-
Disruptor详细介绍
Disruptor是什么?
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题
(在性能测试中发现竟然与I/O操作处于同样的数量级)。
基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。
2011年,企业应用软件专家Martin Fowler专门撰写长文介绍Disruptor。同年Disruptor还获得了
Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能。
Java内置队列的问题
介绍Disruptor之前,我们先来看一看常用的线程安全的内置队列有什么问题。
Java的内置队列如下表所示
队列 有界性 锁 数据结构 ArrayBlockingQueue bounded 加锁 arraylist LinkedBlockingQueue optionally-bounded 加锁 linkedlist ConcurrentLinkedQueue unbounded 无锁 linkedlist LinkedTransferQueue unbounded 无锁 linkedlist PriorityBlockingQueue unbounded 加锁 heap DelayQueue unbounded 加锁 heap Disruptro与ArrayBlockingQueue性能对比
https://my.oschina.net/u/3434392/blog/3099183
前置知识
Cpu结构
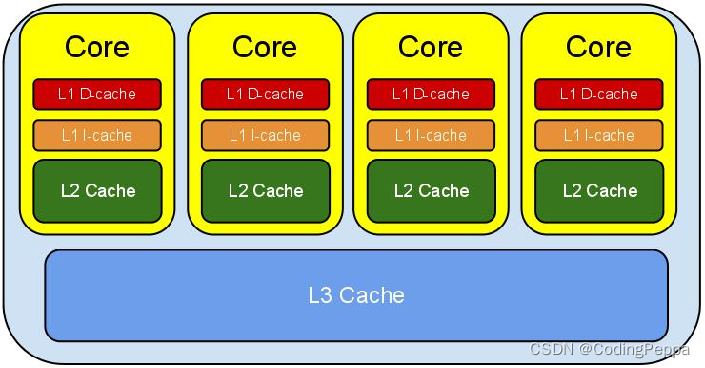
伪共享(False Sharing)
CPU的缓存系统是以缓存行(cache line)为单位存储的,一般的大小为64bytes。
在多线程程序的执行过程中,存在着一种情况,多个需要频繁修改的变量 存在同一个缓存行当中
假设:有多个线程同时访问修改X和Y,X和Y在同一个缓存行上,这两个线程分别在不同的CPU上执行。
两个线程分别修改了X和Y,发现刚刷入的变量已经改变,缓存行失效,又需要重新从L3中读取。
为了减少这种情况的发生,其实就是避免这几个变量在同一个缓存行中
伪共享的本质:
对缓存行中的单个变量进行修改了,导致整个缓存行其他不相关的数据也就失效了,需要从主存重新加
载
如果 其中有 volatile 修饰的变量,需要保证线程可见性的变量,还需要进入 缓存与数据一致性的保障
流程, 如mesi协议的数据一致性保障 用了其他变量的 Core的缓存一致性。
如何解决伪共享
其中一个手段就是通过填充(Padding)数据的形式,来保证本应有可能位于同一个缓存行的两个变量,在被多线程访问时必定位于不同的缓存行。disruptor 无锁框架就是这么干的。
JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充
@Contended public long padVar;- 1
- 2
在Java 8中,使用@Contended注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大
多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。我们目前的缓存行大小一般为64Byte,
这里Contended注解为我们前后加上了128字节绰绰有余。
注意:如果想要@Contended注解起作用,需要在启动时添加JVM参数-XX:-RestrictContended
可见至少在JDK1.8以上环境下, 只有@Contended注解才能解决伪共享问题, 但是消耗也很大, 占用
了宝贵的缓存, 用的时候要谨慎。
@Contended 注释还可以添加在类上,每一个成员,都会加上。
启示
当某个变量,竞争激烈,在高并发环境下,被大量读写,可以使用消除伪共享的机制,提高性能
Disruptor
Disruptor如何解决伪共享
在Disruptor中有一个重要的类Sequence,该类包装了一个volatile修饰的long类型数据value,无论是Disruptor中的基于数组实现的缓冲区RingBuffffer,还是生产者,消费者,都有各自独立的Sequence。
