部署
【Lipschitz】基于matlab的Lipschitz李氏指数仿真
docker入门教程
数字信号处理及python实现(一)
STM32物联网项目-通过ESP12S模块连接TCP服务器
工程结算的23个问题及技巧
- 原文地址:https://blog.csdn.net/Fire_Cloud_1/article/details/127538935
