-
[oeasy]python0011 - python虚拟机的本质_cpu架构_二进制字节码_汇编语言
程序本质
回忆上次内容
- 我们把python源文件
- 词法分析 得到 词流(token stream)
- 语法分析 得到 抽象语法树(Abstract Syntax Tree)
- 编译 得到 字节码 (bytecode)
- 字节码我们看不懂
- 所以反编译 得到 指令文件(opcode)
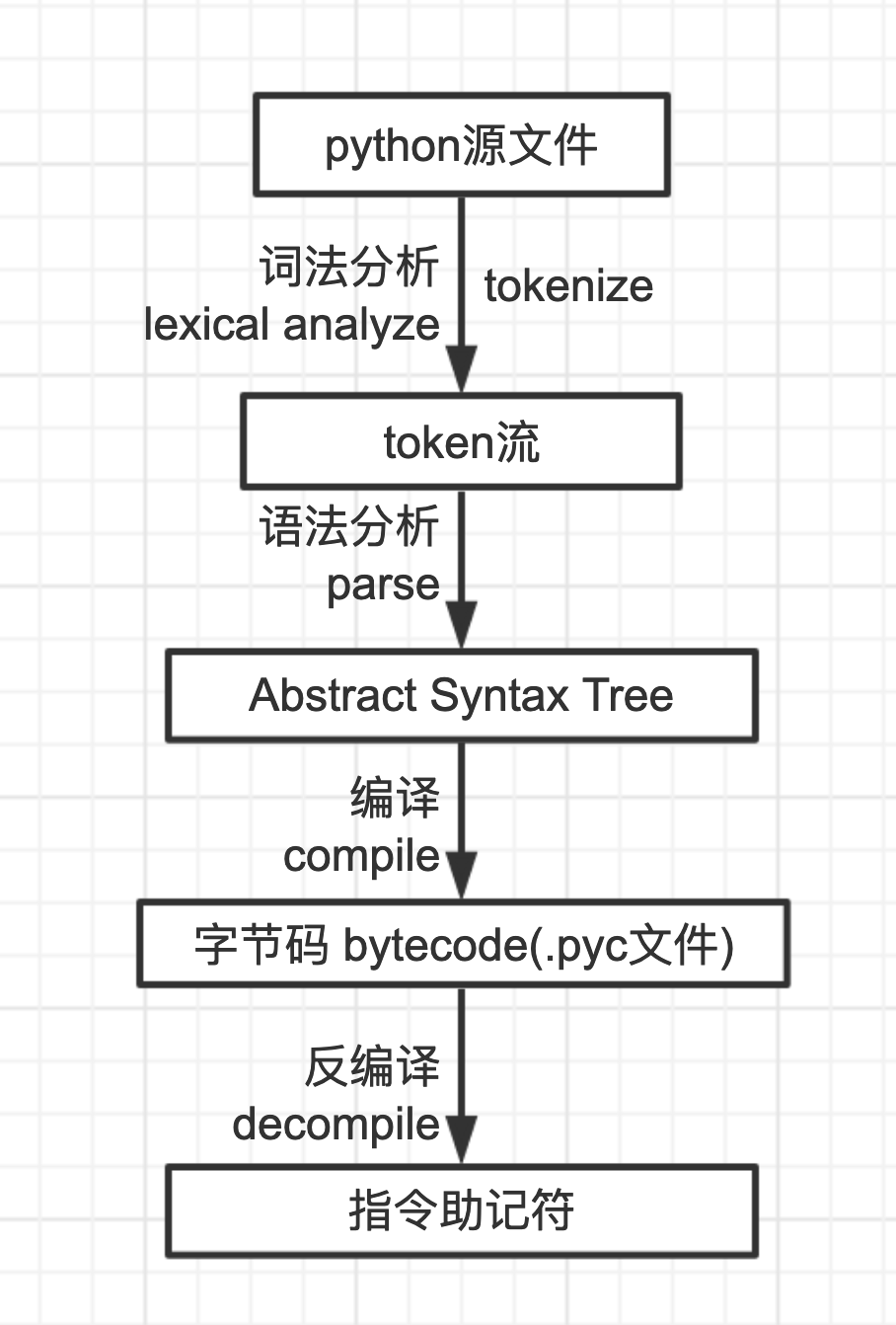
- 指令文件是基于python虚拟机的虚拟cpu的指令集
- 什么是python虚拟机呢?🤔
- 在了解虚拟cpu之前
- 我们先看看真实的cpu
真实的cpu
- 无论手机还是计算机
- 最核心器件的器件就是cpu

- 这个东西是个实实在在存在的实体
- 我们所说的python虚拟机能看到么?
- 就是用来运行py文件的
python3 到底是个啥?which python3 ll /usr/bin/python3
- 这个 python3
- 是一个符号链接文件
- 只有9字节
- 他指向 python3.8
- python3.8
- 也在 /usr/bin 里面
- 就是/usr/bin/python3.8

- python3.8是一个5.3M的文件
- 可以看得见
- 可以直接运行这个phthon3.8吗?
直接运行
/usr/bin/python3.8
python3.8 就在硬盘里呆着
- 位置就在/usr/bin/python3.8
- usr 是 unix software resource
- bin 是二进制 binary
- python3.8 是这个文件的名称
- 在运行命令的时候
- 把这个文件从硬盘装载到内存
- 然后用 cpu 开始逐行执行文件中的0101指令
- 可以把他复制到shiyanlou用户的宿主文件夹下吗?
复制

- 复制到shiyanlou下
- 再观察
#把/usr/bin/python3这个py文件的解释器拷贝到~(当前用户文件夹) #cp的意思是copy cp /usr/bin/python3 ~ #确认python3已经拷到~(当前用户文件夹) #ls的意思是list ls ~/python3.8 #查看python3文件细节 ls -lah ~/python3.8
- python3 指向的 python3.8 只有 5.3M
- 这个可执行文件怎么这么小?
- 5.3M 这也就是一张照片的大小
- 以前的 Python3.5 只有 4.3M
- 更小
- 目前这 5.3M 的 Python3 里面到底有什么呢?🤔
研究 python3
#用vi打开这个刚拷贝过来的python3 vi ~/python3.8
- 这个样子看起来
- 全是乱码
- 完全看不懂啊

- 这个东西我们确实看不懂
- 但是有人能看懂
- 谁呢?
cpu
- cpu能看懂!!!
- 这些我们看不懂的乱码
- cpu能看懂
- 这是属于cpu的机器语言
- 这就是cpu的一条条的机器指令(instruction)

- 机器指令码都是二进制形式的
- 我们尝试把python3.8转化为字节表现形式
以字节形式观察python3.8
vi ~/python3.8
- 用vim打开~/python3.8

