-
HashMap和Hashtable的联系与区别
前言
Hashtable是java一开始发布时就提供的键值映射的数据结构,而HashMap产生于JDK1.2。虽然Hashtable比HashMap出现的早一些,但是现在Hashtable基本上已经被弃用了。而HashMap已经成为应用最为广泛的一种数据类型了。
一、联系
HashMap继承自AbstractMap类,而HashTable继承自Dictionary类。它们都同时实现了Map(图)、Cloneable(可克隆)、Serializable(可序列化)这三个接口。Dictionary类现已被弃用,父类已被弃用,自然没有人使用它的子类Hashtable。
二、区别
1. 初始容量和每次扩充的容量不同
HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75
- HashMap每次扩充,容量变为原来的2倍;
- HashTable每次扩充,容量会变为原来的2倍+1;
下面给出HashMap中的源码:

拓展:什么是负载因子?
负载因子loadFactor = 哈希表的有效元素个数/哈希表长度
- 这个值越大就说明冲突越严重一些
- 这个值越小说明冲突越小,数组利用率越低
扩容:采用整表扩容的方式什么时候需要对数组扩容?
扩容与否就根据负载因子来决定,当数组长度 * 负载因子 <= 有效元素个数就需要扩容
HashMap中的源码:

2. 对外提供的接口不同
Hashtable比HashMap多提供了elments() 和contains() 两个方法。(某博主写到HashMap没有重写toString 其实两者都重写了toString方法的额)
-
elements() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。
-
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。


3. 底层数组结构不同
- jdk1.7底层都是数组+链表,但jdk1.8 HashMap加入了红黑树,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
- Hashtable 没有这样的机制。
4. 对null值的支持不同
- Hashtable:key和value都不能为null。
- HashMap: key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;
可以有多个key值对应的value为null。
