-
【Netty 从成神到升仙系列 四】让我们一起探索 Netty 中的零拷贝
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄(回复 “技术书籍” 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙、操作系统从入门到成神
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
一、编解码器
解码器:将字节解码成消息
编码器:将消息编码为字节
1. 一次解码器
解决半包、粘包问题的常用三种解码器

将客户端发送过来的字节数组转为可使用的用户数据
io.netty.buffer.ByteBuf(原始数据流)> io.netty.buffer.ByteBuf(用户数据)2. 二次解码器
需要和项目中所使用的对象做转化的编解码器
- Java 序列化
- Marshaling
- XML
- JSON
- MessagePack
- Protobuf
- 其他

二次解码器的速度对比:
链接:https://www.howtoautomate.in.th/protobuf-101/2017-05-06-10_30_22-serialization-performance-comparisonxmlbinaryjsonp/

MessagePack
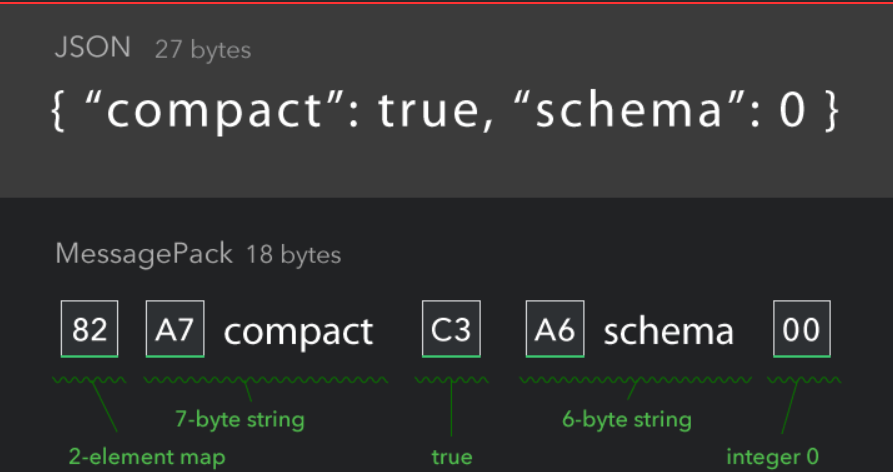
优点:压缩之后占用字节较少
缺点:压缩后的内容晦涩难懂
3. 解码器为什么要分次?
一次和二次的功能不同
一次主要是针对客户端传输过来的数据转变为用户数据,这个解码主要避免粘包、半包问题
而二次解码的作用在于将用户数据转为可用的对象数据。
一次和二次的不同解码结合,能创建更多的选择
如果合二为一,一定程度上浪费了其扩展性
4. 解码器源码分析
4.1 String 解码器
@Override protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception { out.add(msg.toString(charset)); }- 1
- 2
- 3
- 4
4.2 NETTY的Java序列化编解码器
在
io.netty.handler.codec.serialization.ObjectEncoder这个类中,存在encode方法,这个方法调用了CompactObjectOutputStream@Override protected void encode(ChannelHandlerContext ctx, Serializable msg, ByteBuf out) throws Exception { int startIdx = out.writerIndex(); ByteBufOutputStream bout = new ByteBufOutputStream(out); ObjectOutputStream oout = null; try { bout.write(LENGTH_PLACEHOLDER); // 重点主要在这 oout = new CompactObjectOutputStream(bout); oout.writeObject(msg); oout.flush(); } int endIdx = out.writerIndex(); out.setInt(startIdx, endIdx - startIdx - 4); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
实现的方法都是在
CompactObjectOutputStream(bout)中,于是,我们一起看一下这个方法里面做了什么@Override protected void writeClassDescriptor(ObjectStreamClass desc) throws IOException { Class<?> clazz = desc.forClass(); if (clazz.isPrimitive() || clazz.isArray() || clazz.isInterface() || desc.getSerialVersionUID() == 0) { write(TYPE_FAT_DESCRIPTOR); super.writeClassDescriptor(desc); } else { //比较JDK的,少很多信息:元信息 write(TYPE_THIN_DESCRIPTOR); //但是也写了类的名字,这点在反序列化(用反射)时就会用到,很重要 writeUTF(desc.getName()); } /**下面是JDK代码:JDK的序列化多写了下面一些信息 out.writeShort(fields.length); for (int i = 0; i < fields.length; i++) { ObjectStreamField f = fields[i]; out.writeByte(f.getTypeCode()); out.writeUTF(f.getName()); if (!f.isPrimitive()) { out.writeTypeString(f.getTypeString()); } } */ }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
通过上述对比,我们可以发现:
Netty 对于 Java 的序列化又封装了一层,较高的提高了序列化反序列化的性能
- Netty:直接塞一个描述符
TYPE_THIN_DESCRIPTOR,将类名字塞进去,后续通过反射来获取 - Java:塞类名称+类的变量
4.3 Protobuf编解码器

这里可以看出来,protobuf采用的是不定长,报文头不是定长的,站在性能角度来说,是可以不浪费空间的。
这样看也大致大知道protobuf非常高效
二、零拷贝
零拷贝(Zero-copy):减少没有必要拷贝的这类技术
传统的网络传输:4次拷贝
1. 为什么要有 DMA 技术?
我们来看一下,没有DMA技术的时候,我们的I/O流程是什么样子的?