- :
- 进入命令行模式
:%!xxd我们可以看到这个文件的二进制形态
-
%是指的对于所有行的范围 -
!是执行外部命令 -
xxd指的是转化为 16 进制形式
- 什么是xxd命令呢?
xxd

- xxd 可以查看文件的二进制形态
- dump的本意是(倾倒垃圾)
- 这里指的是转储
- 把文件转储为16进制形式汇编代码形式
:xxd –r 可以还原回去 😉
-
:%!xxd 转成字节形态 -
:%!xxd –r 转回文本形态
- 反复横跳...
另存为python3.8hex
- 一行是(16)10 进制 个字节
- G
- 总共有 343148 行
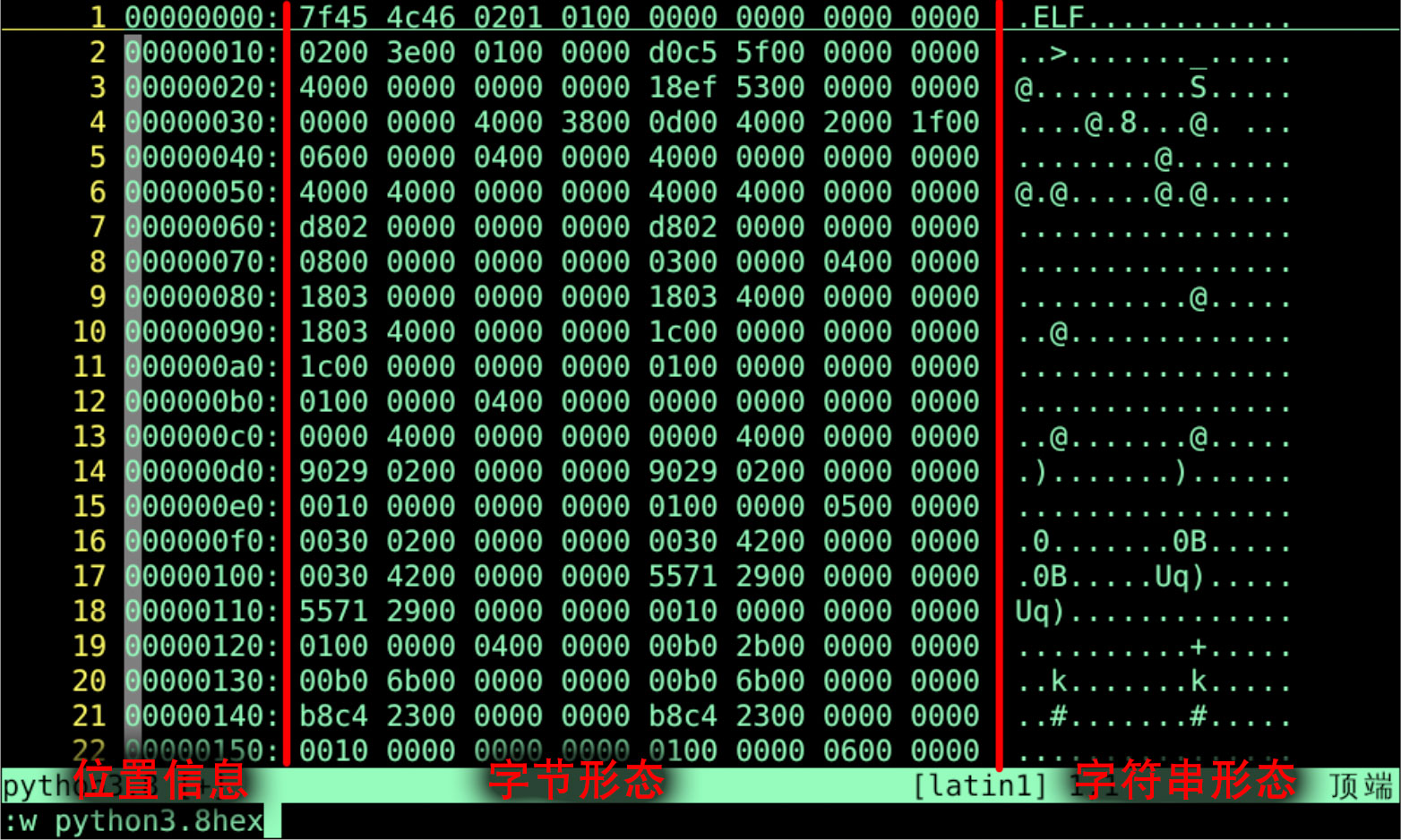
- 这就是 真正的机器语言🤭
- cpu能执行的东西
- 真真切切看到了的
- 真的存在硬盘上 01010 的二进制可执行指令!!
- 这些指令执行出来就是我们的游乐场!!!
- 或者说是我们的python虚拟机
- 可是这个指令我们看不懂怎么办?🤔
- 先把他另存出来
