-
【redis】字符串
1、redis数据结构的存储
在说字符串之前我们先了解一下redis中的数据结构都是怎么存储的。
在redis中使用一个redisObject数据结构保存所有的键值对形式。
下面是redisObject的定义。typedef redisObject{ unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; int refcount; void* ptr; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- type:数据的类型:由OBJ_STRING,OBJ_LIST,OBJ_SET等等。
- encoding:编码格式,在redis中即使数据类型相同,存储数据的编码格式也有不同,以字符串为例,就分为OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_RAW这三种编码格式。后面会详细介绍这三种编码格式。
- lru:24位,LRU时间戳或者LFU计数。用于管理数据过期。
LRU:least recently used,最远使用的。 LFU:least ferquently used,最少使用- 1
- 2
- refcount:引用计数,参考JVM里的垃圾回收算法的引用计数法。
- ptr:指向实际的数据。
2、redis里面字符串的存储
redis中为了存储不同长度的字符串,定义了不同的sds结构体来存储。
有sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64。
其中sdshdr5的结构体较为特殊。
sdshdr5的结构体定义typedef sdshdr5{ unsigned char flags; char buf[]; }- 1
- 2
- 3
- 4
sdshdr8的结构体定义,sdshdr16,32,64就只是将len和alloc的数据类型换成了uint16_t,uint32_t,uint64_t
typedef sdshdr8{ uint8_t len; uint8_t alloc; unsigned char flags; char buf[]; }- 1
- 2
- 3
- 4
- 5
- 6
结构体中各个参数的含义
- len:代表字符串的长度。
- alloc:代表分配的长度,sdshdr8分配的长度就是2的8次幂。
- flags:第三位代表结构体的类型,高五位只用在sdshdr5种,代表字符串的长度,在redis中对于sdshdr5类型的定义是常量字符串,所以sdshdr5中没有len和alloc属性。
- buf:保存字符串的内容,这个字符串是C的字符串其结尾是由’\0’的,但是len属性并没有算上这个长度。
3、redis字符串的创建
- 根据字符串的长度获得字符串的类型
- 当字符串类型为sdshdr5且字符串长度为0时,通常需要扩容,将类型替换为sdshdr8。
- 为字符串分配空间。hdrlen+strlen+1。
hdrlen:代表结构体所占空间长度,sdshdr5只用一个char类型的flags。而对于sdshdr8来说还有两个uint8_t类型的参数。 strlen:字符串的长度。 1:用来存储'\0'- 1
- 2
- 3
- 最后将字符串复制给buf。
4、字符串的扩容
s指向buf的头部,addlen代表需要扩容的空间
sds _sdsMakeRoomFor(sds s, size_t addlen, int greedy) { void *sh, *newsh; // sds中可用的空间 size_t avail = sdsavail(s); size_t len, newlen, reqlen; char type, oldtype = s[-1] & SDS_TYPE_MASK; int hdrlen; size_t usable; //可用空间大于addlen时,不用进行扩容 if (avail >= addlen) return s; //原字符串长度 len = sdslen(s); //指向sds的结构体 sh = (char*)s-sdsHdrSize(oldtype); // 新字符串的长度 reqlen = newlen = (len+addlen); assert(newlen > len); /* Catch size_t overflow */ //SDS_MAX_PREALLOC的大小为1024*1024字节,但新字符串长度超过它时,每次扩容加1MB的空间。否则空间扩容一倍。 