-
微服务实践之全链路追踪(sleuth,zipkin)详解-SpringCloud(2021.0.x)-4
[版权申明] 非商业目的注明出处可自由转载
出自:shusheng007前言
本文将介绍微服务架构中关于链路追踪相关组件Sleuth与Zipkin的在SpringCloud入门使用。
链路追踪
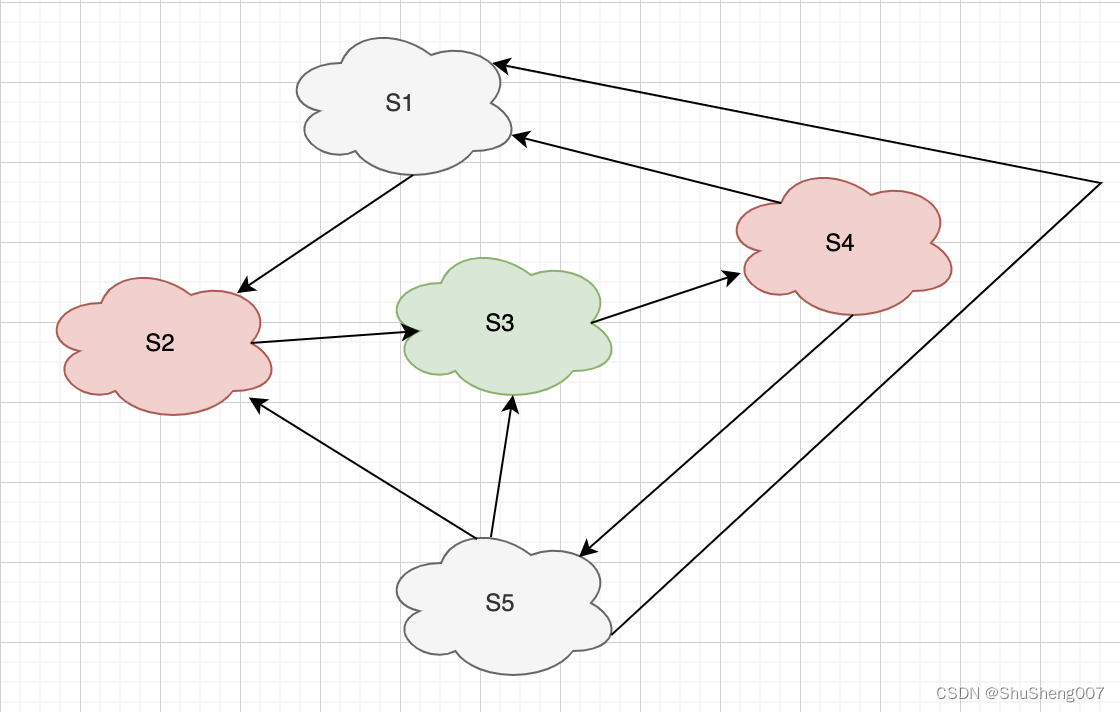
为什么要进行链路追踪啊?为什么它在微服务架构中突然显得那么重要,以前怎么不太受重视啊? 看看下面这个图,只有5个服务以及他们互相调用方式,这但凡某个调用出了问题:请求都经过哪几个服务啦?先过的你还是它啊?那个服务耗时太长拉?等等你是不是半天都理不清,那要是50个微服务呢?很明显,我们需要链路追踪。
理论
目前流行的分布式链路追踪实现方案都是基于Google发布的Dapper相关的论文的,你要是感兴趣可以去看一下Dapper论文,这是中文翻译版:Dapper论文翻译版。论文肯定是比较晦涩难懂拉,但你应该大体明白里面的一些关键概念,例如Trace,Span, Annotations, Sampling(采样率)等
假设现在调用链路是 A-B-C
- Trace
这一次调用是一个trace,以一个全局唯一的id来标识,这个就叫traceId
- Span
A-B就是一个Span,B-C也是一个Span。以一个唯一id来标识,叫spanId
- Annotations
链路的额外信息,例如 服务名称,Ip,调用起始结束时间等信息
- Sampling
采样率,在高并发下,你不可能采集每次调用的信息,所以可以100个调用采集1个。