5. 计算hash值的方法不同
为了得到元素的位置,首先需要根据元素的 KEY计算出一个hash值,然后再用这个hash值来计算得到最终的位置。
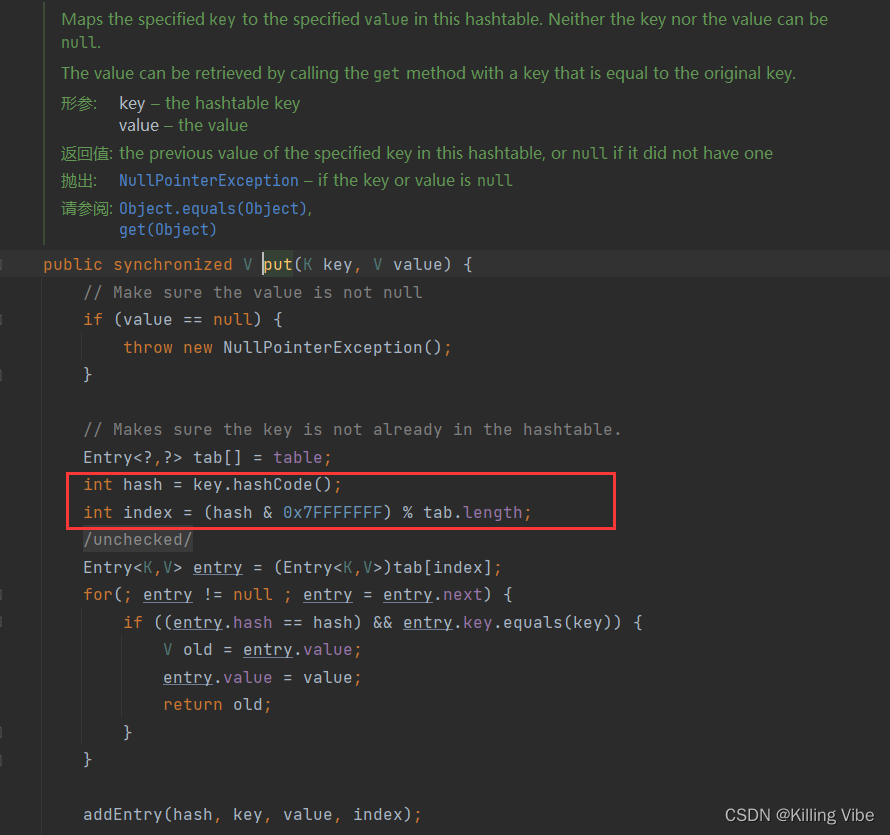
- Hashtable中hash的计算方法为:直接使用对象的hashCode()。
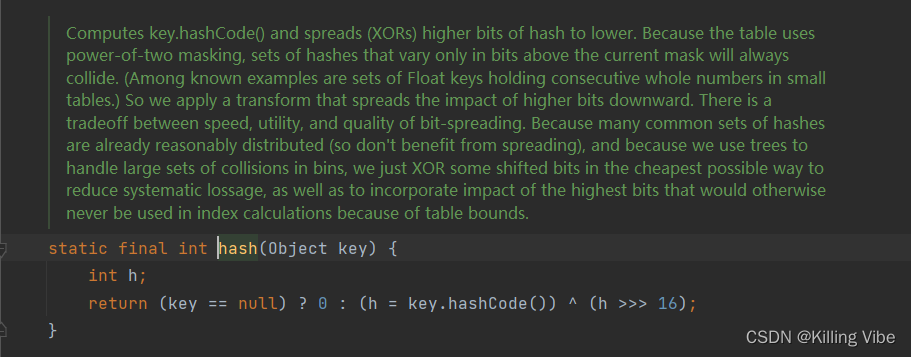
- HashMap中hash的计算方法为:key的 hash 值高16位不变,低16位与高16位异或作为key最终的hash值。(h>>>16,表示无符号右移16位,高位补0)
Hashtable:
HashMap:
拓展:什么是hashCode?
hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。
两者为啥hash算法不一样?
-
Hashtable在计算元素的位置时使用除留余数法来获得存储的最终的位置,而除法运算是比较耗时的。
-
HashMap为了提高计算效率,将哈希表的大小固定为了2的倍数,这样在取模运算时,不需要做除法,只需要做位运算(左移一位就是乘以2)。位运算比除法的效率要高很多。
-
HashMap的效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高。
-
为了解决这个问题,HashMap重新根据hashcode计算hash值后,又将hash值无符号右移16位,使得运算出来所取得的位置分散到高低位中,从而减少了hash冲突。HashMap中采取的这种简单位运算操作,不会把使用2的幂次方带来的效率提升给抵消掉。
6. 线程安全性与效率不同
-
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。在多线程并发的环境下,可以直接使用Hashtable,不需要我们为它的方法实现同步,所以在单线程环境下它的效率要比HashMap低。
-
HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题。使用HashMap时需要自己增加同步处理,不过其效率比Hashtable高的多。
-
在我们的日常使用当中,大部分是单线程操作的,推荐使用HashMap。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。
-
ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
拓展:什么是分段锁?