if (greedy == 1) { if (newlen < SDS_MAX_PREALLOC) newlen *= 2; else newlen += SDS_MAX_PREALLOC; } // 计算扩容后新的sds结构体类型,不允许使用sdshdr5 type = sdsReqType(newlen); if (type == SDS_TYPE_5) type = SDS_TYPE_8; //扩容后结构体的空间 hdrlen = sdsHdrSize(type); assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */ if (oldtype==type) { //扩容后结构体类型没变,使用realloc分配空间 newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable); if (newsh == NULL) return NULL; s = (char*)newsh+hdrlen; } else { //扩容后结构体改变,使用malloc重新分配空间 newsh = s_malloc_usable(hdrlen+newlen+1, &usable); if (newsh == NULL) return NULL; memcpy((char*)newsh+hdrlen, s, len+1); s_free(sh); s = (char*)newsh+hdrlen; s[-1] = type; sdssetlen(s, len); } usable = usable-hdrlen-1; if (usable > sdsTypeMaxSize(type)) usable = sdsTypeMaxSize(type); sdssetalloc(s, usable); return s; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
5、字符串的编码
-
OBJ_ENCODING_INT
顾名思义就是将字符串转化为整型数据存储,对于“123456789012”这种数值型字符串使用char数组存储需要占用12个字节,而使用long long类型来存储只用8个字节,可以降低内存的占用。 -
OBJ_ENCODING_EMBSTR
存储长度小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44个字节)的字符串。
在该编码格式下,redisObject和sds存储在一片连续的内存块中。
优点在于:
1、redisObject和sds的内存分配和释放只用执行一次。
2、由于使用一片连续的内存块,减少了空间碎片的存在。 -
OBJ_ENCODING_RAW
存储长度大于OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44个字节)的字符串。
redisObject和sds存储在两个不连续的内存块中。
6、字符串数据的优化步骤
redis中所有的键都是字符串类型,但是它的编码格式只能为OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR
redis中字符串键值对的值在存储时会进行优化,选择合适的编码格式
- 第一步:判断对象是否有被多处引用(refcount>1),有的情况下编码格式不能改,退出优化。
- 第二步:判断字符串长度是否小于等于20,且可以转化为long long类型的整数,不可以则跳到第六步。
- 第三步:redis具有一个共享数据集,存放小数字0~9999。如果能够使用共享数据,sds指向共享数据集。
- 第四步:不能使用共享数据集,且原编码格式使用OBJ_ENCODING_RAW,sds指向字符串转换成的数值。
- 第五步:不能使用共享数据集,且原编码格式使用OBJ_ENCODING_EMBSTR,由于空间连续无法替换redisObject.ptr,分配一个新的redisObject。
- 根据字符串长度选择使用OBJ_ENCODING_RAW还是OBJ_ENCODING_EMBSTR编码。
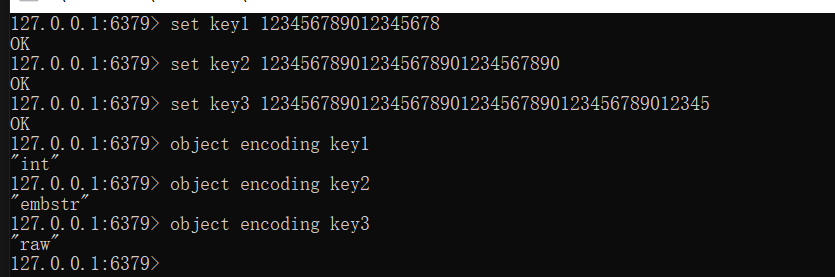
7、在redis中验证字符串的编码
创建三个字符串类型的键值对。其中value都是数值字符串。
key1:长度为18,对应的编码格式为“int”
key2:长度为30,对应的编码格式为“embstr”
key3:长度为45,对应的编码格式为“raw”
-
相关阅读:
Arduino IDE的下载和安装
微信小程序开发学习笔记——3.11完成form评论案例的实现逻辑
Python基本语法(未完待续)
什么是 HTTPS 的证书信任链?自己给自己发行不行?
Mybatis的优缺点
哈工大李治军老师操作系统笔记【8】:用户级线程(Learning OS Concepts By Coding Them !)
qemu-system-arm搭建arm仿真环境
Git --》如何在IDEA中玩转Git与GitHub?
Collection和list和set集合的增删改查及遍历方式
网络基本知识——双绞线(文字 + 图解)
- 原文地址:https://blog.csdn.net/m0_46661713/article/details/126902708