- :w python3.8hex
- 把当前缓存(buffer)另存(write)为
- python3.8hex
- 对python3.8强制退出
- :q!
- 不保存修改强制退出
- python3.8hex就是我们要的机器语言的字节形态
- 可是这字节形态我们看不懂啊
汇编语言助记符
#先把~/python3对应的机器语言输出为汇编指令形式(反汇编) objdump -d python3.8 > python3.8.asm vi python3.8.asm
- 这次真的可以看懂了
- 减法(sub)
- 移动(mov)
- 这些指令
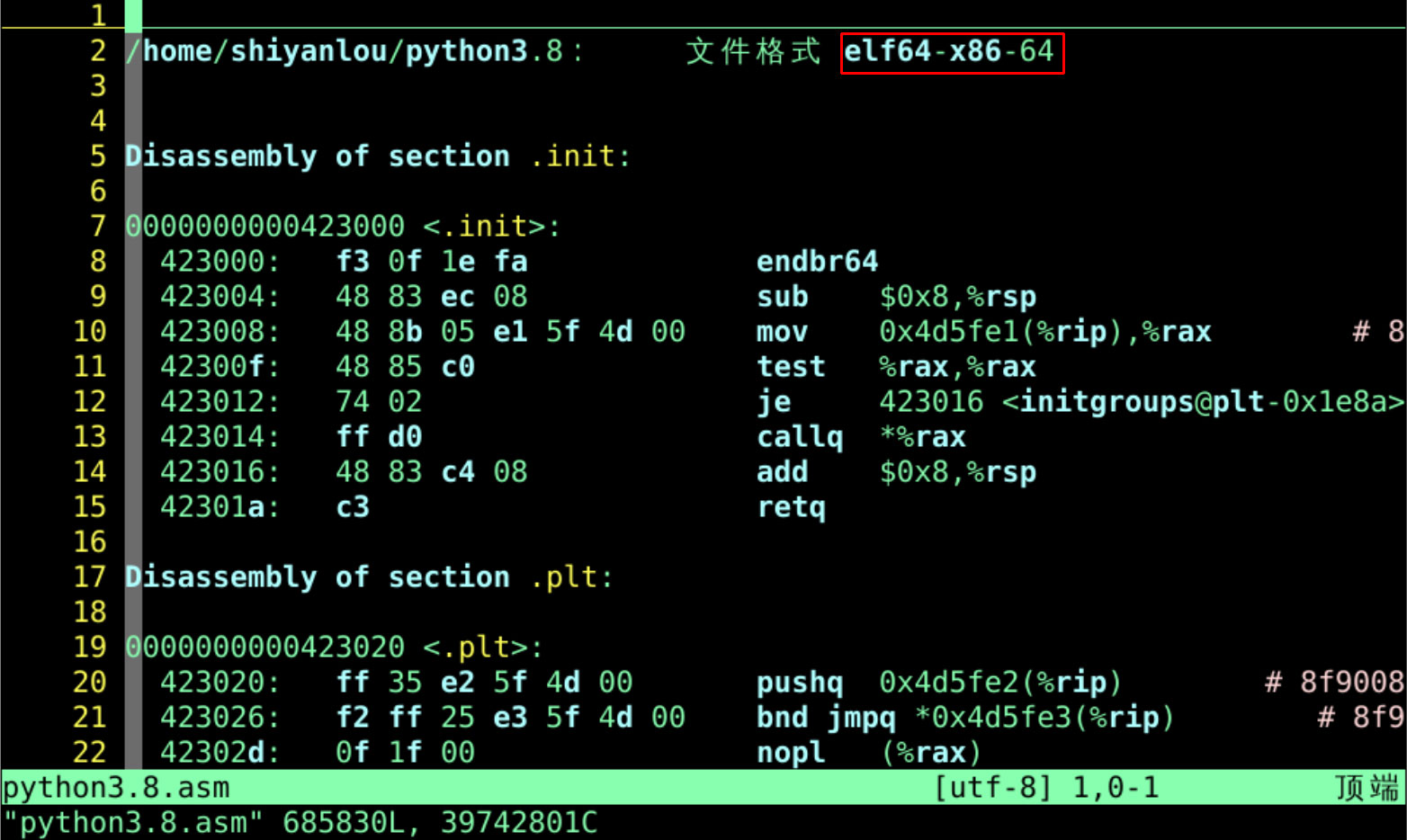
- 可以发现当前系统的架构(指令集)是x86-64
- 这些和我们刚才的字节形态有关系吗?
对比
- 用vi分窗口分别打开打开python3 和 python3.asm
vi -o python3.8hex python3.8.asm
- 下图中上半部分是机器语言
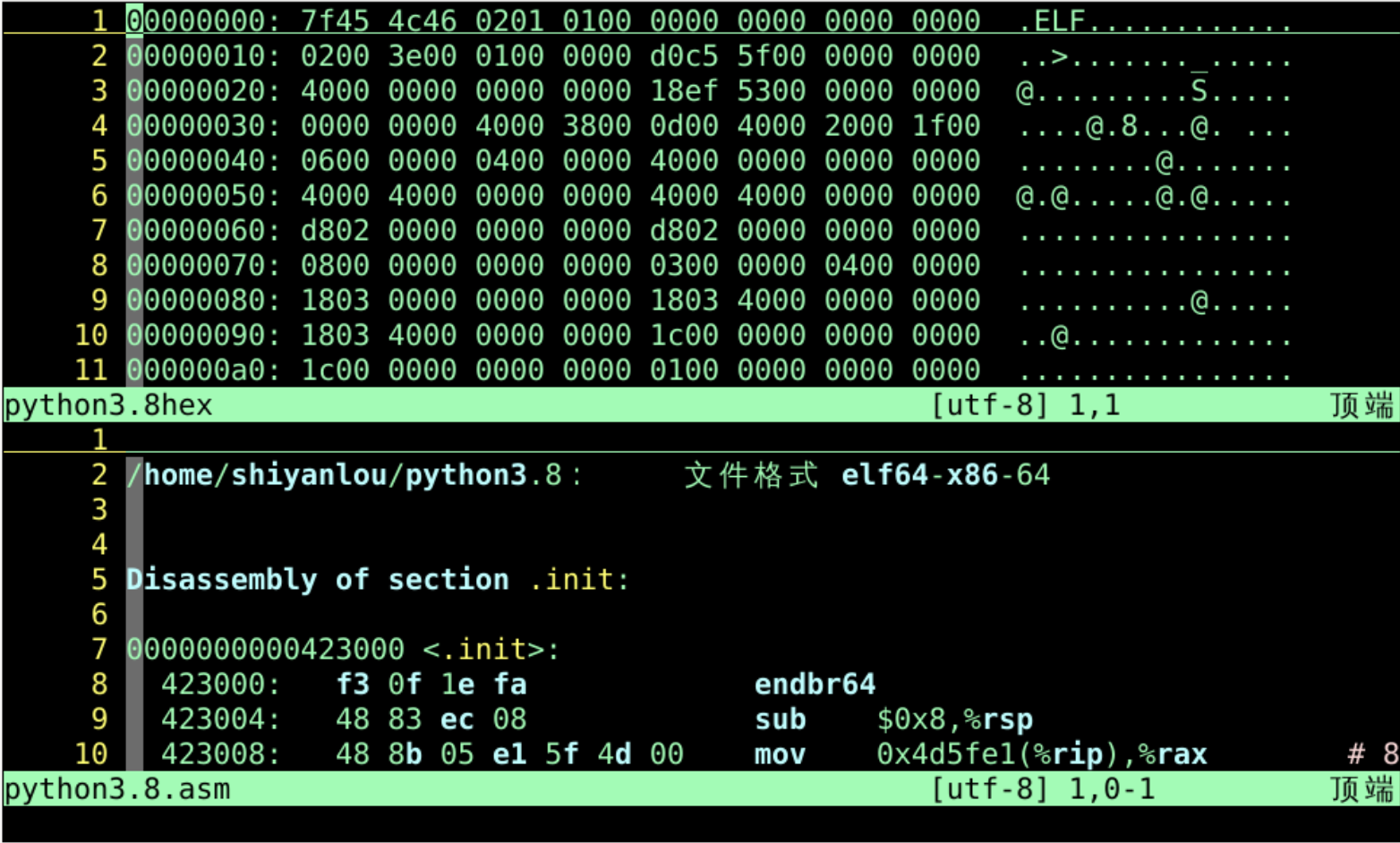
