-
CMSC5707-高级人工智能之卷积神经网络CNN
卷积神经网络的概念在本科就已经有了解,笔者这篇文章主要是涉及一些CNN的细节,包括卷积核大小的计算,各层参数个数计算等等。Correlation 与Convolution
Correlation就是在a上移动b,将对应位置的元素两两相乘加起来,得到最后的结果,下面的计算包括了a和b non-overlap的情况,且默认step size=1,因此a输入为 3 × 3 3 \times 3 3×3,最后得到 4 × 4 4\times4 4×4。

但Convolution的计算,则需要先flip,可以看作是根据左对角线整体交换了元素,然后再用correlation计算。

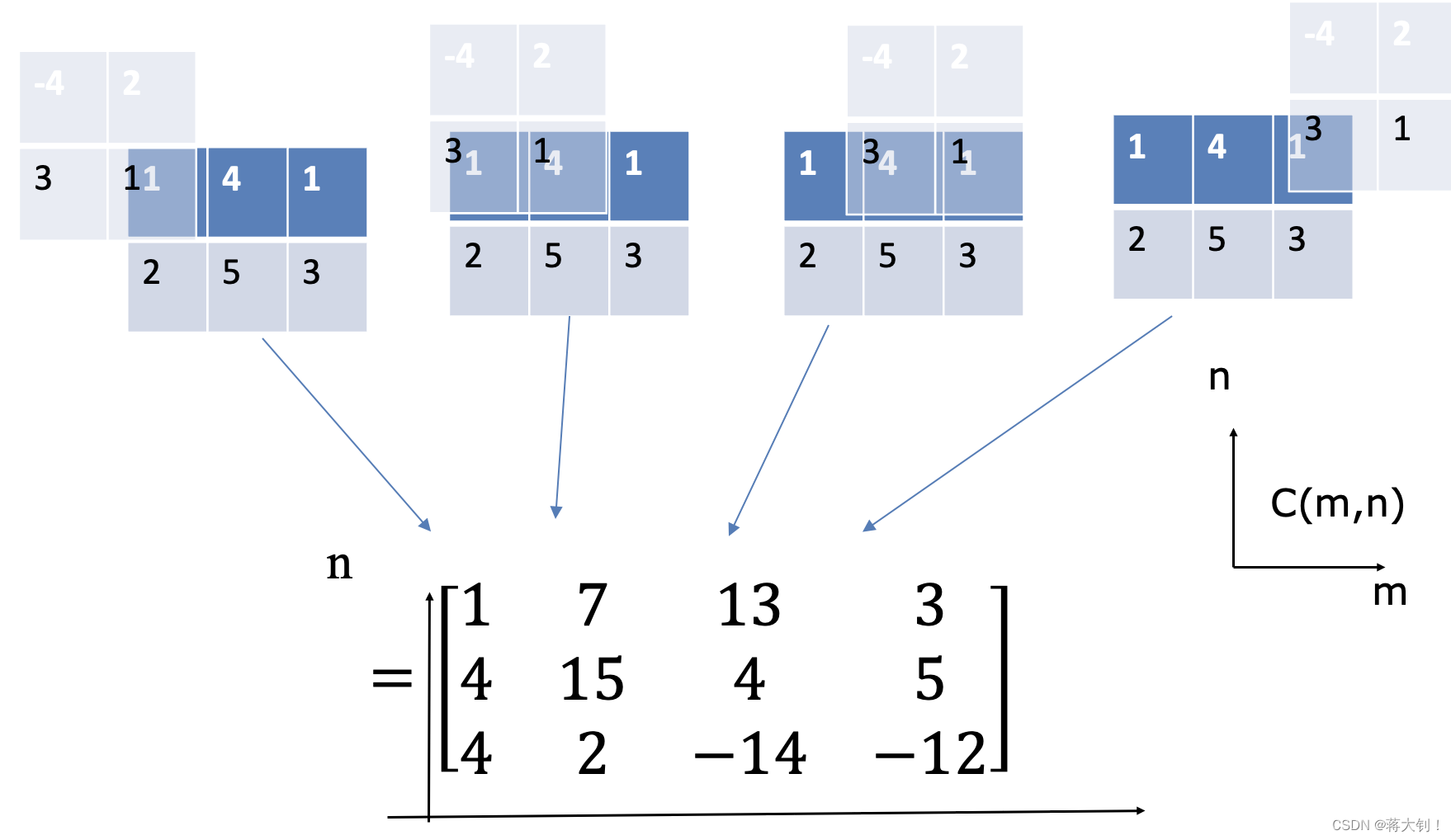
但通常我们直接将Convolution和Correlation看作相同的计算了,在这种情况下,要么就是默认相乘的矩阵kernel已经被flip过了,要么就是说明Convolution is implemented by Correlation. 实际上这两者的计算确实可以相同,主要取决于我们如何给kernel编号了。典型网络参数
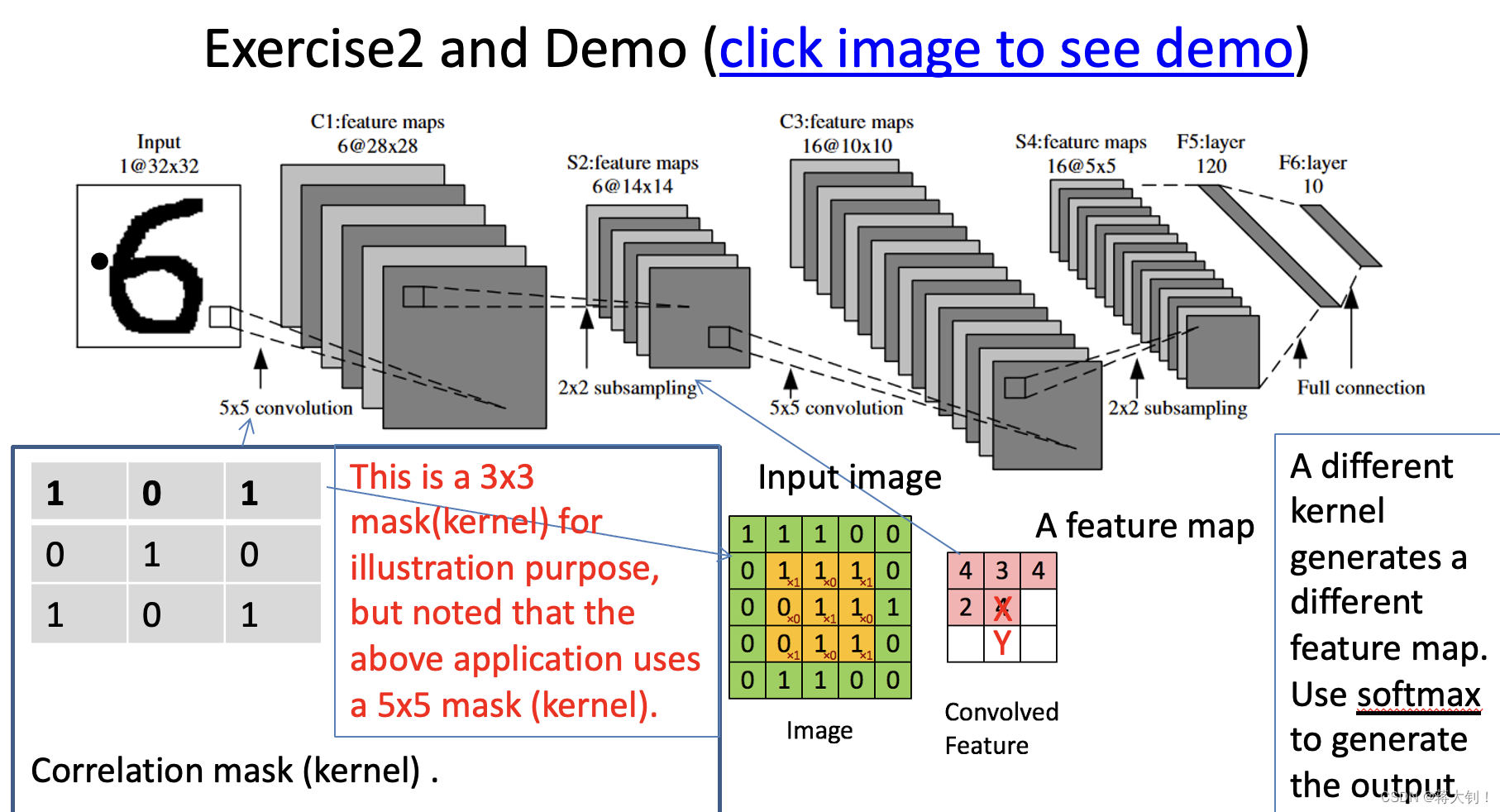
一种典型的卷积神经网络模型如下:
Softmax
最后一层会引入Softmax进行概率计算