SpringCloud的实现方案
在SpringCloud中我们可以采用Sleuth加Zipkin来实现全链路追踪,Sleuth负责采集链路信息,Zipkin负责处理展示这些信息。
Zipkin服务
因为要使用Zipkin服务,肯定的需要安装Zipkin的服务,我们以docker的形式安装,以mysql来存储链路信息。
下面是安装的docker-compose文件的一部分,完整部分可以在文章末尾的源码中找到。
... # 数据库 ms_mariadb: image: mariadb:10.6.5 container_name: ms_mariadb ports: - 3306:3306 volumes: - ~/software/database/ms_mariadb/config:/etc/mysql/conf.d - ~/software/database/ms_mariadb/data:/var/lib/mysql environment: - MYSQL_ROOT_PASSWORD=root networks: ms_network: ipv4_address: 172.171.1.11 # 链路追踪 ms_zipkin: image: openzipkin/zipkin container_name: ms_zipkin ports: - 9411:9411 environment: - STORAGE_TYPE=mysql # Point the zipkin at the storage backend - MYSQL_DB=zipkin - MYSQL_USER=root - MYSQL_PASS=root - MYSQL_HOST=ms_mariadb - MYSQL_TCP_PORT=3306 networks: ms_network: ipv4_address: 172.171.1.12 depends_on: - ms_mariadb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
当安装了数据库后,还需要执行zipkin的sql脚本来创建其需要的表,脚本也在文后源码中。
引入依赖
pom文件中引入sleuth的依赖:org.springframework.cloud spring-cloud-starter-sleuth - 1
- 2
- 3
- 4
pom文件中引入zipkin的依赖:org.springframework.cloud spring-cloud-sleuth-zipkin - 1
- 2
- 3
- 4
配置
spring: zipkin: enabled: true baseUrl: http://localhost:9411 sleuth: sampler: rate: 100- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面配置了zipkin的服务地址,以及采样率,这里为了测试将采样率设置为100%。
注意每个服务都要配置哦,这样才能完成全链路的追踪。
使用
当我们引入sleuth的starter后,其就自动为我们的调用织入了追踪信息,例如我们这里使用的
OpenFeign,此外它还可以为rabbitmq,kafka等消息队列织入追踪信息。当我们的order-service这个服务的接口