- 上图下半部分是机器语言对应的汇编指令助记符
- ctrl+j、ctrl+k可以上下切换
- 我们来试着找找
- python3文件中
- 机器语言的0101和cpu的汇编指令的对应关系🧐
找到了
- 先跳过下面窗格的第8行
- endbr64 意味着 64位结束分支
- 下面的sub执行的是减法
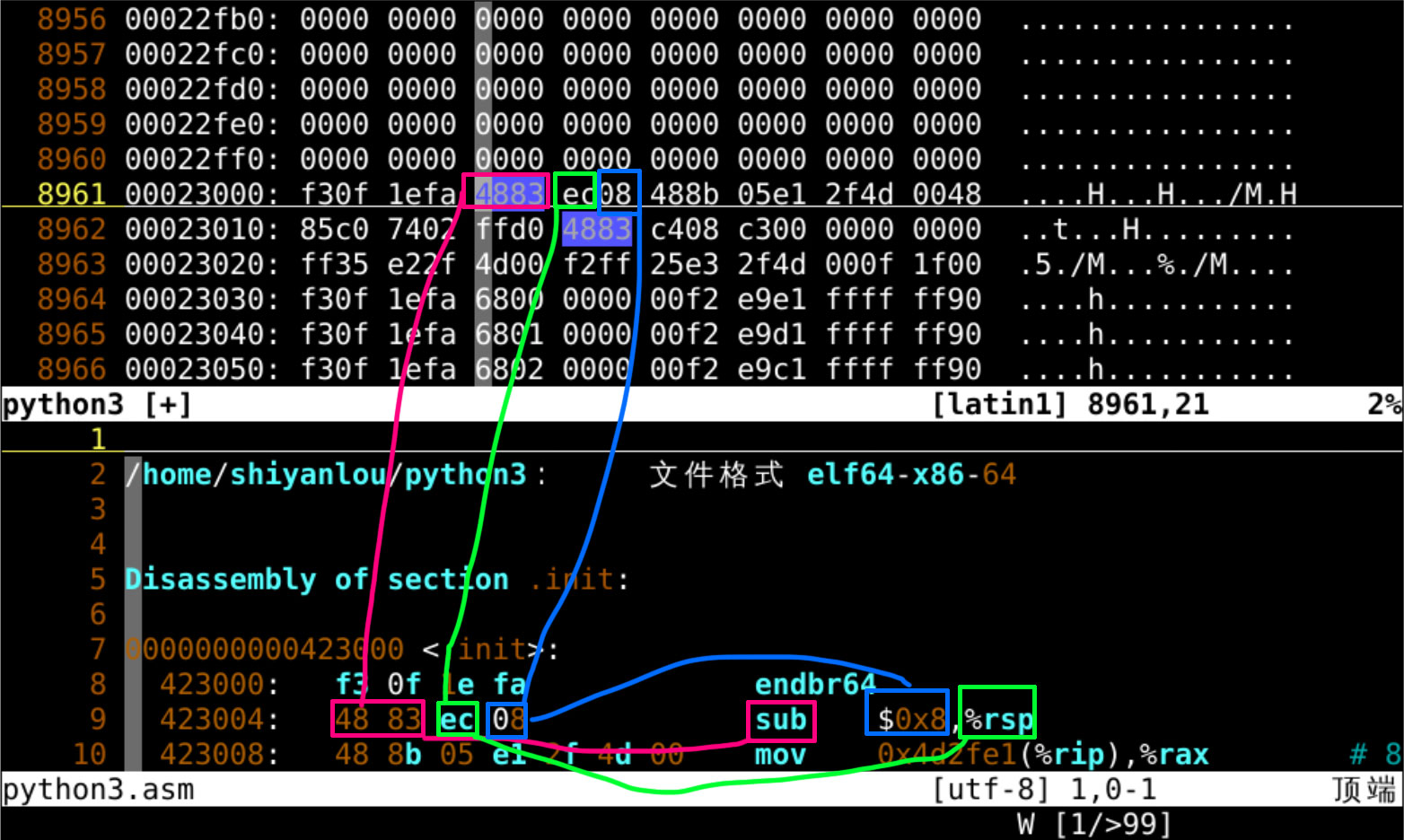
- 下面窗格的 第9行
-
/48 83 找到上下的对应关系 - 也就是第一条执行的汇编指令减法(sub)
- 汇编指令是计算机 cpu 机器指令的助记符
查找对应关系
-
423000 就是初始化(init)的 cpu 开始执行指令的地址 - 我们在上面查找48 83 有没有对应的字节
- /4883 ec08 488b...
- 在上面的窗格中
- 搜索这些字节形态
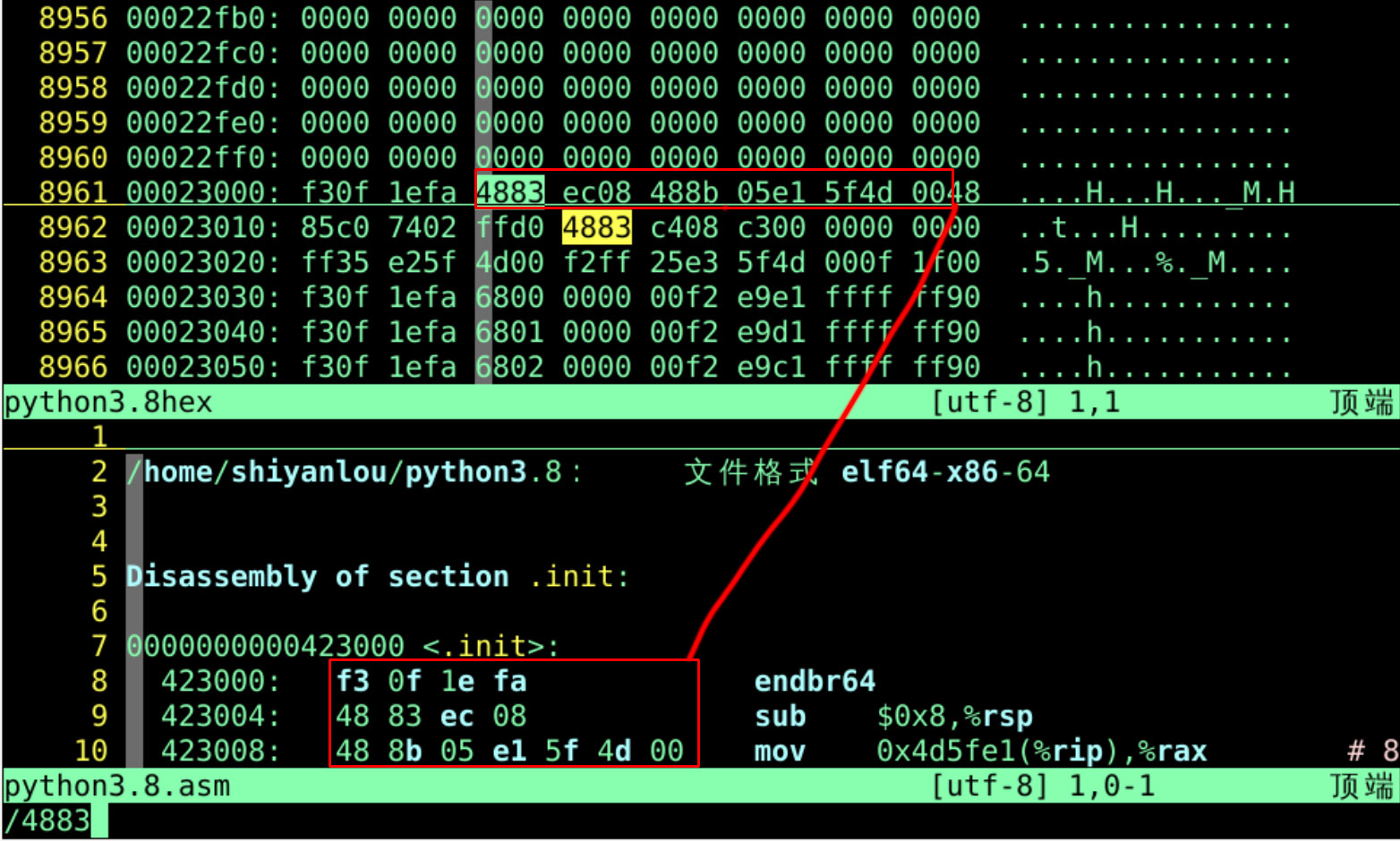
- 好像找到了对应关系
- 具体怎么对应的呢?
- 这台计算机用的是什么指令集呢?