Kernel
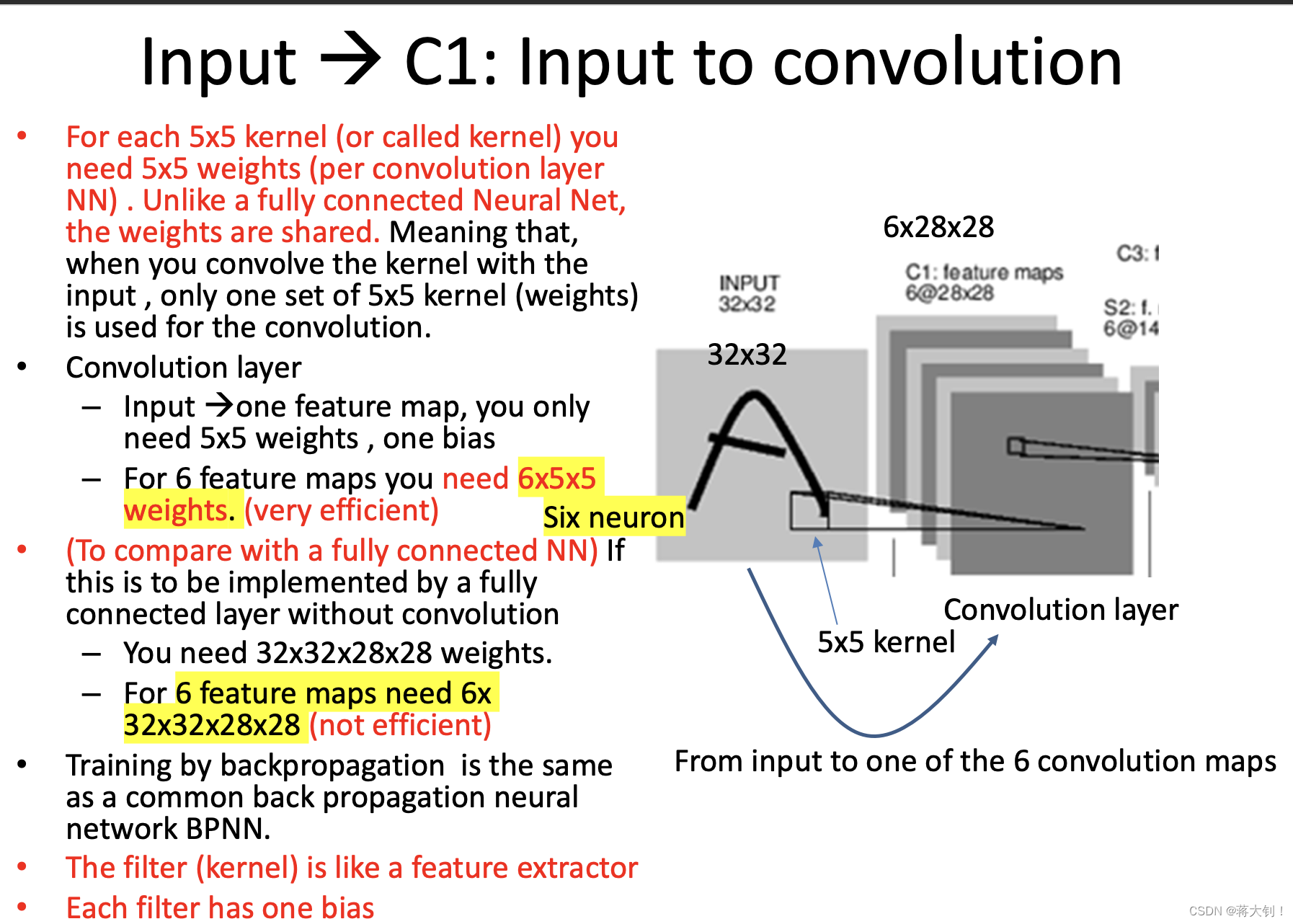
kernel又称作mask, correlation mask, filter,一个kernel所代表的weights就是本身的格子数目,并且在图像的不同区域进行卷积,这些参数是共享的,每个kernel还带有一个bias,一个kernel输出一个feature map,当有多个kernel的时候可以输出多个feature map. 这里的weight个数为
kernel长度*kernel宽度* kernel数量(feature map数量),bias个数为一个kernel对应一个,计算总参数个数就是weight+bias。在不指定的情况下,这里的kernel在计算feature map的时候,kernel对应的元素全和input image重叠,并且step size=1。
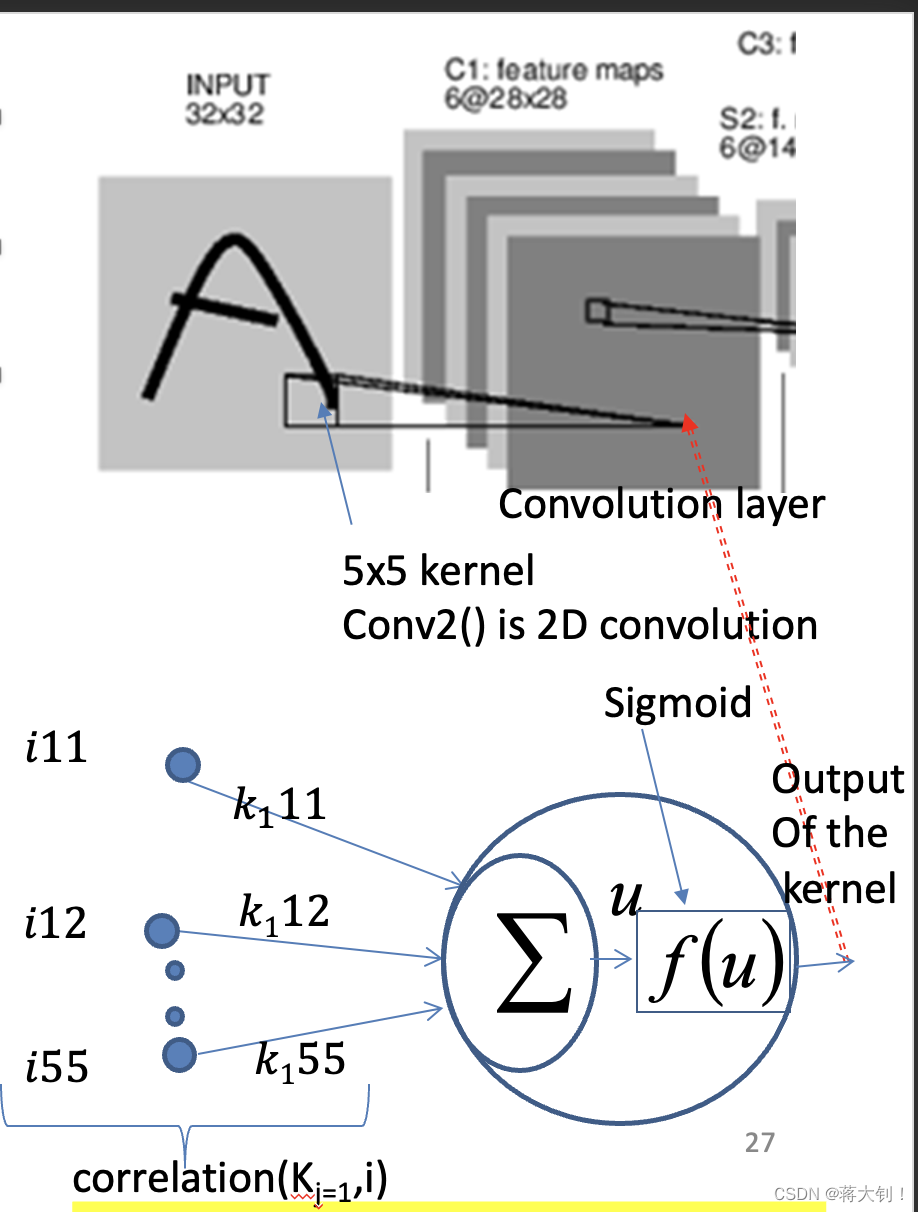
每一次卷积的结果还需要通过activation function进行输出,不过我们通常在手算的时候就直接忽略掉了激励函数处理,直接输出了累加和看结果。
Zero padding
zero padding用在kernel计算中,将没法整分的input image进行补全,最后能够得到完整的feature map. Output_feature_map_width的计算公式如下:
D = ( N − m + 2 ∗ p ) / s ) + 1 D=(N-m+2*p)/s)+1 D=(N−m+2∗p)/s)+1