- 用户进程执行
read()方法,由用户态变为内核态,由CPU向磁盘控制器发送I/O指令; - 磁盘控制器收到指令后,将磁盘中的数据读取放到磁盘缓存区,向 CPU 发送
中断信号 - CPU 收到中断信号后,将磁盘缓存区的数据一个字节一个字节的读进寄存器当中,再由寄存器读取到内存中
- 在 CPU 搬运数据的过程中,CPU 是无法做其他的事情的,这就导致了如果我们传输大量的数据,势必会影响当前 CPU 的性能。
这种肯定不是科学家们想要看到的,于是出现了 DMA(直接内存访问) 技术
DMA技术:在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务

简单来说,DMA技术代替了CPU将磁盘中的数据搬运到内核缓存区的这个过程。
2. 传统的文件传输的弊端
我们要想提供文件传输的能力,必须经过一下两步:
- 从磁盘中读取出来:
read(file, tmp_buf, len) - 从网卡中发送出去:
write(socket, tmp_buf, len)
虽然只有两行代码,但发生的事情可不少

这个流程一共发生了4次用户态到内核态的切换以及4次数据拷贝(2次DMA拷贝、2次CPU拷贝)
要想优化我们的数据传输,必须要优化
用户态到内核态的切换以及数据拷贝3. 零拷贝
在文件传输的场景中,我们不会对文件进行再次加工,所以数据实际上不需要搬运到用户空间,因此用户区的缓存是完全没有必要的,也就是2次CPU拷贝也是没有必要的。
目前,零拷贝实现的方法有两种:
- mmap + write
- sendfile
3.1 mmap + write
原始的代码如下:
buf = mmap(file, len); write(sockfd, buf, len);- 1
- 2
这里的
mmap就是我们将内核中的数据在用户数据做了一份映射,用户空间和内核空间都可以访问该处的数据。这样,我们就不需要将数据拷贝到用户缓存区了。
但是,我们看图可以发现,这样的技术方案一共经历了:
- 2次DMA拷贝、1次CPU拷贝
- 2次系统调用(4次上下文切换)
3.2 sendfile
Linux 2.1 版本专门提供了一个发送文件的函数:
sendfile()#includessize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); - 1
- 2
- out_fd:输出端的描述符
- in_fd:输入端的描述符
- off_t:输入端的偏移量
- count:复制数据的长度
使用一个方法代替了原有的
read() + write(),减少了一次系统调用,也就减少了2次上下文切换。
当然,如果你的网卡支持
SG-DMA技术,我们可以直接把内核缓冲区的描述符直接发送到网卡。这个时候,就是我们真正的零拷贝技术。
我们的CPU不参与任何的数据搬运,所有的数据都是通过 DMA 技术进行搬运的。
这种零拷贝技术相较于传统的数据传输,节省了:
- 1次系统调用(2次上下文切换)
- 2次CPU拷贝
总体来说,零拷贝相较于普通的数据传输,起码性能要提高一倍。
4. 零拷贝实战测试
当然,我们通过上述的描述可以看出:零拷贝确实比正常的数据传输性能要快一倍,但你怎么证明呢?
我们起一个简单的服务端:
public class Server { public static void main(String[] args) throws Exception { //创建serversocket 对象--8081服务 ServerSocket serverSocket = new ServerSocket(8088); //循环监听连接 while (true){ Socket socket = serverSocket.accept();//客户端发起网络请求---连接 //创建输⼊流对象 DataInputStream dataInputStream = new DataInputStream(socket.getInputStream()); int byteCount=0; try{ byte[] bytes = new byte[1024]; //创建缓冲区字节数组 while(true){ int readCount = dataInputStream.read(bytes, 0, bytes.length); byteCount=byteCount+readCount; if(readCount==-1){ System.out.println("服务端接受:"+byteCount+"字节"); break; } } }catch (Exception e){ e.printStackTrace(); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
服务端的作用就负责接受数据
传统文件传输的客户端:
public class TranditionClient { public static void main(String[] args) throws Exception { Socket socket = new Socket("localhost",8088); String fileName = "C:\\Users\\Administrator\\Desktop\\零拷贝.png"; //创建输⼊流对象 InputStream inputStream = new FileInputStream(fileName); //创建输出流 DataOutputStream dataOutputStream = new DataOutputStream(socket.getOutputStream()); byte[] buffer = new byte[1024]; long readCount = 0; long total=0; long startTime = System.currentTimeMillis(); //TODO 这里要发生2次copy while ((readCount=inputStream.read(buffer))>=0){ total+=readCount; //TODO 网络发送:这里要发生2次copy dataOutputStream.write(buffer); } long endTime = System.currentTimeMillis(); System.out.println("发送总字节数:"+total+",耗时:"+(endTime-startTime)+" ms"); //释放资源 dataOutputStream.close(); socket.close(); inputStream.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
零拷贝的客户端:
public class NewIOClient { public static void main(String[] args) throws Exception { //socket套接字 SocketChannel socketChannel = SocketChannel.open(); socketChannel.connect(new InetSocketAddress("localhost",8088)); socketChannel.configureBlocking(true); //文件 String fileName = "C:\\Users\\Administrator\\Desktop\\零拷贝.png"; //FileChannel 文件读写、映射和操作的通道 FileChannel fileChannel = new FileInputStream(fileName).getChannel(); long startTime = System.currentTimeMillis(); //transferTo⽅法⽤到了零拷⻉,底层是sendfile,这里只需要发生2次copy和2次上下文切换 long transferCount = fileChannel.transferTo(0, fileChannel.size(), socketChannel); long endTime = System.currentTimeMillis(); System.out.println("发送总字节数:"+transferCount+"耗时:"+(endTime-startTime)+" ms"); //释放资源 fileChannel.close(); socketChannel.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们来看看效果对比:
- 传统文件传输:

