-
Mysql事物、隔离级别、锁
1. 理论知识:
数据库的事务必须同时满足 4 个特性 ( ACID )。默认事物级别:可重复读RR(一般大厂为了提高并发,都是RC)
特性
说明
原子性 Atomic
表示组成一个事务的多次数据库操作是一个不可分割的原子单元,只有所有的操作都执行成功,才提交整个事务 。 事务中的任何一次数据库操作失败,已经执行操作都必须回滚,让数据库返回到操作前的状态 。 要么全部成功,要不全部失败
一致性 Consistency
事务操作后,数据库所处的状态和它的业务规则是一致的 。比如 A 账户转账到 B 账户,不管操作是否异常, A 账户与 B 账户的总额是不变的。 数据和业务一致
隔离性 Isolation
在并发操作数据时,不同的事务拥有各自的数据空间,它们的操作既可能地不对对方产生干扰。数据库规定了多种事务隔离级别,不同的隔离级别对应不同的干扰程度 。 隔离级别越高,数据一致性越好,但并发性越差。 不同事物互不影响
持久性 Durability
一旦事务提交成功,事务中所有的数据都必须被持久化到数据库中 。 即使在提交事务后数据库发生崩溃,那么当数据库重启时,也必须保证能够根据日志恢复数据 。
数据库管理系统采用数据库锁来保证事物的隔离性,当多个事务试图对相同的数据执行操作时,只有持有锁的事务才能真正操作数据。但是
因为直接使用锁比较麻烦,所以数据库为我们设置了事务的隔离级别,这些级别实现了自动锁机制 。 设置好事务的隔离级别后,数据库就会分析事务中的 SQL 语句,然后自动为事务所操作的数据加上适合的锁 。 而且,数据库还会维护这些锁,当一个资源上的锁数目太多时,就会自动升级,从而提高系统的运行性能。这些过程对我们来说是完全透明的
数据库的加锁
分类方式
类别
锁定对象
表锁定(整张表)、行锁定(特定行)
并发事务锁定关系
共享锁定(运行其它的共享锁定,但防止独占锁定)、独占锁定(防止任何锁定)
事物的隔离级别
- Read Uncommitted(读未提交):在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read);(某个数据)
- Read Committed(读已提交):这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果;(某个数据)
- Repeatable Read(可重读):这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题(某几行数据)
