-
【论文笔记】Encoding cloth manipulations using a graph of states and transitions
【论文笔记】Encoding cloth manipulations using a graph of states and transitions
Abstract
问题:
- Cloth manipulation is very relevant for domestic robotic tasks. 对衣服的操作对于家用机器人来说比较困难
- It presents many challenges due to the complexity of representing, recognizing and predicting behavior of cloth under manipulation. 这个任务受到衣物操作的特征复杂度、识别和预测衣物操作的行为具有困难性
提出的方法:
- a generic, compact and simplified representation of the states of cloth manipulation that allows for representing tasks as sequences of states and transitions. 提出了一种通用的、紧凑的和简化的布操作状态的表示,它允许将任务表示为状态和转换的序列
- define a graph of manipulation primitives that encodes all the strategies to accomplish a task. 定义一个操作原语图,它编码完成任务的所有策略
- It is used to encode the task of folding a napkin, learned from an experiment with human subjects with video and motion data. 是用来编码折叠餐巾的任务,这是从人体对视频和运动数据的实验中学到的
实验结果:
- 展示了简化特征表示如何允许获得有意义的运动原语的映射,并对运动数据进行分割,以获得与图中每个操作原语对应的轨迹、速度和加速度轮廓集。
(本质上可以看成是“模仿学习 + 运动原语分割”来实现DOM任务)
DOM: Deformable Objection Manipulation
I. INTRODUCTION
因此,衣物操作研究传统上在衣物状态估计和抓取点检测上的投入更大,而操作技能还没有被开发很多
操纵的关键技能之一是抓取,很少有工作分析高度灵活的物体的抓取,尽管有各种各样的抓取类型对于确定可能的动作和定义对操作有用的场景状态是至关重要的。
提出了一种基于符合布料抓握部分形状的纺织品抓握的分类:
J. Borr as, G. Aleny a, and C. Torras, “A grasping-centered analysis for cloth manipulation,” IEEE Transactions on Robotics, vol. 36, no. 3, pp. 924–936, 2020.
However, it is important to learning cloth manipulation tasks through human demonstrations to obtain a diversity of strategies to accomplish a task, and with different parameters related to safety, fast accomplishment of the objective or number of steps needed to accomplish a task, inducing a measure of task complexity.
然而,重要的是,学习布操作任务通过人工演示,以获得多样性的策略来完成任务,并与不同的参数与安全,快速完成目标或所需的步骤数来完成任务,诱导任务复杂性的措施
- The first contribution of this work is to propose a generic and compact representation of scene states and the possible transitions between them that enables to account for textile manipulations.
- The second contribution is the Graph of Manipulation Primitives (GoMP), a graph that can be built using the previous representation to encode all the possible states and transitions of a given manipulation task.
From the motion data and the labeling of video data we extract a map of strategies(抽取策略地图), and we generate segmented motion data that contains specific parameters about the upper body trajectories(上躯体运动分割数据的参数), velocities and accelerations that have been used for each identified manipulation primitive.