Sequence中的 long类型的Value,左右都用7个long类型做了填充,保证了无论Cpu如何读取该数据,都能让真正的Value始终保持在一个缓存行中。
Disruptor如何实现高性能
Disruptor实现高性能主要体现了去掉了锁,采用CAS算法,同时内部通过环形队列实现有界队列。
- 环形数据结构
环形缓存的一个显著特点是不需要进行 GC,直接通过覆盖过期数据。,数组元素不会被回收,避免频繁的GC,避免了垃圾回收
同时,数组对处理器的缓存机制更加友好。
- 元素位置定位
数组长度2^n,通过位运算,加快定位的速度。
下标采取递增的形式。不用担心index溢出的问题。
index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
- 无锁设计
采用CAS无锁方式,保证线程的安全性
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位
置写入或者读取数据。整个过程通过原子变量CAS,保证操作的线程安全。
- 属性填充:
通过添加额外的无用信息,避免伪共享问题
- 内存预加载:
RingBuffer使用数组Object[] entries来存储元素:
-初始化RingBuffer时,会将所有数组元素entries的指定为特定的事件Event参数,此时Event中的detail属性为nul
-生产者向RingBuffer写入消息时 ,RingBuffer不是直接将数组元素entries指向Event对象,而是先获取Event对象,更改Event对象中的detail属性
-消费者在消费时,也是从RingBuffer中读取Event, 读取Event对象中的detail属性
-由此可见,在生产和消费过程中 ,RingBuffer中的数组元素entries没有发生任何变化,没有产生临时对象,数组中的元素一直存活,直到RingBuffer消亡Disruptor 核心组件
Ring Buffffer
如其名,环形的缓冲区。
曾经 RingBuffffer 是 Disruptor 中的最主要的对象,但从3.0版本开始,其职责被简化为仅仅负责对通过
Disruptor 进行交换的数据(事件)进行存储和更新。
在一些更高级的应用场景中,Ring Buffffer 可以由用户的自定义实现来完全替代。
Sequence
通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序
号逐个递增处理。
Sequence 采用缓存行填充的方式对long类型的一层包装,用以代表事件的序号。
一个 Sequence 用于跟踪标识某个特定的事件处理者( RingBuffffer/Consumer )的处理进度。
虽然一个 AtomicLong 也可以用于标识进度,但定义 Sequence 来负责该问题还有另一个目的,那就是
防止不同的 Sequence 之间的CPU缓存伪共享(Flase Sharing)问题。
另外,Sequence 通过 unsafe 的cas方法从而避免了锁的开销。
Sequencer
Sequencer 是 Disruptor 的真正核心。
生产者与缓存RingBuffffer之间的桥梁、
此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和
消费者之间快速、正确地传递数据的并发算法。
Sequence Barrier
消费者 与 消费者 直接的 隔离 屏障。
消费者 之间,并不是通过 RingBuffffer 进行加锁互斥 隔离,而是 通过 Sequence Barrier 来管理依赖次
序关系, 从而能减少RingBuffffer上的并发冲突;
在一定程度上, Sequence Barrier 类似与 aqs 同步队列
Sequence Barrier 用于保持对 RingBuffffer 的 main published Sequence 和Consumer依赖的其它
Consumer的 Sequence 的引用。
Sequence Barrier 还定义了: Consumer 是否还有可处理的事件的逻辑。
Wait Strategy
定义 Consumer 如何进行等待下一个事件的策略。 (注:Disruptor 定义了多种不同的策略,针对不
同的场景,提供了不一样的性能表现)