Subsampling
Subsampling输出大小如下,这一层没有weight和bias。

当卷积网络中进行convolution,输入为多个feature map的时候(也称为多个通道),也可以进行处理。

filter个数决定了这次输出的feature map个数。如下图所示,这里的每个Filter就需要有对应input feature map个数的权重矩阵,并且每个filter带有一个bias,如下图所示,将一个filter内所有权重矩阵算出来的correlation result求和,算出一个结果,放在和input volume对应的位置上。最后整体的weights个数为kernel中的格子数量*input feature map数量* output filter数量,bias个数为filter个数,total parameter=(kernel中的格子数量*input feature map数量+1)* output filter数量。

过拟合
随着epoch的增加,训练数据的loss一直在下降,而测试数据的loss却在下降的过程中陡然变高,就是出现过拟合了,这时候就应该停止训练。
能改进的地方就是使用validation data调整模型参数,让它在early stopping处的test error尽可能小。

-
相关阅读:
React16、18 使用 Redux
Spring boot+Spring security+JWT实现前后端分离登录认证及权限控制
智能捡乒乓球机器人
Python之多进程
【Linux基础】3.3 Linux网络环境配置、设置主机名、HOST映射
Microsoft SQL Server 图书管理数据库的建立
如何找回误删的文件呢?
数据中台可视化:赋能企业数据应用的关键一步
用DIV+CSS技术设计的环保主题网站(web前端网页制作课作业)
面试官:如何搭建Redis集群?
- 原文地址:https://blog.csdn.net/qq_44036439/article/details/127532981