II. RELATED WORK
简化表示场景状态基于手之间的接触交互,对象和环境在过去的上下文操作刚性对象,然后用于识别,分割和学习操作操作由机器人执行。在这项工作中,状态是在一个特定场景中出现的所有不同的刚性物体之间的简单交互(触摸/不触摸)的表示。转换可以是复杂的(如剪切或倒入),并且从语义到实际执行都定义得很好。但是,他们没有关联到序列。
We are interested in the interaction of symbolic actions and in building a representation that allows to relate subsequent actions. 我们感兴趣的是符号动作的交互作用,以及构建一个允许关联后续动作的表示法。
图是操作转换的一种常见表示方式:
1. The Dexterous Manipulation Graph
-
它是一个图,其中节点是一个抓取中接触点的位置和方向,如果两个抓取点能连接(重新配置,reconfiguration),那么边就存在。
-
由于 DMG 考虑了刚性对象,因此它们不需要指定对象的状态或操作可能对其配置造成的更改(抓取导致坚硬物体的形变)。
2. Contact Interactions With The Environment
- 用于定义多接触运动任务中的支持阶段序列(sequences of support phases)
- 全身支撑姿势的象征性特征(symbolic representation)被用来学习一个依赖于手柄、墙壁或桌子的可能的过渡模型,以提供一个更健壮的操作。
- 基于模型的环境对象由运动跟踪系统直接捕获,使姿态序列的数据捕获和标记
- 但是这个不适用于衣物操作
3. The Transition Graph of Object Pose
- 这张图编码了一个类人机器人和简单物体之间的全身接触的复杂性。
- 正如我们所做的那样,接触被分为面(我们称之为平面)、线、点和无接触。
- 该图是通过考虑一个特定物体的几何模型,并应用使用物理模型考虑稳定性的不同运动来生成的。
- 相反,我们考虑更多的符号状态,并建议通过观察人类执行的几次执行来学习转换。
III. A GENERIC STATE-AND-TRANSITION DEFINITION
This is a difficult problem and our approach is to defifine a simplified representation of a scene in a way that can be recognized by a robot and that allows it to execute the next action.
GT:the grasp type
In this framework, each grasp is defined by the geometries of the two contact patches that apply the couple of opposing forces, that is, the geometries of each virtual finger. 在这个框架中,每个抓握都是由两个施加一对对立力的接触块的几何形状来定义的,即每个虚拟手指的几何形状。
The framework considers as virtual fingers geometries that can be either intrinsic (part of the gripper,内在的,也就是抓持器的两瓣) or extrinsic (like the table,抓取和桌面的配合). It also considers bimanual grasps(双臂的抓取) in a natural way.
Our grasp framework considers elements in the environment as extrinsic contact geometries and, therefore, it already encompasses environmental contact interactions. 我们的掌握框架将环境中的元素视为外部接触几何图形,因此,它已经包含了环境接触的相互作用。
GL:the grasp location
we have defined a set of labels(一系列的标签) to describe the approximate locations(描述近似的位置) of the grasping points on a given rectangular cloth. Similar nomenclature(相似的分类法) could be used for other cloth shapes.
LC, RC:the corner closest to the subject at that side
FL, FR:The two farthest corners are labeled far left (FL) and far right (FR).
For certain state transitions we may get a swap of labels for the same points. (获得状态标签的转换)
For instance, when placing a cloth flat on a table, and then folding it without releasing it, the labeling swaps from (LC+RC) to (FL+FR) after the table contact has been added. (远部分与近部分实现了转换)
CC:the cloth configuration
The high complexity of its full solution has been bypassed in the past by just looking for task-oriented features, such as adequate and accessible grasping points. 在过去,仅仅通过寻找面向任务的特征,如足够和可访问的抓取点,就已经绕过了其完整解决方案的高度复杂性。
We have defined only 5 categories of simplified cloth states:
{ C r u m p l e d , F l a t , F o l d e d , S e m i − F o l d e d , S e m i − F l a t } \{Crumpled, Flat, F olded, Semi-F olded, Semi-Flat\} {Crumpled,Flat,Folded,Semi−Folded,Semi−Flat}For the crumpled category, there are subcategories dependent on the number of visible corners.(对于每一小类我们都有一些视觉角度的子类)
A further simplification in the current work has been to assume there is always a visible corner that can be grasped.(假设总有一个角落可以被抓住)
M:the motion label
Semantic labels are useful for high-level planning and scene understanding, and can be linked to low level parameters like motion primitives or other trajectory representations.