Event
在 Disruptor 的语义中,生产者和消费者之间进行交换的数据被称为事件(Event)。
它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor 的使用者定义并指定。
EventProcessor
事件处理器,是消费者线程池Executor的调度单元,
EventProcessor 是对事件业务处理EventHandler与异常处理ExceptionHandler等的一层封装;
EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供事件循环(Event Loop),用于调用
业务事件处理实现EventHandler
EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。
Producer
即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型
RingBuffffer
基于数组的缓存实现,也是创建sequencer与定义WaitStrategy的入口;
Disruptor
Disruptor的使用入口。
持有RingBuffffer、消费者线程池Executor、消费者仓库ConsumerRepository等引用。
等待策略
- BlockingWaitStrategy
Disruptor的默认策略是BlockingWaitStrategy。在BlockingWaitStrategy内部是使用锁和condition来控制线程的唤醒。BlockingWaitStrategy是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现。
- SleepingWaitStrategy
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,通过使用LockSupport.parkNanos(1)来实现循环等待。一般来说Linux系统会暂停一个线程约60µs,这样做的好处是,生产线程不需要采取任何其他行动就可以增加适当的计数器,也不需要花费时间信号通知条件变量。但是,在生产者线程和使用者线程之间移动事件的平均延迟会更高。它在不需要低延迟并且对生产线程的影响较小的情况最好。一个常见的用例是异步日志记录。
- YieldingWaitStrategy
YieldingWaitStrategy是可以使用在低延迟系统的策略之一。YieldingWaitStrategy将自旋以等待序列增加到适当的值。在循环体内,将调用Thread.yield(),以允许其他排队的线程运行。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
- BusySpinWaitStrategy
性能最好,适合用于低延迟的系统。在要求极高性能且事件处理线程数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
- PhasedBackoffWaitStrategy
自旋 + yield + 自定义策略,CPU资源紧缺,吞吐量和延迟并不重要的场景。
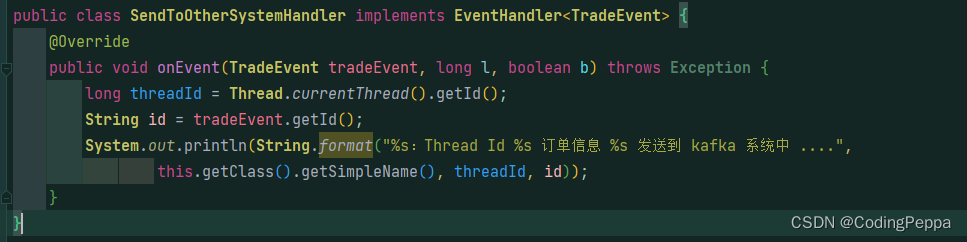
Disruptor使用案例
消费者:


生产者:

Main方法验证:
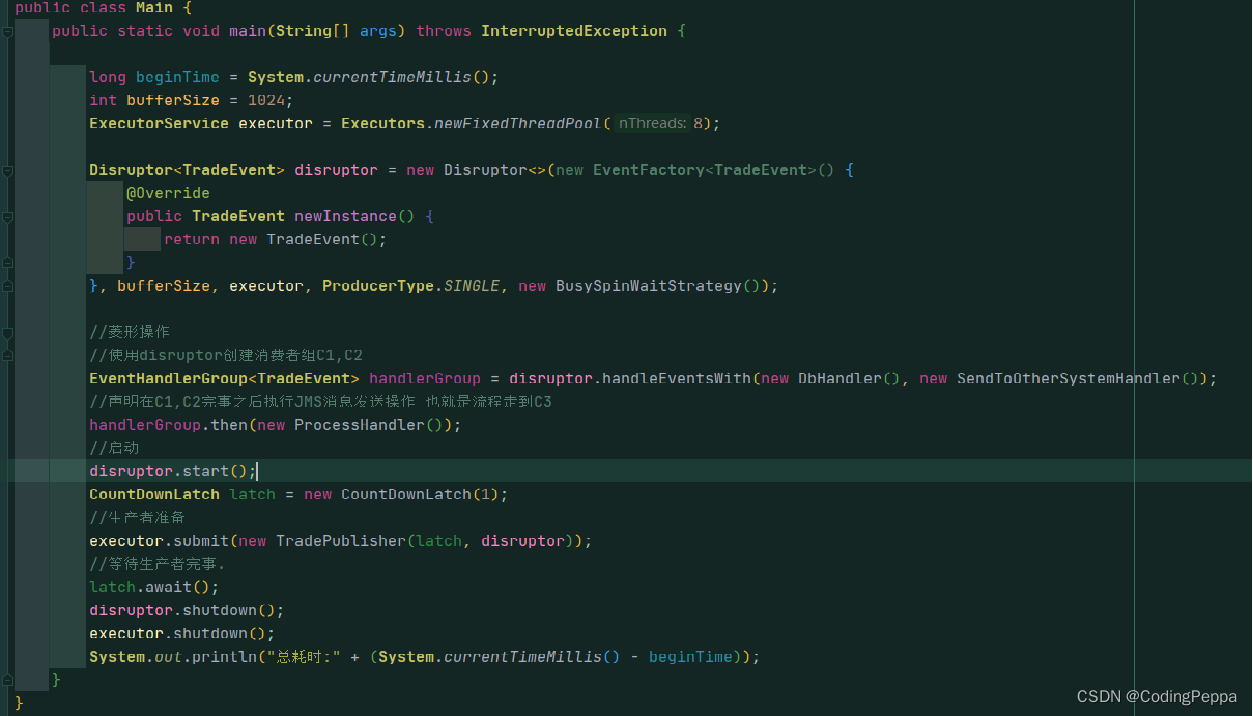
Disrurptor 可通过DSL编程实现消费者间任意方式的组合消费:多消费者串行,多消费者并行,多消费者竞争并行。 -
相关阅读:
Anycloud37D平台移植wpa_supplicant
ubuntu 22 安装 python3.11.7
Kafka - Broker 详解
Linux内核驱动开发-001字符设备开发-内核中断驱动独立按键
单向的2.4G频段RF射频芯片-SI24R2E
JAVA定时任务怎么实现
软件分享 | 第十二期 yoco文库下载
TCP滑动窗口
控制台警报:DevTools failed to load SourceMap
PMP提分练习
- 原文地址:https://blog.csdn.net/qq_44073614/article/details/127428053