/order/payment被调用时就会输出如下的日志:2022-10-22 09:04:10.263 DEBUG [order-service,9c759536a9740bb8,fd458cf91ce56f44] 81008 --- [nio-7002-exec-4] o.s.web.servlet.DispatcherServlet : POST "/order/payment", parameters={}- 1
查看日志中
[order-service,9c759536a9740bb8,fd458cf91ce56f44]这部分,后面的两个id,分别是traceId和spanId,sleuth会把这些信息传递给zipkin。接下来我们登录zipkin后台来看下
- 登录
浏览器访问
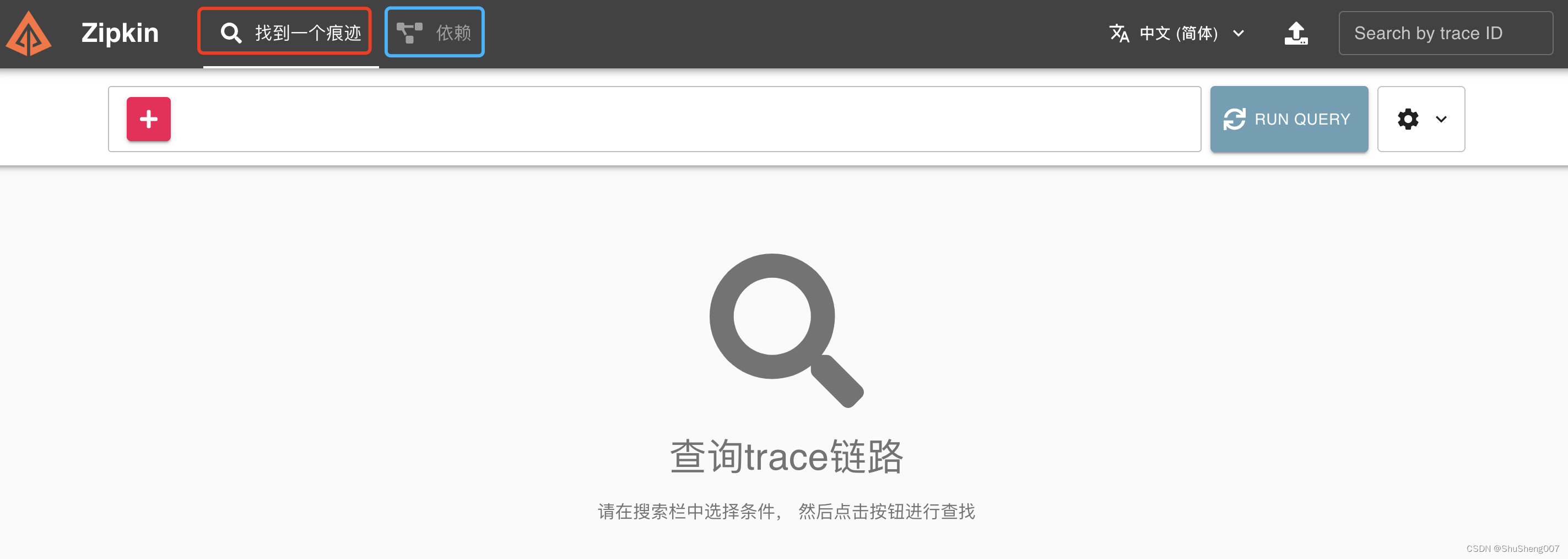
http://localhost:9411如下图所示,红框tab表示你要查询的链路,可以点击那个
+号红色按钮来添加条件查询。蓝框是全局展示调用链路的依赖图,这个特别棒,有了它你再也不用担心请求时怎么走的了。
- 查找链路
你可以通过各种条件来查询链路,例如直接从api-gateway来查,查到的是最全的。
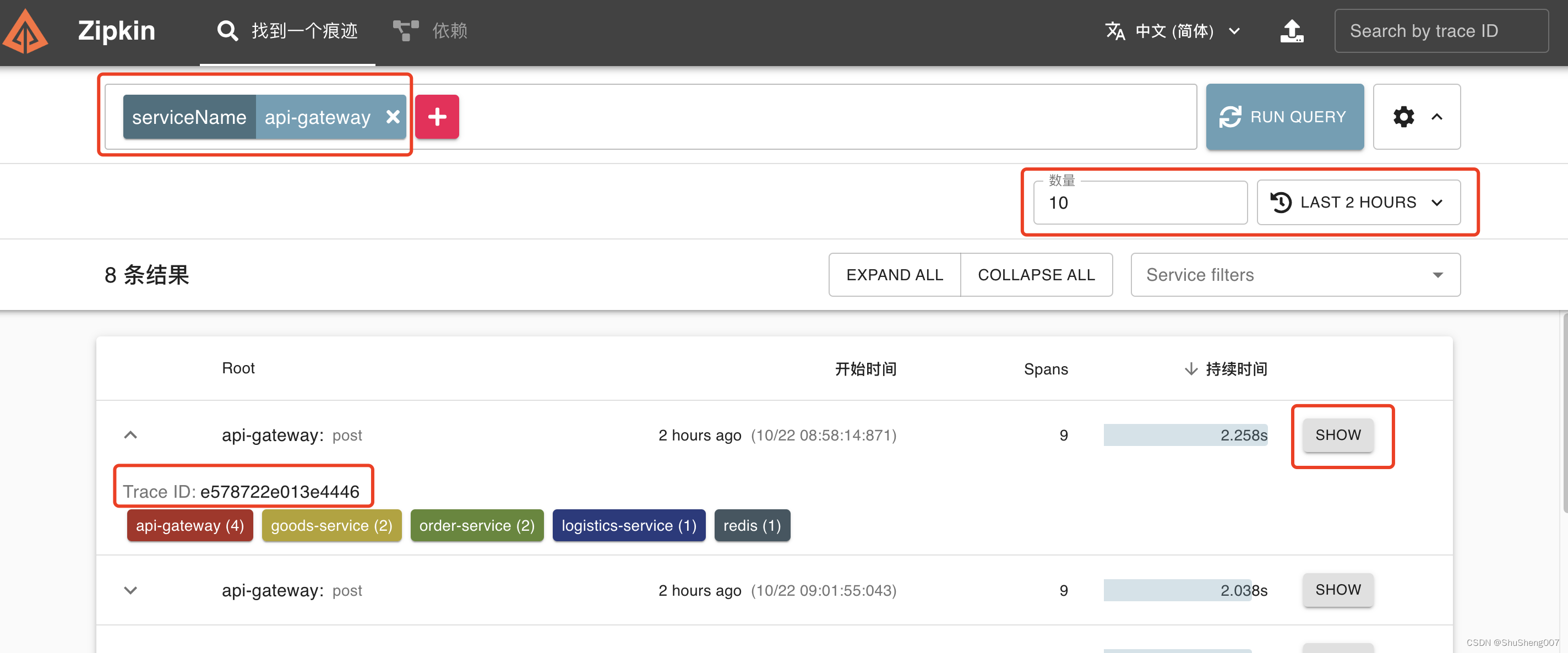
然后点击右边的Show按钮,就会展示此trace的详情。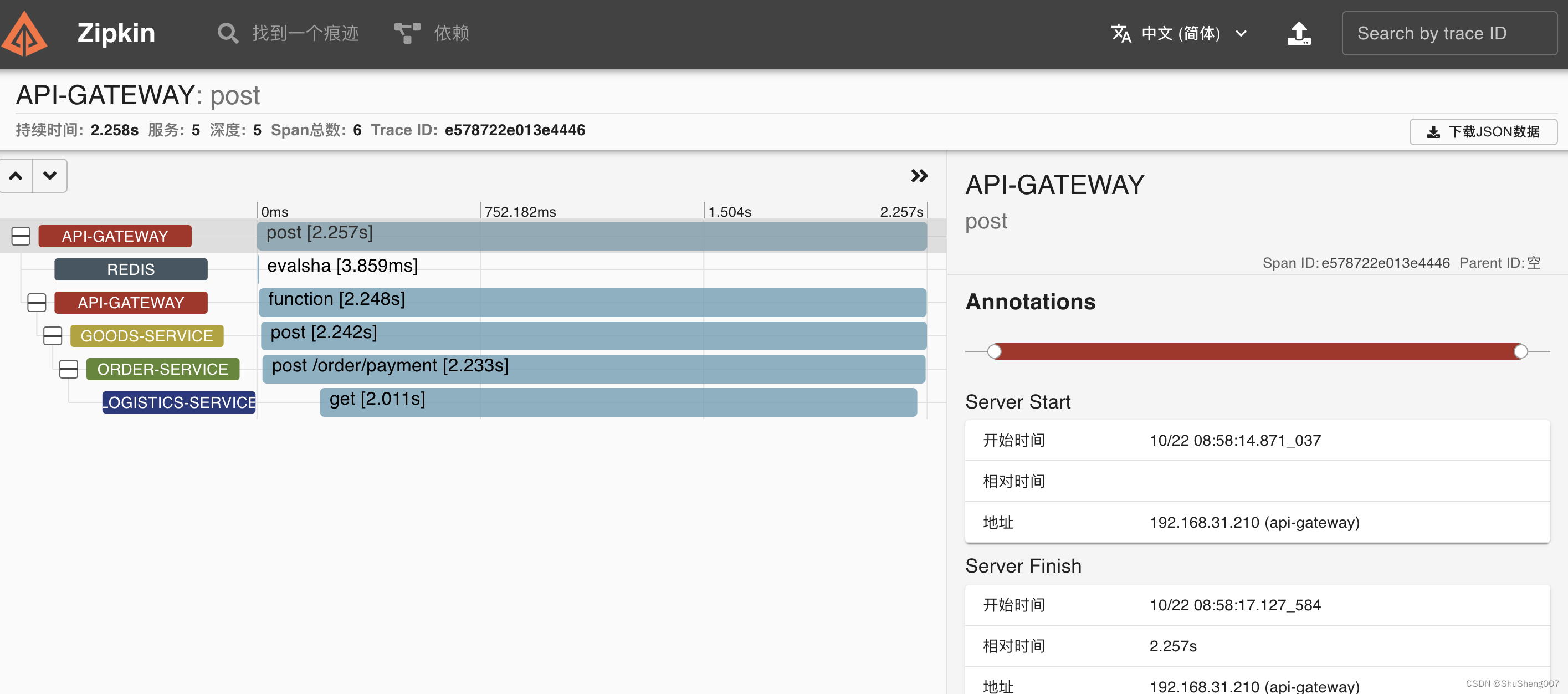