- 什么是指令集来着?
- 指令集就是指令的集合
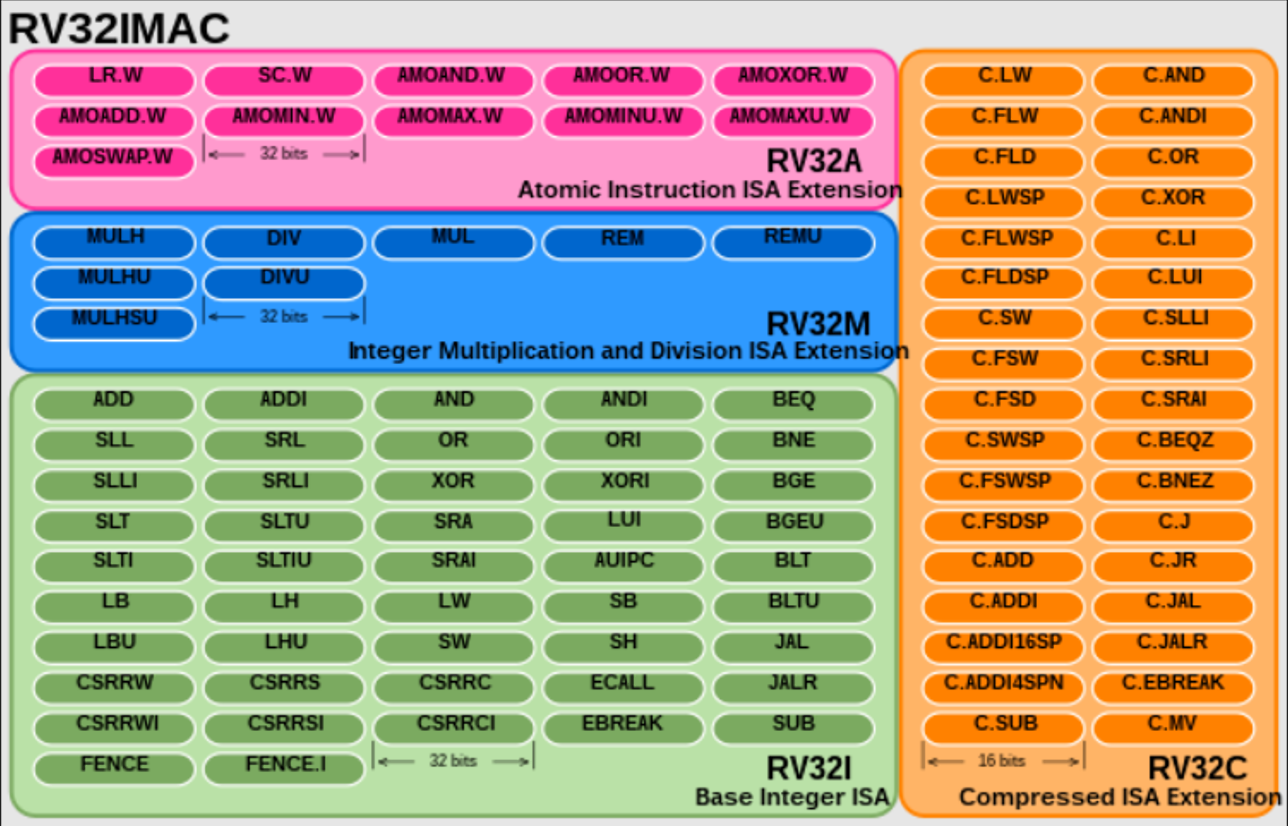
- 指令集也叫计算机的架构
- 不同架构的 cpu 有不同的指令集
- 我们目前的这个浏览器里面的系统用的是
x86-64 - 除此之外
arm、MIPS、RISC-V 也是常用的指令集
- 指令助记符和机器语言到底是则怎么对应的呢?
回到代码
- 代码会有不同的
section 模块
- 入口是
init - 作用是初始化
initialization
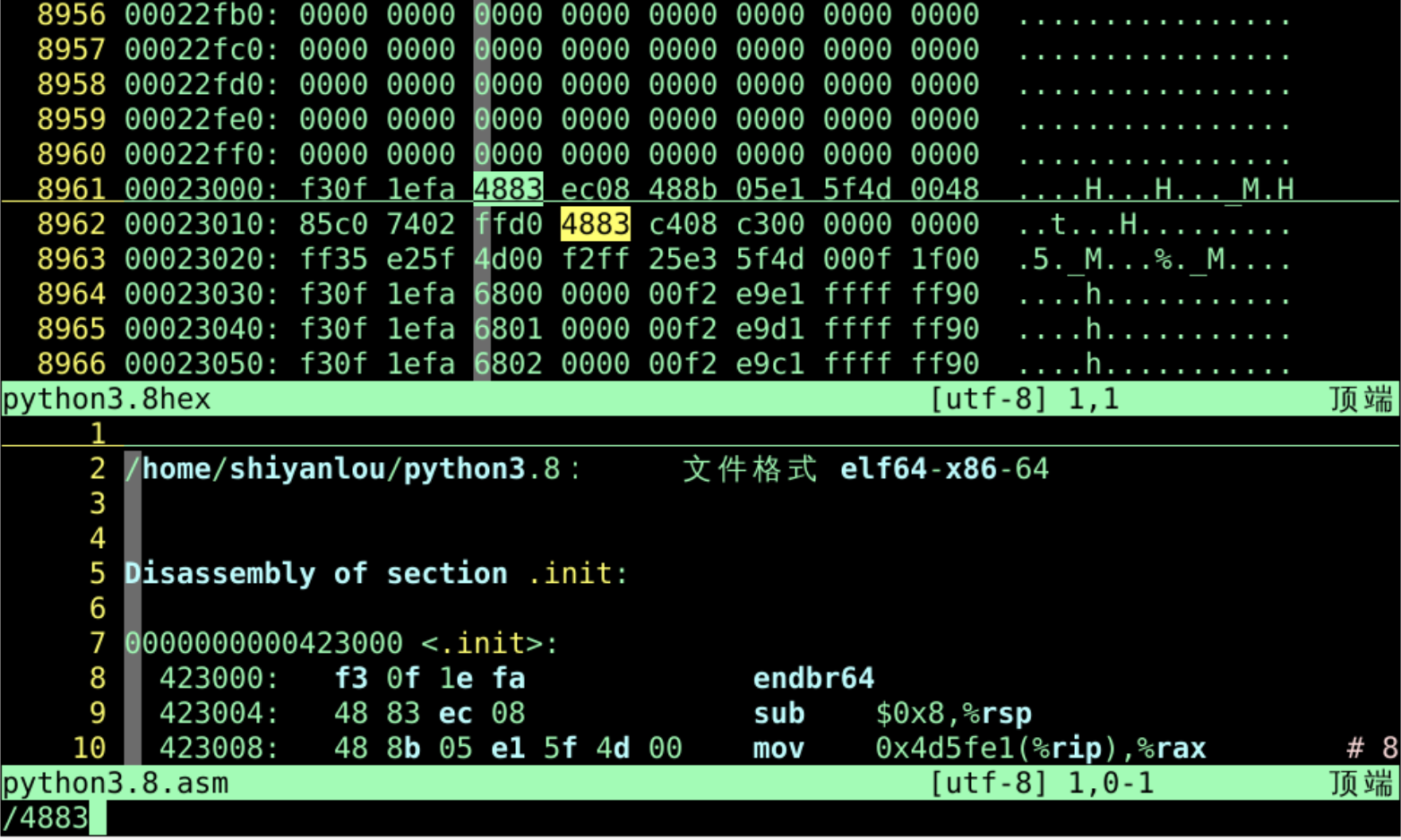
- 模块里面是具体的指令
- 比如第一句
48 83 ec 08
- 为什么48 83 就可以代表减法
- 这是谁规定的呢?
查看指令集
- 这是cpu架构规定的
- 首先要明确到当前机器cpu的架构
- 反汇编里面说是x86-64
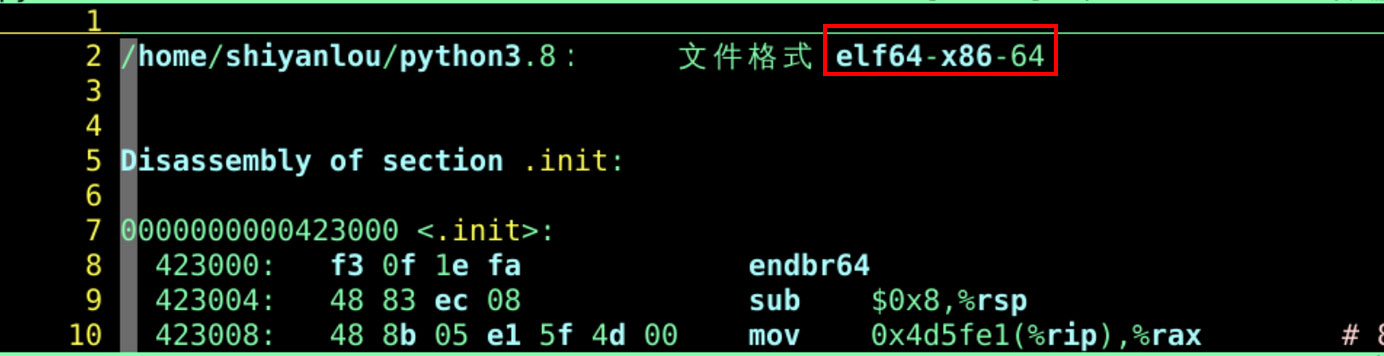
- 到shell里面验证一下

