-
PAA介绍
ECCV 2020 的一篇文章
论文地址:https://arxiv.org/abs/2007.08103
目录
一、简介(摘要)
PAA表示(Probabilistic Anchor Assignment),仍然是anchor分配机制(这几年目标检测的一个热点方向)。近年来已经证实anchor分配策略可以很大影响一个模型的性能。
本文提出的策略可以根据模型的学习状态自适应地将锚点分配给对应gt的正样本和负样本,从而使模型能够以概率的方式对分配进行推理。
整个策略流程为:
- 首先根据当前模型计算所有anchor的得分,这个得分可以反映出检测框分类和定位的质量,可以看作是模型认为这个anchor是否跟object相关
- 然后根据这些得分拟合出一个概率分布(可以区分是正负样本两种模式),然后再根据这个概率分布来找到正样本概率高的样本,以此划分正负样本,这样就将anchor分配问题转换成一个最大似然估计问题
- 最后再用这些正负样本对模型进行训练。
此外,本文还研究了训练阶段和测试推理阶段的gap(训练的时候要同时优化分类和定位,但是测试的时候只根据分类得分来选择bbox),并且提出了在测试阶段加入预测IoU来衡量定位的精度,最后用分类得分乘IoU的预测值来当NMS的依据,弥补训练和测试的gap,如下图所示(Post-Processing=后处理,表示推理阶段)。这种方法在RetinaNet的baseline上只额外增加了一层卷积层,因此十分高效。
最后,还提出了一种得分投票的方法来提高精度

已在mmdetection里实现,详见configs/paa/
二、相关背景介绍
已有的一些anchor分配策略一般考虑anchor跟gt的IoU,如果IoU超过给定的阈值,那么就被指定为正样本。但是这种策略没有考虑到相交区域里的实际内容,可能里面包含了很多带噪声的背景、其他object以及只包含了对应object里少量有意义的部分。
在本文提出以前已经有一些工作提出了新的anchor分配策略,本文进一步拓展了相关思想,提出了一种新的anchor分配策略PAA(PAA具体操作见简介)。思路是分配过程要跟模型相关,不同的模型产生的正样本也不同;哪怕没有一个anchor跟gt的iou高,也要分配一些anchor作为正样本进行训练,即,只要模型推理出这个anchor跟gt相关,没必要看iou高不高;另外只要满足条件,都可以成为正样本,没必要限制固定的数量;最重要的是,需要评估这些anchor的质量来反映模型的状态。
三、提出的方法
3.1 概率Anchor分配算法
本文的目的是为了设计出一个Anchor分配策略, 要求是实现三个功能:
- 要能根据模型能否找到能用于分配anchor给对应object的证据的概率来衡量这个anchor的质量
- anchor划分为正负样本应该是自适应的,动态的,所以不能有什么IoU阈值这样的超参数
- 分配策略总体是概率分布的可能性最大化,类似极大似然的思想,这样分配过程就带有概率性
具体来说,定义一个anchor的质量分数,用来反映出这个anchor对于离它最近的gt的bbox预测输出的质量,可以简单设计为定位得分乘分类得分,其中定位得分是IoU


注:文中w.r.t =with regard to 的缩写,意思是“关于”
然后对这个评分进行相关操作后拓展成一个评分损失函数:
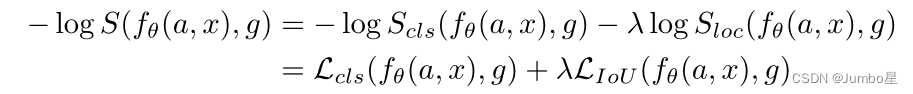
我们把这个anchor对于给定GT的得分看成是从一个分布中采样得到的,然后用最大似然的方法来估计这个分布的参数。由于要将anchor分为正样本和负样本,因此我们用GMM(高斯混合模型),用两个高斯分布来建模这个anchor的得分分布。

只要给定一组anchor的得分,就可以用EM(期望值最大化)来估计上面这个高斯分布的参数。
得到概率分布后,进行区分正负样本的方法有很多种,如下图所示,都行。

具体算法伪代码如下图所示:

为了计算anchor的分数,首先把anchor分配给IoU最高的那个gt(第3行)。为了让EM算法更加高效,我们从每个特征level上选择了top k个anchor(5-11行),然后进行EM的估计(12行),top k之外的anchor被分配为负样本(16行)。
3.2 测试阶段加入预测IoU值作为定位质量评估
测试的时候,只需要加入一个额外的卷积层,用sigmoid进行激活,预测得到合理范围内的IoU的预测,训练目标现在变成:

实验证明可以提高精度。
3.3 评分投票
在后处理阶段提出了一个trick:在NMS之后,对每个留下来的预测框b,根据其中si计算得到的分数si将b更新为b_hat

候,只需要加入一个额外的卷积层,用sigmoid进行激活,预测得到合理范围内的IoU的预测,训练目标现在变成:

实验证明可以提高精度。
-
相关阅读:
(JAVA)认识Java中的数据类型和变量
【Linux初阶】认识冯诺依曼结构
快速排序实现Java版本
DN gc影响hbase查询性能
【python】python进行debug操作
银行实时汇率查询易语言代码
新闻发稿多少钱一篇?轻松发布新闻一站式发稿服务平台
他们在学校里不会教你的编程原则
IPV6(IPV6,RIPng的配置以及手工配置IPV4隧道)
利用python数据分析——Numpy基础:数组和矢量计算
- 原文地址:https://blog.csdn.net/jiangqixing0728/article/details/126505989