- 零拷贝文件传输:

Netty的文件传输使用了 FileChannel 的 transferTo 方法,底层使用到sendfile函数来实现了零拷贝
// 类的全路径:io.netty.channel.DefaultFileRegion @Override public long transferTo(WritableByteChannel target, long position) throws IOException { long count = this.count - position; //这里使用的sendfile的拷贝技术 long written = file.transferTo(this.position + position, count, target); if (written > 0) { transferred += written; } else if (written == 0) { validate(this, position); } return written; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
三、锁优化
1. 减少锁的粒度
在版本
4.1.15版本中,io.netty.bootstrap.ServerBootstrap#init,对当前执行的对象进行加锁请注意,因为这个方法已经被重构了,但是这个地方比较经典:展示需要找老版本

2. 减少锁对象的空间占用
在
io.netty.channel.ChannelOutboundBuffer类中,Netty使用了private volatile long totalPendingSize;统计待发送的字节数。//使用原子操作类确保多线程安全 private static final AtomicLongFieldUpdater<ChannelOutboundBuffer> TOTAL_PENDING_SIZE_UPDATER = AtomicLongFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "totalPendingSize"); //统计待发送的字节数(为什么不直接使用原子操作类:AtomicLong) private volatile long totalPendingSize; private void incrementPendingOutboundBytes(long size, boolean invokeLater) { if (size == 0) { return; } long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size); //判断待发送的数据的size是否高于高水位线 if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) { setUnwritable(invokeLater); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
使用
volatile是为了保证线程安全,那么为什么不直接使用原子操作类(AtomicLong)呢?原因在于这样写可以节省内存空间,我们将
AtomicLong与totalPendingSize + AtomicLongFieldUpdater进行对比可发现对于
AtomicLong它始终是一个类,既然是类,那么必定有对象头 + Long + 引用这样,在32位的系统下,这个类最低也要占用32 bytes,而我们的totalPendingSize只需要占用8 bytes即可。我们一次计算就可以减少
24 bytes,假设拿Netty做的网关,一天的调用量可达上亿次,这就体现出空间优化的好处了。3. 提高锁的性能
public static LongCounter newLongCounter() { if (javaVersion() >= 8) { return new LongAdderCounter(); } else { return new AtomicLongCounter(); } } final class LongAdderCounter extends LongAdder implements LongCounter { @Override public long value() { return longValue(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这里主要对比
LongAdder和AtomicLong的性能我们尽量用一张图来描述这两个技术的关联和区别

简单来说,
LongAdder使用空间换时间的概念,性能比AtomicLong要高测试数据如下:
条件>>>>>>线程数:10, 单线程操作10000 LongAdder--count100000,time:5 Atomic--count100000,time:5 ================== 条件>>>>>>线程数:10, 单线程操作200000 LongAdder--count2000000,time:17 Atomic--count2000000,time:43 ================== 条件>>>>>>线程数:100, 单线程操作200000 LongAdder--count20000000,time:29 Atomic--count20000000,time:377- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
随着线程数的越来越多,我们
LongAdder的性能远远大于我们的AtomicLong的性能但如果你当前的线程较少,则直接使用
AtomicLong即可,不需要使用LongAdder4. 能不用锁则不用锁
在
io.netty.util.Recycler中,使用ThreadLocal来进行替代锁的功能 -
相关阅读:
magento1.x多域名部署可行性方案
抖音短视频实操:抖音热门视频的分类特点,如何选择视频内容并创作(下)
神经网络拟合函数表达式,神经网络拟合效果不好
2022面试相关 - react相关原理
计算机毕业设计JAVA网上商城购物系统mybatis+源码+调试部署+系统+数据库+lw
飞致云及其旗下1Panel项目进入2023年第三季度最具成长性开源初创榜单
「优选算法刷题」:比较含退格的字符串
Java基础学习
Avalonia 实现跨平台的视频聊天、屏幕分享(源码,支持Win、银河麒麟、统信UOS)
DispatcherServlet初始化之遍历HandlerMethod
- 原文地址:https://blog.csdn.net/qq_40915439/article/details/126614269