- 当前机器所用的架构指令集确实是x86_64
- 这是谁的架构呢?
搜索
- 不会了就去搜索😄
- 去intel官网找指令集
查询x86_64指令集
- 找到cpu的手册
- 可以找到指令和二进制状态之间的关系么?
- 先要找到x86-64指令集中 48 83 这条指令

- 注意上图中
- 100B中的B是0或1
- 100B可以是1000
- 也可以是1001
- 这确实是一条减法指令
- 而且是8位立即数和寄存器的减法运算
逐步搜索

- 找起来真的很费劲
-
48 83 ec 08 对应sub $0x8,%rsp - 确实是一条减法指令
- 确实是8位立即数和寄存器的减法运算
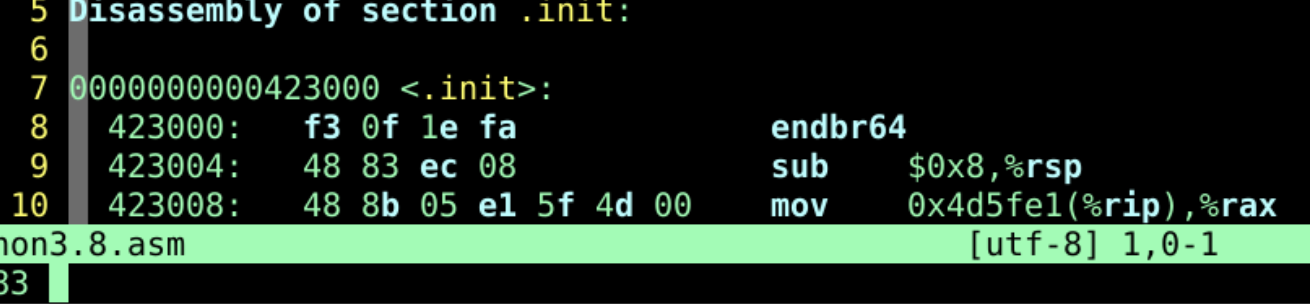
- 和objdump的结果是一致的
- 废话!!!😠
- 除了减法指令sub之外
- 还有什么别的指令呢?
各种cpu指令
- 指令那可还有很多的
- 有运算的
- 有移位的
- 加减乘除都有

- 这些指令的集合就是指令集
- 指令集就是cpu运行的基础!
- 这些机器语言的指令不能在别的指令集架构上运行么?
移植 port
- 想在别的指令集架构上运行程序
- 就需要移植(port)
- 移植(port)指的是从一种指令集移植到另一种指令集
- 从这个词的词源
- 可以看出欧美的航海文化基础
- port 港口
- 也可以看出我们的农耕文化基础
- 移植