-
ConcurrentHashMap 中的分段锁称为 Segment,它的内部结构是维护一个 HashEntry 数组,同时 Segment 还继承了 ReentrantLock。
-
当需要 put 元素的时候,并不是对整个 ConcurrentHashMap 进行加锁,而是先通过 hashcode 来判断它放在哪一个分段中,然后对该分段进行加锁。所以当多线程 put 的时候,只要不是放在同一个分段中,就可以实现并行的插入。分段锁的设计目的就是为了细化锁的粒度,从而提高并发能力。
-
jdk1.8 中的 ConcurrentHashMap 中废弃了 Segment 锁,直接使用了数组元素,数组中的每个元素都可以作为一个锁。在元素中没有值的情况下,可以直接通过 CAS 操作来设值,同时保证并发安全;如果元素里面已经存在值的话,那么就使用 synchronized 关键字对元素加锁,再进行之后的 hash 冲突处理。jdk1.8 的 ConcurrentHashMap 加锁粒度比 jdk1.7 里的 Segment 来加锁粒度更细,并发性能更好。
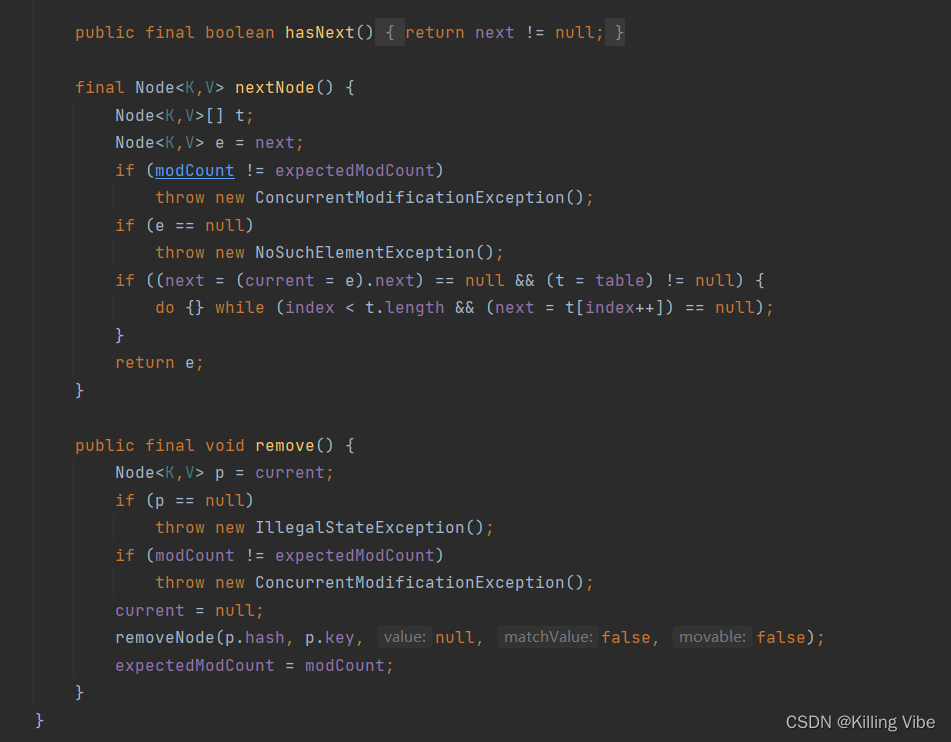
7. 迭代器内部实现不同
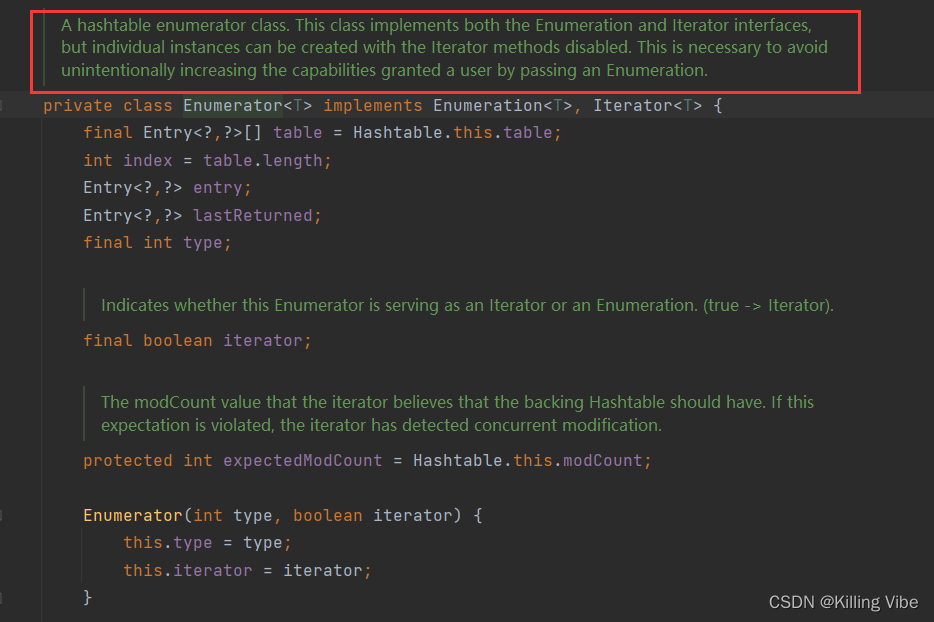
Hashtable、HashMap都使用了 Iterator。Hashtable还使用了Enumeration的方式 。
Hashtable中的 Enumerator类,实现了Enumeration接口和Iterator接口:
 HashMap中的Iterator:
HashMap中的Iterator: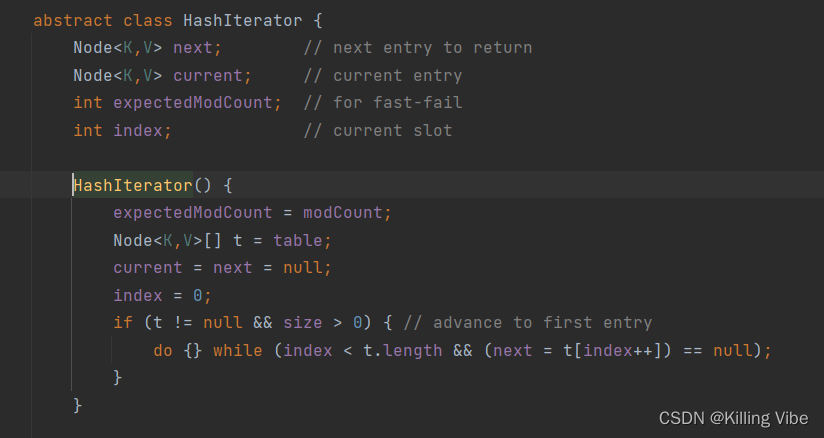
拓展:JDK8之后,HashMap和Hashtable的Iterator都有fast-fail机制。
当有其它线程修改了HashMap的结构时,将会抛出ConcurrentModificationException异常。
注:结构修改是指改变HashMap中的映射数量或以其他方式修改其内部结构 (如,重新哈希,增加,删除,修改元素)。
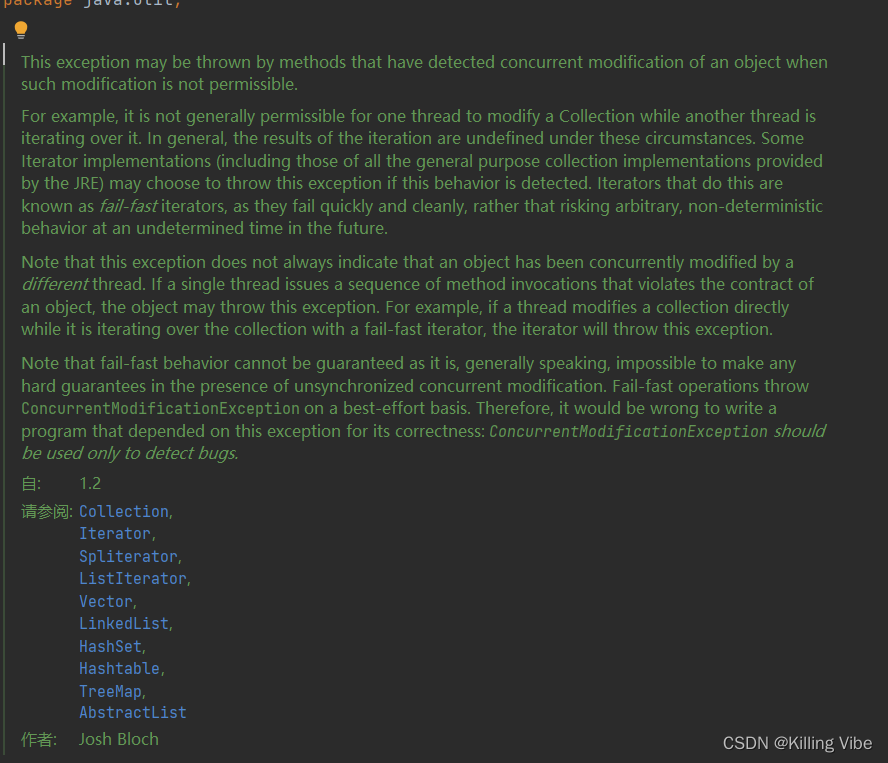
什么是fast-fail机制?