从上面的图,你已经可以清晰的看到调用链,以及每个span所花费的时间。例如从上图可知,最后一个logistics-service耗时最久,达到了2秒多,导致整个请求的响应时间达到2秒多,所以找到了最慢的点,然后进行优化。我们这里出现了redis服务,那是因为网关使用了Redis限流器,所以所有流经gateway的请求都走了redis。
- 查看链路依赖
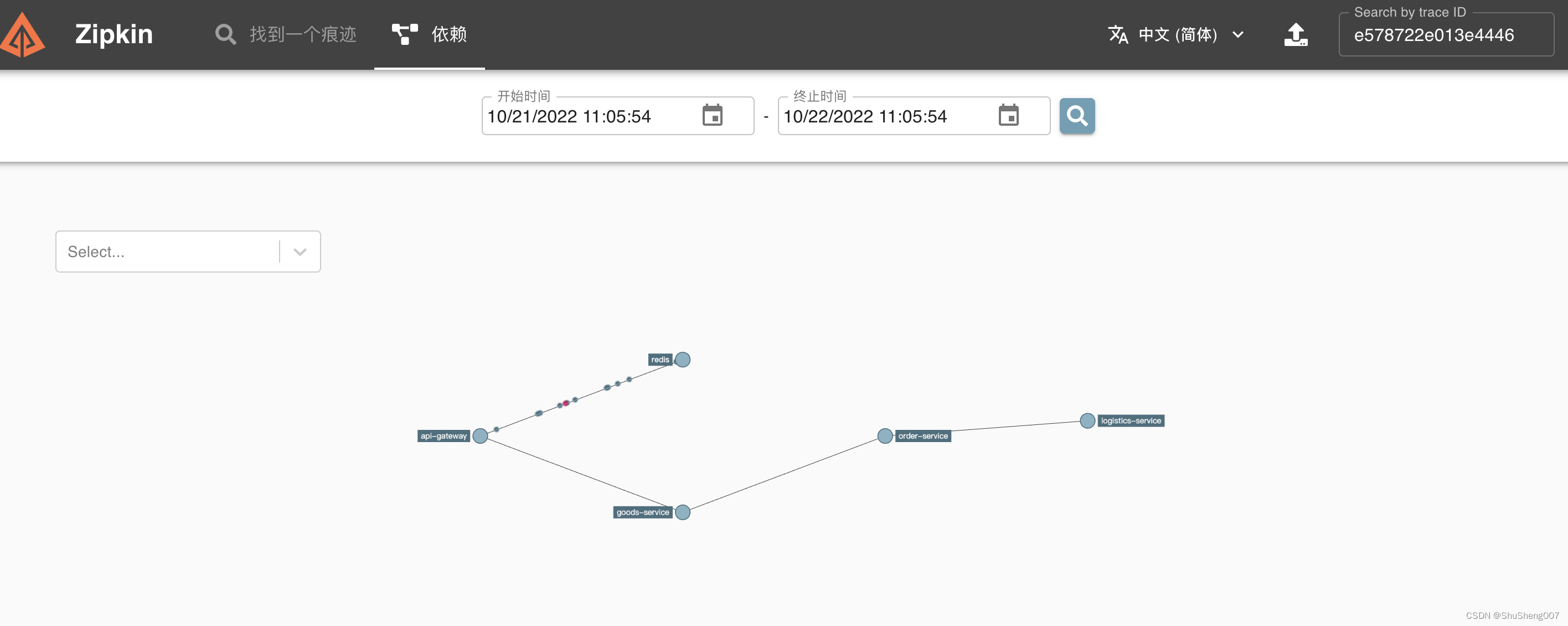
如果你已经查到了traceId,那么直接在右上角使用traceId结合时间来查询即可。
图中清晰的展示了各个此链路的各个节点,实际上zipkin展示的是动态图,你会看到不断有小圆点从一个服务跑到另一个服务,特别棒
总结
在SpringCloud中如何进行链路追踪就至此链路追踪就介绍完了,只是介绍了入门使用,更复杂的还是要在实际工作中慢慢总结,毕竟万事开头难,入门后就靠后天发展了…
源码
一如既往,你可以在Github上找到本文的源代码:master-microservice
-
相关阅读:
python实现简单的神经网络,python的神经网络编程
七星创客商业模式:享受优惠价格和丰厚奖励的新选择!
Python【多分支练习】
机器学习笔记 - 使用具有triplet loss的孪生网络进行图像相似度估计
远程访问本地jupyter notebook服务 - 无公网IP端口映射
【滤波跟踪】扩展卡尔曼滤波的无人机路径跟踪【含Matlab源码 2236期】
Hive优化
HAL库笔记(重要库函数)
Redis key基本使用
Python 实现12306抢票脚本
- 原文地址:https://blog.csdn.net/ShuSheng0007/article/details/127460837