- 不移植会如何呢?
不移植
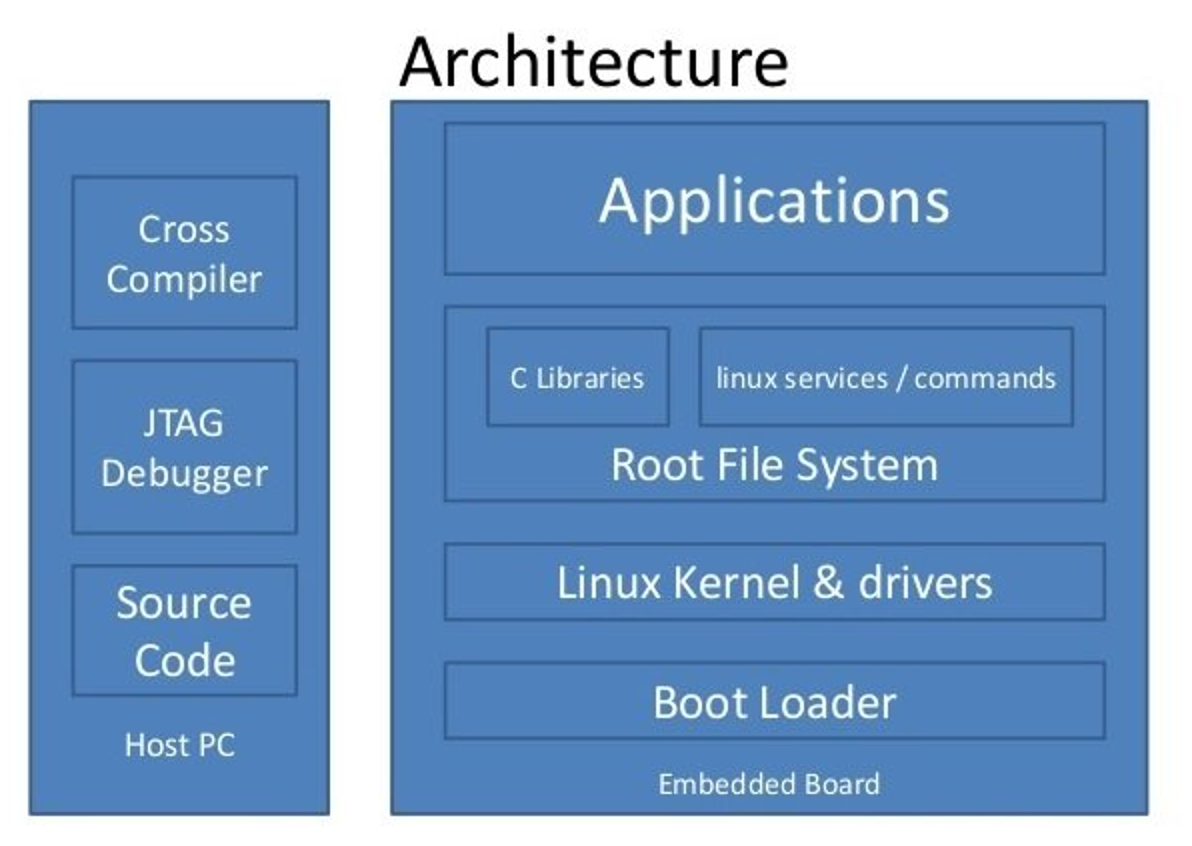
- 这是playstation2的架构图
- cpu是mips架构的

- 不移植的话
- 就是让x86架构的pc
- 去直接执行这些基于mips架构的的0101...
- 就像让一个意大利泥瓦匠看一份中文写成的烹饪书来砌墙
- 鸡同鸭讲
- 驴唇不对马嘴
- 0101的文件执行出来全是乱的
- 完全不能用
- 而且不全是软件的问题
- 也涉及到硬件等方面
- 可能某个寄存器在新架构中根本就不存在
架构师
- 这个时候架构师要解决相当多的问题
- 很不容易的
- 落实到我们的python3.8游乐场
- 我们的python3.8就是这样的一系列的cpu指令
- 可以解释py文件的
- python3.8 又是如何解释py文件的来着?
python3 执行过程
- 不管是python3这个游乐场
- 还是hello.py这个python程序
- 都在我们的硬盘上
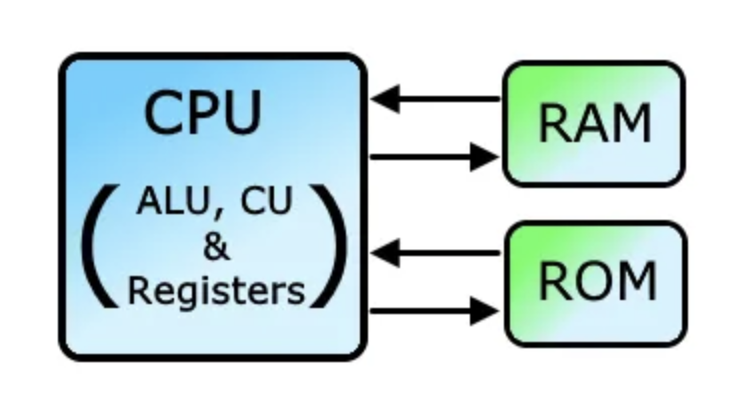
- 先得把文件从硬盘读到内存
python3 执行的过程大致是这样
- 先把python3.8这个主解释器加载到内存中
- 然后在x86-64的cpu上执行
- 模拟出一台python虚拟机
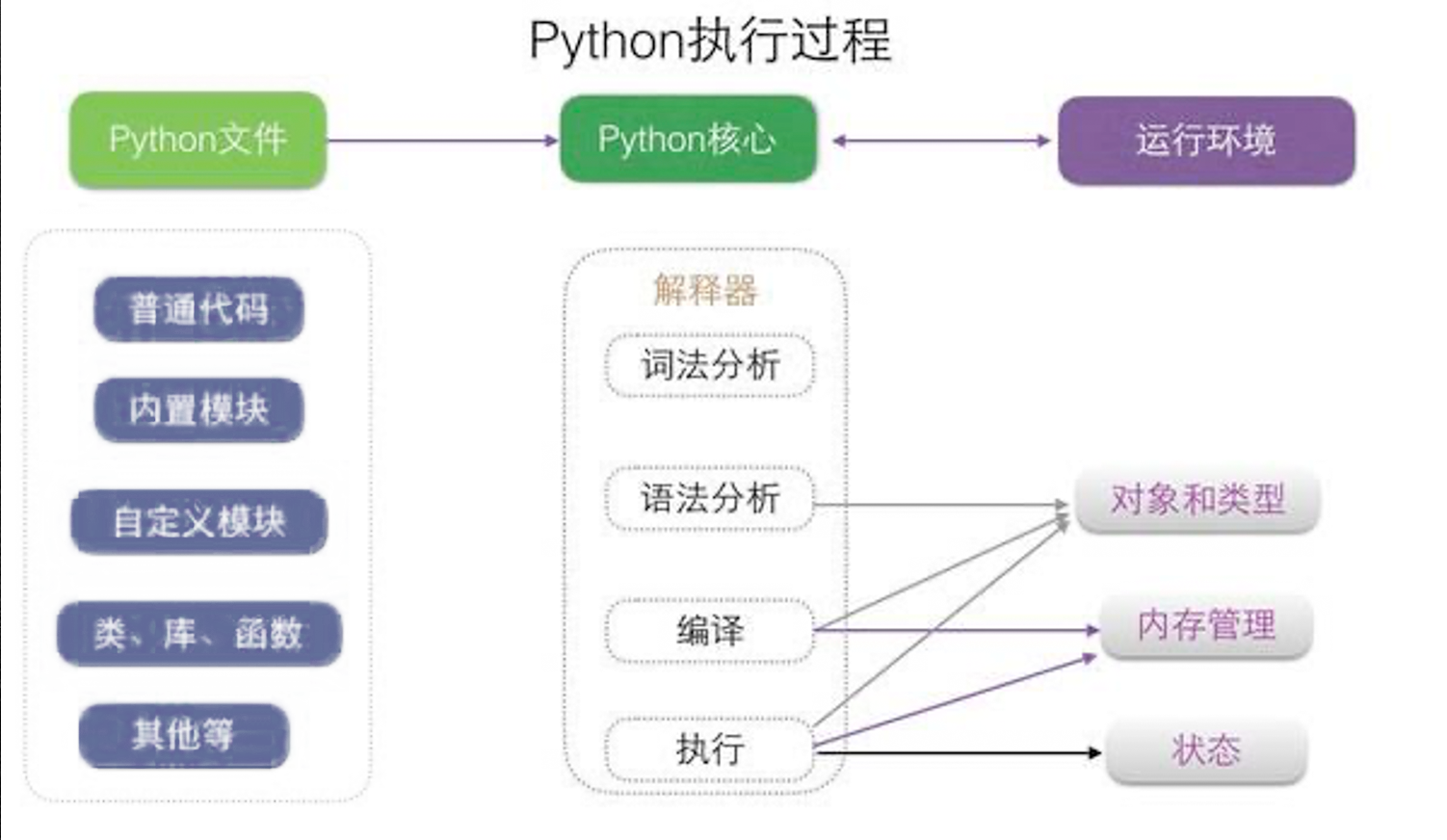
- 准备开始对py文件解释执行
先编译
- 然后把参数
hello.py 这个需要执行的程序加载到内存
- 词法分析 得到 词流(token stream)
- 语法分析 得到 抽象语法树(Abstract Syntax Tree)
- 编译 得到 字节码 (bytecode)
- 也就是编译后的pyc文件
解释执行
- 不过这个pyc指令文件
- 是基于python虚拟机的虚拟cpu的指令集的