所提出的状态和转换定义在每个场景状态变化时诱导了操作任务的分割
每次在重新抓取时状态都会发生变化,在我们的抓取框架中,这包括与环境接触的变化。然而,不仅是重新掌握改变了状态,而且还改变了位置或布料状态。
IV. EXPERIMENTAL SETUP AND DATA COLLECTION
共8个测试衣物操作;运动数据套装(XSens);一个GoPro摄像头固定在他们的额头上;
We asked the subjects to wear a simple gripper, at the bottom of Fig. 1, to reduce their manipulation dexterity to one closer to that of the robot.(以将他们的操作灵活性降低到一个更接近机器人的水平)
Therefore, learning state sequences from humans will provide us with a much richer graph regarding alternative strategies, and we will be able to learn new manipulation approaches for robots.(从人类那里学习状态序列将为我们提供一个更丰富的关于替代策略的图表,并且我们将能够学习新的机器人操作方法。)
当涉及到布料操作时,尤其如此,几乎每个主题都有自己的折叠衣服的技巧。出于这个原因,我们指示受试者执行一个非常具体的任务(折叠在桌子上,而不是在空中,然后折叠3次)。尽管有这些迹象,我们还是获得了很多可变性,有时甚至是在同一受试者的试验之间。
从收集到的数据中,我们在每次状态变化时手动标记视频,根据所做的动作,根据每次过渡到状态的动作,将运动语义标签关联到每个状态。
我们故意忽略了任何纠正错误的操作,或者重新定位桌子上的布料,只是为了简化数据。
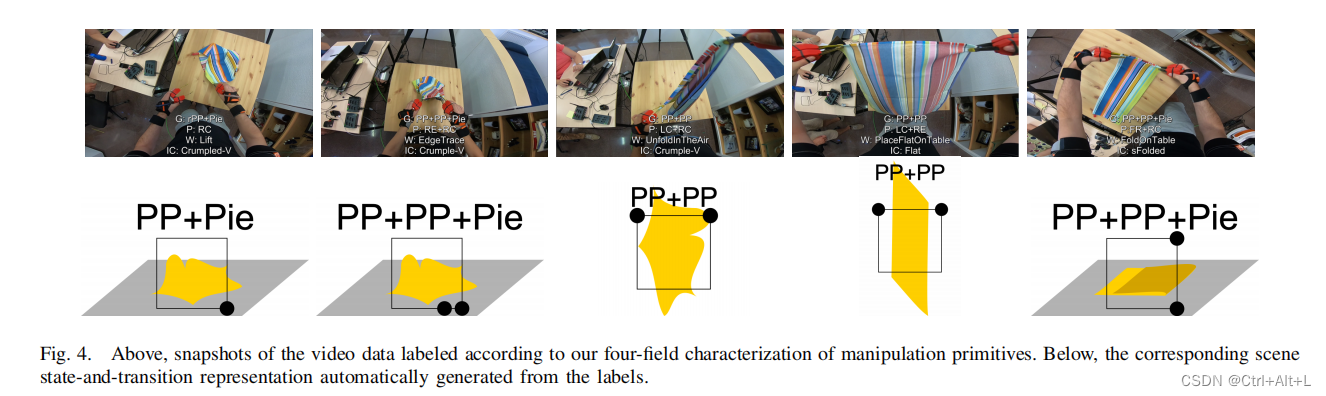

V. GRAPH OF MANIPULATION PRIMITIVES
we can generate a graph where each node is a scene state, and the edges represent the manipulation primitives. (图的节点是场景状态,图的边界是操作原语)每个初始状态和目标状态都是图边的初始节点和结束节点,运动语义值是边标签。公共节点和公共边,定义具有所有已经出现的不同顶点和边的图,计算它们的多重性。
To simplify data classification, we have removed some left and right distinctions(消除左边和右边的影响). For instance, a single corner grasped is the same irrespective of whether it is the left or right corner, grasped with the left or right hand. We also assume two grasped points on the same cloth edge are the same regardless if they are on the right or left side.