-
例如,通常不允许一个线程在另一个线程迭代Collection时修改它。
-
通常,迭代的结果在这些情况下是没有定义的。如果检测到此行为,一些Iterator实现(包括JRE提供的所有通用集合实现)可能会选择抛出此异常。这样做的迭代器被称为快速失败迭代器,因为它们快速而干净地失败,而不是冒着在未来不确定的时间发生任意、不确定行为的风险。
-
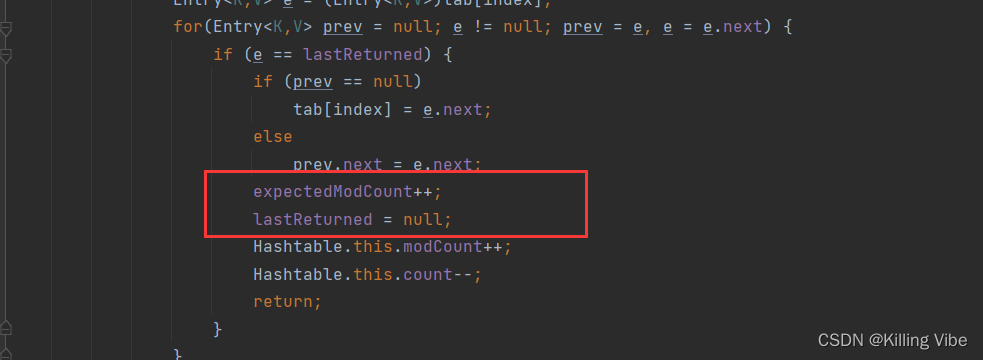
迭代器中的modCount变量,类似于并发编程中的CAS(Compare and Swap)技术。我们可以看到这个方法中,每次在发生增删改的时候都会出现modCount++的动作。
-
而modcount可以理解为是当前hashtable的状态。每发生一次操作,状态就向前走一步。设置这个状态,主要是由于hashtable等容器类在迭代时,判断数据是否过时时使用的。尽管hashtable采用了原生的同步锁来保护数据安全。但是在出现迭代数据的时候,则无法保证边迭代,边正确操作。于是使用这个值来标记状态。一旦在迭代的过程中状态发生了改变,则会快速抛出一个异常,终止迭代行为。
总结
关于迭代器具体是什么,多线程相关的线程安全问题,老铁们可以关注博主后续的更新,或者自行查找一下相关的文章,此篇文章是博主反复查阅HashMap和Hashtable的源码和借阅了部分文章总结出来的,希望各位老铁们可以多多支持~~点赞+关注,感谢!!!😁😁😁
-
相关阅读:
30、同vlan不同网段能否ping通?网络中各种互通与不通的总结分析
计算机网络--应用层(http)
云原生之深入解析K8S集群内的服务通信
IO进程间通信:信号
快鲸智慧楼宇数字化管理平台,赋能商业地产快速转型升级
全网疯传,阿里 P8 技术官的架构笔记外泄:微服务分布式架构实践手册
为chrome浏览器单独设置代理服务器
【GhostNet】《GhostNet:More Features from Cheap Operations》
Node编写更新用户头像接口
【回溯算法】leetcode 46. 全排列
- 原文地址:https://blog.csdn.net/qq_43575801/article/details/127353962