- Serializable(可串行化):这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。(顺序执行,解决所有问题)
2. 实际操作问题
- 可重复读会出现幻读问题
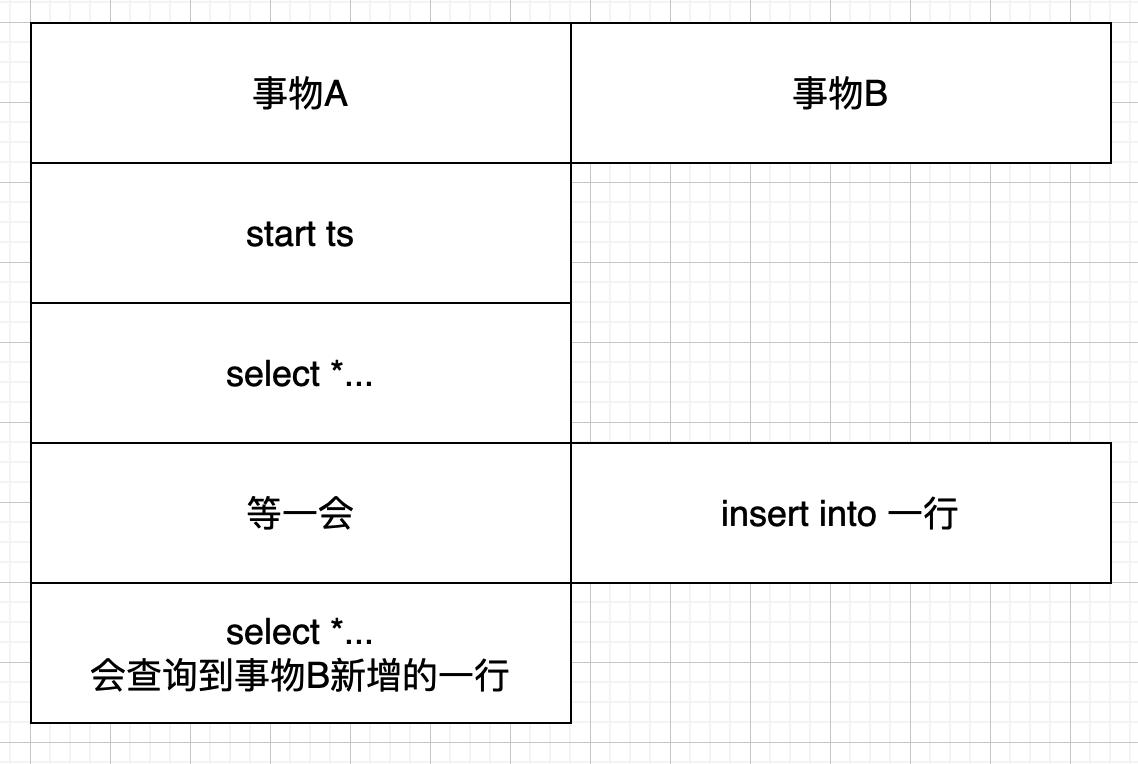
注意:start ts 事物不会真正开始,只有对数据库进行读写后才会开始;所以事物A的事物开始时间是执行了select * 操作;
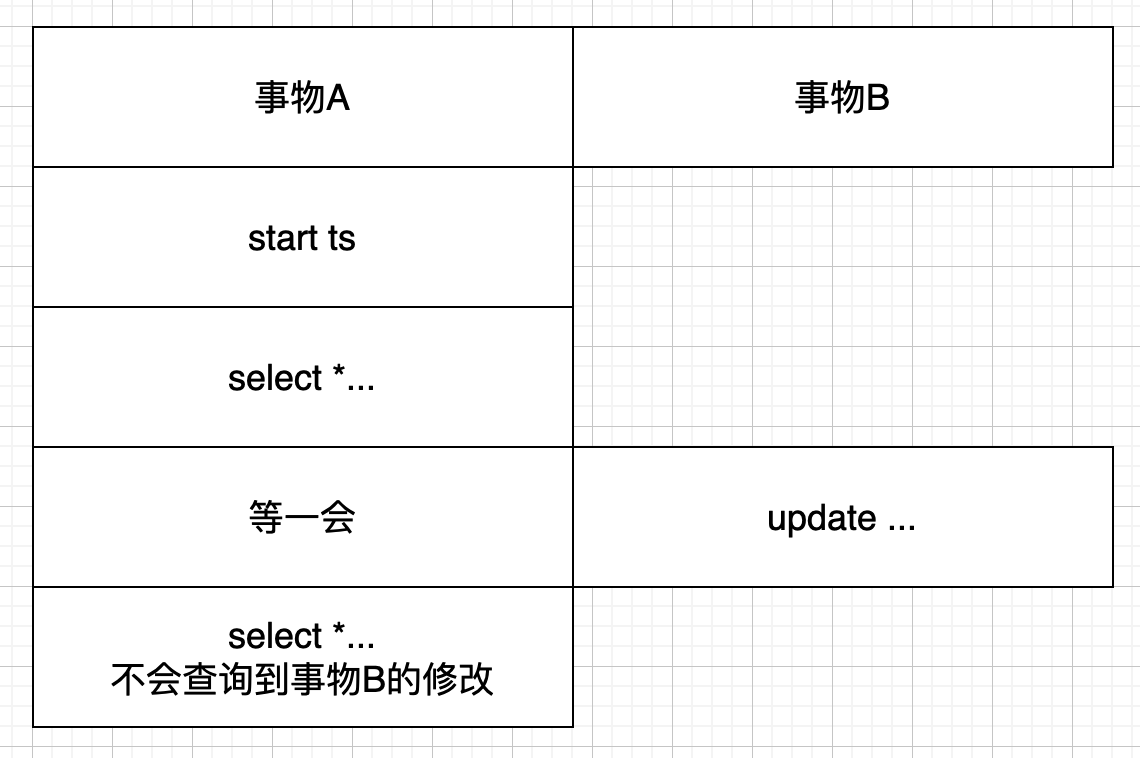
- 读提交问题;
-
- 正常操作;
(图2.a)
b. 异常操作

(图2.b)
如何理解:
我们都知道哈,事物开启时会存在类似一个版本号的东西(tx_id),图2.a,为什么事物A在事物B更新了一条数据后依旧查的是之前的数据,那就是因为版本号,事物A在开始事物时创建了版本号为1的数据,事物B在开始事物并提交的时候修改的是版本号为2的数据,所以,事物A查的版本号为1的事物还是之前的数据;
但是:
图2.b为什么,事物A在最后查的时候却查出来a=2,并不是a=1呢?
因为事物A更新操作时拿到的a记录的版本号是最新的2,并不是旧的1,所以,A更新时拿到了事物B更新之后的a=1,并且更新了版本号2,所以,再查的时候就是查到了版本2的数据;
(MVCC给每条数据都加了两个隐藏列:创建版本、新增版本(值时事物的版本值)。所以所谓的创建是:先删除在新增。并且在查询时版本值必须大于等于当前事物的版本)
Mysql扩展
纵向分割与横向分割:表的拆分分为横向拆分(记录的拆分)和纵向拆分(字段的拆分)。拆分表的目的:提高查询速度。
横向:根据id平均拆分表记录
纵向:根据字段拆分
比如人员表,活跃字段像用户名、密码、昵称等,惰性字段像手机号、邮箱、性别等不经常使用和修改的字段。
一张完整的用户表可以拆分为两张表
-
相关阅读:
.NET Avalonia开源、免费的桌面UI库 - SukiUI
Python 操作MongoDB数据库
HAL库与cubemx系列教程|采用面向对象的方法写一个OLED驱动
Docker 仓库与注册表: 构建可靠的容器镜像生态系统
Tomcat部署及优化
C语言的MySQL接口详解
Redis数据结构
1:uniapp路由跳转
mysql.help_topic:join后面on居然还可以用 < 连接实现列转行
二分算法(2)
- 原文地址:https://blog.csdn.net/qq_17213067/article/details/126400170