- 需要放到模拟好的python虚拟机中
- 一条条指令进行执行
换句话说
- 简化版的hello.py 的执行过程是:
- 给了
python3 一个参数hello.py - 使用
python3 这个解释器来解释执行hello.py -
hello.py中的语句一句句地依次解释执行
- 全解释完成后
- 退出python这个程序
- 把控制权交回到shell

- 这些都是基于解释器python3.8的
- 所谓的解释器也是
- 先编译成python虚拟机的字节码
- 然后用python虚拟机解释直接执行
- 而解释器(python3)是在不同系统不同架构的cpu语言上运行的
- 那不同的系统、cpu架构
- python都能正确地解释么?

架构的层次
- 不同架构的 cpu 都可以运行 python
- risc-v
- arm
- x64
- mips
- 龙芯
- 不同系统的环境都可以运行 python
- win
- mac
- linux
- freebsd
跨架构跨平台原理
- 由于python3可以运行在不同的cpu架构和系统上
- 所以同样的py文件被加载之后
- python程序可以对py文件跨架构、跨系统进行解释执行
- 一次编写到处运行
- 不同的架构
- 二进制对应的汇编指令都不一样
- 怎么能正确解释执行同样的python程序呢?
跨架构跨平台原理
/usr/bin/python3.8 本身是二进制文件
- 是基于当前操作系统当前架构编译出来的可执行二进制文件
- 不同的架构有不同的编译器
- 不同的编译器编译出来的python3.8
- 是不同的二进制指令序列
python3.8 构建了一个运行时环境
- 这个环境可以解释读到的
python语句 - 把
python语句翻译成系统能读懂输入输出 - 翻译成当前架构能够执行的代码
- 然后边解释边执行
- 恭喜您完成了非常烧脑一个实验!
- 我们去总结吧!!!
总结
python3 的程序是一个 5.3M 的可执行文件
-
python3 里面全都是 cpu 指令 - 可以执行的那种
- 我们可以把指令对应的汇编找到
-
objdump -d ~/python3 > python3.asm
- 汇编语句是和当前机器架构的指令集相关的
-
uname -a可以查询指令集
- 我们执行的过程其实就
- 系统执行
python3这个可执行文件 - 给了
python3一个参数hello.py -
python3对于hello.py一句句的解释执行 - 在显示器输出了
hello world -
python3执行完毕 - 把控制权交回给 shell
- 这就是我们执行
hello.py的过程 - 为什么我们学编程总是从
hello world开始呢?🤔 - 我们下次再说!👋
- 蓝桥->https://www.lanqiao.cn/teacher/3584
- github->GitHub - overmind1980/oeasy-python-tutorial: 良心的 Python 教程,面向零基础初学者简明易懂的 Python3 入门基础课程。在linux+vim生产力环境下,从浅入深,从简单程序学到网络爬虫。可以配合蓝桥云上实验环境操作。
- gitee->oeasy教您玩转python教程: 面向零基础初学者的简明易懂的 Python3 入门课程,对没有编程经验的同学也非常友好。在vim下从浅入深,逐步学习。从基础入门学习到爬虫。
- 视频->https://www.bilibili.com/video/BV1CU4y1Z7gQ
-
相关阅读:
【测试开发】一个5年测试开发的成长经验,大学毕业就开启他的职业生涯......
Qt之qobject_cast使用
WPF 控件专题 RadioButton详解
Zookeeper原理解析-单机模式
javaO2O生鲜果蔬电商设计与实现计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
分布式系统架构理论与组件
CentOS安装kafka单机部署
戏说领域驱动设计(三)——困境
Vue-3.5vuex分模块
【期望初步、例题】单选错位+小魔女帕琪+收集邮票
- 原文地址:https://blog.csdn.net/overmind/article/details/127545237