使用收集到的所有数据,我们得到了一个包含31个节点和65条边的图,但其中许多节点,它们在我们的数据中一次性出现。
如果我们要求每条边在数据中至少出现3次,那么图将减少为17个节点和23条边。
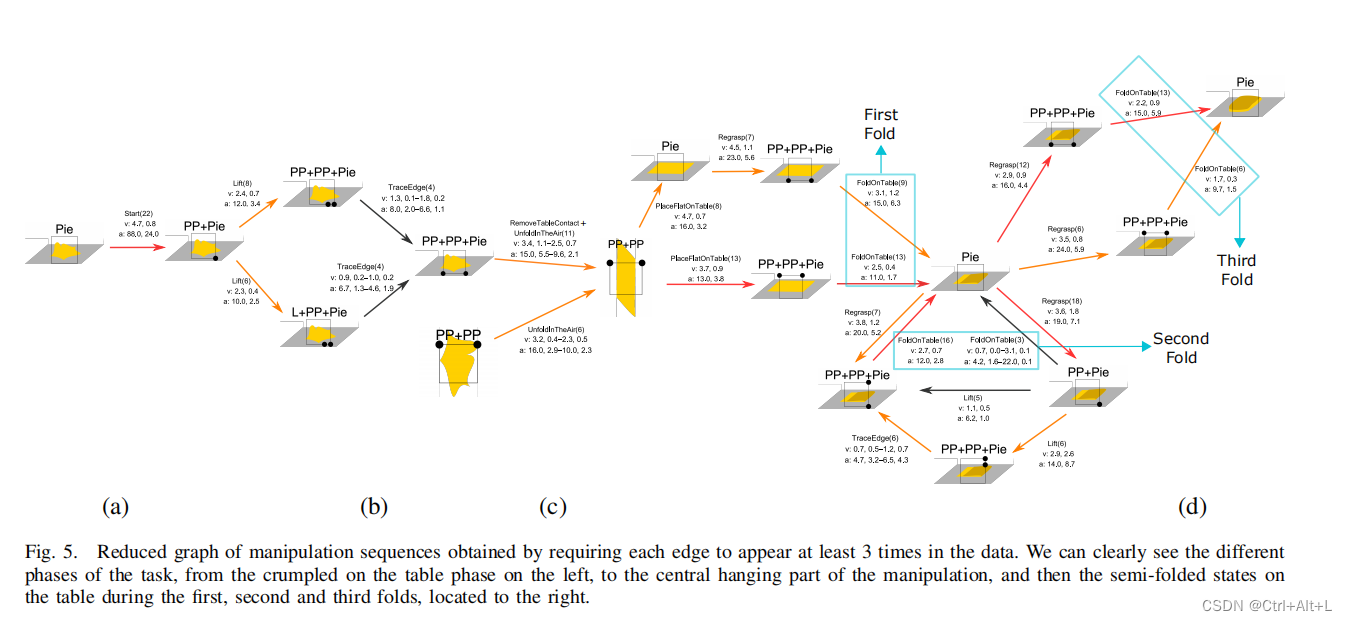
每条边的标签由原语的语义名称、它出现在数据中的次数(在括号中)以及双手的平均速度和加速度组成。
We performed a total of 24 trials, meaning the maximum times one primitive can appear repeated in the data is 24. (一个动作原语能在一次试验中重复执行最多24次)
Despite the diversity of strategies displayed by the subjects there are some transitions that consistently appear. We plotted in red the transitions that appear in at least half of the total capacity (12 times)(红色区域至少一半次数) and, in orange, the ones that appear 6 times or more(橙色区域至少四分之一次数).
We can see that the weakest flow(最缓慢的流动——最有变化的) in the graph is in the transition from the crumpled on the table to the flat hanging.
VI. DISCUSSION
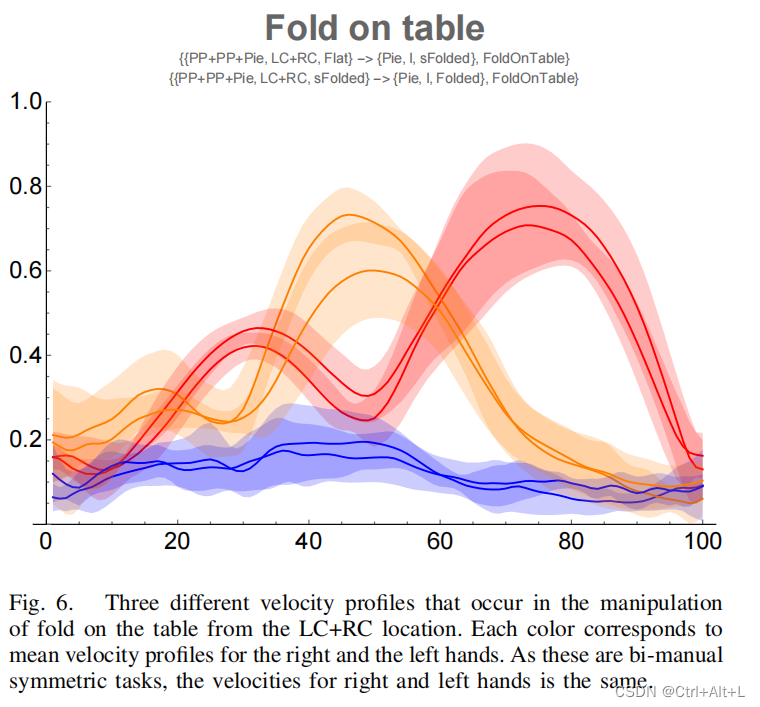
Depending on the cloth states, we can identify the first, second and third fold, the first and third being the most consistent and similar in grasping the two corners at the far or close edge. 根据布的状态,我们可以识别出第一、第二和第三折叠,第一和第三折叠在抓住远边缘或近边缘的两个角时是最一致和相似的。
对具有不同动态参数的轮廓进行识别和分类,对于使用原语图来规划优化不同成本函数的任务是非常有用的。
For instance, plan based on maximum velocities or accelerations is very relevant for collaboration context where safety is very relevant, or based on the shortest graph path, meaning less primitives are executed.
One of the motivation behind our approach is to enable explainable reasoning at the manipulation level as well as learning a dynamic movement primitive (DMP) for each regrasp strategy(增强动态环境下运动原语的操作等级的可解释性), which is also associated with its preconditions and effects.
In addition, the state-and-transition representation simplifies the perceptual information(感知信息) that needs to be acquired. Thus, in subsequent research, we plan to use previous work in our group on cloth part recognition(衣物部分识别) and pose estimation(位姿估计) and grasping point detection(抓取点检测) to perceive the aforementioned manipulation-oriented scene states(感知先前提到的操作导向的场景状态), including cloth state, grasping point location and confidence values that can provide explanations about the belief in the current state.
VII. CONCLUSIONS
This manipulation-oriented representation of cloth states and transitions would permit probabilistic planning of actions to ensure reaching a desired cloth con-figuration without requiring high accuracy in perception nor searching in high-dimensional configuration spaces.
这种面向操作的布状态和转换表示将允许动作的概率规划,以确保达到期望的布料配置,而不需要高精度的感知或在高维配置空间中搜索。
-
相关阅读:
【基础架构】Flink/Flink-CDC的部署和配置(MySQL / ES)
720云手机电动云台全新上市,让手机能自动拍摄亿万像素VR全景
spring5.0 源码解析 populateBean 10
基于Java毕业设计大学宿舍管理系统源码+系统+mysql+lw文档+部署软件
选择SSL证书的理由以及优势
【Unity脚本】使用脚本操作游戏对象的组件
请问一下测试过来人,现在学来得及吗😫
【Linux】进程(6):环境变量
服务器带宽与家用带宽的区别
MySQL——数据库基础
- 原文地址:https://blog.csdn.net/m0_48948682/article/details/127563118